

10_泛型程序设计与STL
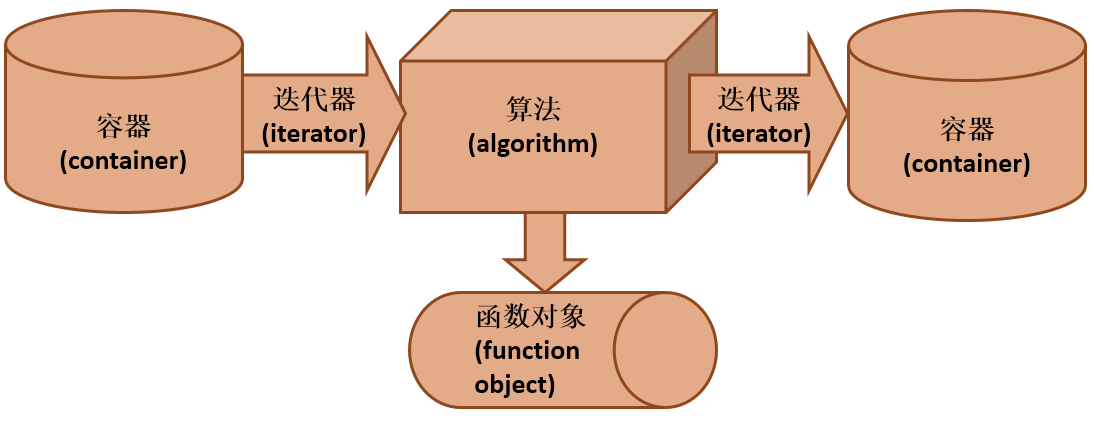
泛型程序和STL
STL组件
-
容器:存储元素的对象
-
迭代器:泛化后的指针
-
适配器:stack, queue,
-
函数对象:泛化的函数
-
算法:函数对象作为算法的参数
迭代器
算法和容器的桥梁,使得算法和容器独立
- istream_iterator 输入流迭代器
- ostream_iterator 输出流迭代器
- 前向迭代器
- 双向迭代器
- 随机访问迭代器
迭代器的区间
- [p1, p2) 左闭右开;一般以迭代器的区间作为算法的输入
- advance(p, n) n次递增
- distance(first, last) 两个迭代器距离
#include <iostream>
#include <vector>
#include <algorithm>
#include <iterator>
using namespace std;
template <class T, class InputIterator, class OutputIterator>
void mySort(InputIterator first, InputIterator last, OutputIterator result)
{
vector<int> s;
for (;first!=last;first++)
{
s.push_back(*first);
}
sort(s.begin(), s.end()); //随机访问迭代器
copy(s.begin(), s.end(), result);
}
int main() {
//将s数组的内容排序后输出
double a[5] = { 1.2, 2.4, 0.8, 3.3, 3.2 };
mySort<double>(a, a + 5, ostream_iterator<double>(cout, " "));
cout << endl;
//从标准输入读入若干个整数,将排序后的结果输出
mySort<int>(istream_iterator<int>(cin), istream_iterator<int>(), ostream_iterator<int>(cout, " "));
cout << endl;
return 0;
}
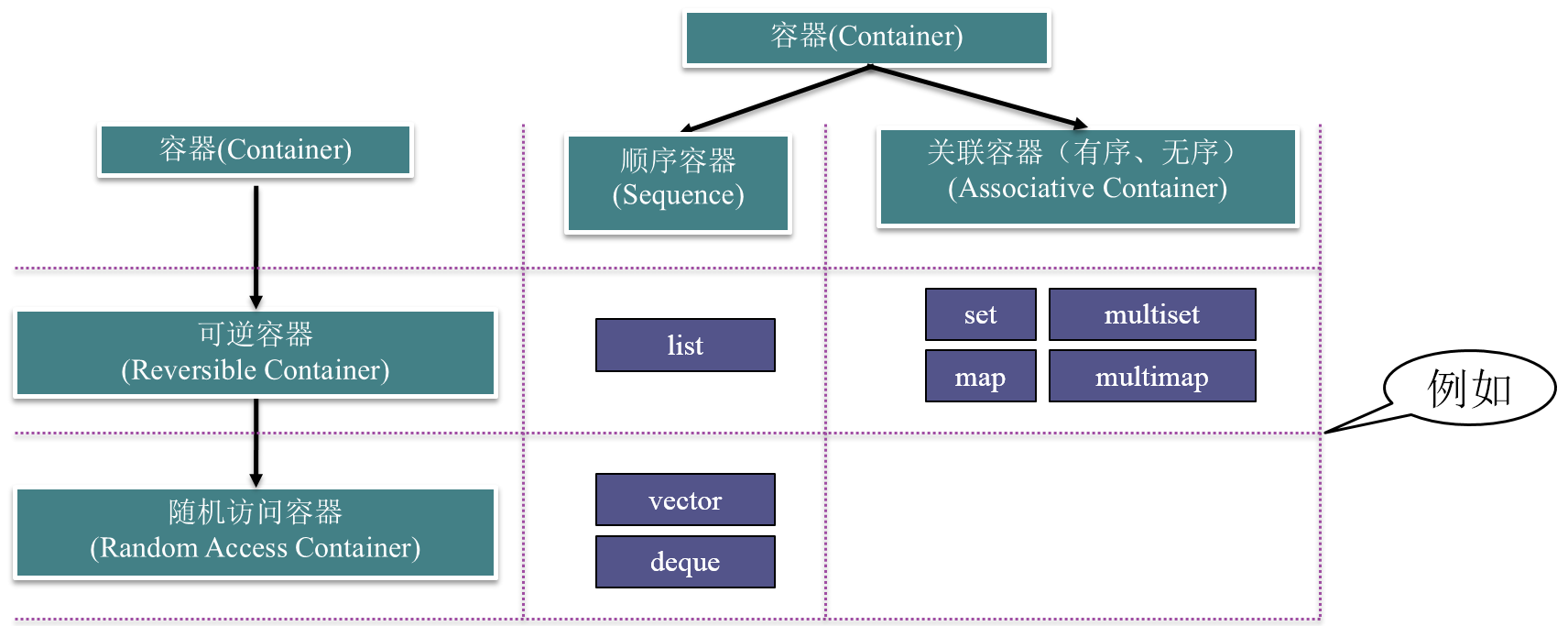
容器
-
容器的通用功能
-
- 用默认构造函数构造空容器
- 支持关系运算符:==、!=、<、<=、>、>=
- begin()、end():获得容器首、尾迭代器;end()指向最后一个元素的下一个位置;一般循环终止条件是first!=end()
- clear():将容器清空
- empty():判断容器是否为空
- size():得到容器元素个数
- s1.swap(s2):将s1和s2两容器内容交换
-
相关数据类型(S表示容器类型)
-
- S::iterator:指向容器元素的迭代器类型
- S::const_iterator:常迭代器类型
-
STL为每个可逆容器都提供了逆向迭代器,逆向迭代器可以通过下面的成员函数得到:
-
- rbegin() :指向容器尾的逆向迭代器
- rend():指向容器首的逆向迭代器
-
随机访问容器支持对容器的元素进行随机访问
-
- s[n]:获得容器s的第n个元素
顺序容器
包括vector、双端队列,链表,单向链表
可以看作是长度可扩展的数组
顺序容器的接口(不包含单向链表(forward_list)和数组(array))
- 构造函数
- 赋值函数
- assign
- 插入函数
- insert, push_front(只对list和deque), push_back,emplace,emplace_front
- 删除函数
- erase,clear,pop_front(只对list和deque) ,pop_back,emplace_back
- 首尾元素的直接访问
- front,back
- 改变大小
- resize
#include <iostream>
#include <list>
#include <deque>
//输出指定的顺序容器的元素
template <class T>
void printContainer(const char* msg, const T& s) {
cout << msg << ": ";
copy(s.begin(), s.end(), ostream_iterator<int>(cout, " "));
cout << endl;
}
int main() {
//从标准输入读入10个整数,将它们分别从s的头部加入
deque<int> s;
for (int i = 0; i < 10; i++) {
int x;
cin >> x;
s.push_front(x);
}
printContainer("deque at first", s);
//用s容器的内容的逆序构造列表容器l
list<int> l(s.rbegin(), s.rend());
printContainer("list at first", l);
//将列表容器l的每相邻两个元素顺序颠倒
list<int>::iterator iter = l.begin();
while (iter != l.end()) {
int v = *iter;
iter = l.erase(iter);
l.insert(++iter, v);
}
printContainer("list at last", l);
//用列表容器l的内容给s赋值,将s输出
s.assign(l.begin(), l.end());
printContainer("deque at last", s);
return 0;
}
/*
运行结果如下:
0 9 8 6 4 3 2 1 5 4
deque at first: 4 5 1 2 3 4 6 8 9 0
list at first: 0 9 8 6 4 3 2 1 5 4
list at last: 9 0 6 8 3 4 1 2 4 5
deque at last: 9 0 6 8 3 4 1 2 4 5
/*
向量vector
- 一个可以扩展的动态数组
- 随机访问、在尾部插入或删除元素快
- 在中间或头部插入或删除元素慢
双端队列deque
- 在两端插入或删除元素快
- 在中间插入或删除元素慢
- 随机访问较快,但比向量容器慢
链表list
- 在任意位置插入和删除元素都很快
- 不支持随机访问
单向链表(forward_list)
- 单向链表每个结点只有指向下个结点的指针,没有简单的方法来获取一个结点的前驱;
- 未定义insert、emplace和erase操作,而定义了insert_after、emplace_after和erase_after操作,其参数与list的insert、emplace和erase相同,但并不是插入或删除迭代器p1所指的元素,而是对p1所指元素之后的结点进行操作;
- 不支持size操作。
数组(array)
- array是对内置数组的封装,提供了更安全,更方便的使用数组的方式
- array的对象的大小是固定的,定义时除了需要指定元素类型,还需要指定容器大小。
- 不能动态地改变容器大小
顺序容器的比较
- STL所提供的顺序容器各有所长也各有所短,我们在编写程序时应当根据我们对容器所需要执行的操作来决定选择哪一种容器。
- 如果需要执行大量的随机访问操作,而且当扩展容器时只需要向容器尾部加入新的元素,就应当选择向量容器vector;
- 如果需要少量的随机访问操作,需要在容器两端插入或删除元素,则应当选择双端队列容器deque;
- 如果不需要对容器进行随机访问,但是需要在中间位置插入或者删除元素,就应当选择列表容器list或forward_list;
- 如果需要数组,array相对于内置数组类型而言,是一种更安全、更容易使用的数组类型。
int main() {
istream_iterator<int> i1(cin), i2; //建立一对输入流迭代器
vector<int> s1(i1, i2); //通过输入流迭代器从标准输入流中输入数据
sort(s1.begin(), s1.end()); //将输入的整数排序
deque<int> s2;
//以下循环遍历s1
for (vector<int>::iterator iter = s1.begin(); iter != s1.end(); ++iter)
{
if (*iter % 2 == 0) //偶数放到s2尾部
s2.push_back(*iter);
else //奇数放到s2首部
s2.push_front(*iter);
}
//将s2的结果输出
copy(s2.begin(), s2.end(), ostream_iterator<int>(cout, " "));
cout << endl;
return 0;
}
int main() {
string names1[] = { "Alice", "Helen", "Lucy", "Susan" };
string names2[] = { "Bob", "David", "Levin", "Mike" };
//用names1数组的内容构造列表s1
list<string> s1(names1, names1 + 4);
//用names2数组的内容构造列表s2
list<string> s2(names2, names2 + 4);
//将s1的第一个元素放到s2的最后
s2.splice(s2.end(), s1, s1.begin());
list<string>::iterator iter1 = s1.begin(); //iter1指向s1首
advance(iter1, 2); //iter1前进2个元素,它将指向s1第3个元素
list<string>::iterator iter2 = s2.begin(); //iter2指向s2首
++iter2; //iter2前进1个元素,它将指向s2第2个元素
list<string>::iterator iter3 = iter2; //用iter2初始化iter3
advance(iter3, 2); //iter3前进2个元素,它将指向s2第4个元素
//将[iter2, iter3)范围内的结点接到s1中iter1指向的结点前
s1.splice(iter1, s2, iter2, iter3);
//分别将s1和s2输出
copy(s1.begin(), s1.end(), ostream_iterator<string>(cout, " "));
cout << endl;
copy(s2.begin(), s2.end(), ostream_iterator<string>(cout, " "));
cout << endl;
return 0;
}
适配器
插入迭代器:front_inserter, back_inserter, inserter
list<int> s;
back_inserter iter(s);
*(iter++) = 5; //通过iter把5插入s末尾
以顺序容器为基础构建一些常用数据结构,是对顺序容器的封装,称为适配器
- 栈(stack):最先压入的元素最后被弹出
- 队列(queue):最先压入的元素最先被弹出
- 优先级队列(priority_queue):最“大”的元素最先被弹出
template <class T, class Sequence = deque<T> > class stack;
template <class T, class FrontInsertionSequence = deque<T> > class queue;
栈和队列
- s1 op s2 op可以是==、!=、<、<=、>、>=之一,它会对两个容器适配器之间的元素按字典序进行比较
- s.size() 返回s的元素个数
- s.empty() 返回s是否为空
- s.push(t) 将元素t压入到s中
- s.pop() 将一个元素从s中弹出,对于栈来说,每次弹出的是最后被压入的元素,而对于队列,每次被弹出的是最先被压入的元素
- 不支持迭代器,因为它们不允许对任意元素进行访问
栈和队列不同的操作
- 栈的操作
- s.top() 返回栈顶元素的引用
- 队列操作
- s.front() 获得队头元素的引用
- s.back() 获得队尾元素的引用
int main() {
stack<char> s;
string str;
cin >> str; //从键盘输入一个字符串
//将字符串的每个元素顺序压入栈中
for (string::iterator iter = str.begin(); iter != str.end(); ++iter)
s.push(*iter);
//将栈中的元素顺序弹出并输出
while (!s.empty()) {
cout << s.top();
s.pop();
}
cout << endl;
return 0;
}
运行结果如下:
congratulations
snoitalutargnoc
优先级队列
-
每次弹出“最大”的元素
-
优先级队列的基础容器必须是支持随机访问的顺序容器。
-
支持栈和队列的size、empty、push、pop几个成员函数,用法与栈和队列相同。
-
优先级队列并不支持比较操作。
-
与栈类似,优先级队列提供一个top函数,可以获得下一个即将被弹出元素(即最“大”的元素)的引用
template <class T, class Sequence = vector<T> > class priority_queue;
const int SPLIT_TIME_MIN = 500; //细胞分裂最短时间
const int SPLIT_TIME_MAX = 2000; //细胞分裂最长时间
class Cell;
priority_queue<Cell> cellQueue;
class Cell { //细胞类
private:
static int count; //细胞总数
int id; //当前细胞编号
int time; //细胞分裂时间
public:
Cell(int birth) : id(count++) { //birth为细胞诞生时间
//初始化,确定细胞分裂时间
time = birth + (rand() % (SPLIT_TIME_MAX - SPLIT_TIME_MIN))+ SPLIT_TIME_MIN;
}
int getId() const { return id; } //得到细胞编号
int getSplitTime() const { return time; } //得到细胞分裂时间
bool operator < (const Cell& s) const //定义“<”
{ return time > s.time; }
void split() { //细胞分裂
Cell child1(time), child2(time); //建立两个子细胞
cout << time << "s: Cell #" << id << " splits to #"
<< child1.getId() << " and #" << child2.getId() << endl;
cellQueue.push(child1); //将第一个子细胞压入优先级队列
cellQueue.push(child2); //将第二个子细胞压入优先级队列
}
};
int Cell::count = 0;
int main() {
srand(static_cast<unsigned>(time(0)));
int t; //模拟时间长度
cout << "Simulation time: ";
cin >> t;
cellQueue.push(Cell(0)); //将第一个细胞压入优先级队列
while (cellQueue.top().getSplitTime() <= t) {
cellQueue.top().split(); //模拟下一个细胞的分裂
cellQueue.pop(); //将刚刚分裂的细胞弹出
}
return 0;
}
/*
运行结果如下:
Simulation time: 5000
971s: Cell #0 splits to #1 and #2
1719s: Cell #1 splits to #3 and #4
1956s: Cell #2 splits to #5 and #6
2845s: Cell #6 splits to #7 and #8
3551s: Cell #3 splits to #9 and #10
3640s: Cell #4 splits to #11 and #12
3919s: Cell #5 splits to #13 and #14
4162s: Cell #10 splits to #15 and #16
4197s: Cell #8 splits to #17 and #18
4317s: Cell #7 splits to #19 and #20
4686s: Cell #13 splits to #21 and #22
4809s: Cell #12 splits to #23 and #24
4818s: Cell #17 splits to #25 and #26
*/
关联容器
- 关联容器的特点
- 每个关联容器都有一个键(key)
- 可以根据键高效地查找元素
- 接口
- 插入:insert
- 删除:erase
- 查找:find
- 定界:lower_bound、upper_bound、equal_range
- 计数:count
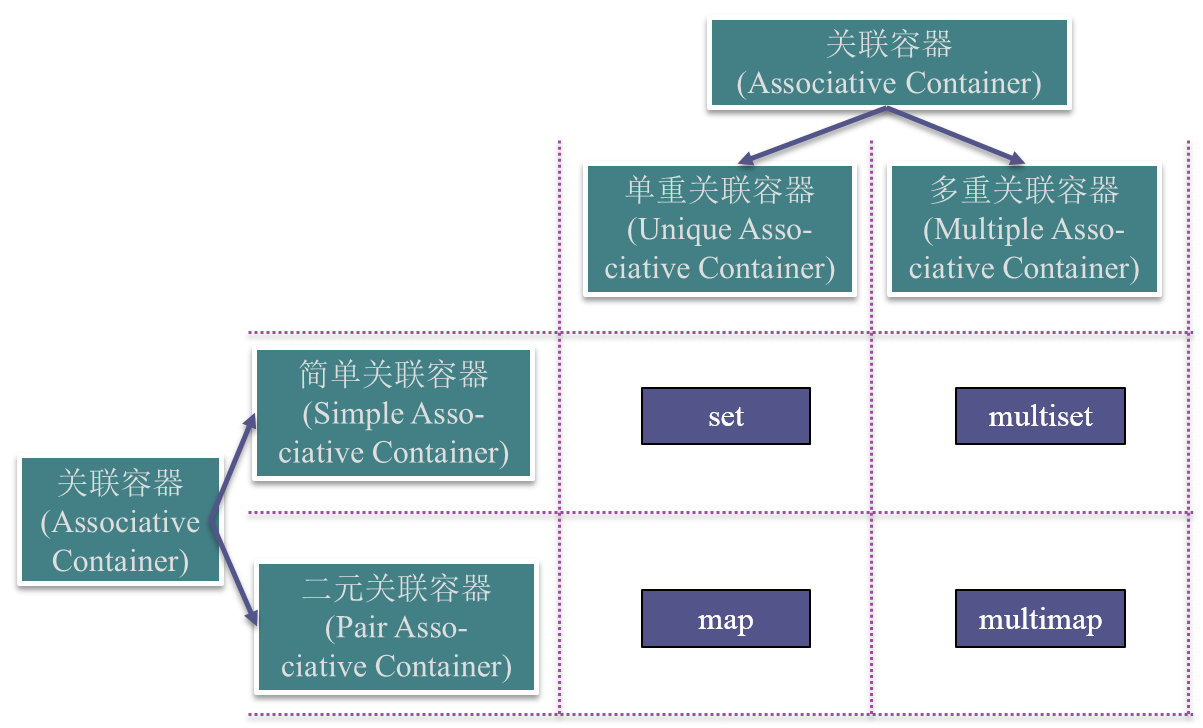
四种关联容器
- 单重关联容器(set和map)
- 键值是唯一的,一个键值只能对应一个元素
- 多重关联容器(multiset和multimap)
- 键值是不唯一的,一个键值可以对应多个元素
- 简单关联容器(set和multiset)
- 容器只有一个类型参数,如set、multiset,表示键类型
- 容器的元素就是键本身
- 二元关联容器(map和multimap)
- 容器有两个类型参数,如map、multimap,分别表示键和附加数据的类型
- 容器的元素类型是pair,即由键类型和元素类型复合而成的二元组
无序关联容器
- C++11新标准中定义了4个无序关联容器
- unordered_set、unordered_map、unordered_multiset、unordered_multimap
- 不是使用比较运算符来组织元素的,而是通过一个哈希函数和键类型的==运算符。
- 提供了与有序容器相同的操作
- 可以直接定义关键字是内置类型的无序容器。
- 不能直接定义关键字类型为自定义类的无序容器,如果需要,必须提供我们自己的hash模板。
集合set
元素是有序的
#include <iostream>
using namespace std;
int main() {
set<double> s;
while (true) {
double v;
cin >> v;
if (v == 0) break; //输入0表示结束
//尝试将v插入
pair<set<double>::iterator,bool> r=s.insert(v);
if (!r.second) //如果v已存在,输出提示信息
cout << v << " is duplicated" << endl;
}
//得到第一个元素的迭代器
set<double>::iterator iter1=s.begin();
//得到末尾的迭代器
set<double>::iterator iter2=s.end();
//得到最小和最大元素的中值
double medium=(*iter1 + *(--iter2)) / 2;
//输出小于或等于中值的元素
cout<< "<= medium: "
copy(s.begin(), s.upper_bound(medium), ostream_iterator<double>(cout, " "));
cout << endl;
//输出大于或等于中值的元素
cout << ">= medium: ";
copy(s.lower_bound(medium), s.end(), ostream_iterator<double>(cout, " "));
cout << endl;
return 0;
}
运行结果如下:
1 2.5 5 3.5 5 7 9 2.5 0
5 is duplicated
2.5 is duplicated
<= medium: 1 2.5 3.5 5
>= medium: 5 7 9
映射
- 映射与集合同属于单重关联容器,它们的主要区别在于,集合的元素类型是键本身,而映射的元素类型是由键和附加数据所构成的二元组。
- 在集合中按照键查找一个元素时,一般只是用来确定这个元素是否存在,而在映射中按照键查找一个元素时,除了能确定它的存在性外,还可以得到相应的附加数据。
#include <iostream>
#include <map>
#include <string>
#include <utility>
using namespace std;
int main() {
map<string, int> courses;
//将课程信息插入courses映射中
courses.insert(make_pair("CSAPP", 3));
courses.insert(make_pair("C++", 2));
courses.insert(make_pair("CSARCH", 4));
courses.insert(make_pair("COMPILER", 4));
courses.insert(make_pair("OS", 5));
int n = 3; //剩下的可选次数
int sum = 0; //学分总和
while (n > 0) {
string name;
cin >> name; //输入课程名称
map<string, int>::iterator iter = courses.find(name);//查找课程
if (iter == courses.end()) { //判断是否找到
cout << name << " is not available" << endl;
} else {
sum += iter->second; //累加学分
courses.erase(iter); //将刚选过的课程从映射中删除
n--;
}
}
cout << "Total credit: " << sum << endl; //输出总学分
return 0;
}
运行结果如下:
C++
COMPILER
C++
C++ is not available
CSAPP
Total credit: 9
#include <iostream>
#include <map>
#include <cctype>
using namespace std;
int main() {
map<char, int> s; //用来存储字母出现次数的映射
char c; //存储输入字符
do {
cin >> c; //输入下一个字符
if (isalpha(c)){ //判断是否是字母
c = tolower(c); //将字母转换为小写
s[c]++; //将该字母的出现频率加1
}
} while (c != '.'); //碰到“.”则结束输入
//输出每个字母出现次数
for (map<char, int>::iterator iter = s.begin(); iter != s.end(); ++iter)
cout << iter->first << " " << iter->second << " ";
cout << endl;
return 0;
}
多重集合和多重映射
- 多重集合是允许有重复元素的集合,多重映射是允许一个键对应多个附加数据的映射。
- 多重集合与集合、多重映射与映射的用法差不多,只在几个成员函数上有细微差异,其差异主要表现在去除了键必须唯一的限制。
#include <iostream>
#include <map>
#include <utility>
#include <string>
using namespace std;
int main() {
multimap<string, string> courses;
typedef multimap<string, string>::iterator CourseIter;
//将课程上课时间插入courses映射中
courses.insert(make_pair("C++", "2-6"));
courses.insert(make_pair("COMPILER", "3-1"));
courses.insert(make_pair("COMPILER", "5-2"));
courses.insert(make_pair("OS", "1-2"));
courses.insert(make_pair("OS", "4-1"));
courses.insert(make_pair("OS", "5-5"));
//输入一个课程名,直到找到该课程为止,记下每周上课次数
string name;
int count;
do {
cin >> name;
count = courses.count(name);
if (count == 0)
cout << "Cannot find this course!" << endl;
} while (count == 0);
//输出每周上课次数和上课时间
cout << count << " lesson(s) per week: ";
pair<CourseIter, CourseIter> range = courses.equal_range(name);
for (CourseIter iter = range.first; iter != range.second; ++iter)
cout << iter->second << " ";
cout << endl;
return 0;
}
运行结果如下:
JAVA
Cannot find this course!
OS
3 lesson(s) per week: 1-2 4-1 5-5
函数对象
- 普通函数就是函数对象
- 重载了“()”运算符的类的实例是函数对象
#include <numeric> //包含数值算法头文件
using namespace std;
//定义一个普通函数
int mult(int x, int y) { return x * y; };
int main() {
int a[] = { 1, 2, 3, 4, 5 };
const int N = sizeof(a) / sizeof(int);
cout << "The result by multipling all elements in a is "
<< accumulate(a, a + N, 1, mult)
<< endl;
return 0;
}
class MultClass{ //定义MultClass类
public:
//重载操作符operator()
int operator() (int x, int y) const { return x * y; }
};
int main() {
int a[] = { 1, 2, 3, 4, 5 };
const int N = sizeof(a) / sizeof(int);
cout << "The result by multipling all elements in a is "
<< accumulate(a, a + N, 1, MultClass()) //将类multclass传递给通用算法
<< endl;
return 0;
}
函数适配器
-
绑定适配器:bind1st、bind2nd
- 将n元函数对象的指定参数绑定为一个常数,得到n-1元函数对象
-
组合适配器:not1、not2
- 将指定谓词的结果取反
-
函数指针适配器:ptr_fun
- 将一般函数指针转换为函数对象,使之能够作为其它函数适配器的输入。
- 在进行参数绑定或其他转换的时候,通常需要函数对象的类型信息,例如bind1st和bind2nd要求函数对象必须继承于binary_function类型。但如果传入的是函数指针形式的函数对象,则无法获得函数对象的类型信息。
-
成员函数适配器:ptr
fun、ptr
fun_ref
- 对成员函数指针使用,把n元成员函数适配为n + 1元函数对象,该函数对象的第一个参数为调用该成员函数时的目的对象
- 也就是需要将“object->method()”转为“method(object)”形式。将“object->method(arg1)”转为二元函数“method(object, arg1)”。
int main() {
int intArr[] = { 30, 90, 10, 40, 70, 50, 20, 80 };
const int N = sizeof(intArr) / sizeof(int);
vector<int> a(intArr, intArr + N);
vector<int>::iterator p = find_if(a.begin(), a.end(), bind2nd(greater<int>(), 40));
if (p == a.end())
cout << "no element greater than 40" << endl;
else
cout << "first element greater than 40 is: " << *p << endl;
return 0;
}
注:
find_if算法在STL中的原型声明为:
template<class InputIterator, class UnaryPredicate>
InputIterator find_if(InputIterator first, InputIterator last, UnaryPredicate pred);
它的功能是查找数组[first, last)区间中第一个pred(x)为真的元素。
#include <functional>
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
bool g(int x, int y) {
return x > y;
}
int main() {
int intArr[] = { 30, 90, 10, 40, 70, 50, 20, 80 };
const int N = sizeof(intArr) / sizeof(int);
vector<int> a(intArr, intArr + N);
vector<int>::iterator p;
p = find_if(a.begin(), a.end(), bind2nd(ptr_fun(g), 40));
if (p == a.end())
cout << "no element greater than 40" << endl;
else
cout << "first element greater than 40 is: " << *p << endl;
p = find_if(a.begin(), a.end(), not1(bind2nd(greater<int>(), 15)));
if (p == a.end())
cout << "no element is not greater than 15" << endl;
else
cout << "first element that is not greater than 15 is: " << *p << endl;
p = find_if(a.begin(), a.end(), bind2nd(not2(greater<int>()), 15));
if (p == a.end())
cout << "no element is not greater than 15" << endl;
else
cout << "first element that is not greater than 15 is: " << *p << endl;
return 0;
}
#include <functional>
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
struct Car {
int id;
Car(int id) { this->id = id; }
void display() const { cout << "car " << id << endl; }
};
int main() {
vector<Car *> pcars;
vector<Car> cars;
for (int i = 0; i < 5; i++)
pcars.push_back(new Car(i));
for (int i = 5; i < 10; i++)
cars.push_back(Car(i));
cout << "elements in pcars: " << endl;
for_each(pcars.begin(), pcars.end(), std::mem_fun(&Car::display));
cout << endl;
cout << "elements in cars: " << endl;
for_each(cars.begin(), cars.end(), std::mem_fun_ref(&Car::display));
cout << endl;
for (size_t i = 0; i < pcars.size(); ++i)
delete pcars[i];
return 0;
}
算法
本质上是函数模板
