
简述伪共享和缓存一致性MESI
什么是伪共享
计算机系统中为了解决主内存与CPU运行速度的差距,在CPU与主内存之间添加了一级或者多级高速缓冲存储器(Cache),这个Cache一般是集成到CPU内部的,所以也叫 CPU Cache,如下图是两级cache结构:

Cache内部是按行存储的,其中每一行称为一个cache行,cache行是Cache与主内存进行数据交换的单位,cache行的大小一般为2的幂次数字节。

当 CPU 访问某一个变量时候,首先会去看 CPU Cache 内是否有该变量,如果有则直接从中获取,否者就去主内存里面获取该变量,然后把该变量所在内存区域的一个Cache行大小的内存拷贝到 Cache(cache行是Cache与主内存进行数据交换的单位)。由于存放到 Cache 行的的是内存块而不是单个变量,所以可能会把多个变量存放到了一个cache行。当多个线程同时修改一个缓存行里面的多个变量时候,由于同时只能有一个线程操作缓存行,所以相比每个变量放到一个缓存行性能会有所下降,这就是伪共享。
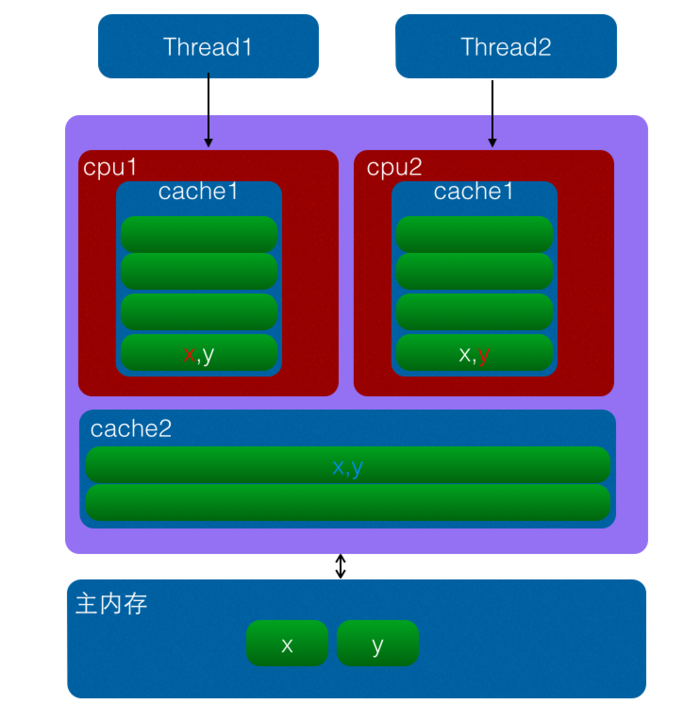
如上图变量x,y同时被放到了CPU的一级和二级缓存,当线程1使用CPU1对变量x进行更新时候,首先会修改cpu1的一级缓存变量x所在缓存行,这时候缓存一致性协议会导致cpu2中变量x对应的缓存行失效,那么线程2写入变量x的时候就只能去二级缓存去查找,这就破坏了一级缓存,而一级缓存比二级缓存更快。更坏的情况下如果cpu只有一级缓存,那么会导致频繁的直接访问主内存。
为何会出现伪共享
伪共享的产生是因为多个变量被放入了一个缓存行,并且多个线程同时去写入缓存行中不同变量。那么为何多个变量会被放入一个缓存行那。其实是因为Cache与内存交换数据的单位就是Cache,当CPU要访问的变量没有在Cache命中时候,根据程序运行的局部性原理会把该变量在内存中大小为Cache行的内存放如缓存行。
long a; long b; long c; long d;
如上代码,声明了四个long变量,假设cache行的大小为32个字节,那么当cpu访问变量a时候发现该变量没有在cache命中,那么就会去主内存把变量a以及内存地址附近的b,c,d放入缓存行。也就是地址连续的多个变量才有可能会被放到一个缓存行中,当创建数组时候,数组里面的多个元素就会被放入到同一个缓存行。那么单线程下多个变量放入缓存行对性能有影响?其实正常情况下单线程访问时候由于数组元素被放入到了一个或者多个cache行对代码执行是有利的,因为数据都在缓存中,代码执行会更快,可以对比下面代码执行:
代码(1):
public class TestForContent { static final int LINE_NUM = 1024; static final int COLUM_NUM = 1024; public static void main(String[] args) { long [][] array = new long[LINE_NUM][COLUM_NUM]; long startTime = System.currentTimeMillis(); for(int i =0;i<LINE_NUM;++i){ for(int j=0;j<COLUM_NUM;++j){ array[i][j] = i*2+j; } } long endTime = System.currentTimeMillis(); long cacheTime = endTime - startTime; System.out.println("cache time:" + cacheTime); } }
代码(2):
public class TestForContent2 { static final int LINE_NUM = 1024; static final int COLUM_NUM = 1024; public static void main(String[] args) { long [][] array = new long[LINE_NUM][COLUM_NUM]; long startTime = System.currentTimeMillis(); for(int i =0;i<COLUM_NUM;++i){ for(int j=0;j<LINE_NUM;++j){ array[j][i] = i*2+j; } } long endTime = System.currentTimeMillis(); System.out.println("no cache time:" + (endTime - startTime)); } }
笔者mac电脑上执行代码(1)多次耗时均在10ms一下,执行代码(2)多次耗时均在10ms以上。总结下来是说代码(1)比代码(2)执行的快,这是因为数组内数组元素之间内存地址是连续的,当访问数组第一个元素时候,会把第一个元素后续若干元素一块放入到cache行,这样顺序访问数组元素时候会在cache中直接命中,就不会去主内存读取,后续访问也是这样。总结下也就是当顺序访问数组里面元素时候,如果当前元素在cache没有命中,那么会从主内存一下子读取后续若干个元素到cache,也就是一次访问内存可以让后面多次直接在cache命中。而代码(2)是跳跃式访问数组元素的,而不是顺序的,这破坏了程序访问的局部性原理,并且cache是有容量控制的,cache满了会根据一定淘汰算法替换cache行,会导致从内存置换过来的cache行的元素还没等到读取就被替换掉了。
所以单个线程下顺序修改一个cache行中的多个变量,是充分利用了程序运行局部性原理,会加速程序的运行,而多线程下并发修改一个cache行中的多个变量而就会进行竞争cache行,降低程序运行性能。
如何避免伪共享
JDK8之前一般都是通过字节填充的方式来避免,也就是创建一个变量的时候使用填充字段填充该变量所在的缓存行,这样就避免了多个变量存在同一个缓存行,如下代码:
public final static class FilledLong { public volatile long value = 0L; public long p1, p2, p3, p4, p5, p6; }
假如Cache行为64个字节,那么我们在FilledLong类里面填充了6个long类型变量,每个long类型占用8个字节,加上value变量的8个字节总共56个字节,另外这里FilledLong是一个类对象,而类对象的字节码的对象头占用了8个字节,所以当new一个FilledLong对象时候实际会占用64个字节的内存,这个正好可以放入Cache的一个行。
在JDK8中提供了一个sun.misc.Contended注解,用来解决伪共享问题,上面代码可以修改为如下:
@sun.misc.Contended public final static class FilledLong { public volatile long value = 0L; }
上面是修饰类的,当然也可以修饰变量,比如Thread类中的使用:
/** The current seed for a ThreadLocalRandom */ @sun.misc.Contended("tlr") long threadLocalRandomSeed; /** Probe hash value; nonzero if threadLocalRandomSeed initialized */ @sun.misc.Contended("tlr") int threadLocalRandomProbe; /** Secondary seed isolated from public ThreadLocalRandom sequence */ @sun.misc.Contended("tlr") int threadLocalRandomSecondarySeed;
多核CPU多级缓存一致性协议MESI
多核CPU的情况下有多个一级缓存,如何保证缓存内部数据的一致,不让系统数据混乱。这里就引出了一个一致性的协议MESI。
MESI协议缓存状态
MESI 是指4中状态的首字母。每个Cache line有4个状态,可用2个bit表示,它们分别是:
缓存行(Cache line):缓存存储数据的单元。
| 状态 | 描述 | 监听任务 |
|---|---|---|
| M 修改 (Modified) | 该Cache line有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中。 | 缓存行必须时刻监听所有试图读该缓存行相对就主存的操作,这种操作必须在缓存将该缓存行写回主存并将状态变成S(共享)状态之前被延迟执行。 |
| E 独享、互斥 (Exclusive) | 该Cache line有效,数据和内存中的数据一致,数据只存在于本Cache中。 | 缓存行也必须监听其它缓存读主存中该缓存行的操作,一旦有这种操作,该缓存行需要变成S(共享)状态。 |
| S 共享 (Shared) | 该Cache line有效,数据和内存中的数据一致,数据存在于很多Cache中。 | 缓存行也必须监听其它缓存使该缓存行无效或者独享该缓存行的请求,并将该缓存行变成无效(Invalid)。 |
| I 无效 (Invalid) | 该Cache line无效。 | 无 |
注意:
对于M和E状态而言总是精确的,他们在和该缓存行的真正状态是一致的,而S状态可能是非一致的。如果一个缓存将处于S状态的缓存行作废了,而另一个缓存实际上可能已经独享了该缓存行,但是该缓存却不会将该缓存行升迁为E状态,这是因为其它缓存不会广播他们作废掉该缓存行的通知,同样由于缓存并没有保存该缓存行的copy的数量,因此(即使有这种通知)也没有办法确定自己是否已经独享了该缓存行。
从上面的意义看来E状态是一种投机性的优化:如果一个CPU想修改一个处于S状态的缓存行,总线事务需要将所有该缓存行的copy变成invalid状态,而修改E状态的缓存不需要使用总线事务。
假使有一个数据 int a = 1,这个数据被两个线程读取到了,线程1在 cpu 核心1上面执行,线程 2 在 cpu核心2上面执行,此时数据a的状态在cup核心1和cpu核心2上面就是S(Shared)共享的,线程1执行指 “a=a+1”,此时数据 a 在 cpu 核心1中的状态就是 M(Modified)修改的,数据a在cpu核心2上面的状态就变成了I(Invalid)失效的,此时如果cpu核心2再去读取a的数据,会发现a数据的状态是Invalid,那么就会直接去内存读取。
如果数据 a,只在 cpu 核心1的高速缓存里面,而在cpu核心2的高速缓存里面没有,此时数据 a 在cpu核心1中就是E(Exclusive)独占的。cpu是怎么更新这4种状态的呢?
如果每个cpu核心都要与其他 cpu 核心交互这样的复杂度就是N2,而cpu核心不止与其他cpu核心通信还要与一些内存等等数据通信,这样复杂度会很高。
如果有一根总线,所有的 cpu 都与这根总线通信,复杂度就会降低很多,而真实的cpu的核心也是这样的,最新的Intel处理器中,有一种快速通道互联的技术(如果你是搞软件的,我觉得了解到这里就够了,没必要再去研究什么是快速通道互联技术)。
相关文章
synchronized(this) 与synchronized(class) 之间的区别

 浙公网安备 33010602011771号
浙公网安备 33010602011771号