
HTTP 1.x 学习笔记 —— Web 性能权威指南
HTTP 1.0的优化策略非常简单,就一句话:升级到HTTP 1.1。完了!
改进HTTP的性能是HTTP 1.1工作组的一个重要目标,后来这个版本也引入了大量增强性能的重要特性,其中一些大家比较熟知的有:
-
持久化连接以支持连接重用;
-
分块传输编码以支持流式响应;
-
请求管道以支持并行请求处理;
-
字节服务以支持基于范围的资源请求;
-
改进的更好的缓存机制。
当然,这些只是其中一部分,要全面讨论HTTP 1.1的所有增强特性,非得用一本书不可。同样,推荐大家买一本《HTTP权威指南》(David Gourley和Brian Totty合著)放在手边。另外,提到好的参考书,Steve Souder的《高性能网站建设指南》中概括了14条规则,有一半针对网络优化:
减少DNS查询
每次域名解析都需要一次网络往返,增加请求的延迟,在查询期间会阻塞请求。
减少HTTP请求
任何请求都不如没有请求更快,因此要去掉页面上没有必要的资源。
使用CDN
从地理上把数据放到接近客户端的地方,可以显著减少每次TCP连接的网络延迟,增加吞吐量。
添加Expires首部并配置ETag标签
相关资源应该缓存,以避免重复请求每个页面中相同的资源。Expires首部可用于指定缓存时间,在这个时间内可以直接从缓存取得资源,完全避免HTTP请求。ETag及Last-Modified首部提供了一个与缓存相关的机制,相当于最后一次更新的指纹或时间戳。
Gzip资源
所有文本资源都应该使用Gzip压缩,然后再在客户端与服务器间传输。一般来说,Gzip可以减少 60%~80% 的文件大小,也是一个相对简单(只要在服务器上配置一个选项),但优化效果较好的举措。
避免HTTP重定向
HTTP重定向极其耗时,特别是把客户端定向到一个完全不同的域名的情况下,还会导致额外的DNS查询、TCP连接延迟,等等。
上面每一条建议都经受了时间检验,无论是该书出版的2007年还是今天,都是适用的。这并不是巧合,而是因为所有这些建议都反映了两个根本方面:消除和减少不必要的网络延迟,把传输的字节数降到最少。这两个根本问题永远是优化的核心,对任何应用都有效。
可是,对所有HTTP 1.1的特性和最佳实践,我们就不能这么说了。因为有些HTTP 1.1特性,比如请求管道,由于缺乏支持而流产,而其他协议限制,比如队首响应阻塞,则导致了更多问题。为此,Web开发社区(一直都最有创造性),创造和推行了很多自造的优化手段:域名分区、连接文件、拼合图标、嵌入代码,等等,不下数十种。
对多数Web开发者而言,所有这些都是切实可行的优化手段:熟悉、必要,而且通用。可是,现实当中,我们应该对这些技术有正确的认识:它们都是些针对当前HTTP 1.1协议的局限性而采用的权宜之计。我们本来不应该操心去连接文件、拼合图标、分割域名或嵌入资源。但遗憾的是,“不应该”并不是务实的态度:这些优化手段之所以存在,都是有原因的,在背后的问题被HTTP的下一个版本解决之前,必须得依靠它们。
持久连接的优点
HTTP 1.1的一个主要改进就是引入了持久HTTP连接 。现在我们再演示一下为什么这个特性对我们的优化策略如此重要。
为简单起见,我们限定最多只有一个TCP连接,并且只取得两个小文件(每个<4 KB):一个HTML文档,一个CSS文件,服务器响应需要不同的时间(分别为40 ms和20 ms)。
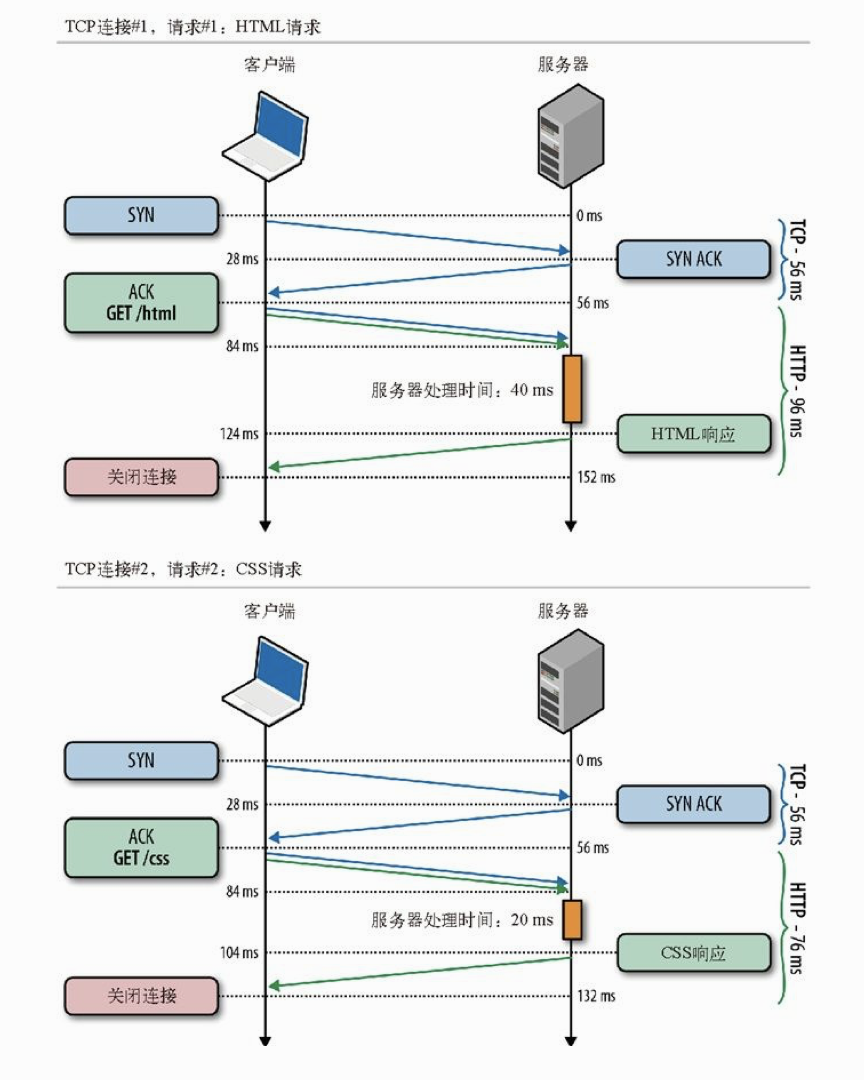
假设从纽约到伦敦的单向光纤延迟都是28 ms
每个TCP连接开始都有三次握手,要经历一次客户端与服务器间完整的往返。此后,会因为HTTP请求和响应的两次通信而至少引发另一次往返。最后,还要加上服务器处理时间,才能得到每次请求的总时间。
服务器处理时间无法预测,因为这个时间因资源和后端硬件而异。不过,这里的重点其实是由一个新TCP连接发送的HTTP请求所花的总时间,最少等于两次网络往返的时间:一次用于握手,一次用于请求和响应。这是所有非持久HTTP会话都要付出的固定时间成本。
服务器处理速度越快,固定延迟对每个网络请求总时间的影响就越大!要验证这一点,可以改一改前面例子中的往返时间和服务器处理时间。”
实际上,这时候最简单的优化就是重用底层的连接!添加对HTTP持久连接的支持,就可以避免第二次TCP连接时的三次握手、消除另一次TCP慢启动的往返,节约整整一次网络延迟。
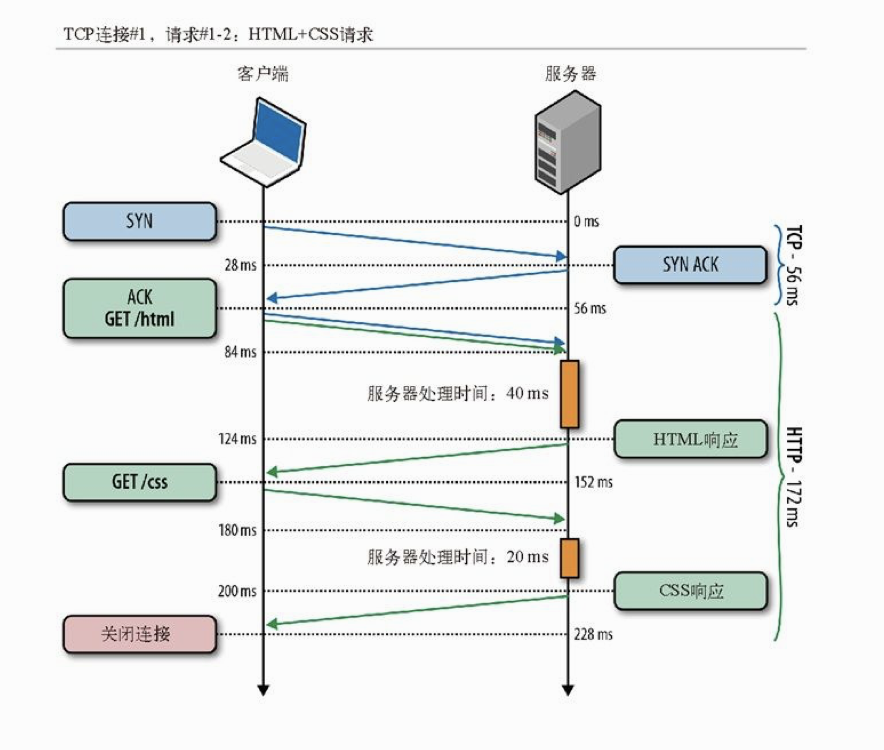
通过持久TCP连接取得HTML和CSS文件
在我们两个请求的例子中,总共只节约了一次往返时间。但是,更常见的情况是一次TCP连接要发送N 次HTTP请求,这时:
-
没有持久连接,每次请求都会导致两次往返延迟;
-
有持久连接,只有第一次请求会导致两次往返延迟,后续请求只会导致一次往返延迟。
在启用持久连接的情况下,N 次请求节省的总延迟时间就是(N -1)×RTT。还记得吗,前面说过,在当代Web应用中,N 的平均值是90,而且还在继续增加。因此,依靠持久连接节约的时间,很快就可以用秒来衡量了!这充分说明持久化HTTP是每个Web应用的关键优化手段。
HTTP管道
持久HTTP可以让我们重用已有的连接来完成多次应用请求,但多次请求必须严格满足先进先出(FIFO)的队列顺序:发送请求,等待响应完成,再发送客户端队列中的下一个请求。HTTP管道是一个很小但对上述工作流却非常重要的一次优化。管道可以让我们把
FIFO队列从客户端(请求队列)迁移到服务器(响应队列)。
要理解这样做的好处,我们再看一看通过持久TCP连接取得HTML和CSS文件示意图。首先,服务器处理完第一次请求后,会发生了一次完整的往返:先是响应回传,接着是第二次请求。在此期间服务器空闲。如果服务器能在处理完第一次请求后,立即开始处理第二次请求呢?甚至,如果服务器可以并行或在多线程上或者使用多个工作进程,同时处理两个请求呢?
通过尽早分派请求,不被每次响应阻塞,可以再次消除额外的网络往返。这样,就从非持久连接状态下的每个请求两次往返,变成了整个请求队列只需要两次网络往返!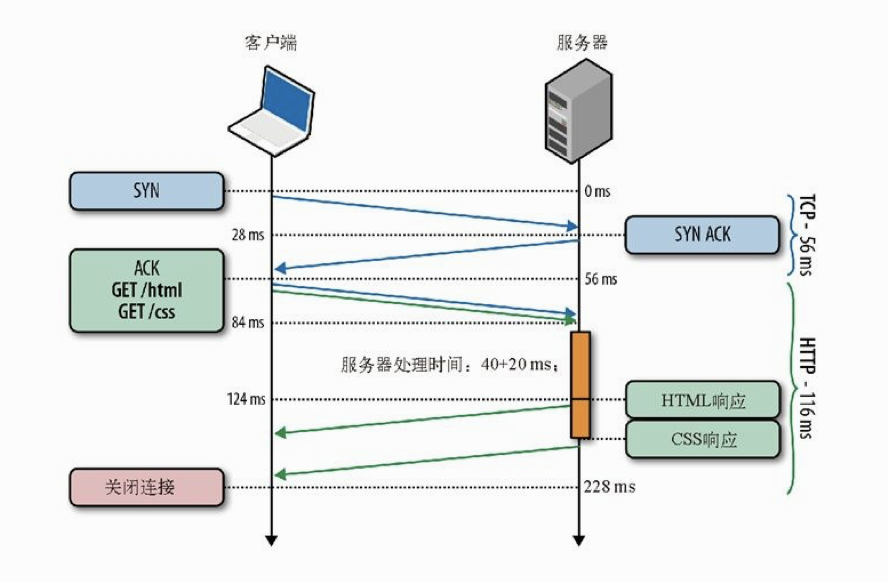
现在我们暂停一会,回顾一下在性能优化方面的收获。一开始,每个请求要用两个TCP连接,总延迟为284 ms。在使用持久连接后,避免了一次握手往返,总延迟减少为228 ms。最后,通过使用HTTP管道,又减少了两次请求之间的一次往返,总延迟减少为172 ms。这样,从284 ms到172 ms,这40%的性能提升完全拜简单的协议优化所赐。
而且,这40%的性能提升还不是固定不变的。这个数字与我们选择的网络延迟和两个请求的例子有关。希望读者自己能够尝试一些不同的情况,比如延迟更高、请求更多的情况。尝试之后,你会惊讶于性能提升效果比这里还要高得多。事实上,网络延迟越高,请求越多,节省的时间就越多。我觉得大家很有必要自己动手验证一下这个结果。因此,越是大型应用,网络优化的影响越大。
不过,这还不算完。眼光敏锐的读者可能已经发现了,我们可以在服务器上并行处理请求。理论上讲,没有障碍可以阻止服务器同时处理管道中的请求,从而再减少20 ms的延迟。
可惜的是,当我们想要采取这个优化措施时,发现了HTTP 1.x协议的一些局限性。HTTP 1.x只能严格串行地返回响应。特别是,HTTP 1.x不允许一个连接上的多个响应数据交错到达(多路复用),因而一个响应必须完全返回后,下一个响应才会开始传输。为说明这一点,我们可以看看服务器并行处理请求的情况(如下图)。
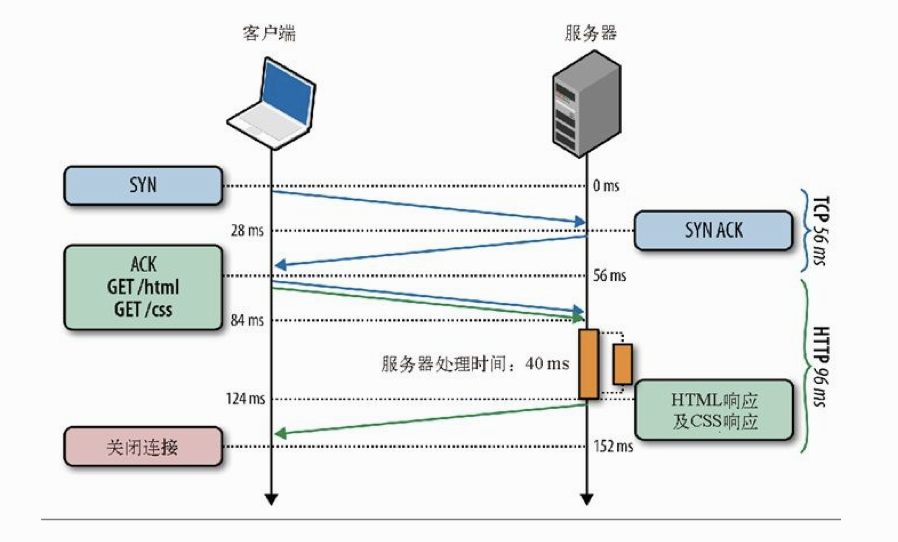
上图演示了如下几个方面:
-
HTML和CSS请求同时到达,但先处理的是HTML请求;
-
服务器并行处理两个请求,其中处理HTML用时40 ms,处理CSS用时20 ms;
-
CSS请求先处理完成,但被缓冲起来以等候发送HTML响应;
-
发送完HTML响应后,再发送服务器缓冲中的CSS响应。”
即使客户端同时发送了两个请求,而且CSS资源先准备就绪,服务器也会先发送HTML响应,然后再交付CSS。这种情况通常被称作队首阻塞 ,并经常导致次优化交付:不能充分利用网络连接,造成服务器缓冲开销,最终导致无法预测的客户端延迟。假如第一个请求无限期挂起,或者要花很长时间才能处理完,怎么办呢?在HTTP 1.1中,所有后续的请求都将被阻塞,等待它完成。
实际中,由于不可能实现多路复用,HTTP管道会导致HTTP服务器、代理和客户端出现很多微妙的,不见文档记载的问题:
-
一个慢响应就会阻塞所有后续请求;
-
并行处理请求时,服务器必须缓冲管道中的响应,从而占用服务器资源,如果有个响应非常大,则很容易形成服务器的受攻击面;
-
响应失败可能终止TCP连接,从页强迫客户端重新发送对所有后续资源的请求,导致重复处理;
-
由于可能存在中间代理,因此检测管道兼容性,确保可靠性很重要;
-
如果中间代理不支持管道,那它可能会中断连接,也可能会把所有请求串联起来。
由于存在这些以及其他类似的问题,而HTTP 1.1标准中也未对此做出说明,HTTP管道技术的应用非常有限,虽然其优点毋庸置疑。今天,一些支持管道的浏览器,通常都将其作为一个高级配置选项,但大多数浏览器都会禁用它。换句话说,如果浏览器是Web应用的主要交付工具,那还是很难指望通过HTTP管道来提升性能。
使用多个TCP连接
由于HTTP 1.x不支持多路复用,浏览器可以不假思索地在客户端排队所有HTTP请求,然后通过一个持久连接,一个接一个地发送这些请求。然而,这种方式在实践中太慢。实际上,浏览器开发商没有别的办法,只能允许我们并行打开多个TCP会话。多少个?现实中,大多数现代浏览器,包括桌面和移动浏览器,都支持每个主机打开6个连接。
进一步讨论之前,有必要先想一想同时打开多个TCP连接意味着什么。当然,有正面的也有负面的。下面我们以每个主机打开最多6个独立连接为例:
-
客户端可以并行分派最多6个请求;
-
服务器可以并行处理最多6个请求;
-
第一次往返可以发送的累计分组数量(TCP cwnd)增长为原来的6倍。
在没有管道的情况下,最大的请求数与打开的连接数相同。相应地,TCP拥塞窗口也要乘以打开的连接数量,从而允许客户端绕开由TCP慢启动规定的分组限制。这好像是一个方便的解决方案。我们再看看这样做的代价:
-
更多的套接字会占用客户端、服务器以及代理的资源,包括内存缓冲区和CPU时钟周期;
-
并行TCP流之间竞争共享的带宽;
-
由于处理多个套接字,实现复杂性更高;
-
即使并行TCP流,应用的并行能力也受限制。
实践中,CPU和内存占用并非微不足道,由此会导致客户端和服务器端的资源占用量上升,运维成本提高。类似地,由于客户端实现的复杂性提高,开发成本也会提高。最后,说到应用的并行性,这种方式提供的好处还是非常有限的。这不是一个长期的方案。了解这些之后,可以说今天之所以使用它,主要有三个原因:
-
作为绕过应用协议(HTTP)限制的一个权宜之计;
-
作为绕过TCP中低起始拥塞窗口的一个权宜之计;
-
作为让客户端绕过不能使用TCP窗口缩放”的一个权宜之计。
后两个针对TCP的问题(窗口缩放和cwnd)最好是通过升级到最新的OS内核来解决。cwnd值最近又提高到了10个分组,而所有最新的平台都能可靠地支持TCP窗口缩放。这当然是好消息。但坏消息是,没有更好办法绕开HTTP 1.x的多路复用问题。
只要必须支持HTTP 1.x客户端,就不得不想办法应对多TCP流的问题。而这又会带来一个明显的问题:为什么浏览器要规定每个主机6个连接呢?恐怕有读者也猜到了,这个数字是多方平衡的结果:这个数字越大,客户端和服务器的资源占用越多,但随之也会带来更高的请求并行能力。每个主机6个连接只不过是大家都觉得比较安全的一个数字。对某些站点而言,这个数字已经足够了,但对其他站点来说,可能还满足不了需求。
域名分区
HTTP 1.x协议的一项空白强迫浏览器开发商引入并维护着连接池,每个主机最多6个TCP流。好的一方面是对这些连接的管理工作都由浏览器来处理。作为应用开发者,你根本不必修改自己的应用。不好的一方面呢,就是6个并行的连接对你的应用来说可能仍然不够用。
根据HTTP Archive的统计,目前平均每个页面都包含90多个独立的资源,如果这些资源都来自同一个主机,那么仍然会导致明显的排队等待(如下图所示)。实际上,何必把自己只限制在一个主机上呢?我们不必只通过一个主机(例如www.example.com)提供所有资源,而是可以手工将所有资源分散到多个子域名:{shard1, shardn}.example.com。由于主机名称不一样了,就可以突破浏览器的连接限制,实现更高的并行能力。域名分区使用得越多,并行能力就越强!
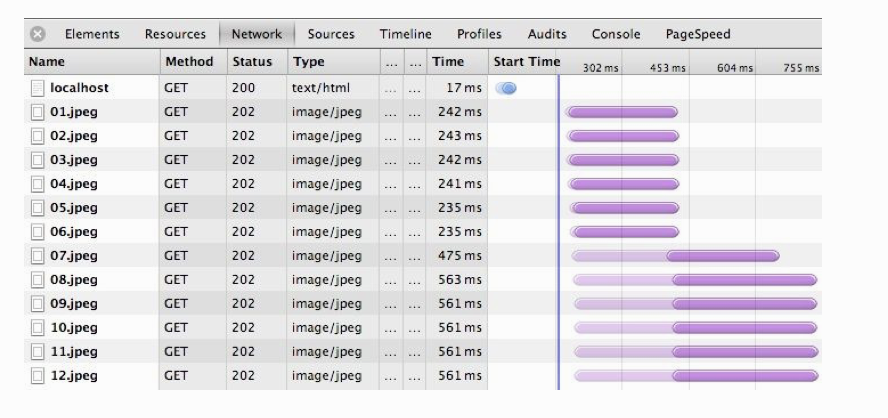
由于每个主机只能同时发起6个连接而导致的资源错列
当然,天下没有免费的午餐,域名分区也不例外:每个新主机名都要求有一次额外的DNS查询,每多一个套接字都会多消耗两端的一些资源,而更糟糕的是,站点作者必须手工分离这些资源,并分别把它们托管到多个主机上。
实践中,域名分区经常会被滥用,导致几十个TCP流都得不到充分利用,其中很多永远也避免不了TCP慢启动,最坏的情况下还会降低性能。此外,如果使用的是HTTPS,那么由于TLS握手导致的额外网络往返,会使得上述代价更高。此时,请大家注意如下几条:
-
首先,把TCP利用好;
-
浏览器会自动为你打开6个连接;
-
资源的数量、大小和响应时间都会影响最优的分区数目;”
-
客户端延迟和带宽会影响最优的分区数目;
-
域名分区会因为额外的DNS查询和TCP慢启动而影响性能。
域名分区是一种合理但又不完美的优化手段。请大家一定先从最小分区数目(不分区)开始,然后逐个增加分区并度量分区后对应用的影响。现实当中,真正因同时打开十几个连接而提升性能的站点并不多,如果你最终使用了很多分区,那么你会发现减少资源数量或者将它们合并为更少的请求,反而能带来更大的好处。
DNS查询和TCP慢启动导致的额外消耗对高延迟客户端的影响最大。换句话说,移动(3G、4G)客户端经常是受过度域名分区影响最大的!
度量和控制协议开销
HTTP 0.9当初就是一个简单的只有一行的ASCII请求,用于取得一个超文本文档,这样导致的开销是最小的。HTTP 1.0增加了请求和响应首部,以便双方能够交换有关请求和响应的元信息。最终,HTTP 1.1把这种格式变成了标准:服务器和客户端都可以轻松扩展首部,而且始终以纯文本形式发送,以保证与之前HTTP版本的兼容。
今天,每个浏览器发起的HTTP请求,都会携带额外500~800字节的HTTP元数据:用户代理字符串、很少改变的接收和传输首部、缓存指令,等等。有时候,500~800字节都少说了,因为没有包含最大的一块:HTTP cookie。现代应用经常通过cookie进行会话管理、记录个性选项或者完成分析。综合到一起,所有这些未经压缩的HTTP元数据经常会给每个HTTP请求增加几千字节的协议开销。
HTTP首部的增多对它本身不是坏事,因为大多数首部都有其特定用途。然而,由于所有HTTP首部都以纯文本形式发送(不会经过任何压缩),这就会给每个请求附加较高的额外负荷,而这在某些应用中可能造成严重的性能问题。举个例子,API驱动的Web应用越来越多,这些应用需要频繁地以序列化消息(如JSON)的形式通信。在这些应用中,额外的HTTP开销经常会超过实际传输的数据净荷一个数量级:
“$> curl --trace-ascii - -
d'{"msg":"hello"}'
http://www.igvita.com/api”
对应的结果:
== Info: Connected to www.igvita.com => Send header, 218 bytes ➊ POST /api HTTP/1.1 User-Agent: curl/7.24.0 (x86_64-apple-darwin12.0) libcurl/7.24.0 ... Host: www.igvita.com Accept: */* Content-Length: 15 ➋ Content-Type: application/x-www-form-urlencoded => Send data, 15 bytes (0xf) {"msg":"hello"} <= Recv header, 134 bytes ➌ HTTP/1.1 204 No Content Server: nginx/1.0.11 Via: HTTP/1.1 GWA Date: Thu, 20 Sep 2012 05:41:30 GMT Cache-Control: max-age=0, no-cache
-
HTTP请求首部:218字节
-
应用静荷15字节({"msg”:"hello"})
-
服务器的204响应:134字节
在前面的例子中,寥寥15个字符的JSON消息被352字节的HTTP首部包裹着,全部以纯文本形式发送——协议字节开销占96%,而且这还是没有cookie的最好情况。减少要传输的首部数据(高度重复且未压缩),可以节省相当于一次往返的延迟时间,显著提升很多Web应用的性能。
“Cookie在很多应用中都是常见的性能瓶颈,很多开发者都会忽略它给每次请求增加的额外负担。
连接与拼合
最快的请求是不用请求。不管使用什么协议,也不管是什么类型的应用,减少请求次数总是最好的性能优化手段。可是,如果你无论如何也无法减少请求,那么对HTTP 1.x而言,可以考虑把多个资源捆绑打包到一块,通过一次网络请求获取:
-
连接 :把多个JavaScript或CSS文件组合为一个文件。
-
拼合:把多张图片组合为一个更大的复合的图片。
对JavaScript和CSS来说,只要保持一定的顺序,就可以做到把多个文件连接起来而不影响代码的行为和执行。类似地,多张图片可以组合为一个“图片精灵”,然后使用CSS选择这张大图中的适当部分,显示在浏览器中。这两种技术都具备两方面的优点。
-
减少协议开销:通过把文件组合成一个资源,可以消除与文件相关的协议开销。如前所述,每个文件很容易招致KB级未压缩数据的开销。
-
应用层管道:说到传输的字节,这两种技术的效果都好像是启用了HTTP管道:来自多个响应的数据前后相继地连接在一起,消除了额外的网络延迟。实际上,就是把管道提高了一层,置入了应用中。
连接和拼合技术都属于以内容为中心的应用层优化,它们通过减少网络往返开销,可以获得明显的性能提升。可是,实现这些技术也要求额外的处理、部署和编码(比如选择图片精灵中子图的CSS代码),因而也会给应用带来额外的复杂性。此外,把多个资源打包到一块,也可能给缓存带来负担,影响页面的执行速度。
要理解为什么这些技术会伤害性能,可以考虑一种并不少见的情况:一个包含十来个JavaScript和CSS文件的应用,在产品状态下把所有文件合并为一个CSS文件和一个JavaScript文件。
-
相同类型的资源都位于一个URL(缓存键)下面。
-
资源包中可能包含当前页面不需要的内容。
-
对资源包中任何文件的更新,都要求重新下载整个资源包,导致较高的字节开销。
-
JavaScript和CSS只有在传输完成后才能被解析和执行,因而会拖慢应用的执行速度。
实践中,大多数Web应用都不是只有一个页面,而是由多个视图构成。每个视图都有自己的资源,同时资源之间还有部分重叠:公用的CSS、JavaScript和图片。实际上,把所有资源都组合到一个文件经常会导致处理和加载不必要的字节。虽然可以把它看成一种预获取,但代价则是降低了初始启动的速度。
对很多应用来说,更新资源带来的问题更大。更新图片精灵或组合JavaScript文件中的某一处,可能就会导致重新传输几百KB数据。由于牺牲了模块化和缓存粒度,假如打包资源变动频率过高,特别是在资源包过大的情况下,很快就会得不偿失。如果你的应用真到了这种境地,那么可以考虑把“稳定的核心”,比如框架和库,转移到独立的包中。
内存占用也会成为问题。对图片精灵来说,浏览器必须分析整个图片,即便实际上只显示了其中的一小块,也要始终把整个图片都保存在内存中。浏览器是不会把不显示的部分从内存中剔除掉的!
最后,为什么执行速度还会受影响呢?我们知道,浏览器是以递增方式处理HTML的,而对于JavaScript和CSS的解析及执行,则要等到整个文件下载完毕。JavaScript和CSS处理器都不允许递增式执行。
CSS和JavaScript文件大小与执行性能
CSS文件越大,浏览器在构建CSSOM前经历的阻塞时间就越长,从而推迟首次绘制页面的时间。类似地,JavaScript文件越大,对执行速度的影响同样越大;小文件倒是能实现“递增式”执行。打包文件到底多大合适呢?可惜的是,没有理想的大小。然而,谷歌PageSpeed团队的测试表明,30~50 KB(压缩后)是每个JavaScript文件大小的合适范围:既大到了能够减少小文件带来的网络延迟,还能确保递增及分层式的执行。具体的结果可能会由于应用类型和脚本数量而有所不同。
总之,连接和拼合是在HTTP 1.x协议限制(管道没有得到普遍支持,多请求开销大)的现实之下可行的应用层优化。使用得当的话,这两种技术可以带来明显的性能提升,代价则是增加应用的复杂度,以及导致缓存、更新、执行速度,甚至渲染页面的问题。应用这两种优化时,要注意度量结果,根据实际情况考虑如下问题。
-
你的应用在下载很多小型的资源时是否会被阻塞?
-
有选择地组合一些请求对你的应用有没有好处?
-
放弃缓存粒度对用户有没有负面影响?
-
组合图片是否会占用过多内存?
-
首次渲染时是否会遭遇延迟执行?
在上述问题的答案间求得平衡是一种艺术。
嵌入资源
嵌入资源是另一种非常流行的优化方法,把资源嵌入文档可以减少请求的次数。比如,JavaScript和CSS代码,通过适当的script 和style 块可以直接放在页面中,而图片甚至音频或PDF文件,都可以通过数据URI(data:[mediatype][;base64],data )的方式嵌入到页面中:
<img src="data:image/gif;base64,R0lGODlhAQABAIAAAAA AAAAAACH5BAAAAAAALAAAAAABAAEAAAICTAEAOw==" alt="1x1 transparent (GIF) pixel" />
数据URI适合特别小的,理想情况下,最好是只用一次的资源。以嵌入方式放到页面中的资源,应该算是页面的一部分,不能被浏览器、CDN或其他缓存代理作为单独的资源缓存。换句话说,如果在多个页面中都嵌入同样的资源,那么这个资源将会随着每个页面的加载而被加载,从而增大每个页面的总体大小。另外,如果嵌入资源被更新,那么所有以前出现过它的页面都将被宣告无效,而由客户端重新从服务器获取。
最后,虽然CSS和JavaScript等基于文本的资源很容易直接嵌入页面,也不会带来多余的开销,但非文本性资源则必须通过base64编码,而这会导致开销明显增大:编码后的资源大小比原大小增大33%!
base64编码使用64个ASCII符号和空白符将任意字节流编码为ASCII字符串。编码过程中,base64会导致被编码的流变成原来的4/3,即增大33%的字节开销。
实践中,常见的一个经验规则是只考虑嵌入1~2 KB以下的资源,因为小于这个标准的资源经常会导致比它自身更高的HTTP开销。然而,如果嵌入的资源频繁变更,又会导致宿主文档的无效缓存率升高。嵌入资源也不是完美的方法。如果你的应用要使用很小的、个别的文件,在考虑是否嵌入时,可以参照如下建议:
-
如果文件很小,而且只有个别页面使用,可以考虑嵌入;
-
如果文件很小,但需要在多个页面中重用,应该考虑集中打包;
-
如果小文件经常需要更新,就不要嵌入了;
-
通过减少HTTP cookie的大小将协议开销最小化。
关于 HTTP 系列文章:
-
HTTP 概述
-
TCP 三次握手和四次挥手图解(有限状态机)
-
从你输入网址,到看到网页——详解中间发生的过程
-
深入浅出 HTTPS (详解版)
-
漫谈 HTTP 连接
-
漫谈 HTTP 性能优化
-
HTTP 报文格式简介
-
深入浅出:HTTP/2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号