
快速读懂 HTTP/3 协议
在 深入浅出:HTTP/2 一文中详细介绍了 HTTP/2 新的特性,比如头部压缩、二进制分帧、虚拟的“流”与多路复用,性能方面比 HTTP/1 有了很大的提升。与所有性能优化过程一样,去掉一个性能瓶颈,又会带来新的瓶颈。对HTTP 2.0而言,TCP 很可能就是下一个性能瓶颈。这也是为什么服务器端TCP配置对HTTP 2.0至关重要的一个原因。”
TCP 的限制
HTTP/3功能的核心是围绕着底层的QUIC协议来实现的。在讨论QUIC和UDP之前,我们有必要先列出TCP的某些限制,这也是导致QUIC发展的原因。
TCP可能会间歇性地挂起数据传输
如果一个序列号较低的数据段还没有接收到,即使其他序列号较高的段已经接收到,TCP的接收机滑动窗口也不会继续处理。这将导致TCP流瞬间挂起,在更糟糕的情况下,即使所有的段中有一个没有收到,也会导致关闭连接。这个问题被称为TCP流的行头阻塞(HoL)。

TCP不支持流级复用
虽然TCP确实允许在应用层之间建立多个逻辑连接,但它不允许在一个TCP流中复用数据包。使用HTTP/2时,浏览器只能与服务器打开一个TCP连接,并使用同一个连接来请求多个对象,如CSS、JavaScript等文件。在接收这些对象的同时,TCP会将所有对象序列化在同一个流中。因此,它不知道TCP段的对象级分区。
TCP会产生冗余通信
TCP连接握手会有冗余的消息交换序列,即使是与已知主机建立的连接也是如此。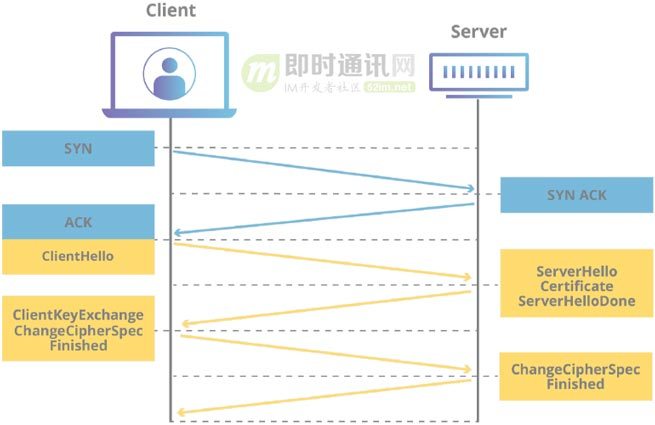
QUIC 协议
这里先贴一下 HTTP/3 的协议栈图,让你对它有个大概的了解。

QUIC协议在以下设计选择的基础上,通过引入一些底层传输机制的改变,解决了这些问题。
- 1)选择UDP作为底层传输层协议:在TCP之上建立新的传输机制,将继承TCP的上述所有缺点。因此,UDP是一个明智的选择。此外,QUIC是在用户层构建的,所以不需要每次协议升级时进行内核修改。
- 2)流复用和流控:QUIC引入了连接上的多路流复用的概念。QUIC通过设计实现了单独的、针对每个流的流控,解决了整个连接的行头阻塞问题。

- 3)灵活的拥塞控制机制:TCP的拥塞控制机制是刚性的。该协议每次检测到拥塞时,都会将拥塞窗口大小减少一半。相比之下,QUIC的拥塞控制设计得更加灵活,可以更有效地利用可用的网络带宽,从而获得更好的吞吐量。
- 4)更好的错误处理能力:QUIC使用增强的丢失恢复机制和转发纠错功能,以更好地处理错误数据包。该功能对于那些只能通过缓慢的无线网络访问互联网的用户来说是一个福音,因为这些网络用户在传输过程中经常出现高错误率。
-
5)更快的握手:QUIC使用相同的TLS模块进行安全连接。然而,与TCP不同的是,QUIC的握手机制经过优化,避免了每次两个已知的对等者之间建立通信时的冗余协议交换。

通过在QUIC之上构建基于HTTP/3的应用层,您可以获得增强型传输机制的所有优势,同时保留HTTP/2的语法和语义。但是,你也必须注意到,HTTP/2不能直接与QUIC集成,因为从应用到传输的底层帧映射是不兼容的。因此,IETF的HTTP工作组建议将HTTP/3作为新的HTTP版本,并根据QUIC协议的帧格式要求修改了帧映射。
除此之外,HTTP/3还使用了一种新的HTTP头压缩机制,称为QPACK,是对HTTP/2中使用的HPACK的增强。在QPACK下,HTTP头可以在不同的QUIC流中不按顺序到达。与HTTP/2中的TCP确保数据包的按顺序传递不同,QUIC流是不按顺序传递的,在不同的流中可能包含不同的HTTP头。因此,QPACK使用查找表机制对报头进行编码和解码。
因此想要了解 HTTP/3,QUIC 是绕不过去的,下面主要通过几个重要的特性让大家对 QUIC 有更深的理解。
QUIC 的特点
零 RTT 建立连接
用一张图可以形象地看出 HTTP/2 和 HTTP/3 建立连接的差别。
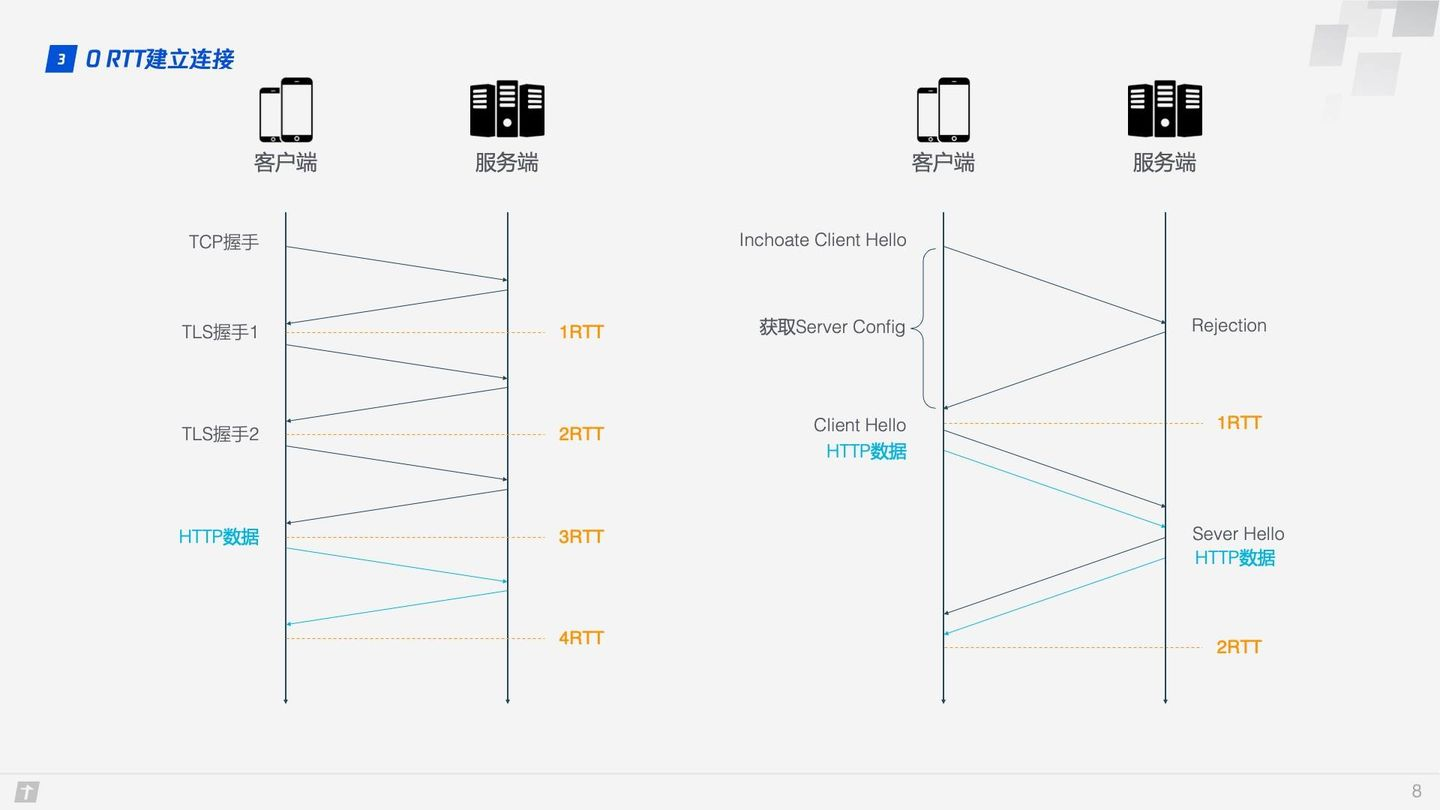
HTTP/2 的连接需要 3 RTT,如果考虑会话复用,即把第一次握手算出来的对称密钥缓存起来,那么也需要 2 RTT,更进一步的,如果 TLS 升级到 1.3,那么 HTTP/2 连接需要 2 RTT,考虑会话复用则需要 1 RTT。有人会说 HTTP/2 不一定需要 HTTPS,握手过程还可以简化。这没毛病,HTTP/2 的标准的确不需要基于 HTTPS,但实际上所有浏览器的实现都要求 HTTP/2 必须基于 HTTPS,所以 HTTP/2 的加密连接必不可少。而 HTTP/3 首次连接只需要 1 RTT,后面的连接更是只需 0 RTT,意味着客户端发给服务端的第一个包就带有请求数据,这一点 HTTP/2 难以望其项背。那这背后是什么原理呢?我们具体看下 QUIC 的连接过程。
-
Step1:首次连接时,客户端发送 Inchoate Client Hello 给服务端,用于请求连接;
-
Step2:服务端生成 g、p、a,根据 g、p 和 a 算出 A,然后将 g、p、A 放到 Server Config 中再发送 Rejection 消息给客户端;
-
Step3:客户端接收到 g、p、A 后,自己再生成 b,根据 g、p、b 算出 B,根据 A、p、b 算出初始密钥 K。B 和 K 算好后,客户端会用 K 加密 HTTP 数据,连同 B 一起发送给服务端;
-
Step4:服务端接收到 B 后,根据 a、p、B 生成与客户端同样的密钥,再用这密钥解密收到的 HTTP 数据。为了进一步的安全(前向安全性),服务端会更新自己的随机数 a 和公钥,再生成新的密钥 S,然后把公钥通过 Server Hello 发送给客户端。连同 Server Hello 消息,还有 HTTP 返回数据;
-
Step5:客户端收到 Server Hello 后,生成与服务端一致的新密钥 S,后面的传输都使用 S 加密。
这样,QUIC 从请求连接到正式接发 HTTP 数据一共花了 1 RTT,这 1 个 RTT 主要是为了获取 Server Config,后面的连接如果客户端缓存了 Server Config,那么就可以直接发送 HTTP 数据,实现 0 RTT 建立连接。

这里使用的是 DH 密钥交换算法,DH 算法的核心就是服务端生成 a、g、p 3 个随机数,a 自己持有,g 和 p 要传输给客户端,而客户端会生成 b 这 1 个随机数,通过 DH 算法客户端和服务端可以算出同样的密钥。在这过程中 a 和 b 并不参与网络传输,安全性大大提高。因为 p 和 g 是大数,所以即使在网络中传输的 p、g、A、B 都被劫持,那么靠现在的计算机算力也没法破解密钥。
连接迁移
TCP 连接基于四元组(源 IP、源端口、目的 IP、目的端口),切换网络时至少会有一个因素发生变化,导致连接发生变化。当连接发生变化时,如果还使用原来的 TCP 连接,则会导致连接失败,就得等原来的连接超时后重新建立连接,所以我们有时候发现切换到一个新网络时,即使新网络状况良好,但内容还是需要加载很久。如果实现得好,当检测到网络变化时立刻建立新的 TCP 连接,即使这样,建立新的连接还是需要几百毫秒的时间。
QUIC 的连接不受四元组的影响,当这四个元素发生变化时,原连接依然维持。那这是怎么做到的呢?道理很简单,QUIC 连接不以四元组作为标识,而是使用一个 64 位的随机数,这个随机数被称为 Connection ID,即使 IP 或者端口发生变化,只要 Connection ID 没有变化,那么连接依然可以维持。

队头阻塞/多路复用
HTTP/1.1 和 HTTP/2 都存在队头阻塞问题(Head of line blocking),那什么是队头阻塞呢?
TCP 是个面向连接的协议,即发送请求后需要收到 ACK 消息,以确认对方已接收到数据。如果每次请求都要在收到上次请求的 ACK 消息后再请求,那么效率无疑很低。后来 HTTP/1.1 提出了 Pipelining 技术,允许一个 TCP 连接同时发送多个请求,这样就大大提升了传输效率。

在这个背景下,下面就来谈 HTTP/1.1 的队头阻塞。下图中,一个 TCP 连接同时传输 10 个请求,其中第 1、2、3 个请求已被客户端接收,但第 4 个请求丢失,那么后面第 5 - 10 个请求都被阻塞,需要等第 4 个请求处理完毕才能被处理,这样就浪费了带宽资源。
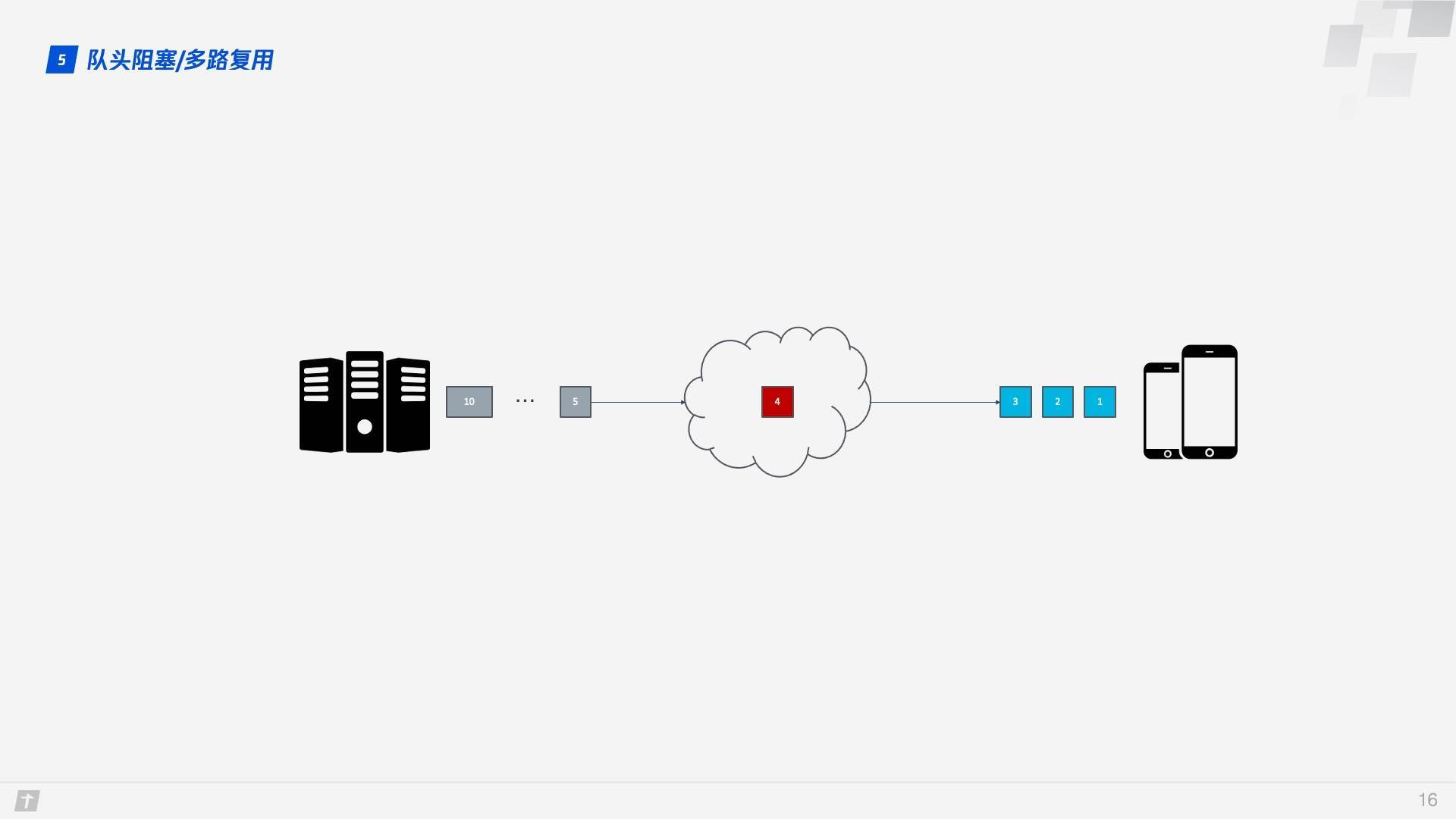
因此,HTTP 一般又允许每个主机建立 6 个 TCP 连接,这样可以更加充分地利用带宽资源,但每个连接中队头阻塞的问题还是存在。
HTTP/2 的多路复用解决了上述的队头阻塞问题。不像 HTTP/1.1 中只有上一个请求的所有数据包被传输完毕下一个请求的数据包才可以被传输,HTTP/2 中每个请求都被拆分成多个 Frame 通过一条 TCP 连接同时被传输,这样即使一个请求被阻塞,也不会影响其他的请求。如下图所示,不同颜色代表不同的请求,相同颜色的色块代表请求被切分的 Frame。
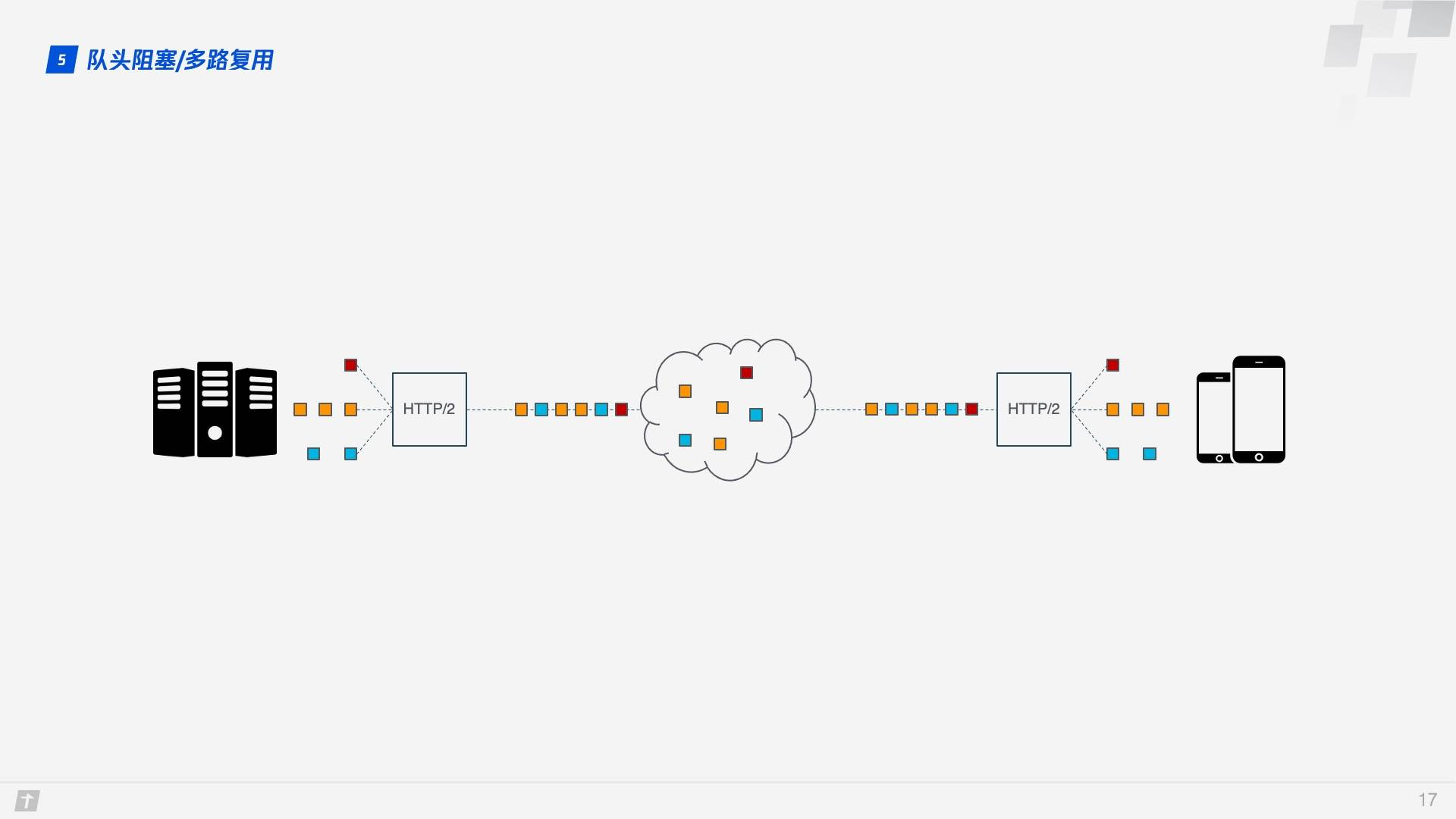
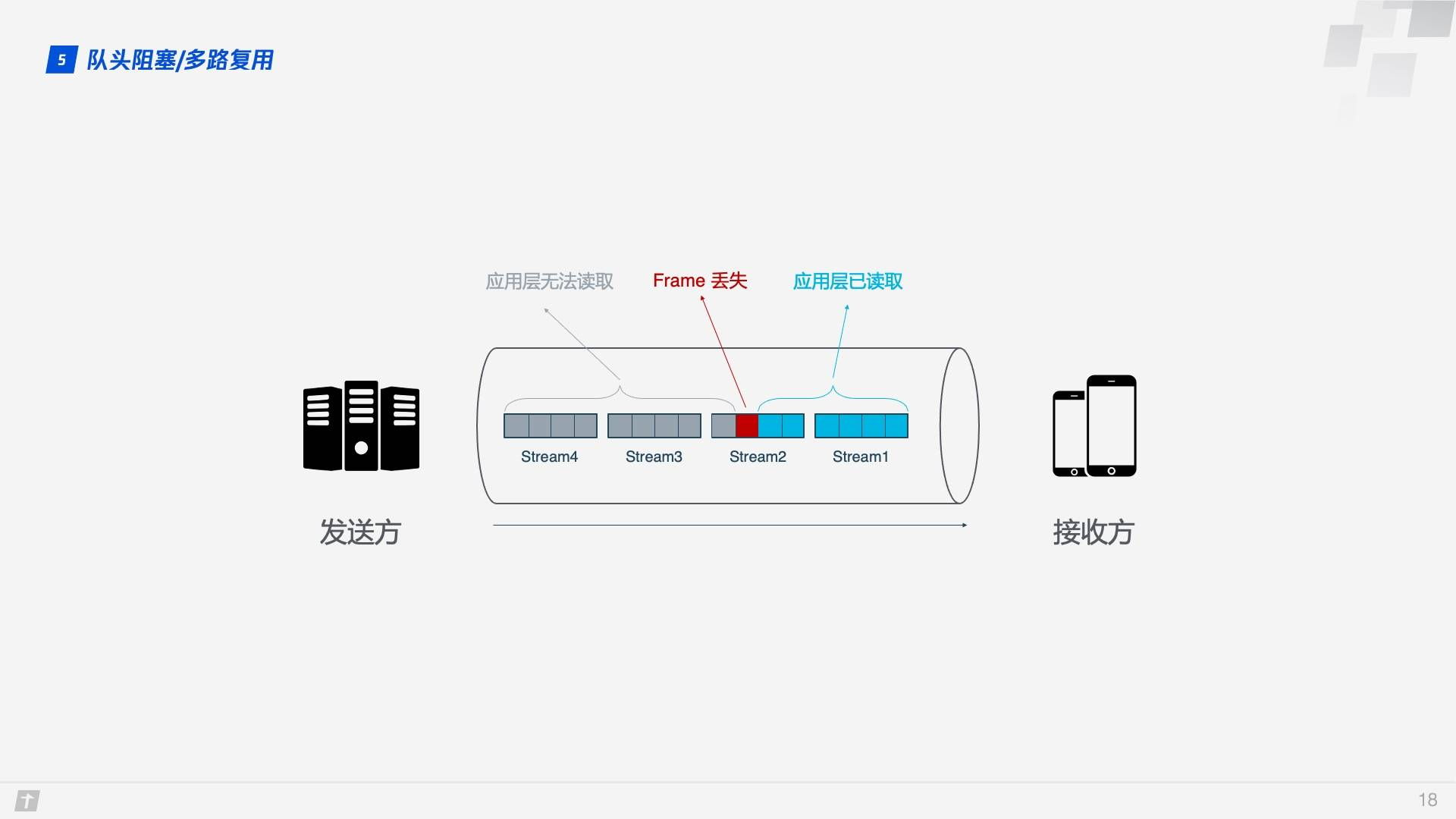
事情还没完,HTTP/2 虽然可以解决“请求”这个粒度的阻塞,但 HTTP/2 的基础 TCP 协议本身却也存在着队头阻塞的问题。HTTP/2 的每个请求都会被拆分成多个 Frame,不同请求的 Frame 组合成 Stream,Stream 是 TCP 上的逻辑传输单元,这样 HTTP/2 就达到了一条连接同时发送多条请求的目标,这就是多路复用的原理。我们看一个例子,在一条 TCP 连接上同时发送 4 个 Stream,其中 Stream1 已正确送达,Stream2 中的第 3 个 Frame 丢失,TCP 处理数据时有严格的前后顺序,先发送的 Frame 要先被处理,这样就会要求发送方重新发送第 3 个 Frame,Stream3 和 Stream4 虽然已到达但却不能被处理,那么这时整条连接都被阻塞。
不仅如此,由于 HTTP/2 必须使用 HTTPS,而 HTTPS 使用的 TLS 协议也存在队头阻塞问题。TLS 基于 Record 组织数据,将一堆数据放在一起(即一个 Record)加密,加密完后又拆分成多个 TCP 包传输。一般每个 Record 16K,包含 12 个 TCP 包,这样如果 12 个 TCP 包中有任何一个包丢失,那么整个 Record 都无法解密。
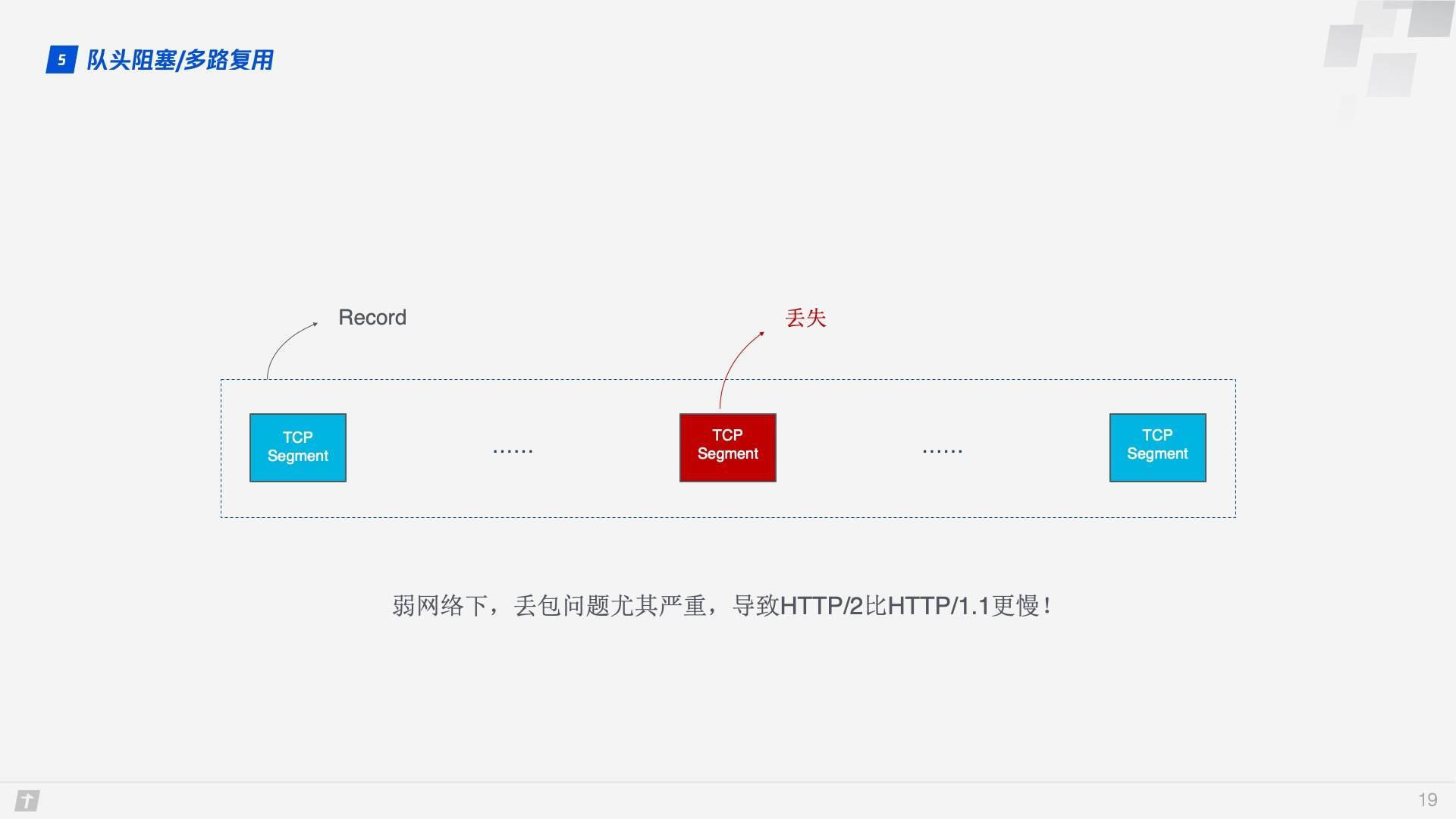
队头阻塞会导致 HTTP/2 在更容易丢包的弱网络环境下比 HTTP/1.1 更慢!
那 QUIC 是如何解决队头阻塞问题的呢?主要有两点。
-
QUIC 的传输单元是 Packet,加密单元也是 Packet,整个加密、传输、解密都基于 Packet,这样就能避免 TLS 的队头阻塞问题;
-
QUIC 基于 UDP,UDP 的数据包在接收端没有处理顺序,即使中间丢失一个包,也不会阻塞整条连接,其他的资源会被正常处理。

拥塞控制
拥塞控制的目的是避免过多的数据一下子涌入网络,导致网络超出最大负荷。QUIC 的拥塞控制与 TCP 类似,并在此基础上做了改进。所以我们先简单介绍下 TCP 的拥塞控制。
TCP 拥塞控制由 4 个核心算法组成:慢启动、拥塞避免、快速重传和快速恢复,理解了这 4 个算法,对 TCP 的拥塞控制也就有了大概了解。
-
慢启动:发送方向接收方发送 1 个单位的数据,收到对方确认后会发送 2 个单位的数据,然后依次是 4 个、8 个……呈指数级增长,这个过程就是在不断试探网络的拥塞程度,超出阈值则会导致网络拥塞;
-
拥塞避免:指数增长不可能是无限的,到达某个限制(慢启动阈值)之后,指数增长变为线性增长;
-
快速重传:发送方每一次发送时都会设置一个超时计时器,超时后即认为丢失,需要重发;
-
快速恢复:在上面快速重传的基础上,发送方重新发送数据时,也会启动一个超时定时器,如果收到确认消息则进入拥塞避免阶段,如果仍然超时,则回到慢启动阶段。
QUIC 重新实现了 TCP 协议的 Cubic 算法进行拥塞控制,并在此基础上做了不少改进。下面介绍一些 QUIC 改进的拥塞控制的特性。
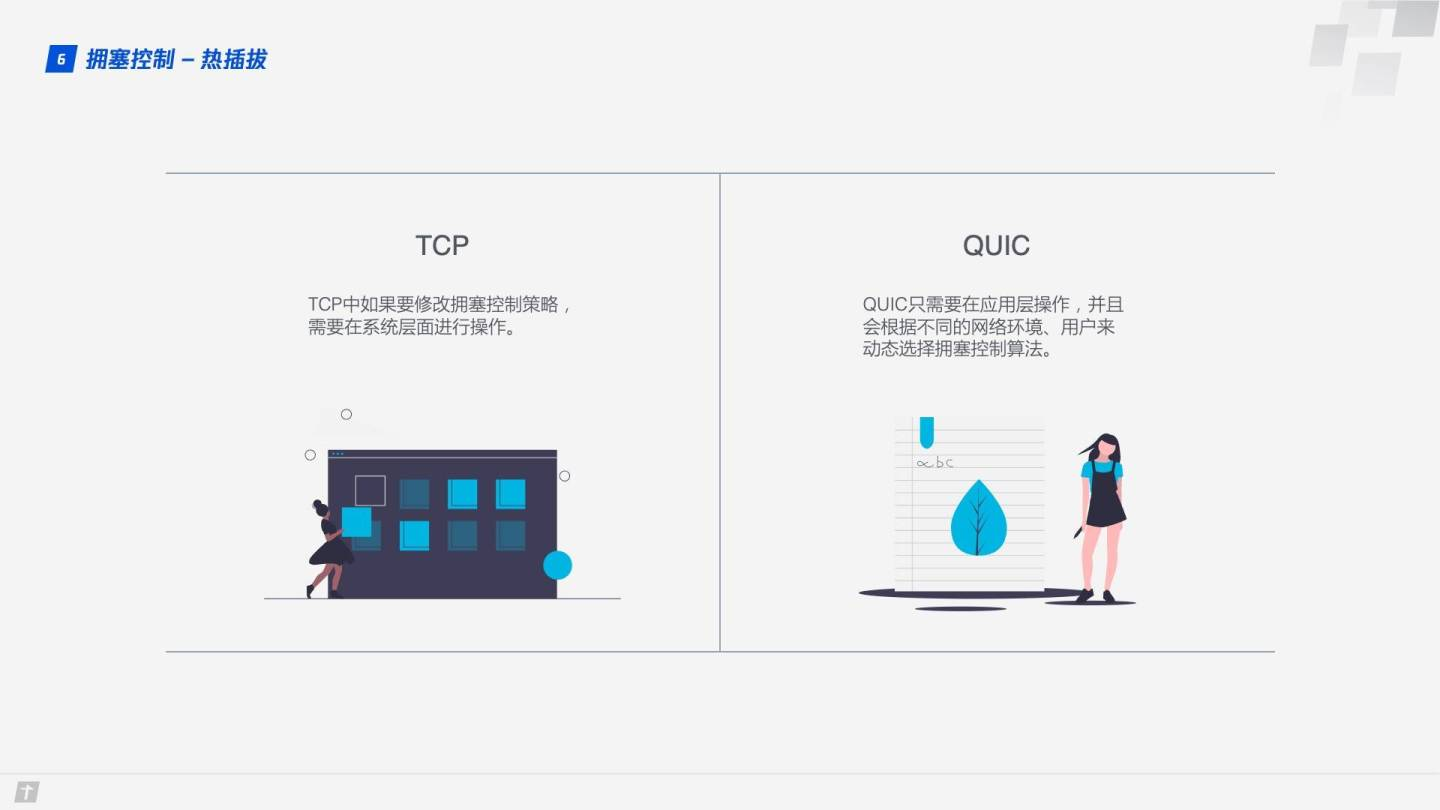
热插拔
TCP 中如果要修改拥塞控制策略,需要在系统层面进行操作。QUIC 修改拥塞控制策略只需要在应用层操作,并且 QUIC 会根据不同的网络环境、用户来动态选择拥塞控制算法
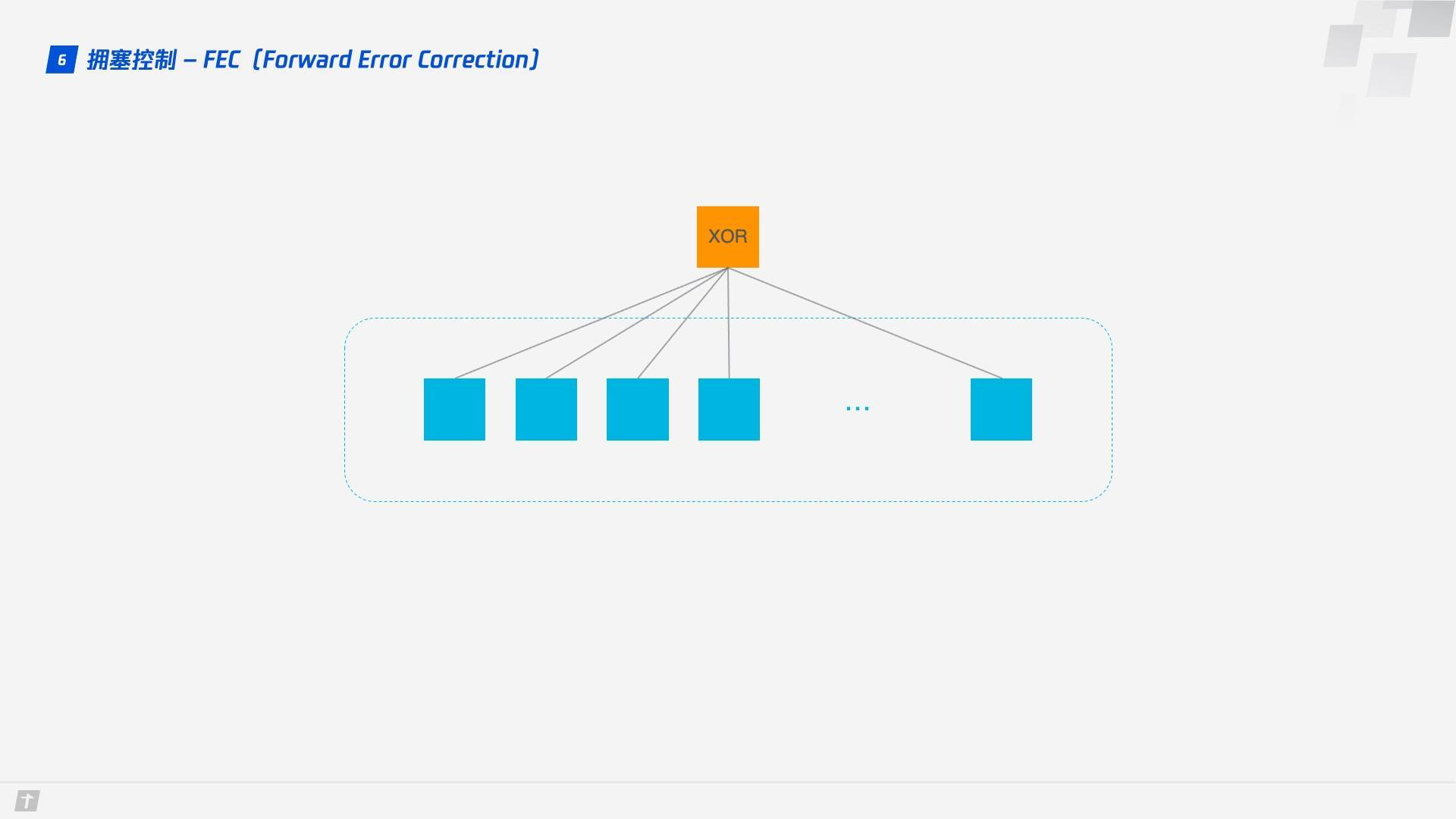
前向纠错 FEC
QUIC 使用前向纠错(FEC,Forward Error Correction)技术增加协议的容错性。一段数据被切分为 10 个包后,依次对每个包进行异或运算,运算结果会作为 FEC 包与数据包一起被传输,如果不幸在传输过程中有一个数据包丢失,那么就可以根据剩余 9 个包以及 FEC 包推算出丢失的那个包的数据,这样就大大增加了协议的容错性。
这是符合现阶段网络技术的一种方案,现阶段带宽已经不是网络传输的瓶颈,往返时间才是,所以新的网络传输协议可以适当增加数据冗余,减少重传操作。
单调递增的 Packet Number
TCP 为了保证可靠性,使用 Sequence Number 和 ACK 来确认消息是否有序到达,但这样的设计存在缺陷。
超时发生后客户端发起重传,后来接收到了 ACK 确认消息,但因为原始请求和重传请求接收到的 ACK 消息一样,所以客户端就郁闷了,不知道这个 ACK 对应的是原始请求还是重传请求。如果客户端认为是原始请求的 ACK,但实际上是左图的情形,则计算的采样 RTT 偏大;如果客户端认为是重传请求的 ACK,但实际上是右图的情形,又会导致采样 RTT 偏小。图中有几个术语,RTO 是指超时重传时间(Retransmission TimeOut),跟我们熟悉的 RTT(Round Trip Time,往返时间)很长得很像。采样 RTT 会影响 RTO 计算,超时时间的准确把握很重要,长了短了都不合适。
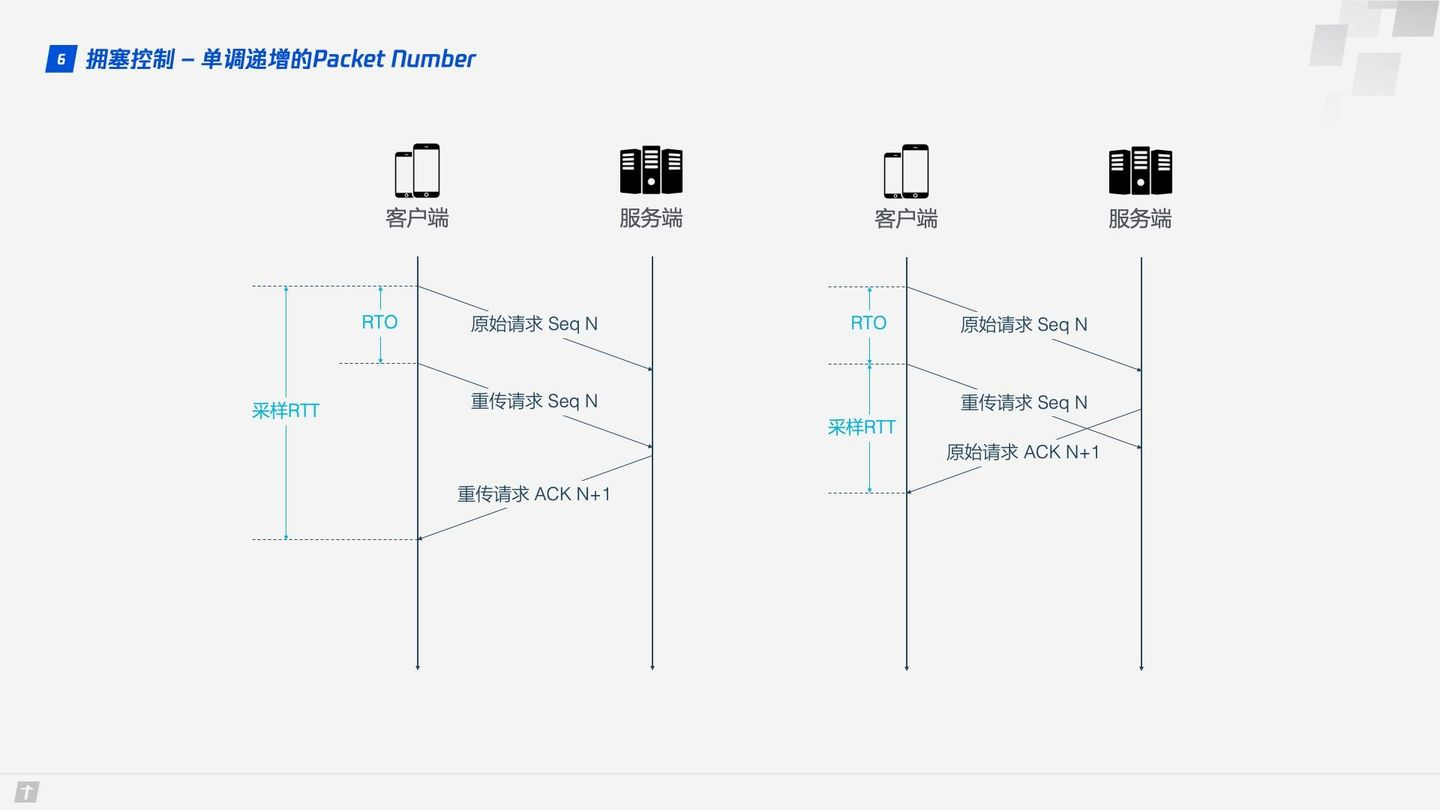
QUIC 解决了上面的歧义问题。与 Sequence Number 不同的是,Packet Number 严格单调递增,如果 Packet N 丢失了,那么重传时 Packet 的标识不会是 N,而是比 N 大的数字,比如 N + M,这样发送方接收到确认消息时就能方便地知道 ACK 对应的是原始请求还是重传请求。

ACK Delay
TCP 计算 RTT 时没有考虑接收方接收到数据到发送确认消息之间的延迟,如下图所示,这段延迟即 ACK Delay。QUIC 考虑了这段延迟,使得 RTT 的计算更加准确。

更多的 ACK 块
一般来说,接收方收到发送方的消息后都应该发送一个 ACK 回复,表示收到了数据。但每收到一个数据就返回一个 ACK 回复太麻烦,所以一般不会立即回复,而是接收到多个数据后再回复,TCP SACK 最多提供 3 个 ACK block。但有些场景下,比如下载,只需要服务器返回数据就好,但按照 TCP 的设计,每收到 3 个数据包就要“礼貌性”地返回一个 ACK。而 QUIC 最多可以捎带 256 个 ACK block。在丢包率比较严重的网络下,更多的 ACK block 可以减少重传量,提升网络效率。

流量控制
TCP 会对每个 TCP 连接进行流量控制,流量控制的意思是让发送方不要发送太快,要让接收方来得及接收,不然会导致数据溢出而丢失,TCP 的流量控制主要通过滑动窗口来实现的。可以看出,拥塞控制主要是控制发送方的发送策略,但没有考虑到接收方的接收能力,流量控制是对这部分能力的补齐。
QUIC 只需要建立一条连接,在这条连接上同时传输多条 Stream,好比有一条道路,两头分别有一个仓库,道路中有很多车辆运送物资。QUIC 的流量控制有两个级别:连接级别(Connection Level)和 Stream 级别(Stream Level),好比既要控制这条路的总流量,不要一下子很多车辆涌进来,货物来不及处理,也不能一个车辆一下子运送很多货物,这样货物也来不及处理。
那 QUIC 是怎么实现流量控制的呢?我们先看单条 Stream 的流量控制。Stream 还没传输数据时,接收窗口(flow control receive window)就是最大接收窗口(flow control receive window),随着接收方接收到数据后,接收窗口不断缩小。在接收到的数据中,有的数据已被处理,而有的数据还没来得及被处理。如下图所示,蓝色块表示已处理数据,黄色块表示未处理数据,这部分数据的到来,使得 Stream 的接收窗口缩小。
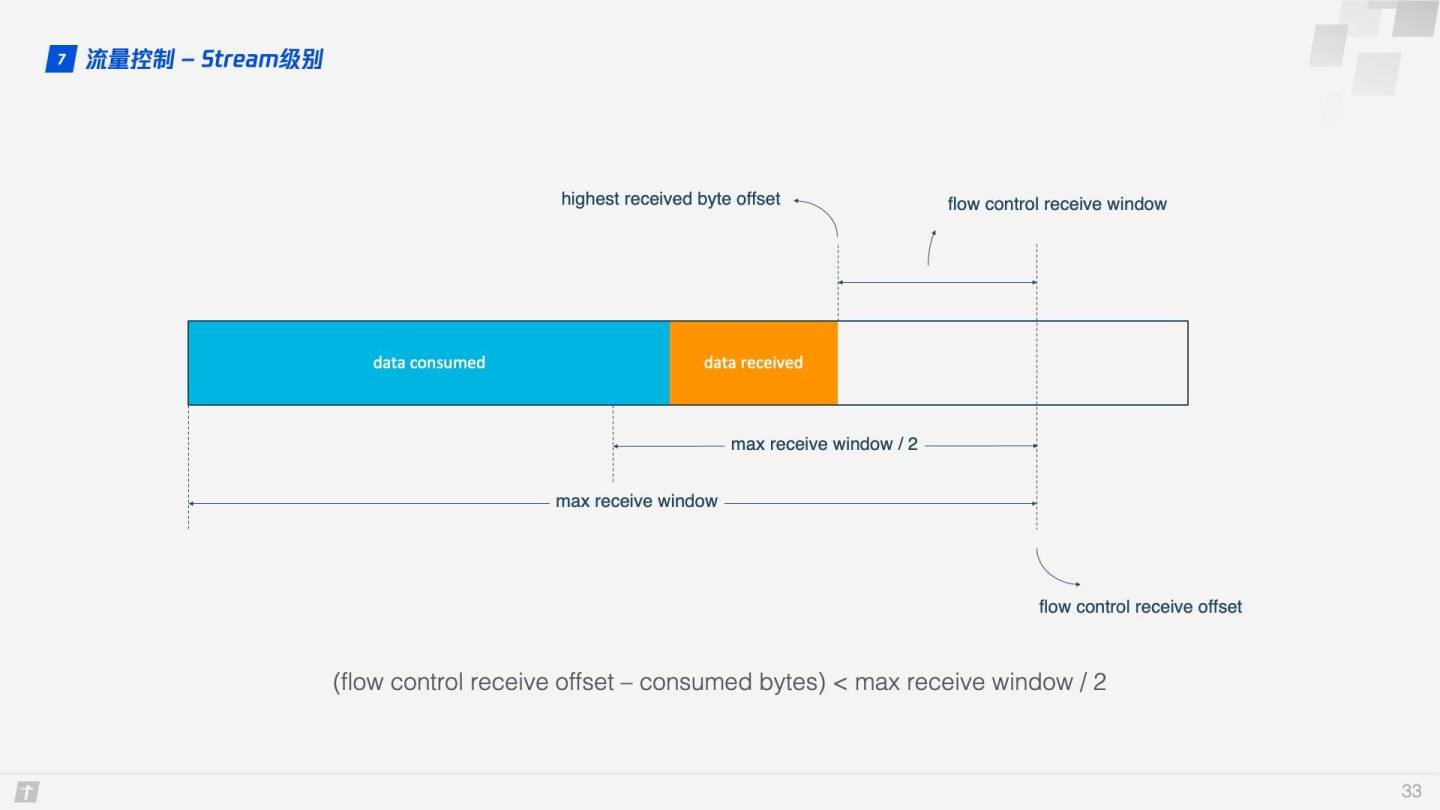
随着数据不断被处理,接收方就有能力处理更多数据。当满足 (flow control receive offset - consumed bytes) < (max receive window / 2) 时,接收方会发送 WINDOW_UPDATE frame 告诉发送方你可以再多发送些数据过来。这时 flow control receive offset 就会偏移,接收窗口增大,发送方可以发送更多数据到接收方。

Stream 级别对防止接收端接收过多数据作用有限,更需要借助 Connection 级别的流量控制。理解了 Stream 流量那么也很好理解 Connection 流控。Stream 中,接收窗口(flow control receive window) = 最大接收窗口(max receive window) - 已接收数据(highest received byte offset) ,而对 Connection 来说:接收窗口 = Stream1 接收窗口 + Stream2 接收窗口 + ... + StreamN 接收窗口 。
为什么HTTP/3很重要?
TCP已经有40多年的历史了。它在1981年通过RFC 793从而标准化。多年来,它经历了多次更新,是一个非常强大的传输协议,可以支持互联网流量的增长。然而,由于设计上的原因,TCP从来就不适合处理有损无线环境中的数据传输。在互联网的早期,有线网络将网络中的每一台计算机连接起来。
现在,随着智能手机和便携式设备的数量超过台式机和笔记本电脑的数量,超过50%的互联网流量已经通过无线传输。这种趋势给整体的网络浏览体验带来了问题,其中最重要的是在无线覆盖率不足的情况下,TCP中的行头阻塞(关于TCP在移动网络下的不足,请阅读《5G时代已经到来,TCP/IP老矣,尚能饭否?》)。
Google的一些初步实验证明,QUIC作为Google部分热门服务的底层传输协议,极大地提高了速度和用户体验。部署QUIC作为YouTube视频的底层传输协议,导致YouTube视频流的缓冲率下降了30%,这直接影响了用户的视频观看体验。在显示谷歌搜索结果时,也有类似的改善。
网络条件较差的情况下提升非常明显,这促使谷歌更加积极地完善该协议,并最终向IETF提出标准化。
由于这些早期的试验所带来的所有改进,QUIC已经成为带领万维网走向未来的重要因素。在QUIC的支持下,HTTP从HTTP/2到HTTP/3的改头换面,朝着这个方向合理地迈出了一步。
HTTP/3 的局限性
过渡到HTTP/3不仅涉及到应用层的变化,还涉及到底层传输层的变化。因此,与它的前身HTTP/2相比,HTTP/3的采用更具挑战性,因为后者只需要改变应用层。传输层承受着网络中的大量中间层审查。这些中间层,如防火墙、代理、NAT设备等会进行大量的深度数据包检查,以满足其功能需求。因此,新的传输机制的引入对IT基础设施和运维团队来说有一些影响。
然而,HTTP/3被广泛采用的另一个问题是,它是基于QUIC的,在UDP上运行。大多数的Web流量,以及IETF定义的知名服务都是在TCP之上运行的。这也是为什么长时间运行HTTP/3的UDP会话会被防火墙的默认数据包过滤策略所影响的原因。
随着IETF正在进行的标准化工作,这些问题最终都会得到解决。此外,考虑到Google在早期QUIC实验所显示的积极结果,人们对HTTP/3的支持是压倒性的,这将最终迫使中间层厂商标准化。
针对受限的IoT设备,HTTP/3由于过于繁琐从而无法采用。许多IoT应用部署的设备的外形尺寸非常小。因此,它们的RAM和CPU功率都是有限的。为了使设备在电池功率、低比特率和有损连接等限制条件下高效运行,必须执行此要求。HTTP/3在现有的UDP之上,以QUIC的形式在传输层处理,增加了HTTP/3在整个协议栈中的占用空间。这使得HTTP/3较为笨重,不适合那些IoT设备。但这种情况很少出现,而且存在专门的协议,这就避免了直接在此类设备上支持HTTP的需要。此外,还有以物联网为核心的协议,如MQTT。
附、TCP 队头阻塞
事实证明,HTTP/2 只解决了 HTTP 级别的队头阻塞,我们可以称之为“应用层”队头阻塞。然而,在典型的网络模型中,还需要考虑下面的其他层。您可以在图6中清楚地看到这一点:
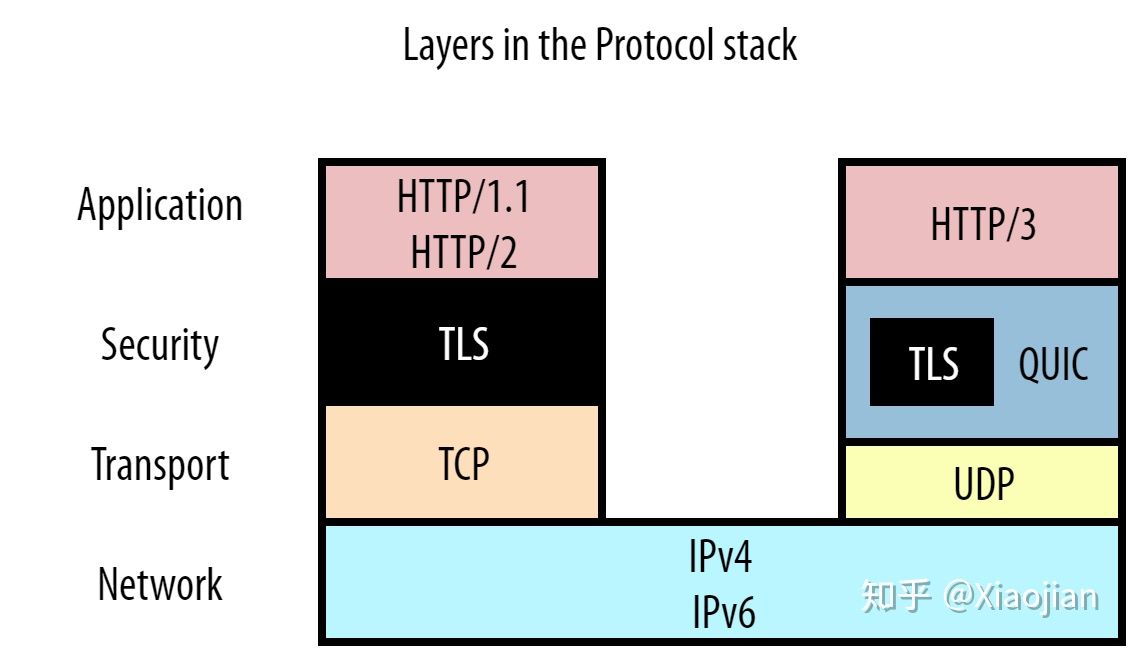
图6:典型网络模型中的几个协议层
HTTP 位于顶层,但首先由安全层的 TLS 支持(请参阅“彩蛋 TLS”部分),然后接着再由传输层的 TCP 传输。这些协议中的每一层都用一些元数据包装来自其上一层的数据。例如,在我们的 HTTP(S) 数据中预先加上 TCP 包头(packet header),然后将其放入 IP 包等,这样就可以在协议之间实现相对简洁的分离。这反过来又有利于它们的可重用性:像 TCP 这样的传输层协议不必关心它正在传输什么类型的数据(可以是 HTTP,也可以是 FTP,也可以是 SSH,谁知道呢),而且 IP 对于 TCP 和 UDP 都能很好地工作。
然而,如果我们想将多个 HTTP/2 资源多路传输到一个 TCP 连接上,这确实会产生重要的后果。如图7:
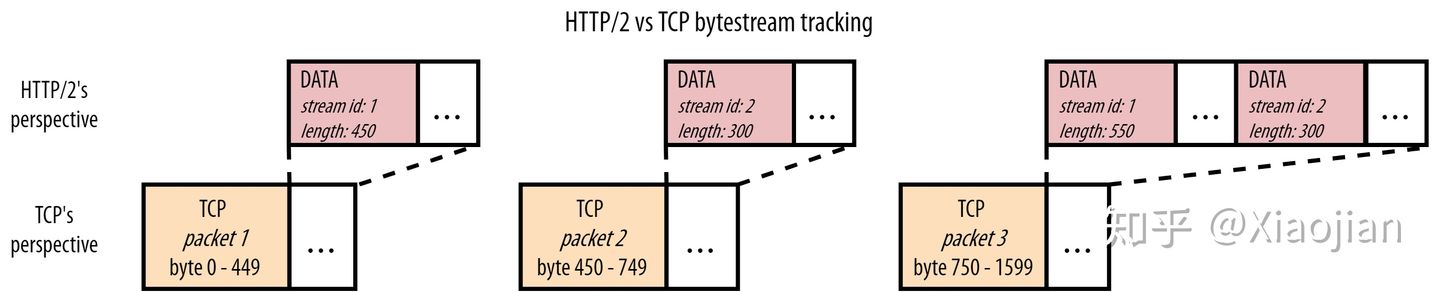
图7:HTTP/2 和 TCP 在透视图上的差异
虽然我们和浏览器都知道我们正在获取 JavaScript 和 CSS 文件,但 HTTP/2 不需要知道这一点。它只知道它在使用来自不同资源流 id (stream id)的块。然而,TCP 甚至不知道它在传输 HTTP!TCP 所知道的就是它被赋予了一系列字节,它必须从一台计算机传输另一台计算机。为此,它使用特定最大大小(maximum size)的数据包,通常大约为1450字节。每个数据包只跟踪它携带的数据的那一部分(字节范围),这样原始数据就可以按照正确的顺序重建。
换言之,这两个层之间的透视图是不匹配的:HTTP/2 可以看到多个独立的资源字节流(bytestream),而 TCP 只看到一个不透明的字节流(bytestreams)。图7的TCP数据包3就是一个例子:TCP 只知道它正在传输的任何内容的字节 750 到字节1 599。另一方面,HTTP/2 知道数据包3中实际上有两个独立资源的两个块。(注意:实际上,每个 HTTP/2 帧(如 DATA 和 HEADERS)的大小也有几个字节。为了简单起见,我没有计算额外的开销或这里的 HEADERS 帧,以使数字更直观。)
所有这些看起来都是不必要的细节,直到你意识到互联网是一个根本不可靠的网络。在从一个端点到另一个端点的传输过程中,数据包会丢失和延迟。TCP 的可靠性正是其最受欢迎的原因之一。它只需重新传输丢失数据包的副本就可以做到这一点。
我们现在可以理解传输层是如何导致队头阻塞的。再次思考下图7并问自己:如果 TCP 数据包2在网络中丢失,但数据包1和数据包3已经到达,会发生什么情况?请记住,TCP并不知道它正在承载 HTTP/2,只知道它需要按顺序传递数据。因此,它知道数据包1的内容可以安全使用,并将这些内容传递给浏览器。然而,它发现数据包1中的字节和数据包3中的字节(放数据包2 的地方)之间存在间隙,因此还不能将数据包3传递给浏览器。TCP 将数据包3保存在其接收缓冲区(receive buffer)中,直到它接收到数据包2的重传副本(这至少需要往返服务器一次),之后它可以按照正确的顺序将这两个数据包都传递给浏览器。换个说法:丢失的数据包2 队头阻塞(HOL blocking)数据包3!
您可能不清楚为什么这是个问题,所以让我们更深入地研究图7中 HTTP 层的 TCP 包中的实际内容。我们可以看到,TCP 数据包2只携带流id 2(CSS文件)的数据,数据包3同时携带流1(JS文件)和流2的数据。在 HTTP 级别,我们知道这两个流是独立的,并且由数据帧(DATA frame)清楚地描述出来。因此,理论上我们可以完美地将数据包3传递给浏览器,而不必等待数据包2到达。浏览器将看到流id为1的数据帧,并且能够直接使用它。只有流2必须被挂起,等待数据包2的重新传输。这将比我们从 TCP 的方式中得到的效率更高,TCP 的方式最终会阻塞流1和流2。
另一个例子是数据包1丢失,但是接收到2和3的情况。TCP将再次阻止数据包2和3,等待1。但是,我们可以看到,在HTTP/2级别,流2的数据(CSS文件)完全存在于数据包2和3中,不必等待数据包1的重新传输。浏览器本可以完美地解析/处理/使用 CSS 文件,但却被困在等待 JS 文件的重新传输。
总之,TCP 不知道 HTTP/2 的独立流(streams)这一事实意味着 TCP 层队头阻塞(由于丢失或延迟的数据包)也最终导致 HTTP 队头阻塞!
现在,您可能会问自己:那重点是什么?如果我们仍然有 TCP 队头阻塞,为什么还要使用HTTP/2 呢?好吧,主要原因是虽然数据包丢失确实发生在网络上,但还是比较少见的。特别是在有线网络中,包丢失率只有 0.01%。即使是在最差的蜂窝网络上,在现实中,您也很少看到丢包率高于2%。这与数据包丢失和抖动(网络中的延迟变化)通常是突发性的这一事实结合在一起的。包丢失率为2%并不意味着每100个包中总是有2个包丢失(例如数据包 42 和 96)。实际上,可能更像是在总共500个包中丢失10个连续的包(例如数据包255到265)。这是因为数据包丢失通常是由网络路径中的路由器内存缓冲区暂时溢出引起的,这些缓冲区开始丢弃无法存储的数据包。不过,细节在这里并不重要(如果你想知道更多,可以在其他地方找到)。重要的是:是的,TCP 队头阻塞是真实存在的,但是它对 Web 性能的影响要比HTTP/1.1 队头阻塞小得多,HTTP/1.1 队头阻塞几乎可以保证每次都会遇到它,而且它也会受到 TCP 队头阻塞的影响!
然而,当比较单个连接上的 HTTP/2 和单个连接上的 HTTP/1.1 时,这个基本上是真的。正如我们之前所看到的,实际上它并不是这样工作的,因为 HTTP/1.1 通常会打开多个连接。这使得 HTTP/1.1 不仅在一定程度上减轻了 HTTP 级别,而且减轻了 TCP 级别的队头阻塞。因此,在某些情况下,单个连接上的 HTTP/2 很难比6个连接上的 HTTP/1.1 快,甚至与 HTTP/1.1 一样快。这主要是由于 TCP 的“拥塞控制”(congestion control)机制。然而,这是另一个非常深入的话题,并不是我们讨论队头阻塞(HOL blocking)的核心,所以我把它移到了末尾的另一个彩蛋部分。
总之,事实上,我们看到(也许出乎意料),HTTP/2 目前部署在浏览器和服务器中,在大多数情况下通常与 HTTP/1.1 一样快或略快。在我看来,这部分是因为网站在优化 HTTP/2 方面做得更好,部分原因是浏览器仍然经常打开多个并行 HTTP/2 连接(要么是因为站点仍然在不同的服务器上共享资源,要么是因为与安全相关的副作用),从而使两者兼得。
然而,也有一些情况(特别是在数据包丢失率较高的低速网络上),6个连接的 HTTP/1.1 仍然比一个连接的 HTTP/2 更为出色,这通常是由于 TCP 级别的队头阻塞问题造成的。正是这个事实极大地推动了新的 QUIC 传输协议的开发,以取代 TCP。
文章:https://zhuanlan.zhihu.com/p/330300133
关于 HTTP 系列文章:
-
HTTP 概述
-
TCP 三次握手和四次挥手图解(有限状态机)
-
从你输入网址,到看到网页——详解中间发生的过程
-
深入浅出 HTTPS (详解版)
-
漫谈 HTTP 连接
-
漫谈 HTTP 性能优化
-
HTTP 报文格式简介
-
深入浅出:HTTP/2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号