


Windows环境编译Spark源码
一、下载源码包
1. 下载地址有官网和github:
http://spark.apache.org/downloads.html
https://github.com/apache/spark
Linux服务器上直接下载:wget https://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0.tgz
2. 解压源码
二、解压环境
需要maven、jdk、git、scala、hadoop环境,并配置环境变量。
二、使用Maven编译Spark
先找到解压后的spark文件里的pom.xml把maven、jdk、scala、hadoop改成当前安装的版本。如图:
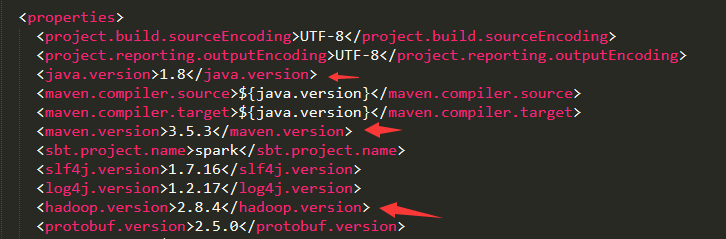
maven库的地址建议换成阿里的地址:http://maven.aliyun.com/nexus/content/groups/public
在编译过程需要保证编译机器的是联网的,以保证Maven从网上下载其依赖包。另外,编译前需要设置JVM内存大小,否则在编译过程中,会由于默认内存小而出现内存溢出的错误。编译执行脚本如下,其中,参数-P表示激活依赖的程序及版本,-Dskip Tests表示编译时跳过测试环节。
1、设置maven内存的环境变量
MAVEN_OPTS=-Xmx2g -XX:MaxPermSize=2048M -XX:ReservedCodeCacheSize=2048M
2、右击spark-2.4.0文件夹,选择Git Bash here,弹出git窗口,输入以下命令:
./build/mvn -Pyarn -Phadoop-2.8.4 -Dhadoop.version=2.8.4 -DskipTests clean package
整个编译过程编译了约29个任务,每个版本的数量不同。如果是已经下载依赖包的情况,则编译耗时1分钟左右。由于编译过程中需要下载较多的依赖包,因此整个编译时间取决于网速,最终编译完成后的文件夹大约为899MB。整个编译可能会很长,要耐心等待。
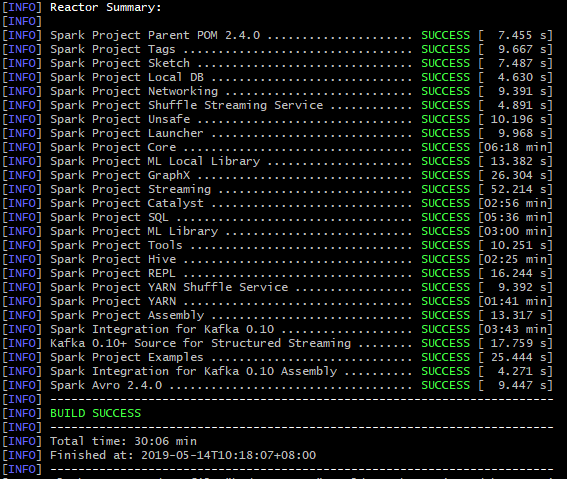
最终成功结果如下图:
如果在编译过程中出现了错误,解决后再重新执行编译命令:
错误1:Failed to collect dependencies at org.jpmml:pmml-model:jar:1.2.15
Could not resolve dependencies for project org.apache.spark:spark-core_2.11:jar:2.4.0
这两种都是依赖包下载失败,为了避免重新跑脚本还会失败浪费时间,建议使用idea加载jar包,或者到maven官网手动下载好放到maven本地库里。
错误2:有时第二次编译时,会删除源码包里面target里面的文件失败,可以手动删除,或者重新解压个新的spark源码文件,再编译。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通