hadoop2.5.1+hbase1.1.2安装与配置
今天正在了解HBase和Hadoop,了解到HBase1.1.x为稳定版,对应的Hadoop2.5.x是最新的支持此版本HBase的,同时jdk版本为jdk7才能支持。--本段话内容参考自Apache官方文档:
1.本表格为jdk与hbase版本对应:
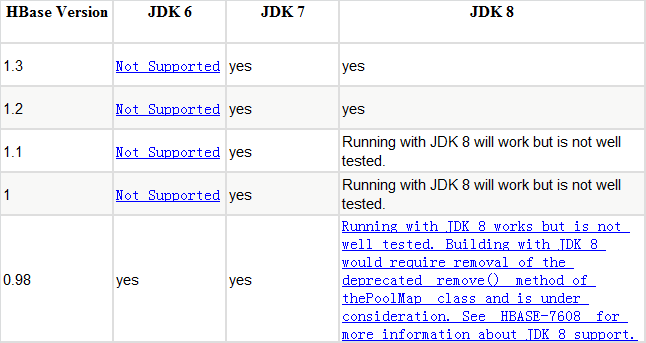
-
"S" = supported
-
"X" = not supported
-
"NT" = Not tested

官方强烈建议安装Hadoop2.x:
|
Hadoop 2.x is recommended.
Hadoop 2.x is faster and includes features, such as short-circuit reads, which will help improve your HBase random read profile. Hadoop 2.x also includes important bug fixes that will improve your overall HBase experience. HBase 0.98 drops support for Hadoop 1.0, deprecates use of Hadoop 1.1+, and HBase 1.0 will not support Hadoop 1.x. |
本想把环境搭建起来,可是找不到机器,我找了一篇文章专门搭建和配置此环境的,先拿来贴在下面,等有机会自己搭一套。
以下详细安装配置的指导内容转自:http://blog.csdn.net/yuansen1999/article/details/50542018
===================================以下全文:
版权声明:本文为博主原创文章,未经博主允许不得转载。
【说明】
hbase自1.0版本发布之后,标志着hbase可以投入企业的生产使用。此后又发布了1.x版本, 这里的1.1.2版本就是其中的一个稳定版本。
因为hbase对Hadoop的库有依赖关系,对于hbase1.1.2要求hadoop的库为2.5.1,所以使用hadoop2.5.1版本做为基本环境。如果使用其它
的hadoop版本, 还需要它lib下的jar文件替换成hadoop的版本,不然就会报本地库找不到的错误, 下面是实际的安装步骤。
1、 软件安装版本
|
组件名 |
版本 |
备注 |
|
操作系统 |
CentOS release 6.4 (Final) |
64位 |
|
JDK |
jdk-7u80-linux-x64.gz |
|
|
Hadoop |
hadoop-2.5. 1.tar.gz |
|
|
ZooKeeper |
zookeeper-3.4.6.tar.gz |
|
|
HBase |
hbase-1.1.2.tar.gz |
|
2、 主机规划
|
IP |
HOST |
模块部署 |
|
192.168.8.127 |
master |
QuorumPeerMain DataNode ResourceManager HRegionServer NodeManager SecondaryNameNode NameNode HMaster |
|
192.168.8.128 |
slave01 |
DataNode QuorumPeerMain HRegionServer NodeManager |
|
192.168.8.129 |
slave02 |
QuorumPeerMain HRegionServer NodeManager DataNode |
3、 目录规划
|
IP |
目录 |
|
192.168.8.127 |
三个挂载点 根目录: /dev/sda1 / swap目录: tmpfs /dev/shm hadoop目录: /dev/sda3 /hadoop |
|
192.168.8.128 |
三个挂载点 根目录: /dev/sda1 / swap目录: tmpfs /dev/shm hadoop目录: /dev/sda3 /hadoop |
|
192.168.8.129 |
三个挂载点 根目录: /dev/sda1 / swap目录: tmpfs /dev/shm hadoop目录: /dev/sda3 /hadoop |
[root@master~]# df -h
4、 为每台主机创建用户hadoop并属于hadoop组
3.1、创建工作组hadoop:
[root@localhost ~]# groupadd hadoop
3.2、新建用户hadoop并添加至hadoop组别:
[root@localhost ~]# useradd hadoop -g hadoop
3.3、设置hadoop用户密码为hadoop:
[root@localhost ~]# passwd hadoop
5、 修改并配置主机名
[root@localhost ~]# vi /etc/hosts
127.0.0.1 localhost
192.168.8.127 master
192.168.8.128 slave01
192.168.8.129slave02
[root@localhost ~]# vi /etc/sysconfig/network
关机重启:
[root@localhost ~]# reboot
查看主机名:
修改hadoop目录的拥有者:
[root@master ~]# chown hadoop:hadoop -R /hadoop
[root@master ~]# ls -l /
6、 上传安装软件包至hadoop用户主目录
7、 安装JDK
6.1 安装JDK
[root@master ~]# cd /usr/local/
[hadoop@master local]$ tar -zxvf jdk-7u80-linux-x64.gz
6.2 配置JDK环境变量
export JAVA_HOME= /usr/local/jdk1.7.0_80
export JRE_HOME= /usr/local/jdk1.7.0_80/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
6.3使环境变量生效
[hadoop@master~]$ source .bashrc
6.4检测JDK是否安装成功:
8、 配置各节点间SSH安全通信协议:
7.1、创建文件目录:
[hadoop@master ~]$ mkdir .ssh
7.2、进入.ssh目录进行相应配置:
[hadoop@master ~]$ cd .ssh/
7.3、生成公钥文件:
[hadoop@master .ssh]$ ssh-keygen -t rsa
备注:一路回车即可
7.4、将生成的公钥文件添加至认证文件:
[hadoop@master .ssh]$ cat id_rsa.pub >>authorized_keys
7.5、赋予.ssh文件700权限:
[hadoop@master .ssh]$ chmod 700 .ssh/
这个有的机器必须,但有的是可选。
7.5、赋予认证文件600权限:
[hadoop@master .ssh]$ chmod 600 authorized_keys
一定是600,不然不会成功。
7.6、测试SSH无密码登录:
[hadoop@master hadoop]$ ssh master
Last login: Tue Jan 19 13:58:27 2016 from 192.168.8.1
7.7、依次生成其他节点的SSH无密码登录(一样套路)
7.8、将master节点节点的公钥文件追加至其他节点(以master追加至slave01为例进行)
7.8.1、将master中的公钥id_rsa.pub远程拷贝至slave01节点的.ssh目录下并重新命名为:master.pub
[hadoop@master .ssh]$ scp id_rsa.pub slave01:/home/hadoop/.ssh/master.pub
这个步骤,注意不要把人家的id_rsa.pub给覆盖了。
7.8.2、切换至slave01节点,将master.pub追加至认证文件authorized_keys文件中
[hadoop@slave01 .ssh]$ cat master_rsa.pub >>authorized_keys
7.8.3、slave02与以上步骤相同
备注:第一次登录时需要进行密码输入
9、 安装Hadoop:
8.1、解压安装包:
[hadoop@master ~]$cd /hadoop
[hadoop@master hadoop]$tar -zxvf hadoop-2.5.1.tar.gz
8.2、配置Hadoop环境变量:
[hadoop@master ~]$vi .bashrc
export HADOOP_HOME=/hadoop/hadoop-2.5.1
export HADOOP_CONF_DIR=/hadoop/hadoop-2.5.1/etc/hadoop
exportPATH=.:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
8.3、使环境变量生效:
[hadoop@master ~]$source .bashrc
8.4、进入hadoop配置目录按照以下表格进行配置:
备注:现将附件中的fairscheduler.xml文件copy至/hadoop/hadoop-2.5.1/
etc/hadoop中
[hadoop@master hadoop]$ pwd
/hadoop/hadoop-2.5.1/etc/hadoop
|
core-site.xml |
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:8020</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/tmp</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.yarn.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.yarn.groups</name> <value>*</value> </property> </configuration> |
|
hdfs-site.xml |
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/hadoop/dfs/data</value> </property> </configuration> |
|
mapred-site.xml |
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> <property> <name>mapred.child.Java.opts</name> <value>-Xmx4096m</value> </property> </configuration> |
|
yarn-site.xml |
<configuration> <!-- Site specific YARN configuration properties --> <property> <description>The hostname of the RM.</description> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <description>The address of the applications manager interface in the RM.</description> <name>yarn.resourcemanager.address</name> <value>${yarn.resourcemanager.hostname}:8032</value> </property> <property> <description>The address of the scheduler interface.</description> <name>yarn.resourcemanager.scheduler.address</name> <value>${yarn.resourcemanager.hostname}:8030</value> </property> <property> <description>The http address of the RM web application.</description> <name>yarn.resourcemanager.webapp.address</name> <value>${yarn.resourcemanager.hostname}:8088</value> </property> <property> <description>The https adddress of the RM web application.</description> <name>yarn.resourcemanager.webapp.https.address</name> <value>${yarn.resourcemanager.hostname}:8090</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>${yarn.resourcemanager.hostname}:8031</value> </property> <property> <description>The address of the RM admin interface.</description> <name>yarn.resourcemanager.admin.address</name> <value>${yarn.resourcemanager.hostname}:8033</value> </property> <property> <description>The class to use as the resource scheduler.</description> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value> </property> <property> <description>fair-scheduler conf location</description> <name>yarn.scheduler.fair.allocation.file</name> <value>${yarn.home.dir}/etc/hadoop/fairscheduler.xml</value> </property> <property> <description>List of directories to store localized files in. An application's localized file directory will be found in: ${yarn.nodemanager.local-dirs}/usercache/${user}/appcache/application_${appid}.Individual containers' work directories, calledcontainer_${contid}, will be subdirectories of this. </description> <name>yarn.nodemanager.local-dirs</name> <value>/home/hadoop/hadoop/local</value> </property> <property> <description>Whether to enable log aggregation</description> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <description>Where to aggregate logs to.</description> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/tmp/logs</value> </property> <property> <description>Amount of physical memory, in MB, that can be allocated for containers.</description> <name>yarn.nodemanager.resource.memory-mb</name> <value>30720</value> </property> <property> <description>Number of CPU cores that can be allocated for containers.</description> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>8</value> </property> <property> <description>the valid service name should only contain a-zA-Z0-9_ and can not start with numbers</description> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration> |
|
slaves |
master slave01 slave02 |
|
hadoop-env.sh |
export JAVA_HOME=/hadoop/jdk1.7.0_80 备注:最后一行进行添加 |
8.5、配置各叶子节点的环境:
8.5.1、在master端将hadoop-2.5.1、jdk1.7.0_80、环境变量文件.bashrc文件远程拷贝至其他节点
8.5.2、在slave01、slave02节点执行使环境变量生效的命令:
[hadoop@slave01 ~]$ source.bashrc
8.6、进行格式化:
[hadoop@master hadoop]$hadoop namenode –format
8.7、启动Hadoop:
[hadoop@master hadoop]$ start-all.sh
[hadoop@master hadoop]$ mr-jobhistory-daemon.shstart historyserver
8.8、查看启动进程:
8.8.1、master节点进程:
[hadoop@master hadoop]$ jps
3456 Jps
2305 NameNode
3418 JobHistoryServer
2592 SecondaryNameNode
2844 NodeManager
2408 DataNode
2739 ResourceManager
8.8.2、slave01、slave02节点进程:
[hadoop@slave01~]$ jps
2567Jps
2249DataNode
2317NodeManager
[hadoop@slave02~]$ jps
2298NodeManager
2560Jps
2229DataNode
8.9、在各个节点关闭防火墙:
[root@master ~]# iptables -F
[root@master ~]# service iptables save
[root@master ~]# service iptables stop
[root@master ~]# chkconfig iptablesoff
有ip6tables的,也一样
[root@master ~]# ip6tables -F
[root@master ~]# service ip6tables save
[root@master ~]# service ip6tablesstop
[root@master ~]# chkconfig ip6tablesoff
8.10、访问Web页面:
http://master:8088/cluster/cluster
10、 安装ZooKeeper:
10.1、master端安装:
10.1.1、解压安装包:
[hadoop@master ~]$cd /hadoop
[hadoop@master hadoop]$tar -zxvf zookeeper-3.4.6.tar.gz
10.1.2、配置环境变量:
[hadoop@master ~]$vi .bashrc
export ZOOKEEPER_HOME=/hadoop/zookeeper-3.4.6
exportPATH=.:$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf:$PATH
10.1.3、使环境变量生效:
[hadoop@master ~]$source .bashrc
10.1.4、切换至ZooKeeper的配置文件目录进行配置:
[hadoop@master ~]$ cd /hadoop/zookeeper-3.4.6/conf/
10.1.5、新建Zookeeper配置文件:
[hadoop@master conf]$ cpzoo_sample.cfg zoo.cfg
10.1.6、对zoo.cfg进行配置:
|
内容 |
备注 |
|
dataDir=/hadoop/zookeeperdata |
1、 此为修改项 2、 hadoop为用户名 |
|
clientPort=2181 |
1、此为修改项 |
|
server.1=master:2888:3888 server.2=slave01:2888:3888 server.3= slave02:2888:3888 |
1、此为新增项 |
10.1.7、在主目录下进行一下操作:
[hadoop@master ~]$ cd /hadoop
[hadoop@master hadoop]$ mkdirzookeeperdata
[hadoop@master hadoop]$ echo"1" > /hadoop/zookeeperdata/myid
10.2、salve01端安装:
10.2.1、将hadoop中zookeeper-3.4.6进行远程复制到salve01的主目录:
[hadoop@master hadoop]$ scp -r zookeeper-3.4.6slave01:/hadoop
10.2.2、将master中.bashrc文件远程拷贝至datanode1中:
[hadoop@master ~]$ cd
[hadoop@master ~]$ scp.bashrc slave01:/home/hadoop
10.2.3、在slave01中使环境变量生效:
[hadoop@salve01~]$ source .bashrc
10.2.4、在slave01中进行如下操作:
[hadoop@slave01 hadoop]$ mkdir zookeeperdata
[hadoop@slave01 hadoop]$ echo"2" > /home/hadoop/zookeeperdata/myid
10.3、slave02端的安装(忽略):
[hadoop@salve02~]$ source .bashrc
[hadoop@slave02 hadoop]$ mkdir zookeeperdata
[hadoop@slave02 hadoop]$ echo"3" > /hadoop/zookeeperdata/myid
10.4、启动所有zookeeper服务:
[hadoop@master hadoop]$ zkServer.shstart
JMX enabled by default
Using config:/hadoop/zookeeper-3.4.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@slave01 ~]$ zkServer.sh start
JMX enabled by default
Using config:/hadoop/zookeeper-3.4.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@slave02 hadoop]$ zkServer.shstart
JMX enabled by default
Using config:/hadoop/zookeeper-3.4.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
10.5、使用JPS查看进程:
[hadoop@master hadoop]$ jps
2305 NameNode
3608 Jps
3418 JobHistoryServer
2592 SecondaryNameNode
2844 NodeManager
2408 DataNode
2739 ResourceManager
3577 QuorumPeerMain
其中“QuorumPeerMain” 就是我们的zookeeper进程。
[hadoop@slave01 ~]$ jps
2249 DataNode
2662 Jps
2317 NodeManager
2616 QuorumPeerMain
[hadoop@slave02 hadoop]$ jps
2599 QuorumPeerMain
2298 NodeManager
2652 Jps
2229 DataNode
11、安装HBASE:
11.1、配置NTP时间同步服务:
11.1.1、服务端(Master)配置:
[hadoop@masterhadoop]$ su - root
密码:
[root@master ~]# vi/etc/ntp.conf
修改以下配置:
#restrictdefault kod nomodify notrap nopeer noquery
restrictdefault kod nomodify
restrict-6 default kod nomodify notrap nopeer noquery
修改完成之后,启动ntpd.
[root@master ~]service ntpd start
[root@master ~]chkconfig ntpd on
11.1.2、客户端配置:
[hadoop@slave01 ~]$su - root
密码:
[root@slave01~]# crontab -e
输入 以下命令:
0-59/10 * * * */usr/sbin/ntpdate 192.168.8.127 && /sbin/hwclock -w
我们每隔10分钟与主机对一下时间。
11.2安装HBASE
11.2.1、解压缩hbase安装包
[hadoop@master ~]$ cd /hadoop
[hadoop@master hadoop]$ tar -zxvf hbase-1.1.2-bin.tar.gz
11.2.2、配置环境变量:
[hadoop@master hadoop]$ vi ~/.bashrc
增加hbase的目录:
export HBASE_HOME=/hadoop/hbase-1.1.2
exportPATH=.:$HBASE_HOME/bin:$HBASE_HOME/conf:$PATH
11.2.3、使环境变量生效:
[hadoop@master hadoop]$ source ~/.bashrc
11.2.4、切换至HBase的配置目录:
[hadoop@master hadoop]$ cd /hadoop/hbase-1.1.2/conf
11.2.5、配置hbase-env.sh文件:
[hadoop@masterconf]$ vi hbase-env.sh
|
内容 |
备注 |
|
export HBASE_MANAGES_ZK=false |
1、此为修改项; |
11.2.6、配置hbase-site.xml文件:
[hadoop@master conf]$ vihbase-site.xml
|
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://master:8020/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.master</name> <value>master</value> </property> <property> <name>hbase.zookeeper.property.clientPort</name> <value>2181</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>master,slave01,slave02</value> </property> </configuration> |
11.2.7、配置regionservers文件:
[hadoop@master conf]$ vi regionservers
master
slave01
slave02
11.2.8、slave01与slave02配置:
同master配置
11.2.9、启动Hbase(确保HADOOP和ZOOKEEPER已经启动)
[hadoop@master conf]$ start-hbase.sh
11.2.10、使用JPS查看进程:
[hadoop@master hadoop]$ jps
2305 NameNode
3418 JobHistoryServer
2592 SecondaryNameNode
2844 NodeManager
2408 DataNode
2739 ResourceManager
3577 QuorumPeerMain
3840 HMaster
4201 Jps
3976 HRegionServer
11.2.11、进入HBASE命令行模式并进行相应查询:
[hadoop@master hadoop]$ hbase shell
HBase Shell; enter'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" toleave the HBase Shell
Version 1.1.2,rcc2b70cf03e3378800661ec5cab11eb43fafe0fc, Wed Aug 26 20:11:27 PDT 2015
hbase(main):005:0> list
TABLE
0 row(s) in 0.0270 seconds
=> []
我们创建一个表,看看是否成功:
hbase(main):006:0> create'test','info'
0 row(s) in 2.3150 seconds
=> Hbase::Table - test
hbase(main):007:0>
看来是成功了,添加一条数据,看看是否能够保存。
hbase(main):008:0> put'test','u00001','info:username','yuansen'
0 row(s) in 0.1400 seconds
hbase(main):009:0> scan 'test'
ROW COLUMN+CELL
u00001 column=info:username,timestamp=1453186521452, value=yuansen
1 row(s) in 0.0550 seconds
看来的确是成功了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号