

剑指offer试题——从尾到头打印链表
输入一个链表,从尾到头打印链表每个节点的值。
'''试题中定义好的类——节点''' # class ListNode: # def __init__(self, x): # self.val = x # self.next = None class Solution: # 返回从尾部到头部的列表值序列,例如[1,2,3] def printListFromTailToHead(self, listNode): # write code here l = [] head = listNode while head: l.insert(0, head.val) #0是索引每次循环都将head.val的值插在索引为0的位置,可以想象,while head循环开始是listNode #中第一个节点,将第一个节点放在索引为0的位置,接着将第二个节点放在索引为0的位置, #当最后一个节点的数值域的值放在索引为0的位置时,此时得到的l中第一个元素就是最后一个节点的值 head = head.next return l
知识点:
链表:http://zhaochj.github.io/2016/05/12/2016-05-12-%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84-%E9%93%BE%E8%A1%A8/
写的非常好的博客,很全面,下面做一些阅读该博客后的笔记和补充,原博客是一定要看的。
数组的优点
- 随机访问性强
- 查找速度快
数组的缺点
- 插入和删除效率低
- 可能浪费内存
- 内存空间要求高,必须有足够的连续内存空间。
- 数组大小固定,不能动态拓展
链表的优点
- 插入删除速度快
- 内存利用率高,不会浪费内存
- 大小没有固定,拓展很灵活。
链表的缺点
- 不能随机查找,必须从第一个开始遍历,查找效率低
| - | 数组 | 链表 |
|---|---|---|
| 读取 | O(1) | O(n) |
| 插入 | O(n) | O(1) |
| 删除 | O(n) | O(1) |
链表是实现了数据之间保持逻辑顺序,但存储空间不必按顺序的方法。可以用一个图来表示这种链表的数据结构:

图1:链表
链表中的基本要素:
- 结点(也可以叫节点或元素),每一个结点有两个域,左边部份叫
值域,用于存放用户数据;右边叫指针域,一般是存储着到下一个元素的指针 - head结点,head是一个特殊的结节,head结点永远指向第一个结点
- tail结点,tail结点也是一个特殊的结点,tail结点永远指向最后一个节点
- None,链表中最后一个结点指针域的指针指向None值,因也叫
接地点,所以有些资料上用电气上的接地符号代表None
链表的常用方法:
- LinkedList() 创建空链表,不需要参数,返回值是空链表
- is_empty() 测试链表是否为空,不需要参数,返回值是布尔值
- append(data) 在尾部增加一个元素作为列表最后一个。参数是要追加的元素,无返回值
- iter() 遍历链表,无参数,无返回值,此方法一般是一个生成器
- insert(idx,value) 插入一个元素,参数为插入元素的索引和值
- remove(idx)移除1个元素,参数为要移除的元素或索引,并修改链表
- size() 返回链表的元素数,不需要参数,返回值是个整数
- search(item) 查找链表某元素,参数为要查找的元素或索引,返回是布尔值
节点类
python用类来实现链表的数据结构,节点(Node)是实现链表的基本模块,每个节点至少包括两个重要部分。首先,包括节点自身的数据,称为“数据域”(也叫值域)。其次,每个节点包括下一个节点的“引用”(也叫指针)
下边的代码用于实现一个Node类:
class Node: def __init__(self, data): self.data = data self.next = None
此节点类只有一个构建函数,接收一个数据参数,其中next表示指针域的指针,实例化后得到一个节点对象,如下:
node = Node(4)
此节点对象数据为4,指针指向None。
这样一个节点对象可以用一个图例来更形象的说明,如下:

图2: 节点
链表类
先来看LinkedList类的构建函数:
class LinkedList: def __init__(self): self.head = None self.tail = None
此类实例后会生成一个链表对象,初始化了head和tail节点,且两节点都指向None,实例化代码如下:
link_list = LinkedList()
也可以用图形象的表示这个链表对象,如下:
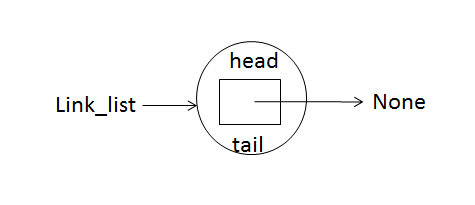
图3:空链表
注意:
1.节点是链表的基本构成元素,每个节点都有一个指针域和值域,每一个节点中可以存储不止一个数据,每一个节点可以存储的是一个数组
2.区分下面两个输入情况下,输出的不同
首先定义节点
class ListNode: def __init__(self, x): self.val = x self.next = None
实现从尾到头打印
class Solution: # 返回从尾部到头部的列表值序列,例如[1,2,3] def printListFromTailToHead(self, listNode): # write code here l = [] head = listNodewhile head: l.insert(0, head.val) head = head.next return l
输入:
a=Solution() listnode=ListNode([1,2,3]) a.printListFromTailToHead(listnode)
输出:
[[1, 2, 3]]
看起来似乎并没有倒序打印,这是因为,我们这里定义的是一个节点,并没有形成链表,因此[1,2,3]是存在一个节点当中的,就这一个节点,倒序打印没有意义
节点的组成是数据域和指针域,而链表的组成是头,尾,单独来看,头,尾本身都是节点
下面看节点构成链表,对链表进行操作
先定义节点node,然后定义链表LinkList
class Node: def __init__(self, data): self.data = data self.next = None
class LinkedList: def __init__(self): self.head = None self.tail = None def is_empty(self): return self.head is None def append(self, data): node = Node(data) if self.head is None: self.head = node self.tail = node else: self.tail.next = node self.tail = node def iter(self): if not self.head: return cur = self.head yield cur.data while cur.next: cur = cur.next yield cur.data def insert(self, idx, value): cur = self.head cur_idx = 0 if cur is None: # 判断是否是空链表 raise Exception('The list is an empty list') while cur_idx < idx-1: # 遍历链表 cur = cur.next if cur is None: # 判断是不是最后一个元素 raise Exception('list length less than index') cur_idx += 1 node = Node(value) node.next = cur.next cur.next = node if node.next is None: self.tail = node def remove(self, idx): cur = self.head cur_idx = 0 if self.head is None: # 空链表时 raise Exception('The list is an empty list') while cur_idx < idx-1: cur = cur.next if cur is None: raise Exception('list length less than index') cur_idx += 1 if idx == 0: # 当删除第一个节点时 self.head = cur.next cur = cur.next return if self.head is self.tail: # 当只有一个节点的链表时 self.head = None self.tail = None return cur.next = cur.next.next if cur.next is None: # 当删除的节点是链表最后一个节点时 self.tail = cur def size(self): current = self.head count = 0 if current is None: return 'The list is an empty list' while current is not None: count += 1 current = current.next return count def search(self, item): current = self.head found = False while current is not None and not found: if current.data == item: found = True else: current = current.next return found
输入:
link_list = LinkedList() for i in range(150): link_list.append(i)
此时,link_list就是一个链表,链表的关键,head,tail
head,tail的本身就是一个节点,节点的两个基本组成数据域跟指针域,指针指向下一个节点的位置,这就是链表的不好之处,想要查找数据等只能遍历所有的节点

倒序打印
class Solution: # 返回从尾部到头部的列表值序列,例如[1,2,3] def printListFromTailToHead(self, listNode): # write code here l = [] link_list = listNode while link_list.head: l.insert(0, link_list.head.data) link_list.head=link_list.head.next return l
输入:
a=Solution()
a.printListFromTailToHead(link_list)
输出:可见此时是倒序打印


