
Scipy Lecture Notes学习笔记(一)Getting started with Python for science 1.2. The Python language
Scipy Lecture Notes学习笔记(一)Getting started with Python for science
1.2. The Python language
1.2.2.1. Numerical types
复数
a = 1.5 + 0.5j type(1. + 0j)

print(a.real)
print(a.imag)
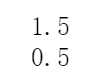
幂运算
print(2**10) print(3**3)

类型转换
float(1)
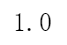
注意:在python3中,虽然3跟2是int型,但是计算后得到的是float型结果,如果想要得到相除后的整数部分,直接采用下面

1.2.2.2. Containers
python提供的很多可以存放对象的结构,称之为containers,主要有lists,strings,dictionaries,tuples,sets
list:链表,有序的项目, 通过索引进行查找,使用方括号”[]”;
tuple:元组,元组将多样的对象集合到一起,不能修改,通过索引进行查找, 使用括号”()”,但可以对一个tuple重新赋值,tuple的存在可能基于两个原因:1)在python中,它比list操作速度更快,如果我们定义一个常量集,不需要修改,只需要遍历,则最好用tuple;2)安全性:由于tuple不能进行修改,那么对于这种类型的数据,tuple可以避免数据被偶然修改。;
dict:字典,字典是一组键(key)和值(value)的组合,通过键(key)进行查找,没有顺序, 使用大括号”{}”;
set:集合,无序,元素只出现一次, 自动去重,使用”set([])”
应用场景:
list, 简单的数据集合,可以使用索引;
tuple, 把一些数据当做一个整体去使用,不能修改;
dict,使用键值和值进行关联的数据;
set,数据只出现一次,只关心数据是否出现, 不关心其位置;
Lists:可变对象
colors = ['red', 'blue', 'green', 'black', 'whiteprint(colors[0])
print(colors[1])
print(colors[2])
print(colors[3])
print(colors[-1])
print(colors[-2])
print(colors[2:3]) #lists中[开始位置:结束位置]开始位置是按照0,1,2,3,标号,结束位置就是物理意义上面的个数,从标号i
#开始,到第j个元素结束,因此color[2:3]就是一个元素,标号为2,个数是第三个的green,但是此时的green是lists
print(colors[0:-1])
print(colors[0:5:2]) #[开始位置:结束位置:步长],注意比较两者结果的不同,开始位置按标号技术,结束位置按照物理个数计数
print(colors[0:4:2]) #[开始位置:结束位置:步长]
print(type(colors[0]))
print(type(colors[2:3]))
输出:
red
blue
green
black
white
black
['green']
['red', 'blue', 'green', 'black']
['red', 'green', 'white']
['red', 'green']
<class 'str'>
<class 'list'>
注意,colors[2]的类型是string,而colors[2:3]的类型是list
倒置reverse
指令:colors.reverse()
输入:
colors = ['red', 'blue', 'green', 'black', 'white']
rcolors = colors[::-1]
rcolors1 = colors
rcolors1.reverse()
print(colors)
print(rcolors)
print(rcolors1)
输出:
['white', 'black', 'green', 'blue', 'red']
['white', 'black', 'green', 'blue', 'red']
['white', 'black', 'green', 'blue', 'red']
输入:
colors = ['red', 'blue', 'green', 'black', 'white']
rcolors = colors[::-1]
rcolors2 = colors.copy()
rcolors2.reverse()
print(colors)
print(rcolors)
print(rcolors2)
输出:
['red', 'blue', 'green', 'black', 'white']
['white', 'black', 'green', 'blue', 'red']
['white', 'black', 'green', 'blue', 'red']
注意上下两段代码的区别,“=” 是两个变量共同分享一段内存,对新的变量赋值同时会影响原来的变量,因此正确的做法应该是b=a.copy()
输入:
rcolors + colors
输出:
['white',
'black',
'green',
'blue',
'red',
'white',
'black',
'green',
'blue',
'red']
排序sort
输入:
print(rcolors)
print(sorted(rcolors))
print(colors)
colors.sort()
print(colors)
输出:
['white', 'black', 'green', 'blue', 'red']
['black', 'blue', 'green', 'red', 'white']
['red', 'blue', 'green', 'black', 'white']
['black', 'blue', 'green', 'red', 'white']
字符串String:字符串是不可变的对象,不可能修改其内容。然而,人们可能会从原来的创建新的字符串。
输入:
a = "hello, world!"
print(a[3:6]) #标号也是从0开始计数,到标号为3的元素,截至是物理位置第6个元素
print(a[2:10:2])
print(a[::3])
print("oraginal value=",a)
print(a.replace('l', 'z', 1)) #采用replace指令对元素值进行替换
print("new value=",a) #但是原来的string变量并没有发生改变
输出:
lo,
lo o
hl r!
oraginal value= hello, world!
hezlo, world!
new value= hello, world!
格式设置:
输入:
'An integer: %i; a float: %f; another string: %s' % (1, 0.1, 'string')
输出:
'An integer: 1; a float: 0.100000; another string: string'
输入:
i = 102
filename = 'processing_of_dataset_%d.txt' % i
filename
输出:
'processing_of_dataset_102.txt'
字典Dictionaries:一个将键映射到值的高效表。它的英文一个无序的容器,他可以方便的存储于检索与名称相关的值
输入
tel = {'emmanuelle': 5752, 'sebastian': 5578}
tel['francis'] = 5915
print(tel)
输出:
{'emmanuelle': 5752, 'sebastian': 5578, 'francis': 5915}
Tuples:元组,不可变
输入:
t = 12345, 54321, 'hello!'
t[0]
输出:
12345
Sets集合
输入:
s = set(('a', 'b', 'c', 'a'))
print(s)
print(s.difference('a','b'))
print(s)
输出:
{'c', 'b', 'a'}
{'c'}
{'c', 'b', 'a'}
1.2.3 控制流程
1.2.3.2. for/range
输入:
for i in range(4):
print(i)
输出:
0
1
2
3
输入:
for word in ('cool', 'powerful', 'readable'):
print('Python is %s' % word)
输出:
Python is cool
Python is powerful
Python is readable
1.2.3.3. while/break/continue
break:终止循环语句跳出整个循环,continue,跳出本次循环,进行下一轮循环
输入:
z = 1 + 1j
while abs(z) < 100:
if z.imag == 0:
break
z = z**2 + 1
print(z)
z = 1 + 1j
while abs(z) < 100:
if z.imag == 1:
break
z = z**2 + 1
print(z)
z = 1 + 1j
while abs(z) < 100:
if z.imag == 0:
continue
z = z**2 + 1
print(z)
a = [1, 0, 2, 4]
for element in a:
if element == 0:
continue
print(1. / element)
输出:
(-134+352j)
(1+1j)
(-134+352j)
1.0
0.5
0.25
输入:
message = "Hello how are you?"
message.split() # returns a list
print(message) #再次说明,message作为string型,是不可变的
print(message.split()) #而message.split()返回的是一个list结构
for word in message.split():
print(word)
输出:
Hello how are you?
['Hello', 'how', 'are', 'you?']
Hello
how
are
you?
输入
words = ('cool', 'powerful', 'readable')
for index, item in enumerate(words):#enumerate是python内置函数
print((index, item))
输出:
(0, 'cool')
(1, 'powerful')
(2, 'readable')
Looping over a dictionary:The ordering of a dictionary in random, thus we use sorted() which will sort on the keys.
输入:
d = {'a': 1, 'b':1.2, 'c':1j}
for key, val in sorted(d.items()):
print('Key: %s has value: %s' % (key, val))
输出:
Key: a has value: 1
Key: b has value: 1.2
Key: c has value: 1j
exercise
Compute the decimals of Pi using the Wallis formula:
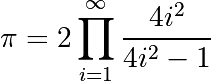
输入:
def wallis(n):
pi = 2.
for i in range(1, n):
left = (2. * i)/(2. * i - 1.)
right = (2. * i)/(2. * i + 1.)
pi = pi * left * right #连乘
return pi
wallis(100000)
输出:
3.1415847995783834
1.2.4. Defining functions
输入:
def slicer(seq, start=None, stop=None, step=None): #seq是位置参数,start是可变参数,如果没有指定start,stop,step的值那么就取函数定义时的默认值,但是如果没有指定seq,那么函数则会报错
return seq[start:stop:step]
rhyme = 'one fish, two fish, red fish, blue fish'.split() #如果此时用的是双引号,那么rhyme类型变成string
print(type(rhyme))
print(slicer(rhyme))
print(slicer(rhyme,step=2))
print(slicer(rhyme,start=1,stop=4,step=2))
输出:
<class 'list'>
['one', 'fish,', 'two', 'fish,', 'red', 'fish,', 'blue', 'fish']
['one', 'two', 'red', 'blue']
['fish,', 'fish,']
输入:如果不指定函数的位置参数seq,那么则会报错,函数缺少位置参数
slicer()
输出:
TypeError Traceback (most recent call last)
<ipython-input-8-3c8febe6fdb8> in <module>()
----> 1 slicer()
TypeError: slicer() missing 1 required positional argument: 'seq'
1.2.4.6 可变数量的参数
- 特殊形式的参数:
-
*args:将任意数量的位置参数打包到一个元组中**kwargs:将任意数量的关键字参数打包到字典中
输入
def variable_args(*args, **kwargs): print ('args is', args) print ('kwargs is', kwargs) variable_args('one', 'two', x=1, y=2, z=3) #前两个没有指定默认值,是位置参数,后面两个有默认值,是关键字参数输出
args is ('one', 'two') kwargs is {'x': 1, 'y': 2, 'z': 3}exercise: Fibonacci sequence
Write a function that displays the
nfirst terms of the Fibonacci sequence, defined by: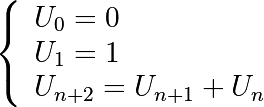
输入:
def Fibonacci(n): u=list(range(0,n)) for i in range(2,n): u[0]=0; u[1]=1; u[i]=u[i-1]+u[i-2]; return uFibonacci(6)
输出:
[0, 1, 1, 2, 3, 5]
别人写的参考,似乎有点问题
输入:
def fib(n): """Display the n first terms of Fibonacci sequence""" a, b = 0, 1 i = 0 while i < n: print(b) a, b = b, a+b i +=1
fib(6)输出:
1 1 2 3 5 8
Exercise: Quicksort
关键:
qsort(less_than) + [pivot] + qsort(greater_equal)
Implement the quicksort algorithm, as defined by wikipedia
伪代码: function quicksort(array) var list less, greater if length(array) < 2 return array select and remove a pivot value pivot from array for each x in array if x < pivot + 1 then append x to less else append x to greater return concatenate(quicksort(less), pivot, quicksort(greater))函数定def qsort(lst):
""" Quick sort: returns a sorted copy of the list. """ if len(lst) <= 1: return lst pivot, rest = lst[0], lst[1:] # Could use list comprehension: # less_than = [ lt for lt in rest if lt < pivot ] less_than = [] for lt in rest: if lt < pivot: less_than.append(lt) # Could use list comprehension: # greater_equal = [ ge for ge in rest if ge >= pivot ] greater_equal = [] for ge in rest: if ge >= pivot: greater_equal.append(ge) return qsort(less_than) + [pivot] + qsort(greater_equal)
#理解快速排序,任意数组,将其第一个元素定为pivot,然后将数组分为两个部分,pivot和数组
#剩余部分rest,将剩余部分与pivot作对比,将rest分为两个部分,大于等于pivot的元素,放
#在greater_quanl中,比pivot小的元素放在less_than中,然后同样对得到的两个新的序列进
#行上述操作,知道最后数组的长度为1,完成所有排序调用:
lst=[9,4,5,6] qsort(lst)1.2.5.2. Importing objects from modules
输入:
import os os print(os.listdir('.'))输出:
['.idea', '.ipynb_checkpoints', 'BoardingPass_MyNameOnInSight.png', 'Industry AI tianchi', 'kaggle-quora-question-pairs-master.zip', 'mobike', 't.xlsx', 'Thumbs.db', 'UAI算法比赛', 'Untitled.ipynb', 'Untitled1.ipynb', 'Untitled2.ipynb', 'Untitled3.ipynb', '人工胰腺', '天池资料', '数据挖掘比赛入门_以去年阿里天猫推荐比赛为例.docx', '新手入门四课时.zip']
输入:
os.remove("x.xlsx") os.listdir('.')输出:
['.idea', '.ipynb_checkpoints', 'BoardingPass_MyNameOnInSight.png', 'Industry AI tianchi', 'kaggle-quora-question-pairs-master.zip', 'mobike', 't.xlsx', 'Thumbs.db', 'UAI算法比赛', 'Untitled.ipynb', 'Untitled1.ipynb', 'Untitled2.ipynb', 'Untitled3.ipynb', 'x.xlsx', '人工胰腺', '天池资料', '数据挖掘比赛入门_以去年阿里天猫推荐比赛为例.docx', '新手入门四课时.zip']1.2.5.3. Creating modules
创建模块demo2.py,其文件内容如下
def print_b(): "Prints b." print 'b' def print_a(): "Prints a." print 'a' # print_b() runs on import print_b() if __name__ == '__main__': # print_a() is only executed when the module is run directly. print_a()其中的 if __name__ == '__main__' 这一语句可以这样理解
通俗的理解
__name__ == '__main__':假如你叫小明.py,在朋友眼中,你是小明(__name__ == '小明');在你自己眼中,你是你自己(__name__ == '__main__')。if __name__ == '__main__'的意思是:当.py文件被直接运行时,if __name__ == '__main__'之下的代码块将被运行;当.py文件以模块形式被导入时,if __name__ == '__main__'之下的代码块不被运行demo2.py中定义了两个函数,如果想在别的文件中调用这两个函数,那么执行如下命令
from demo2 import print_a, print_b #从自定义的模块的demo2中调用print_a和print_b两个函数 print_a() print_b()输出:
a b1.2.7.1.
osmodule: operating system functionality输入:
import os print(os.getcwd()) #获取当前路径 print(os.listdir(os.curdir))#列举当前路径下所有存在文件 os.mkdir('junkdir') #创建新的路径目录 print(os.listdir(os.curdir)) os.rename('junkdir', 'foodir')#将路径目录重命名 print(os.listdir(os.curdir)) os.rmdir('foodir') #删除新的路径 print(os.listdir(os.curdir))输出:
D:\emmmmmm\test ['.ipynb_checkpoints', 'Untitled.ipynb'] ['.ipynb_checkpoints', 'junkdir', 'Untitled.ipynb'] ['.ipynb_checkpoints', 'foodir', 'Untitled.ipynb'] ['.ipynb_checkpoints', 'Untitled.ipynb']

