inline
打开 Linux 内核源代码,会发现内核在定义C语言函数时,有很多都带有 “inline”关键字,请看下图,那么这个关键字有什么作用呢?
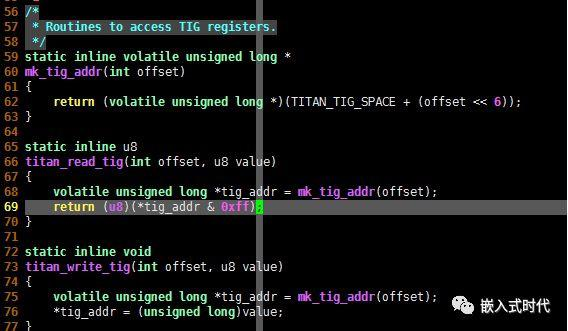
inline 关键字的作用
在C语言程序开发中,inline 一般用于定义函数,inline 函数也被称作“内联函数”,C99 和 GNU C 均支持内联函数。那么在C语言中,内联函数和普通函数有什么不同呢?其实,从 inline 这个名字就应该能看出一点它的性质了——内联函数会在它被调用的位置上展开,这一点表现的和 define 宏定义是非常相似的。
将被调用的函数代码展开,操作系统就无需再在为被调用函数做申请栈帧和回收栈帧的工作,而且,由于编译器会把被调用的函数代码和函数本身放在一起优化,所以也有进一步优化C语言代码,提升效率的可能。
每发生一次函数调用,操作系统就要在程序的栈空间申请一块内存区域(栈帧),供被调用函数使用,被调用函数执行完毕后,操作系统还要回收这些内存。
不过,天下没有免费的午餐,C语言程序要实现内联函数的上述特性是要付出一定的代价的。普通函数只需要编译出一份,就可以被所有其他函数调用,而内联函数没有严格意义上的“调用”,它只是将自身的代码展开到被调用处的,这么做无疑会使整个C语言代码变长,也就意味着占用更多的内存空间,以及更多的指令缓存。
显然,如果滥用内联函数,cpu 的指令缓存肯定是不够用的,这会导致 cpu 缓存命中率降低,反而可能会降低整个C语言程序的效率。因此,建议把那些对时间要求比较高,且C语言代码长度比较短的函数定义为内联函数。如果在C语言程序开发中的某个函数比较大,又会被反复调用,并且没有特别的时间限制,是不适合把它做成内联函数的。
在 Linux 内核中,内联函数常常使用 static 修饰,例如:
1 static inlinevoid set_value(unsignedint val) 2 { 3 ... 4 }
需要注意的是,内联函数必须在使用之前就定义好,否则编译器没法把这个函数展开。Linux 内核中经常像下面这样,将内联函数放在调用它的函数前面,请看C语言代码:
1 static inlinevoid set_value(unsignedint val) 2 { 3 ... 4 } 5 6 int test_inline() 7 { 8 set_value(3); 9 ... 10 }
所以,Linux 内核常常把内联函数定义在头文件里,这样在其他C语言代码文件开头包含头文件时,能确保内联函数在文件的最开始,无需再写额外的声明语句。
这也解释了为什么 Linux 内核为何常常使用 static 修饰内联函数,因为可以避免函数的重复定义。
前文提到内联函数的表现有些像 define 宏定义,但是为了类型安全和易读性,应优先使用内联函数而不是复杂的宏。下面通过实例进一步分析 inline 内联函数的特性。
inline内联函数的“展开代码”是什么意思?
使用过 define 写 C语言代码的朋友应该都知道,编译器在编译 C语言代码时,会将 define 定义的宏展开,而不是像普通函数那样使用 call 指令调用,例如下面这段C语言代码:
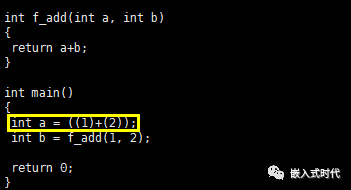
1 #include <stdio.h> 2 3 #define d_add(a, b) ((a)+(b)) 4 5 int f_add(int a, int b) 6 { 7 return a+b; 8 } 9 10 int main() 11 { 12 int a = d_add(1, 2); 13 int b = f_add(1, 2); 14 return0; 15 }
使用 gcc -E 编译这段C语言代码,能够得到预处理后的代码如下,显然 define 定义的宏被展开了,请看:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号