
ASE第二次结对编程——Code Search
复现极限模型
codenn 原理
其原理大致是将代码特征映射到一个向量,再将描述文字也映射到一个向量,将其cos距离作为loss训练。
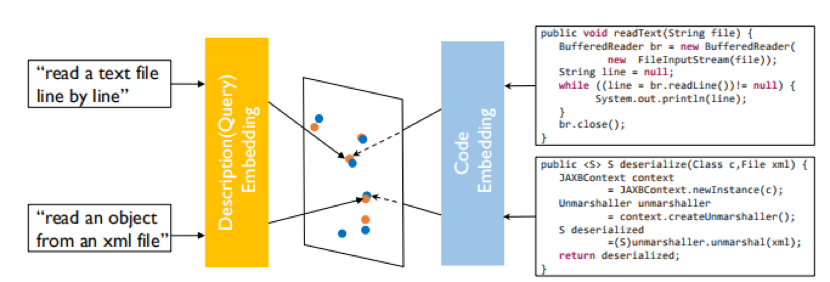
对于代码特征,原论文提取了函数名、调用API序列和token集;对于描述文字,通常选取docstring(Python)或函数上方或内部注释(JavaScript)。对于函数名、token集,会按照驼峰命名和下划线命名进一步划分成更小的词法单元,而API序列则保留不再分割。
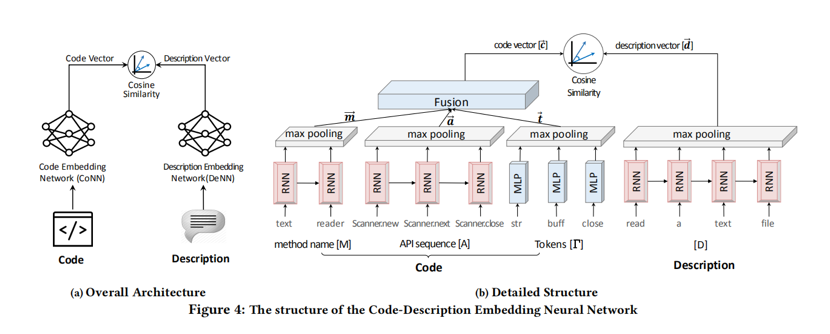
所有的这些词素,对于有序的会使用RNN或其变种处理,再将RNN每一个词的输出进行池化;对于无序的,会用MLP(多层感知机,但是论文作者其实只用了单层)处理再进行池化。所有的代码特征池化得到的特征向量再经过一层全连层,使其维度与描述向量的维度一致。
最后以cos距离作为loss。为了便于batch处理这些变长的数据,这些数据会被截断或者填充到某一个长度,截断截尾,填充填后。
原模型使用了4个评价指标Precision@K、MAP、MRR和NDCG,具体可以参看这个Slides:Information Retrieval - web.stanford.edu 。这里就介绍前两个,首先是Precision@K,这个同下面Mao Yutao同学的top K,不再赘述;MAP除了n之外也有个参数K',其值就是K取1到K'的所有Precision@K的平均值;两个指标都是取值0到1,越高越好。
复现的结果
| k | Success Rate | MAP | nDCG |
|---|---|---|---|
| 1 | 0.28 | 0.28 | 0.28 |
| 5 | 0.55 | 0.39 | 0.42 |
| 10 | 0.68 | 0.40 | 0.46 |
模型的优缺点
优点:
- 提供了一种端到端的code search 的简单实现
缺点:
- 模型过于粗暴,没有考虑code 在结构上的逻辑性
- 从case study 上可以看出, 结果并没有百度搜索来得好。
Case Study
> sort
========
def counting_sort(collection):
"""Pure implementation of counting sort algorithm in Python
:param collection: some mutable ordered collection with heterogeneous
comparable items inside
:return: the same collection ordered by ascending
Examples:
>>> counting_sort([0, 5, 3, 2, 2])
[0, 2, 2, 3, 5]
>>> counting_sort([])
[]
>>> counting_sort([-2, -5, -45])
[-45, -5, -2]
"""
if collection == []:
return []
coll_len = len(collection)
coll_max = max(collection)
coll_min = min(collection)
counting_arr_length = coll_max + 1 - coll_min
counting_arr = [0] * counting_arr_length
for number in collection:
counting_arr[number - coll_min] += 1
for i in range(1, counting_arr_length):
counting_arr[i] = counting_arr[i] + counting_arr[i - 1]
ordered = [0] * coll_len
for i in reversed(range(0, coll_len)):
ordered[counting_arr[collection[i] - coll_min] - 1] = collection[i]
counting_arr[collection[i] - coll_min] -= 1
return ordered
========
def quick_sort(arr, simulation=False):
""" Quick sort
Complexity: best O(n log(n)) avg O(n log(n)), worst O(N^2)
"""
iteration = 0
if simulation:
print('iteration', iteration, ':', *arr)
arr, _ = quick_sort_recur(arr, 0, len(arr) - 1, iteration, simulation)
return arr
========
def sort_1d(input):
return np.sort(input), np.argsort(input)
========
def pancake_sort(arr):
"""
Pancake_sort
Sorting a given array
mutation of selection sort
reference: https://www.geeksforgeeks.org/pancake-sorting/
Overall time complexity : O(N^2)
"""
len_arr = len(arr)
if len_arr <= 1:
return arr
for cur in range(len(arr), 1, -1):
index_max = arr.index(max(arr[0:cur]))
if index_max + 1 != cur:
if index_max != 0:
arr[:index_max + 1] = reversed(arr[:index_max + 1])
arr[:cur] = reversed(arr[:cur])
return arr
========
def np_sort_impl(a):
res = a.copy()
res.sort()
return res
> list to numpy
========
def mulmatmat(matlist1, matlist2, K):
"""
Multiplies two matrices by multiplying each row with each column at
a time. The multiplication of row and column is done with mulrowcol.
Firstly, the second matrix is converted from a list of rows to a
list of columns using zip and then multiplication is done.
Examples
========
>>> from sympy.matrices.densearith import mulmatmat
>>> from sympy import ZZ
>>> from sympy.matrices.densetools import eye
>>> a = [
... [ZZ(3), ZZ(4)],
... [ZZ(5), ZZ(6)]]
>>> b = [
... [ZZ(1), ZZ(2)],
... [ZZ(7), ZZ(8)]]
>>> c = eye(2, ZZ)
>>> mulmatmat(a, b, ZZ)
[[31, 38], [47, 58]]
>>> mulmatmat(a, c, ZZ)
[[3, 4], [5, 6]]
See Also
========
mulrowcol
"""
matcol = [list(i) for i in zip(*matlist2)]
result = []
for row in matlist1:
result.append([mulrowcol(row, col, K) for col in matcol])
return result
========
def getperm(spec, charpair):
spatial = (i for i, c in enumerate(spec) if c not in charpair)
if spec is not rhs_spec:
spatial = sorted(spatial, key=lambda i: rhs_spec.index(spec[i]))
return (spec.index(charpair[0]), spec.index(charpair[1])) + tuple(spatial)
========
def evaluation3(m):
def ev3(ma):
sc = 0
for mi in ma:
j = 0
while j < len(mi) - 10:
if mi[j:j + 11] == [1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0]:
sc += 40
j += 7
elif mi[j:j + 11] == [0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1]:
sc += 40
j += 4
else:
j += 1
return sc
return ev3(m) + ev3(list(map(list, zip(*m))))
========
def list_sku_info(cli_ctx, location=None):
from ._client_factory import _compute_client_factory
def _match_location(l, locations):
return next((x for x in locations if x.lower() == l.lower()), None)
client = _compute_client_factory(cli_ctx)
result = client.resource_skus.list()
if location:
result = [r for r in result if _match_location(location, r.locations)]
return result
========
@property
def releaselinks(self):
""" return sorted releaselinks list """
l = sorted(map(BasenameMeta, self.basename2link.values()), reverse=True)
return [x.obj for x in l]
> convert list to numpy array
========
def to_list_if_array(val):
if isinstance(val, np.ndarray):
return val.tolist()
else:
return val
========
def to_one_dimensional_array(iterator):
"""convert a reader to one dimensional array"""
array = []
for i in iterator:
if type(i) == list:
array += i
else:
array.append(i)
return array
========
def to_representation(self, obj):
return OrderedDict(obj)
========
def ascii_art(*obj, **kwds):
"""
Return an ASCII art representation
INPUT:
- ``*obj`` -- any number of positional arguments, of arbitrary
type. The objects whose ascii art representation we want.
- ``sep`` -- optional ``'sep=...'`` keyword argument (or ``'separator'``).
Anything that can be converted to ascii art (default: empty ascii
art). The separator in-between a list of objects. Only used if
more than one object given.
- ``baseline`` -- (default: 0) the baseline for the object
- ``sep_baseline`` -- (default: 0) the baseline for the separator
OUTPUT:
:class:`AsciiArt` instance.
EXAMPLES::
sage: ascii_art(integral(exp(x+x^2)/(x+1), x))
/
|
| 2
| x + x
| e
| ------- dx
| x + 1
|
/
We can specify a separator object::
sage: ident = lambda n: identity_matrix(ZZ, n)
sage: ascii_art(ident(1), ident(2), ident(3), sep=' : ')
[1 0 0]
[1 0] [0 1 0]
[1] : [0 1] : [0 0 1]
We can specify the baseline::
sage: ascii_art(ident(2), baseline=-1) + ascii_art(ident(3))
[1 0][1 0 0]
[0 1][0 1 0]
[0 0 1]
We can determine the baseline of the separator::
sage: ascii_art(ident(1), ident(2), ident(3), sep=' -- ', sep_baseline=-1)
[1 0 0]
-- [1 0] -- [0 1 0]
[1] [0 1] [0 0 1]
If specified, the ``sep_baseline`` overrides the baseline of
an ascii art separator::
sage: sep_line = ascii_art('\\n'.join(' | ' for _ in range(6)), baseline=6)
sage: ascii_art(*Partitions(6), separator=sep_line, sep_baseline=0)
| | | | | | | | | | *
| | | | | | | | | ** | *
| | | | | | *** | | ** | * | *
| | | **** | | *** | * | ** | ** | * | *
| ***** | **** | * | *** | ** | * | ** | * | * | *
****** | * | ** | * | *** | * | * | ** | * | * | *
TESTS::
sage: n = var('n')
sage: ascii_art(sum(binomial(2 * n, n + 1) * x^n, n, 0, oo))
/ _________ \\
-\\2*x + \\/ 1 - 4*x - 1/
-------------------------
_________
2*x*\\/ 1 - 4*x
sage: ascii_art(list(DyckWords(3)))
[ /\\ ]
[ /\\ /\\ /\\/\\ / \\ ]
[ /\\/\\/\\, /\\/ \\, / \\/\\, / \\, / \\ ]
sage: ascii_art(1)
1
"""
separator, baseline, sep_baseline = _ascii_art_factory.parse_keywords(kwds)
if kwds:
raise ValueError('unknown keyword arguments: {0}'.format(list(kwds)))
if len(obj) == 1:
return _ascii_art_factory.build(obj[0], baseline=baseline)
if not isinstance(separator, AsciiArt):
separator = _ascii_art_factory.build(separator, baseline=sep_baseline)
elif sep_baseline is not None:
from copy import copy
separator = copy(separator)
separator._baseline = sep_baseline
obj = map(_ascii_art_factory.build, obj)
return _ascii_art_factory.concatenate(obj, separator, empty_ascii_art,
baseline=baseline)
========
def to_numpy(self):
return self.string_sequence.to_numpy()
从上面的case study 的结果来看,可以看出,对于比较简单地query (如 sort) 这样的搜索结果还是比较令人满意的。但是对于list 转化为 numpy 这样的请求,如果输入的query 表达不清晰,可能不能得到很好地效果。
总体来说,训练loss 最小的 model checkpoint 体验效果没有baidu 搜索引擎来的好。
结果的可视化分析
(由队友吴雪晴同学精心完成)
我们通过PCA将code embedding与text embedding投影到二维;下图为所有测试数据的embedding的散点图。
https://img2018.cnblogs.com/blog/1342180/201910/1342180-20191015211923865-2032500903.png
可以看出,code embedding与text embedding尺度上不完全一致,这进一步印证选择cosine similarity衡量相似度是正确的。
我们绘制了测试集中部分代码embedding与其描述的embedding在embedding space中的分布。下面两幅图表示code 0、desc 0、code 1、desc 1的embedding分别在原始embedding space中与L2归一化后的embedding space中分布,其中desc 0为"manage pende entry",code 0为其对应代码;desc 1为"Read mesh datum file",code 1为其对应代码。
https://img2018.cnblogs.com/blog/1342180/201910/1342180-20191015214021869-281998976.png
https://img2018.cnblogs.com/blog/1342180/201910/1342180-20191015214038003-1432350826.png
可以看出,语义上相关的代码与文本embedding相似度高、无关的代码或文本embedding相似度低,说明我们的模型是有效的。
提出的改进
改进方法
我个人认为CODEnn框架end-to-end training的思路很好,但是对code和对文本的embedding方式可以改进。另外,模型的评估方式也有一定的问题。我能想到的改进方法如下:
改用更好的encoder
如缺点中所说,我认为CODEnn的code embedding network不能充分编码代码语义。个人认为可以改为其它能够捕捉更多信息的code embedding方法,如code2vec;或者,由于代码可以表示为ast树形结构,可以用Tree LSTM或GNN。
预训练模型
同样如缺点中所说,质量高的(code, description) pair较少,即可以用于将代码embedding与文本embedding投影到同一个embedding space的数据较少;然而无监督的数据,无论是代码(github上有大量开源代码)还是文本(互联网上无监督语料极多)都几乎是无限的。我们可以用已有的大量无监督代码训练encoder、使之已经能表达一定的语义,然后在(code, description) pair数据上进行finetuning。
预训练text embedding network
用语言模型对language encoder进行预训练是NLP中的常用方法。网络上,LSTM和更新的Transformer都有相应的预训练模型发布;也可以自己用与代码有关的文本语料(如爬取stackoverflow的文本)预训练一个模型。
预训练code embedding network
对于如何训练code embedding network,有两种可能的思路:
- 利用有监督数据训练,如code2vec利用代码的属性作为监督,训练code embedding方法。code2vec自己也有发布预训练模型,可以直接使用。
- 训练“语言模型”:可以用类似NLP中语言模型预训练的方法,通过mask掉代码中的某一行或一个token、要求模型通过上下文预测被mask的部分。现在也有一些类似的工作(如The Effectiveness of Pre-trained Code Embeddings),但是效果并不算好。
评价队友
这次结对编程的队友吴雪晴和许佳琪都非常非常的大佬,我主要是国庆假期期间做了代码方面的一些工作,在博客提交这段时间忙于学校的一些事情,一直处于离线状态,队友门的理解让我非常感动,在这里和队友还有助教道歉。可以看到雪晴对于NLP, 图神经网络了解非常深(之后加入了我们model组肯定是一个很大的主力),此外雪晴还做了很多非常精美的可视化,然我们能够更加理解model的原理和performance。许佳琪同学对于deep code search 这篇论文的理解很深,我们一些论文的细节不清楚都可以询问他。总的来说,我有点划水了,多谢两位大佬带我,嘻嘻。
