

软工实践|结对第二次—文献摘要热词统计及进阶需求
班级:软件工程1916|W
作业:结对第二次—文献摘要热词统计及进阶需求
结对学号:221600418 黄少勇、 221600420 黄种鑫
课程目标:学会使用Git、提高团队协作能力
Github地址:基础需求、进阶需求
分工:
- 黄少勇--词频统计代码实现,性能优化
- 黄种鑫--爬虫代码实现,可视化实现,单元测试
目录
Github 签入记录
基本需求:

进阶需求:

PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| • Estimate | • 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 750 | 980 |
| • Analysis | • 需求分析 (包括学习新技术) | 120 | 150 |
| • Design Spec | • 生成设计文档 | 20 | 20 |
| • Design Review | • 设计复审 | 10 | 10 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| • Design | • 具体设计 | 30 | 40 |
| • Coding | • 具体编码 | 400 | 550 |
| • Code Review | • 代码复审 | 100 | 120 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 60 | 80 |
| Reporting | 报告 | 50 | 50 |
| • Test Report | • 测试报告 | 20 | 20 |
| • Size Measurement | • 计算工作量 | 10 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 810 | 1040 |
解题思路
在拿到这个题目后,我们俩通过分析,确定基本需求即为进阶需求的特例(进阶需求中, -m 参数的值取为 1, -n 参数的值取为 10, -w 参数的值取为 0 即为基本需求的要求),所以我们一开始就确定直接开发进阶需求,通过给定参数默认值的方式,完成基本需求的任务。
本次需求包含三部分:字符统计、单词(词组)统计、行数统计,而这三个可以看成一个连续的过程,所以我们的思路一开始也是想把三部分整合在一起完成,即:打开一次文件,按行读取(实现了行数统计),将读取出来的行,进行字符统计,并且使用 String.split() 方法将整行切割为单词,实现单词的统计,进而按照给定的 -m 参数,将分隔完的单词进行拼装,统计出长度为m的词组。但是后来详细分析需求后,发现题目要求将三个功能独立出来,所以最终决定把三个功能分开实现,即:实现三个方法,分别实现打开文件并统计字符、单词(词组)、行数。
另外,为了使处理命令行参数和词频统计等功能分隔开,并且实现相对独立,我们决定实现一个 Signal 类。该类主要完成对命令行的分析,为词频统计提供参数。
设计实现过程
由以上思路可以得到,我们需要两个类—— WordCount 类及 Signal 类。WordCount 类中至少实现三个方法:字符统计、单词(词组)统计、行数统计, Signal 类至少实现一个方法:命令行分析。类图设计如下:

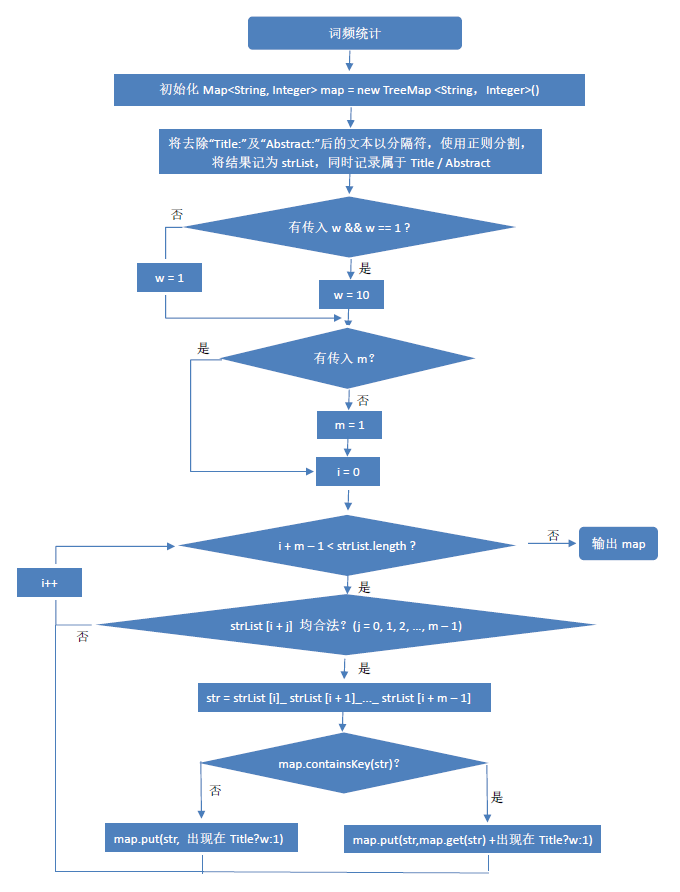
词频统计流程图:
行数、字符数统计流程图:


性能分析及优化
以下测试均使用爬取得到的2018年CVPR论文数据,使用参数 -m 2,使用工具JProfiler得到。
概览:

优化前各方法耗时:

通过分析各个方法的耗时情况,我们得到,程序的瓶颈主要在 WordCount.setWordNumber() 方法上,因此我们着重对该方法优化。
private void setWordNumber() {
String line;
try (BufferedReader br = new BufferedReader(new FileReader(inFile))) {
while ((line = br.readLine()) != null) {
line = line.toLowerCase();
// 按行读取,并判断是否为Title行
if (line.indexOf("title:") == 0) {
weight = signal.getwValue();
line = line.replaceFirst("title:", "");
}
if (line.indexOf("abstract:") == 0) {
weight = 1;
line = line.replaceFirst("abstract:", "");
}
splitLine(line); // 将每一行进行拆分处理
}
} catch (IOException e) {
e.printStackTrace();
}
}
// 判断一个单词是否是题目要求的合法单词
private boolean isWord(String s) {
return s.length() >= 4 && Character.isLetter(s.charAt(0)) && Character.isLetter(s.charAt(1)) && Character.isLetter(s.charAt(2)) && Character.isLetter(s.charAt(3));
}
private void splitLine(String line) {
if(line.isEmpty()){
return;
}
if(Character.isLetterOrDigit(line.charAt(0))) {
deviation = -1;
}
else {
deviation = 0;
}
String[] str = line.split("[^a-z0-9]"); // 切割得到每个单词
for (String aStr : str) {
if (!"".equals(aStr)) { // 去掉切割产生的空白后,将单词加入arrayList待后续组词使用
arrayList.add(aStr);
if (isWord(aStr)) { // 判断单词单词是否合法
wordNumber += 1;
}
}
}
str = line.split("[a-z0-9]"); // 切割得到单词间的分隔符
for(String aStr : str) {
if(!"".equals(aStr)) {
separator.add(aStr);
}
}
setMap(); // 拼接单词,组成长度为m的词组
arrayList.clear();
separator.clear();
word.clear();
}
通过观察JProfiler的数据,我们发现, WordCount.setWordNumber() 中,耗时最多的为 WordCount.splitLine() 中的 String.split() 耗时最多。
查阅资料后,网上对于 split() 方法的优化,主要是使用 String.indexOf() 方法或 StringTokenizer() 方法实现,但是这两个方法一次仅能查找一个分隔符,而本次作业中分隔符种类较多,自行实现起来可能较为麻烦,而且我们查阅了JAVA中的 split() 源码,发现其也是采用的 indexOf() 实现,故我们放弃了手动使用 indexOf() 实现分割。
最后,我们尝试将 split() 的调用,改为使用正则实现:
private void splitLine(String line) {
// ...
Pattern r = Pattern.compile("[a-z0-9]+");
Matcher m = r.matcher(line);
while (m.find()){
arrayList.add(m.group(0));
if (isWord(m.group(0))) {
wordNumber += 1;
}
Pattern r2 = Pattern.compile("[^a-z0-9]+");
Matcher m2 = r2.matcher(line);
while (m2.find()){
separator.add(m2.group(0));
}
// ...
}
改用正则优化第一次后各方法耗时:

使用正则后,时间少了 500ms 左右,算是有些许优化,但是效果并不明显,所以我们针对耗时第二多的 isWord() 方法进行改进。 isWord() 虽然简单,但是由于调用次数过多(每个单词都得调用两次),所以总耗时过大。我们通过加入一个辅助数组,用来记录每个单词是否合法,这样子可以把 isWord() 的调用次数变为原来的一半。修改如下:
private void splitLine(String line) {
// ...
while (m.find()){
arrayList.add(m.group(0));
if (isWord(m.group(0))) {
wordNumber += 1;
isLegalWord.add(true); // 如果是合法单词,就把对应位置为true
}
else{
isLegalWord.add(false);
}
}
// ...
setMap();
// ...
}
private void setMap() {
combineWord();
// ...
}
// 将单词拼接为长度为m的词组
private void combineWord() {
for (int i = 0; i < arrayList.size() - signal.getmValue() + 1; i++) {
boolean flag = true;
for (int j = 0; j < signal.getmValue() && flag; j++) {
if (!isLegalWord.get(i+j)) {
flag = false;
}
}
// ...
}
}
优化第二次后各方法耗时:

加入辅助数组后,时间又减少了 500ms 左右。
至此,在两次优化后,运行时间能够减少 1s 左右。
关键代码
行数统计
// 提供一个获取行数的接口,供外部调用
public int getLineNumber() {
return lineNumber;
}
// 生成行数,为私有方法,供构造函数调用
private void setLineNumber() {
String line;
try (BufferedReader br = new BufferedReader(new FileReader(inFile))) {
while ((line = br.readLine()) != null) { // 按行读取文件
if(!line.trim().isEmpty()){ // 去掉行首行尾的空白后,判断是否为空行
lineNumber++;
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
字符数统计
// 提供一个获取字符数的接口,供外部调用
public int getCharacterNumber() {
return characterNumber;
}
// 生成字符数,为私有方法,供构造函数调用
private void setCharacterNumber() {
int ch;
try (FileReader fr = new FileReader(inFile)) {
while ((ch = fr.read()) != -1) { // 逐字节读取文本
if(ch != 13){ // 如果读取到的字符不为 \r 时字符数加1
// 因为题目要求的换行符为\r\n(为一个整体),
// 如果不跳过其中一个,会导致最终字符数会比实际字符数多出一倍行数,
// 所以选择其中的一个即可,我们选择了 \r。
characterNumber++;
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
单词数(词频)统计
// 提供一个获取单词数的接口,供外部调用
public int getWordNumber() {
return wordNumber;
}
// 生成单词数,为私有方法,供构造函数调用
private void setWordNumber() {
String line;
try (BufferedReader br = new BufferedReader(new FileReader(inFile))) {
while ((line = br.readLine()) != null) {
// 逐行读取,并将每行的内容转为小写,便于后续处理
line = line.toLowerCase();
// 判断是否为Title行或者Abstract行,调整权重,用于统计词频(如果为基础需求,默认的权重为1)
if (line.indexOf("title:") == 0) {
weight = signal.getwValue();
line = line.replaceFirst("title:", "");
}
if (line.indexOf("abstract:") == 0) {
weight = 1;
line = line.replaceFirst("abstract:", "");
}
splitLine(line); // 将每一行进行拆分处理
}
} catch (IOException e) {
e.printStackTrace();
}
}
// 判断一个单词是否是题目要求的合法单词
private boolean isWord(String s) {
return s.length() >= 4 && Character.isLetter(s.charAt(0)) && Character.isLetter(s.charAt(1)) && Character.isLetter(s.charAt(2)) && Character.isLetter(s.charAt(3));
}
private void splitLine(String line) {
if(line.isEmpty()){
return;
}
// 判断首字母是否为字母,用于后续拼接词组时,将单词与分隔符正确拼接
if(Character.isLetterOrDigit(line.charAt(0))) {
deviation = -1;
}
else {
deviation = 0;
}
// 正则匹配单词
Pattern r = Pattern.compile("[a-z0-9]+");
Matcher m = r.matcher(line);
while (m.find()){
arrayList.add(m.group(0)); // 将单词加入arrayList待后续组词使用
if (isWord(m.group(0))) {
wordNumber += 1;
isLegalWord.add(true); // 如果是合法单词,就把对应位置为true
}
else{
isLegalWord.add(false);
}
}
// 正则匹配分隔符
Pattern r2 = Pattern.compile("[^a-z0-9]+");
Matcher m2 = r2.matcher(line);
while (m2.find()){
separator.add(m2.group(0));
}
setMap(); // 拼接单词,组成长度为m的词组
// 清空本行的内容,等待处理下一行
arrayList.clear();
separator.clear();
word.clear();
isLegalWord.clear();
}
// 将单词拼接为长度为m的词组,并统计词组词频
private void setMap() {
combineWord();
for (String aWord : word) {
if (map.containsKey(aWord)) {
map.put(aWord, map.get(aWord) + weight);
} else {
map.put(aWord, weight);
}
}
}
// 将单词拼接为长度为m的词组
private void combineWord() {
for (int i = 0; i < arrayList.size() - signal.getmValue() + 1; i++) {
boolean flag = true;
// 判断从i开始的m个单词是否均为合法单词,若是,则可组成一个长度为m的词组
for (int j = 0; j < signal.getmValue() && flag; j++) {
if (!isLegalWord.get(i+j)) {
flag = false;
}
}
if (flag) {
// 如果可拼接成长度为m的词组,则将这m个单词与其中的分隔符进行拼接
StringBuilder s = new StringBuilder(arrayList.get(i));
for(int j = 1; j < signal.getmValue(); j++) {
s.append(separator.get(i + j + deviation)).append(arrayList.get(i + j));
}
word.add(s.toString());
}
}
}
爬虫部分
爬虫使用的是JAVA实现,由于对于一些爬虫框架并不熟悉,所以使用的是JAVA原生的URL类请求网页内容,使用正则进行数据匹配。代码如下:
// 封装的请求函数,用于发起请求并返回页面HTML内容
private static String getHtmlContent(String uri) {
StringBuilder result = new StringBuilder();
try {
String baseURL = "http://openaccess.thecvf.com";
URL url = new URL(baseURL + "/" + uri);
URLConnection connection = url.openConnection();
connection.connect();
BufferedReader in = new BufferedReader(new InputStreamReader(connection.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
result.append(line);
}
} catch (IOException e) {
e.printStackTrace();
}
return String.valueOf(result);
}
public static void main(String[] args) {
// 加载论文类型的 CSV 表格
// 由于未在官网上找到论文类型,因此使用在Github(https://github.com/amusi/daily-paper-computer-vision/blob/master/2018/cvpr2018-paper-list.csv)上其他人搜集好的数据
Map<String, String> map = new HashMap<>();
try (BufferedReader bufferedReader = new BufferedReader(new FileReader(new File("cvpr/cvpr2018-paper-list.csv")))) {
String line;
// 逐行读取CSV表格,并切割得到其论文类型及论文名,并以论文名为键,论文类型为值,生成一个HashMap
while ((line = bufferedReader.readLine()) != null) {
String[] list = line.split(",");
map.put(list[2].toLowerCase(), list[1]);
}
} catch (IOException e) {
e.printStackTrace();
}
// 获取CVPR官网首页内容
String result = getHtmlContent("CVPR2018.py");
// 获取到首页后,使用正则匹配,得到论文详细内容的链接,并逐个发起请求,继续使用正则匹配详情页,得到论文题目、摘要、作者信息等内容
/*
首页HTML样式
<dt class="ptitle"><br><a href="content_cvpr_2018/html/Das_Embodied_Question_Answering_CVPR_2018_paper.html">Embodied Question Answering</a></dt>
*/
/*
详情页HTML样式
<div id="papertitle">title</div><div id="authors"><br><b><i>authors</i></b>; where</div><font size="5"><br><b>Abstract</b></font><br><br><div id="abstract" >abstract</div><font size="5"><br><b>Related Material</b></font><br><br>[<a href="url">pdf</a>]
*/
String pattern = "<dt class=\"ptitle\"><br><a href=\"(.*?)\">(.*?)</a></dt>";
String pattern2 = "<div id=\"papertitle\">(.*?)</div><div id=\"authors\"><br><b><i>(.*?)</i></b>; (.*?)</div><font size=\"5\"><br><b>Abstract</b></font><br><br><div id=\"abstract\" >(.*?)</div><font size=\"5\"><br><b>Related Material</b></font><br><br>\\[<a href=\"(.*?)\">pdf</a>]";
Pattern r = Pattern.compile(pattern);
Pattern r2 = Pattern.compile(pattern2);
Matcher m = r.matcher(result);
StringBuilder res = new StringBuilder();
int i = 0;
while (m.find()) {
String html = getHtmlContent(m.group(1));
System.out.println(i);
System.out.println("URL: " + m.group(1));
Matcher m2 = r2.matcher(html);
if (m2.find()) {
// 输出详细内容
System.out.println("Title: " + m2.group(1));
System.out.println("authors: " + m2.group(2));
System.out.println("Type: " + map.get(m2.group(1).split(",")[0].toLowerCase()));
System.out.println("Where: " + m2.group(3));
System.out.println("Abstract: " + m2.group(4));
System.out.println("PDF: " + m2.group(5).replace("../../", "http://openaccess.thecvf.com/"));
res.append(i).append("\r\n");
// res.append("Type: ").append(map.get(m2.group(1).split(",")[0].toLowerCase())).append("\r\n");
res.append("Title: ").append(m2.group(1)).append("\r\n");
// res.append("Authors: ").append(m2.group(2)).append("\r\n");
res.append("Abstract: ").append(m2.group(4)).append("\r\n");
// res.append("PDF: ").append(m2.group(5).replace("../../", "http://openaccess.thecvf.com/")).append("\r\n\r\n\r\n");
}
System.out.println();
System.out.println();
i++;
}
// 将内容写入文件
try (BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter(new File("cvpr/result.txt")))) {
bufferedWriter.write(String.valueOf(res));
} catch (IOException e) {
e.printStackTrace();
}
}
爬虫结果展示:

单元测试
使用 JUnit4 进行单元测试,测试了词频统计部分主要的四个函数,即:
WordCount.getCharacterNumber():字符数统计WordCount.getLineNumber():行数统计WordCount.getWordNumber():单词数统计WordCount.getList():词频统计
测试数据集为十个文本,分别为:空文本、全为空行的文本、字母数字分隔符随机交替出现的文本、混有空行的文本、混有非单词的文本、正常的单词文本等。
单元测试结果及代码覆盖率如下图:

覆盖率中,WordCount 类由于存在比较多的异常处理分支,故覆盖率只有86%,而命令行处理类 Signal 类由于在单元测试时未指定所有参数,故覆盖率也较低。
部分测试数据
测试数据:
file123&&&file123
123file
aaa
AAA
aaaa
AAAA
AaAa
测试结果:
charactors: 49
words: 5
lines: 7
<file123&&&file123>: 1
测试数据:
as!@#$!@$rwehhhkk***---===++==++
\t\n
\r\n
mmm&^&&&^^^
测试结果:
charactors: 38
words: 3
lines: 3
<aaaa>: 1
<fefeffffff>: 1
<file1daa>: 1
测试数据:
abcdefghijklmnopqrstuvwxyz
1234567890
,./;'[]\<>?:"{}|`-=~!@#$%^&*()_+
测试结果:
charactors: 76
words: 1
lines: 3
<abcdefghijklmnopqrstuvwxyz>: 1
遇到的困难及解决方法
困难描述
- 对于正则表达式不够熟练,使用起来不够顺手
- 对于爬虫框架不熟,爬虫代码可能较为啰嗦
解决尝试
查阅网上博客及相关教程
是否解决
正则相关已解决,爬虫框架由于时间问题没有深入了解
收获
对于正则表达式,有了进一步的认识,同时对于爬虫相关的东西也有了初步的印象,后续有时间可多多接触下。
评价你的队友
我的队友很nice,思路清晰,代码能力也不错
附加题
爬虫拓展
从网站综合爬取论文的除题目、摘要外其他信息。
由于未在官网上找到论文类型,因此使用在 Github 上其他人搜集好的数据。最终结果如下:

数据可视化
实现了论文作者的关系图。关系图使用 ECharts 框架实现可视化效果。数据来自爬虫得到的论文数据集,使用Java将原始数据生成ECharts所需要的XML数据格式。HTML代码如下:
<html>
<head>
<meta charset="utf-8">
<script src="echarts.js"></script>
<script src="dataTool.min.js"></script>
<script src="jquery-3.3.1.js"></script>
</head>
<body>
<div id="main" style="width: 100%;height:110%;"></div>
<script type="text/javascript">
var myChart = echarts.init(document.getElementById('main'));
myChart.showLoading();
$.get('cvpr_authors.gexf', function (xml) {
myChart.hideLoading();
var graph = echarts.dataTool.gexf.parse(xml);
var categories = [];
for (var i = 0; i < 30; i++) {
categories[i] = {
name: '' + i
};
}
graph.nodes.forEach(function (node) {
node.itemStyle = null;
node.value = node.symbolSize;
node.symbolSize *= 1;
node.label = {
normal: {
show: node.symbolSize > 30
}
};
node.category = node.attributes.modularity_class;
});
option = {
title: {
text: '作者关系图',
subtext: 'Default layout',
top: 'bottom',
left: 'right'
},
tooltip: {},
legend: [{
data: categories.map(function (a) {
return a.name;
})
}],
animationDuration: 1500,
animationEasingUpdate: 'quinticInOut',
series : [
{
name: '论文数',
type: 'graph',
layout: 'circular',
circular: {
rotateLabel: true
},
data: graph.nodes,
links: graph.links,
categories: categories,
roam: true,
focusNodeAdjacency: true,
itemStyle: {
normal: {
borderColor: '#fff',
borderWidth: 1,
shadowBlur: 10,
shadowColor: 'rgba(0, 0, 0, 0.3)'
}
},
label: {
position: 'right',
formatter: '{b}'
},
lineStyle: {
color: 'source',
curveness: 0.3
},
emphasis: {
lineStyle: {
width: 5
}
}
}
]
};
myChart.setOption(option);
}, 'xml');
</script>
</body>
</html>
效果图如下:
由于作者间关系过于复杂,所有数据生成的图会过密。

筛选部分可得下图:

鼠标移动到某个点上可查看这个作者的论文数及与其他作者的关系:

不足
- 由于没有对原始数据进行清洗,得到的图过于复杂,可能不方便直观的看出作者关系。
- 由于对数据在图上的分布位置没有合理规划,可能会导致部分点重叠或无法看清(还是因为数据未清洗)。

