理解爬虫原理
1. 简单说明爬虫原理
2. 理解爬虫开发过程
1).简要说明浏览器工作原理;
HTTP协议的工作原理:
a)连接:Web浏览器与Web服务器建立连接,打开一个称为socket(套接字)的虚拟文件,此文件的建立标志着连接建立成功。
b)请求:Web浏览器通过socket向Web服务器提交请求。HTTP的请求一般是GET或POST命令(POST用于FORM参数的传递)。GET命令的格式为:GET 路径/文件名 HTTP/1.0。文件名指出所访问的文件,HTTP/1.0指出Web浏览器使用的HTTP版本。
c)应答:Web浏览器提交请求后,通过HTTP协议传送给Web服务器。Web服务器接到后,进行事务处理,处理结果又通过HTTP传回给Web浏览器,从而在Web浏览器上显示出所请求的页面。
d)送GET命令: GET /mydir/index.html HTTP/1.0。主机名为www.mycomputer.com的Web服务器从它的文档空间中搜索子目录mydir的文件index.html。如果找到该文件,Web服务器把该文件内容传送给相应的Web浏览器。
e)关闭连接:当应答结束后,Web浏览器与Web服务器必须断开,以保证其它Web浏览器能够与Web服务器建立连接。
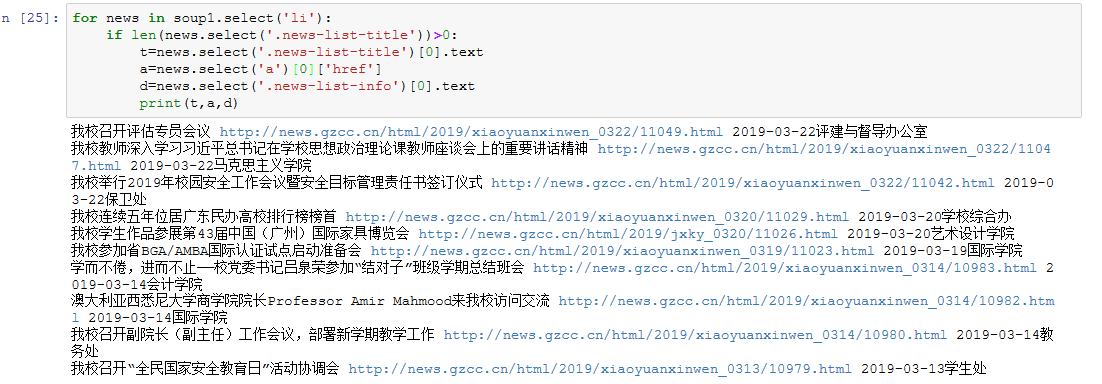
2).使用 requests 库抓取网站数据;
requests.get(url) 获取校园新闻首页html代码
import requests
res=requests.get('http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0322/11042.html')
res.encoding='utf-8'
res.text
3).了解网页
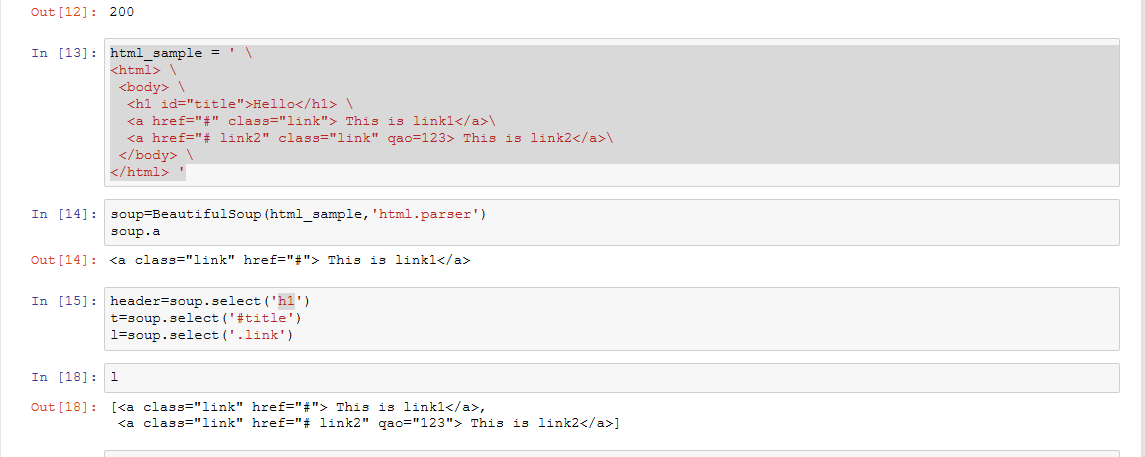
写一个简单的html文件,包含多个标签,类,id
<html>
<body>
<h1 id="title">Hello</h1>
<a href="#" class="link"> This is link1</a><a href="#link2" class="link" num=2019> This is link2</a>
<p id="info">This is info
</body>
</html>'
4).使用 Beautiful Soup 解析网页;
通过BeautifulSoup(html_sample,'html.parser')把上述html文件解析成DOM Tree
select(选择器)定位数据
找出含有特定标签的html元素
找出含有特定类名的html元素
找出含有特定id名的html元素
3.提取一篇校园新闻的标题、发布时间、发布单位
url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html'