

Java提高——常见Java集合实现细节(1)
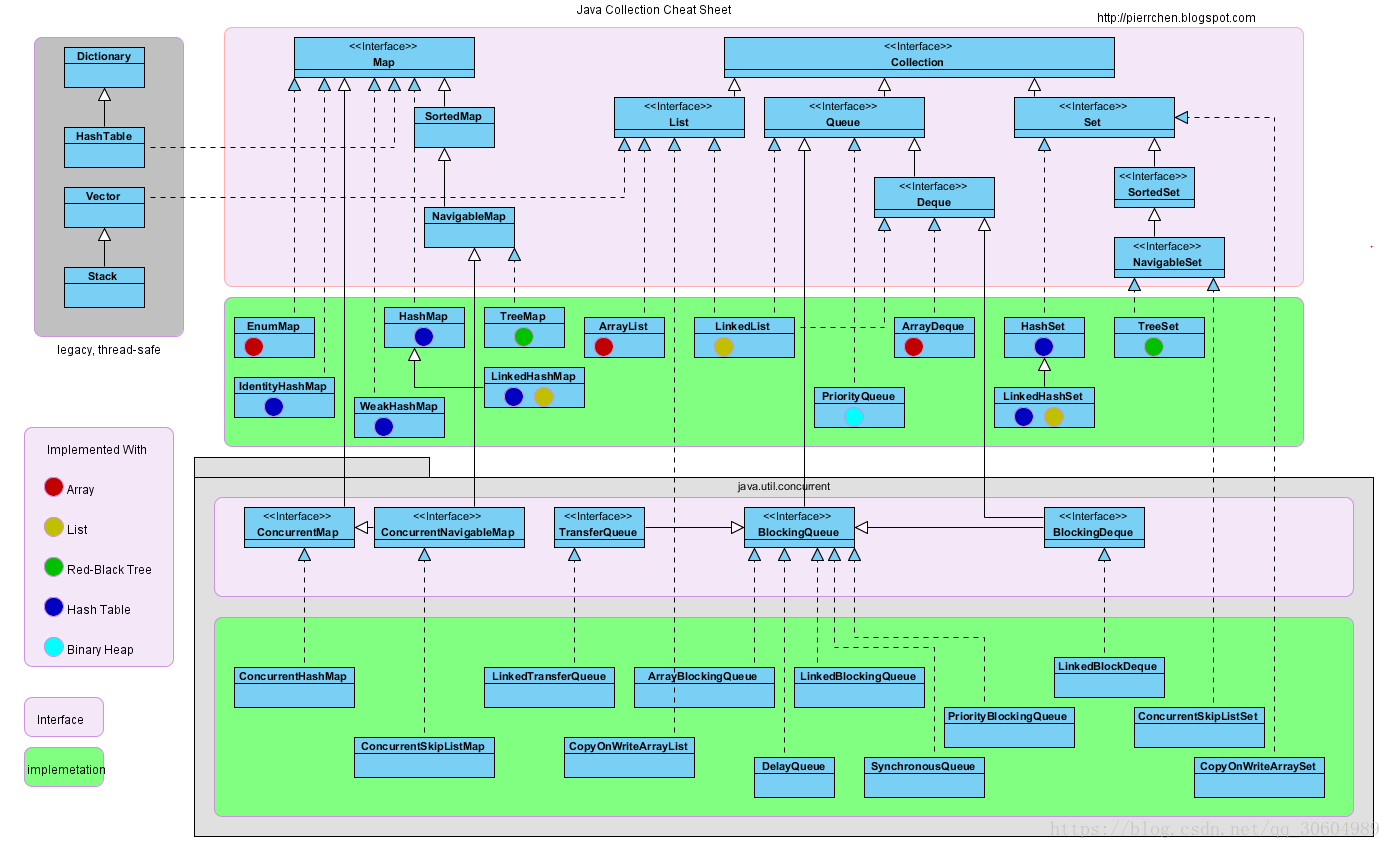
集合关系图
Set和Map
set代表一种集合元素无序、集合元素不可重复的集合
map代表一种由多个key-value对组成的集合
set和map的关系
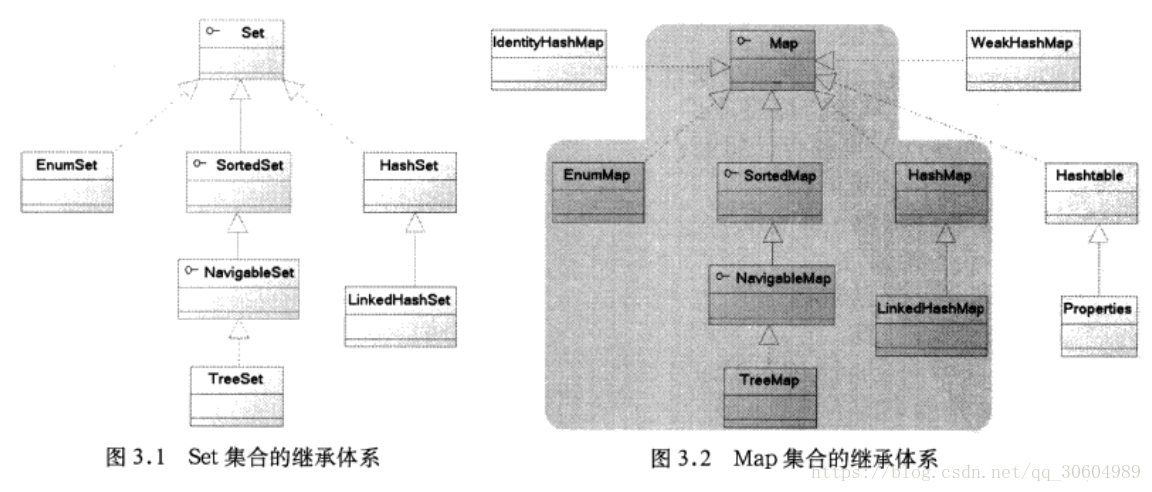
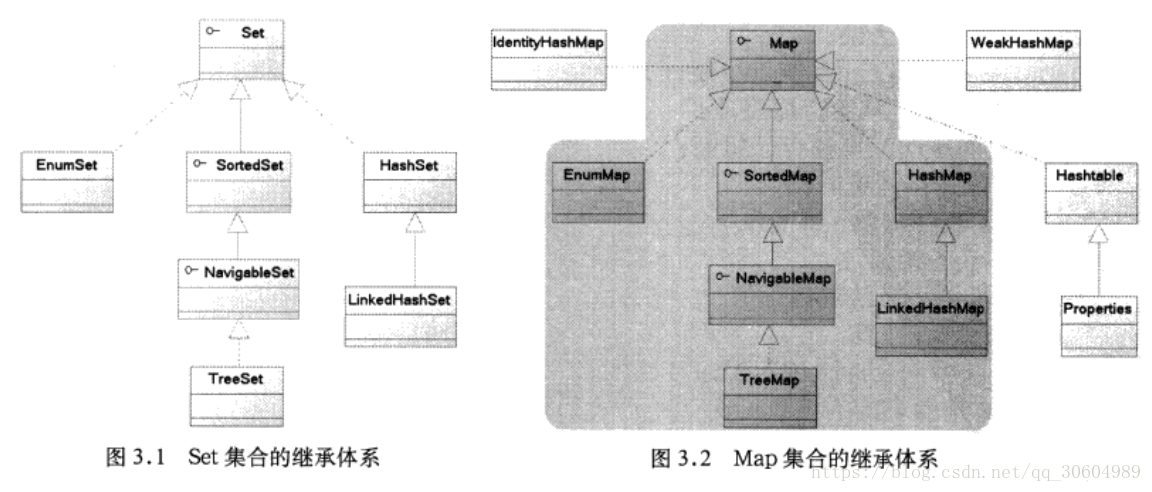
set和map的接口十分类似。
Map的key有一个特征:所有key不能重复,且key之间没有顺序,也就是说将所有key组合起来就是一个Set集合。
Map——>Set : Map中提供了 Set<k> keySet() 返回所有key集合
Set——>Map : 对于map而言,每个元素都是key-value的set集合。把value看成是key的附属物。
为了把set扩展成map,可以新增定义一个SimpleEntry类,该类代表一个key-value对:
class SimpleEntry<K,V> implements Map.Entry<K,V>,Serializable{ private final K key; private V value; //定义如下2个构造器 public SimpleEntry(K key, V value) { this.key = key; this.value = value; } public SimpleEntry(Map.Entry<? extends K,? extends V> entry){ this.key = (K) entry.getKey(); this.value = (V) entry.getValue(); } @Override public K getKey() { return key; } @Override public V getValue() { return value; } //改变key-value对的value值 @Override public V setValue(V value) { V oldValue = this.value; this.value = value; return oldValue; } //根据key比较两个SimpleEntry是否相等 @Override public boolean equals(Object o){ if(o == this){ return true; } if(o.getClass() == SimpleEntry.class){ SimpleEntry se = (SimpleEntry) o; return se.getKey().equals(getKey()); } return false; } //根据key计算hashCode @Override public int hashCode(){ return key == null ? 0 : key.hashCode(); } @Override public String toString() { return key + "=" + value ; } } //继承HashSet,实现一个map public class SetToMap<K,V> extends HashSet<SimpleEntry<K,V>> { //实现所有清空key-value对的方法 @Override public void clear(){ super.clear(); } //判断是否包含某个key public boolean containsKey(Object key){ return super.contains(new SimpleEntry<K, V>((K) key,null)); } //判断是否包含某个value public boolean containsValue(Object value){ for (SimpleEntry se: this) { if (se.getValue().equals(value)){ return true; } } return false; } //根据key支出相应的value public V getValue(Object key){ for (SimpleEntry se : this) { if (se.getKey().equals(key)) { return (V) se.getValue(); } } return null; } //将指定key-value放入集合中 public V put(K key,V value){ add(new SimpleEntry<K, V>(key,value)); return value; } //将另一个Map的key-value放入该map中 public void putAll(Map<? extends K,? extends V> m){ for (K key:m.keySet()){ add(new SimpleEntry<K, V>(key,m.get(key))); } } //根据指定的key删除指定的key-value public V removeEntry(Object key){ for (Iterator<SimpleEntry<K,V>> it = this.iterator();it.hasNext();){ SimpleEntry<K,V> en = it.next(); if (en.getKey().equals(key)){ V v = en.getValue(); it.remove(); return v; } } return null; } //获取该map中包含多少个key-value对 public int getSize(){ return super.size(); } }
HashMap和HashSet
HashSet : 系统采用hash算法决定集合的存储位置,这样可以保证快速存、取元素;
HashMap:系统将value当成key的附属品,系统根据hash算法决定key的位置,这样可以保证快速存、取key,而value总是跟着key存储。
Java集合实际上是多个引用变量所组成的集合,这些引用变量指向实际的Java对象。
class Apple{ double weight; public Apple(double weight) { this.weight = weight; } } public class ListTest { public static void main(String[] args) { //创建两个Apple对象 Apple a = new Apple(1.2); Apple b = new Apple(2.2); List<Apple> appleList = new ArrayList<Apple>(4); //将两个对象放入list中 appleList.add(a); appleList.add(b); //判断从集合中取出的引用变量和原有的引用变量是否指向同一个元素 System.out.println(appleList.get(0)==a); System.out.println(appleList.get(1)==b); } }
HashMap类的put(K key,V value)源码:
public V put(K key, V value) { //如果key为null则调用putForNullKey方法 if (key == null) return putForNullKey(value); //根据key计算hash值 int hash = hash(key); //搜索指定hash值在table中对应的位置 int i = indexFor(hash, table.length); //如果i索引处的Entry不为null,通过循环不断遍历e元素的下一个元素 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; //找到指定key与需要放入的key相等(hash值相同,通过equals比较返回true) if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } //如果i索引处的key为null,则表明此处还没有Entry modCount++; //将key、value添加到i索引处 addEntry(hash, key, value, i); return null; }
每个map.entry就是一个key-value对。当hashmap存储元素时,先计算key的hashCode值,决定Entry的存储位置,如果两个Entry的key的hashCode返回值相同,则存储位置相同;如果这两个Entry的key通过equals比较返回true,添加的Entry的value将会覆盖集合中原有Entry的value,但是key不会覆盖;如果equals返回false,则新添加的Entry与集合中原有的Entry将会形成Entry链,而且新添加的Entry位于链的头部。
addEntry方法:
void addEntry(int hash, K key, V value, int bucketIndex) { //如果map中的Entry(key-value对)数量超过了极限 if ((size >= threshold) && (null != table[bucketIndex])) { //把table对象的长度扩充到2倍 resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } //创建新的entry createEntry(hash, key, value, bucketIndex); }
void createEntry(int hash, K key, V value, int bucketIndex) { //获取指定bucketIndex索引处的Entry Entry<K,V> e = table[bucketIndex]; //将新创建的Entry放入bucketIndex索引处,让新的Entry指向原来的Entry table[bucketIndex] = new Entry<>(hash, key, value, e); size++; }
系统将新添加的Entry对象放入table数组的bucketIndex索引处。如果bucketIndex索引处有一个Entry对象,新添加的Entry对象指向原有的Entry对象(产生一个Entry链);如果bucketIndex索引处没有Entry对象,新建的Entry对象则指向null,没有产生Entry链。
size:包含了HashMap中所包含的key-value对的数量。
table:一个普通的数组,每个数组都有固定长度,这个数组的长度也就是HashMap的容量
threshold:包含了HashMap能容纳key-value对的极限,它的值等于HashMap的容量乘以负载因子(load factor)。
HashMap包含的构造方法:
1)HashMap() : 构建一个初始容量为16,负载因子为0.75的HashMap
2)HashMap(int InitialCapacity) : 构建一个初始容量为InitialCapacity,负载因子为0.75的HashMap
3)HashMap(int InitialCapacity,float loadFactory) : 构建一个指定初始容量和负载因子的HashMap
//指定初始容量和负载因子创建HashMap public HashMap(int initialCapacity, float loadFactor) { //初始容量不能为负 if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); //如果初始容量大于最大容量,则让初始容量等于最大容量 if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; //负载因子必须是大于0的值 if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; threshold = initialCapacity; init(); }
创建HashMap的实际容量并不等于HashMap的实际容量。通常来说,HashMap的实际容量总比initialCapacity大一些,除非指定的initialCapacity参数值正好是2的n次方。掌握了容量分配之后,应创建HashMap时将initialCapacity参数值指定为2的n次方。
当系统开始初始化HashMap时,系统会创建一个长度为capacity的Entry数组。这个数组里可以存储元素的位置被称为”桶(bucket)“每个bucket都有指定的索引,系统可以根据索引快速访问该bucket里存储的元素。
无论何时,HashMap的每个”bucket“中只能存储一个元素(一个Entry)。由于Entry对象可以包含一个引用变量(就是Entry构造器的最后一个参数)用于指向下一个Entry,因此:HashMap中的bucket只有一个Entry,但这个Entry指向另一个Entry,这就形成了一个Entry链。
HashMap的存储:
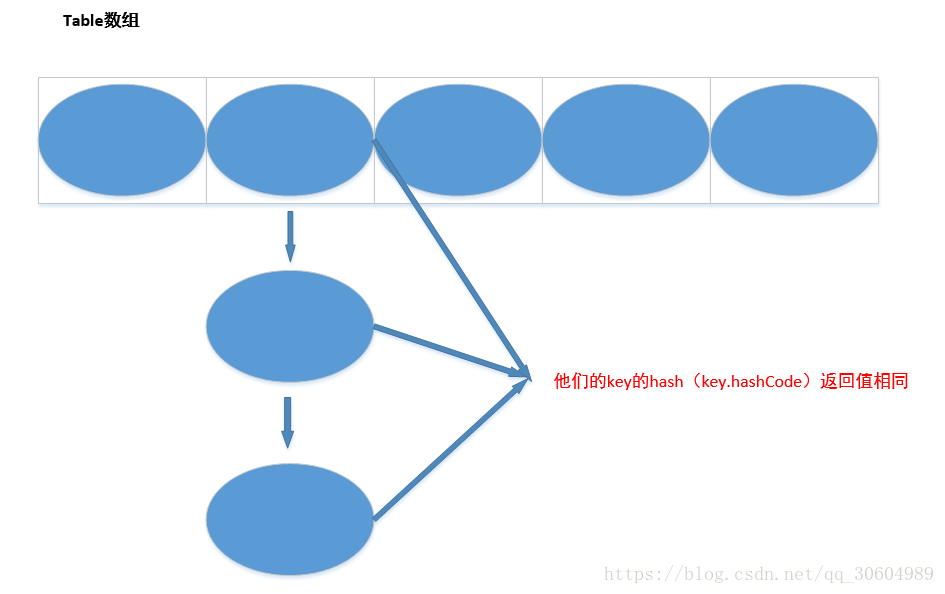
当HashMap中没有产生Entry链时,具有最好的性能。
HashMap类的get方法:
public V get(Object key) { //如果key是null,调用getForNullKey取出对应的value值 if (key == null) return getForNullKey(); Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue(); }
final Entry<K,V> getEntry(Object key) { if (size == 0) { return null; } //根据key值计算出hash码 int hash = (key == null) ? 0 : hash(key); //直接取出table数组中指定索引处的值 for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; //搜索entry链的下一个entry e = e.next) { Object k; //如果该entry的key与被搜索的key相同 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; }
如果HashMap的每个bucket里只有一个Entry,则可以根据索引快速的取出。在发生“Hash冲突”的情况下,单个bucket里存储的是一个Entry链,系统只能按顺序遍历每个Entry,直到找到想要的Entry为止。
总结:HashMap在底层将key-value当成一个整体进行处理,这个整体就是一个Entry对象。HashMap底层采用一个Entry[]数组保存所有的key-value对,当需要存储一个Entry对象时,根据hash算法来决定其存储位置;当需要取出一个Entry对象时,也会根据hash算法找到其存储位置,直接取出该Entry。
创建一个HashMap时,有个默认的负载因子,其默认值为0.75。这是时间和空间的折衷:增大负载因子可以减少Hash表(就是Entry数组)所占用的内存空间,但会增加查询的时间开销(最频繁的put、get操作都要用到查询);减小负载因子可以提高查询的性能,但会降低Hash表占用的内存空间。
对于HashSet而言,他是基于HashMap实现的。HashSet底层采用HashMap来保存所有元素。
源码解析:
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable { static final long serialVersionUID = -5024744406713321676L; //使用HashMap的key来保存HashSet中的所有元素 private transient HashMap<E,Object> map; // 定义一个虚拟的Object对象作为HashMap的value private static final Object PRESENT = new Object(); /** * 初始化HashSet,底层会初始化一个HashMap * default initial capacity (16) and load factor (0.75). */ public HashSet() { map = new HashMap<>(); } /** * 以指定的initialCapacity、loadFactor创建HashSet * 其实就是以相应的参数创建HashMap */ public HashSet(Collection<? extends E> c) { map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16)); addAll(c); } public HashSet(int initialCapacity, float loadFactor) { map = new HashMap<>(initialCapacity, loadFactor); } public HashSet(int initialCapacity) { map = new HashMap<>(initialCapacity); } HashSet(int initialCapacity, float loadFactor, boolean dummy) { map = new LinkedHashMap<>(initialCapacity, loadFactor); } /** * 调用map的keySet方法来返回所有的key */ public Iterator<E> iterator() { return map.keySet().iterator(); } /** * 调用HashMap的size方法返回Entry的数量, * 得到该Set里元素的个数 */ public int size() { return map.size(); } /** * 调用HashMap的isEmpty判断该HashSet是否为空 * 当HashMap为空时,对应的HashSet也为空 */ public boolean isEmpty() { return map.isEmpty(); } /** * 调用HashMap的containsKey判断是否包含指定的key * HashSet的所有元素是通过HashMap的key来保存的 */ public boolean contains(Object o) { return map.containsKey(o); } /** * 将指定元素放入HashSet中,也就是将该元素作为key放入HashMap */ public boolean add(E e) { return map.put(e, PRESENT)==null; } /** * 调用HashMap的remove方法删除指定的Entry对象,也就删除了HashSet中对应的元素 */ public boolean remove(Object o) { return map.remove(o)==PRESENT; } /** * 调用map的clear方法清空所有的Entry,也就清空了HashSet中所有的元素 */ public void clear() { map.clear(); }
从源码可以看出HashSet只是封装了一个HashMap对象来存储所有集合元素。实际是由HashMap的key来保存的,而HashMap的value则是存储了一个PRESENT,一个静态的Object对象。HashSet绝大部方法是调用HashMap的方法来实现的,因此HashMap和HashSet本质上是相同的。
