

从功能测试角度谈大数据测试
大数据,已经成为了一个时代的代名词,当今的互联网属于大数据时代,大数据时代的到来,颠覆了以往对数据的惯性思考方式,要保证数据执行,软件质量,测试质量,数据使用场景等,都需要重新变换一个新的角度,对软件进行更全方面的思考。
之前大数据很少有测试,开发会觉得:测试环境又没有那么多数据,你怎么测?抛开大数据的数据量大的特点,究其根本,他也是为业务服务的,有一句话我非常赞同: 一切技术都是为业务服务,脱离业务的技术一文不值,这句话在大数据时代的今天,依然适用,并且会一直适用下去。测试的工作就是要保证数据的正确性,业务逻辑正确。大数据脚本也有输入、输出,这有点类似与功能测试中的后台逻辑测试,没有界面,一切都是后台服务器处理的,测试人员必须要清楚整个处理流程,每个数据的流转,每个步骤的输入和输出,才能判断最后的输出结果是否正确,对于大数据测试也是一样,我们要清楚每个脚本的功能,每个脚本的输入和输出,整体数据流转过程,来判断大数据实现的功能是否正确。
一个数据脚本或者一段数据计算逻辑,在大数据下运行正确的前提,必须是其功能是正确的,这也是我们测试人员首先要保证的,今天我想从功能测试的角度,讨论大数据的功能测试要怎么做,用例怎么设计,才能覆盖面更广,更好的保证其正确性。
1、编写测试用例
功能测试编写测试用例的常用方法:等价类、边界值(这两个方法估计做测试的都知道),同样适用于大数据测试编写用例,与通常意义上的功能测试不同的是,他的输入不再是一个输入框,而是一个数据库字段或者一个有特殊意义的数据集(包含多个数据)。
我们先回顾一下等价类和边界值两种常用的功能测试设计用例的方法。首先划分等价类:是指某个输入域的子集合。在该子集合中,各个输入数据对于揭露程序中的错误都是等效的,并合理地假定:测试某等价类的代表值就等于对这一类其它值的测试.因此,可以把全部输入数据合理划分为若干等价类,在每一个等价类中取一个数据作为测试的输入条件,就可以用少量代表性的测试数据.取得较好的测试结果.边界值是对等价类的补充,其测试用例来自于每个等价类用例的边界。
那么这两种方法如何用在大数据测试用例的编写上呢?
拿我们之前测试的一个大数据脚本举例,脚本的主要功能是统计某家店铺某一天的订单量,根据设置的每个商品不同的返利规则,计算店铺每天的利润。
首先输入分析条件:
1、指定店铺
2、指定某一天
3、不同时间,不同的商品,不同的返点
商品1:2016.12.6 13:00:00------2016.12.6 15:00:00 返利为5%
商品2:2016.12.7 00:00:00------2016.12.7 23:59:59 返利为15%
所有商品,除指定时间外, 返利均为1%
他的等价类不再是一个输入,而是一个条件,满足这个条件的我们划到有效等价类上,不满足这个条件的,我们划分到无效等价类上,而在条件边界上的数据则是我们的边界值。
用例划分结果:
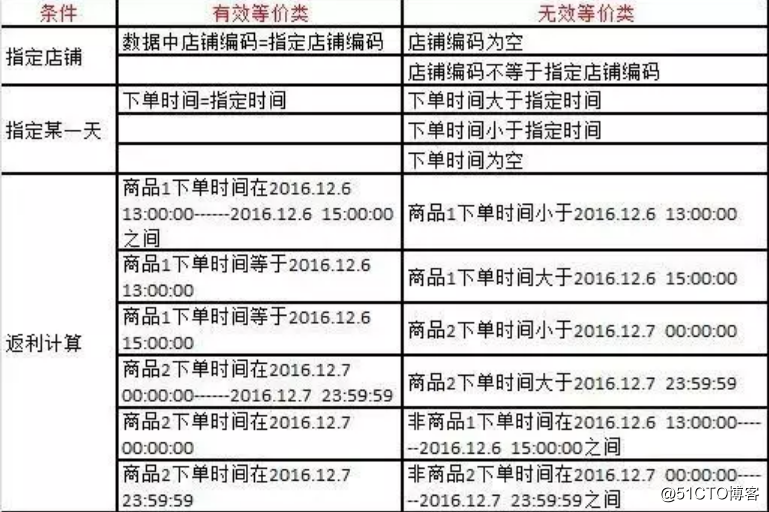
其他编写功能测试用例的方法,如场景分析法、分支覆盖法,也同样可以用在编写大数据测试用例中,任何测试都不能脱离实际业务,单纯的测试数据,或者单纯的测试输入,没什么意义,我们必须结合不同的场景,设计更全面、更有效率的测试用例。
2、准备测试数据
根据编写的测试用例,准备不同类型的测试数据,这个也与功能测试一样,测试数据不在数量的多少,而在于覆盖的全面性,如果你准备了几千条数据,但是数据类型都一样,覆盖的代码分支也都是一条,那这些数据只有一条能称之为有效测试数据,其他的全部是无效测试数据。
其中准备测试数据,可以有几种方法:
1)自己写sql单条插入
2)使用存储过程
3)从线上导导出数据,直接导入到测试环境。
同时要注意,准备测试数据时,尽量和实际数据保持一致,如时间的值,精确到时分秒还是只到年月日,还有金额保留几位小数等。
3、执行测试脚本,检查测试结果
准备好测试数据后,就可以执行测试脚本,脚本可能是在hadoop平台上,也可能是在其他平台上,但这些都只是一个操作,类似我们学习一个工具怎么使用,知道怎么运行脚本后,接下来的工作就又回归到测试上来,这时候测试人员要做的事情就是利用准备好的数据,执行脚本,检查预期结果和实际结果是否一致,判断脚本逻辑是否正确,这完全是我们功能测试的工作一模一样。
所以,不管什么类型的测试,其测试过程都是通用的,测试方法都是可借鉴的,我们储备了足够多的测试基础和测试方法,就可以轻松应对各种不同的测试。
