PerfView专题 (第六篇):如何洞察 C# 中 GC 的变化
一:背景
在洞察 GC 方面,我觉得市面上没有任何一款工具可以和 PerfView 相提并论,这也是为什么我会在 WinDbg 之外还要学习这么一款工具的原因,这篇我们先简单聊聊 PerfView 到底能洞察 GC 什么东西?
二:洞察 GC
1. 到底都能看到 GC 什么?
能获取到的 GC 信息非常多,比如:
-
程序运行期间 GC 触发了多少次?
-
GC 最大一次暂停耗费了多久?
-
每一次 GC 触发的原因是什么?
-
GC 暂停 >200ms 的都有哪些?
-
GC 触发 3 阶段中各个函数的耗时是怎样的?
等等。。。 可获取的信息非常多,后面的文章会逐一聊。
2. 获取 GC 的一般性信息
为了方面讲述,先上一段故意无限次拼接 string 的代码,让 GC 高频触发。
internal class Program
{
static void Main(string[] args)
{
Task.Run(Alloc1);
Console.ReadLine();
}
static void Alloc1()
{
var s = string.Empty;
for (int i = 0; i < 100000; i++)
{
s = s + i.ToString();
}
}
}
接下来我们用 Collect -> Run 对程序采样 20s,观察这 20s 中 GC 的触发情况。
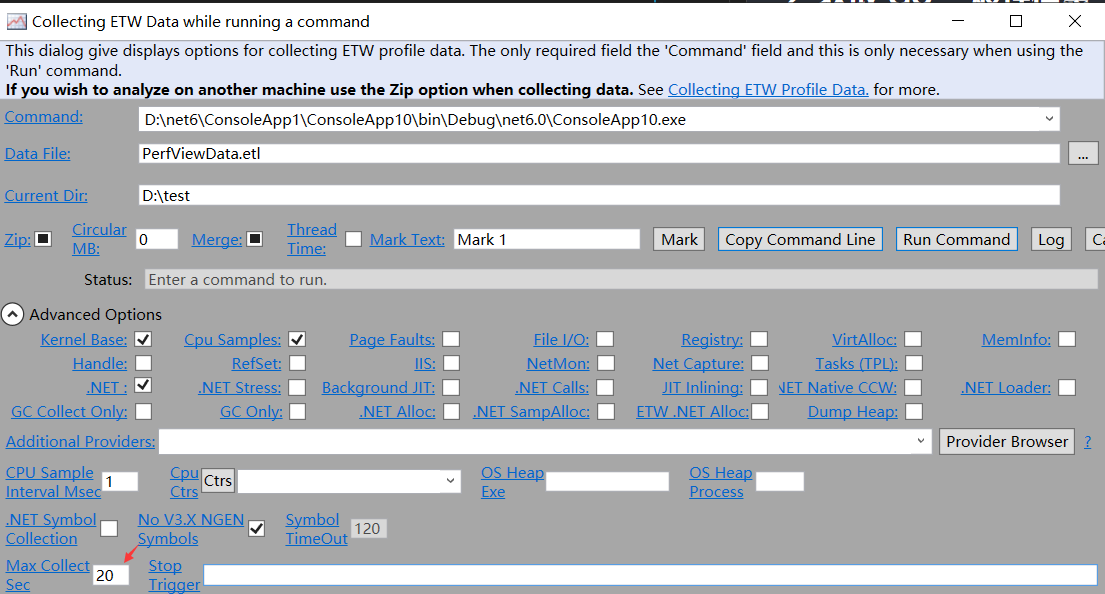
稍等20s后,在打包好的 zip 视图列表中点击 Memory -> GCStats。
然后点击我们的应用程序,就会看到 GC 汇总信息。
GC Stats for Process 3848: ConsoleApp10
•CommandLine: "D:\net6\ConsoleApp1\ConsoleApp10\bin\Debug\net6.0\ConsoleApp10.exe"
•Runtime Version: V 6.0.522.21309 (built on 2022/4/14 1:31:32)
•CLR Startup Flags: 8388611
•Total CPU Time: 10,471 msec
•Total GC CPU Time: 1,305 msec
•Total Allocs : 38,099.086 MB
•GC CPU MSec/MB Alloc : 0.034 MSec/MB
•Total GC Pause: 2,710.6 msec
•% Time paused for Garbage Collection: 19.9%
•% CPU Time spent Garbage Collecting: 12.5%
•Max GC Heap Size: 14.285 MB
•Peak Process Working Set: 40.776 MB
•Peak Virtual Memory Usage: 5,003.682 MB
...
接下来看下 GC Rollup By Generation 列表,如下图所示:
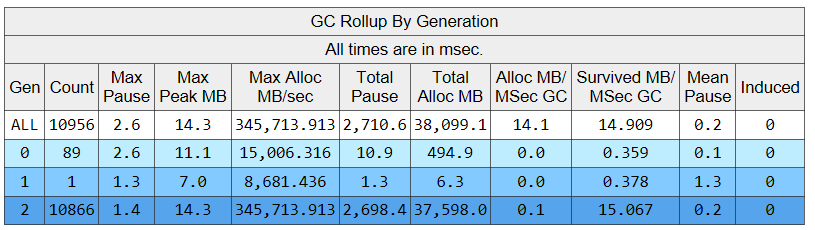
从图中可得知这 20s 期间的如下信息:
-
GC触发了
1w次,平均500次/s,🐂哈 -
GC总的暂停时间是 2.7s,占比 13.5% ,也就是说20s时间,程序其实就跑了 86.5% 的时间,有点像 公摊面积 哈, 其实这是有问题的。
-
1w 次GC 中,最大的单次暂停时发生在 gen0 上,耗费了 2.6ms。
还有一个比较有用的是 Pause > 200 Msec GC Events 列表,它记录着那些暂停时间大于 >200ms 的单次GC,截图如下:

还好本次实验没有遇到,不过可以肯定的是,大于 200ms 的程序暂停肯定会导致明显的卡顿,所以仔细研读下这些 列信息 非常有用,是不是因为 存活对象过多 导致的 mark_phase 和 compact_phase 时间过长? 还是因为 pinned 或者 碎片化过多导致 plan_phase 时间过长等等,具体问题具体分析。
接下来就是这 10956 次 GC 的 detail 信息啦,可以观察到 GC 的触发原因,触发了哪一代 GC,SuppendEE 暂停时间,GC 暂停时间,GC 与上次 GC 之后的一个时间占比 等等各种信息,大家可以把鼠标放在标头上,都有相应的提示。
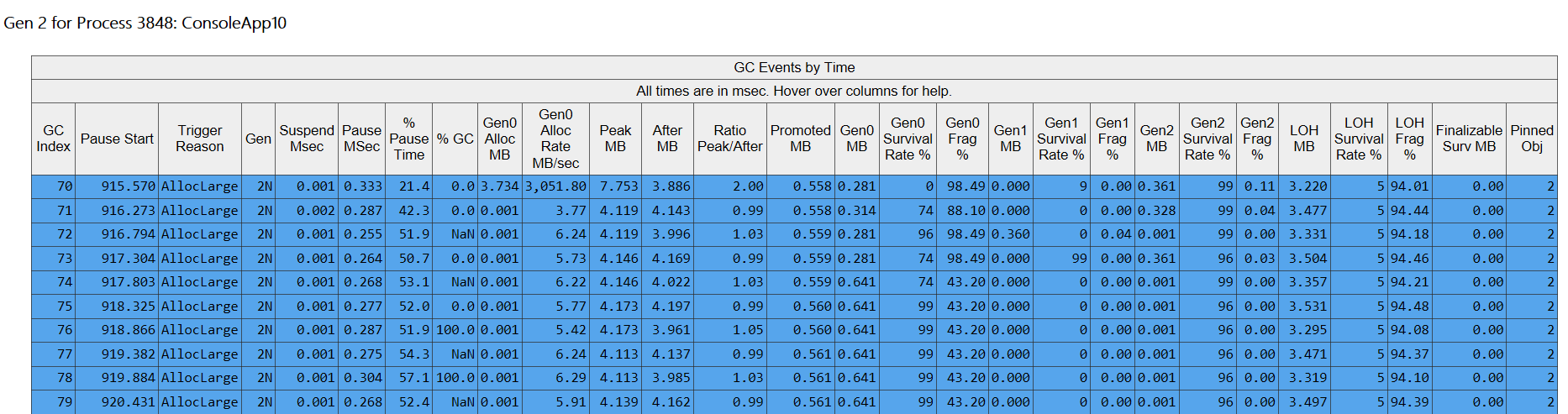
稍微提醒下就是 Pause Start 是没有解释的,其实它是一个毫秒时间戳,如果你仔细观察,也就是 500次/s 的排序记录。
3. 获取 GC 内部函数的 一般性耗时
熟悉 GC 的朋友应该知道,最简单的非并发工作站模式 GC 是这样的一个触发模式,如下代码所示:
GarbageCollectGeneration()
{
SuspendEE();
garbage_collect();
RestartEE();
}
garbage_collect()
{
generation_to_condemn();
gc1();
}
gc1()
{
mark_phase();
plan_phase();
}
plan_phase()
{
// actual plan phase work to decide to
// compact or not
if (compact)
{
relocate_phase();
compact_phase();
}
else
make_free_lists();
}
那如何用 PerfView 去检测这些函数的耗时呢?可以是可以,但只是一个大体的模型,因为原理是对 CPU 进行采样 再根据权重算出来的,所以有一定的参考意义。
接下来我们在 Find 输入框中搜索 coreclr!GarbageCollectGeneration 关键词。
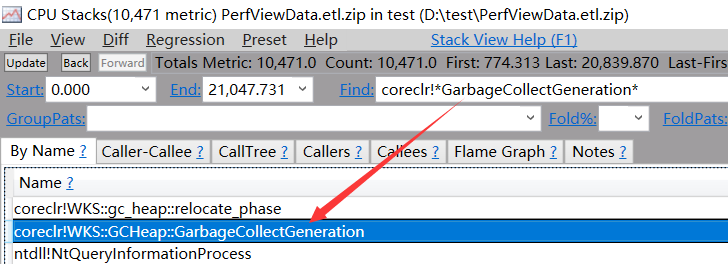
接下来右键选择 Goto -> Goto Item in Callees 选项,然后展开可能的耗时,如下图所示:
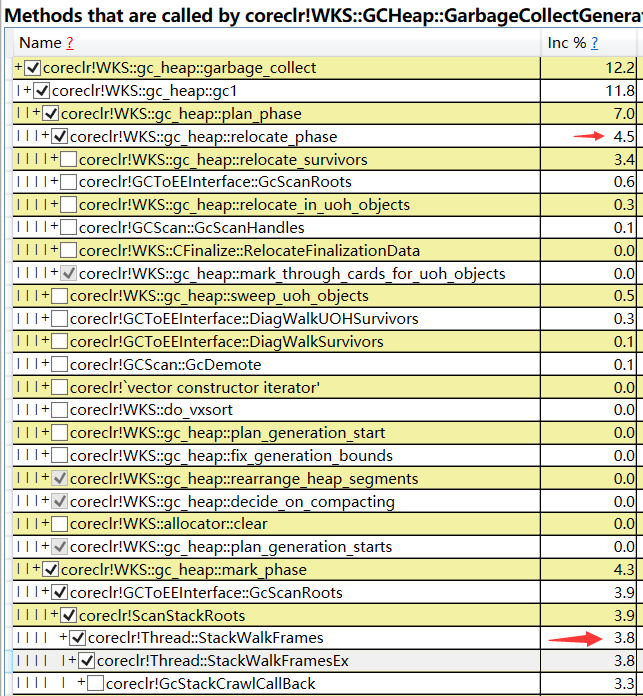
从输出信息看, GarbageCollectGeneration 大概会耗时 12.2ms ,耗时比较长的两块大概是:
- GCScanRoots
在标记阶段,爬线程栈耗时相对较大,耗费了 3.8ms,继续往下翻的话,会发现都耗费在寻找 GC 安全点上。
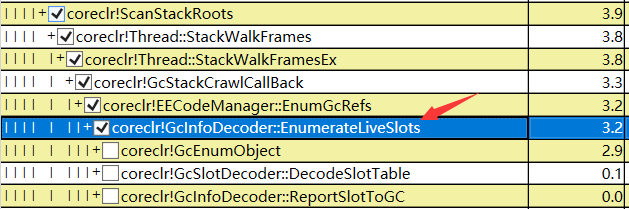
- relocate_phase
这个属于 计划阶段 的重定位阶段,主要用来修改需要移动对象的新地址,所谓 兵马未动,粮草先行。

关于 GC 的洞察,还有更多好玩的东西,放在后续文章聊吧!

