基于datax的数据同步平台
一、需求
由于公司各个部门对业务数据的需求,比如进行数据分析、报表展示等等,且公司没有相应的系统、数据仓库满足这些需求,最原始的办法就是把数据提取出来生成excel表发给各个部门,这个功能已经由脚本转成了平台,交给了DBA使用,而有些数据分析部门,则需要运维把生产库的数据同步到他们自己的库,并且需要对数据进行脱敏,比如客户的身份证号、手机号等等,且数据来源分散在不同的机器,不同的数据库实例里,这样就无法使用MySQL的多源复制,只能用写脚本通过SQL语句实现,随着业务的发展,导致堆积到运维部门的同步数据任务越来越多,一个任务对应一个脚本,有的脚本多达20多张表,脚本超过10个以后,每次同步失败、或者对脚本里的参数进行增删改查,都要从10多个脚本里的10多个SQL去找,这是一件非常痛苦的事情,耗费时间、没有效率,且容易改错,是一件吃力不讨好的事。为此开发了一个数据同步平台,将同步任务的增删改查、执行的历史日志全部放到平台里,然后交给DBA去自己去操作。
市面上也有一些ETL工具,比如kettle,但是为了练手决定重新造轮子。
二、平台简介
平台主要用于数据同步、数据处理等等ETL操作。
平台基于阿里的开源同步工具datax3.0开发。
开发语言:Python、Django、celery、bootstrap、jquery
系统:Centos 7 64位
注意:时间紧迫,平台只支持MySQL数据库,其它的sqlserver等等后期再开发。
datax3.0 介绍:https://yq.aliyun.com/articles/59373
datax3.0 github 地址:https://github.com/alibaba/DataX
项目地址:https://github.com/hanson007/FirstBlood
三、功能模块
1、数据同步
主要用于数据同步
2、SQL脚本(后期开发,包括备份模块等等。)
保存并执行各种增删改查SQL语句。
3、批处理作业
将数据同步、SQL脚本等等各个模块的子任务组合成一个批处理作业。借鉴了数据库客户端工具Navicat Premium 的批处理作业功能。
支持作业定时调度。
4、数据库管理工具(web界面后期开发)
主要用于管理生产数据库的IP、用户名、密码等等信息,供其它模块调用。
目前模块的表已建好,生产库的信息需要通过其它平台同步或者用数据库客户端工具导入,web界面的增删改查后期开发。目前生产环境里是将其它平台保存的所有生产库IP、用户名、密码等等信息同步到此平台里。
5、接口
提供查询批处理作业执行历史的接口,供其它部门使用。(主要还是大数据部门,他们写了一个程序,根据我这边每次同步后的结果,是成功还是失败,再进行下一步的操作。)
后续接口按业务部门的需求再开发。
6、权限(Django自带)
平台管理员账号拥有模块的所有权限,仅供运维部门使用。
普通人员账号只能查看数据同步、批处理作业,以及执行历史,不能新增、修改、执行作业或任务。主要提供给业务部门使用。
查看批处理作业的执行历史接口没有权限控制,普通人员也能调用。
四、表结构设计
1、生产数据库信息
功能:主要用于保存各种生产库的 ip、用户名、密码等等信息。
表名:databaseinfo
| 名称 | 类型 | 约束条件 | 说明 |
| id | int | 不允许为空 | 自增主键 |
| name | varchar | 不允许为空、不允许重复 | 生产库英文标识。 |
| description | varchar | 不允许为空 | 生产库的业务信息描述 |
| host | varchar | 不允许为空、不允许重复 | 生产库的IP地址。 |
| user | varchar | 不允许为空 | 生产数据库的用户名 |
| passwd | varchar | 不允许为空 | 生产数据库的密码 |
| db | varchar | 不允许为空 | 生产数据库中的某一个库 |
| type | varchar | 不允许为空 | 生产数据库类型。 比如MySQL、sqlserver |
| create_time | datetime | 不允许为空 | 创建时间,默认为当前时间 |
| modify_time | datetime | 不允许为空 | 修改时间,默认为当前时间,数据变化时自动改为当前时间。 |
2.数据库同步任务
功能:用于保存数据库同步任务的各种参数,主要为datax的json配置文件里的各种参数。
表名:datax_job
| 名称 | 类型 | 约束条件 | 说明 |
| id | int | 不允许为空 | 自增主键 |
| name | varchar | 不允许为空,不允许重复 | 数据同步任务的英文标识 |
| description | varchar | 不允许为空 | 任务的详细描述 |
| querySql | longtext | 不允许为空 | 提取数据时的查询SQL |
| reader_databaseinfo_id | int | 不允许为空 | 读取数据库(从哪个生产库执行SQL提取数据,对应databaseinfo表的主键) |
| writer_table | varchar | 不允许为空 | 写入表名(提取的数据插入到哪张表里) |
| writer_databaseinfo_id | int | 不允许为空 | 写入数据库(提数据的数据插入到哪个数据库里) |
| writer_preSql | longtext | 允许为空 | 写入前执行的SQL(比如同步数据前需要清空写入的表) |
| writer_postSql | longtext | 允许为空 | 写入后执行的SQL(比如同步完数据后需要再结合其它表执行数据分析) |
| create_time | datetime | 不允许为空 | 创建时间,默认为当前时间 |
| modify-time | datetime | 不允许为空 | 修改时间,默认为当前时间,数据变化时自动改为当前时间。 |
3.写入表的列信息
功能:保存同步任务时写入到表的哪些列。比如写入表有20个字段,此时只需要往其中的10个字段写入信息,就需要保存这10个列名。
注意:* 星号代码写入到表的所有字段。
表名:datax_job_writer_column
| 名称 | 类型 | 约束条件 | 说明 |
| id | int | 不允许为空 | 自增主键 |
| name | varchar | 不允许为空 | 列名 |
| datax_job_id | int | 不允许为空 | 数据同步任务ID,关联datax_job表的主键。 |
| create_time | datetime | 不允许为空 | 创建时间,默认为当前时间 |
| modify_time | datetime | 不允许为空 | 修改时间,默认为当前时间,随着数据的变化而变为当前时间。 |
4.数据同步任务实例
功能:用于保存数据同步任务的执行历史。
方便自己及业务部门进行任务的分析和排错,省的每次同步失败后还得帮他们查日志。现在直接将日志记录表里,在平台开个账号后,让业务部门自己去查。
每一个数据同步任务执行后,可以看成是一个实例,类似面向对象里实例化。将任务的执行时间、执行结果等等保存起来。借鉴了腾讯蓝鲸的作业平台表结构设计思想。(麻花藤啊麻花藤,给你冲了几十年的点卡,终于是回了一点点利息。)
表名:datax_job_instance
说明:instance_id也对应datax生成的日志文件名,当需要在页面查看datax生成的日志时就通过instance_id去查找日志文件,并将其实时输出到页面。
| 名称 | 类型 | 约束条件 | 说明 |
| id | int | 不允许为空 | 自增主键 |
| instance_id | bigint | 任务实例ID ,不允许重复 | 任务实例ID(由datax_job的id号+13位时间戳组成) |
| name | varchar | 不允许为空 | 任务名称 (执行时,datax_job表的name,同下面的字段一样) |
| description | varchar | 不允许为空 | 任务描述 |
| querySql | longtext | 不允许为空 | 查询SQL语句 |
| reader_databaseinfo_host | varchar | 不允许为空 | 读取数据库IP |
| reader_databaseinfo_description | varchar | 不允许为空 | 读取数据库描述 |
| writer_table | varchar | 不允许为空 | 写入表 |
| writer_databaseinfo_host | varchar | 不允许为空 | 写入数据库IP |
| writer_databaseinfo_description | varchar | 不允许为空 | 写入数据库描述 |
| writer_preSql | longtext | 允许为空 | 写入数据前执行的SQL语句 |
| writer_postSql | longtext | 允许为空 | 写入数据后执行的SQL语句 |
| trigger_mode | int | 不允许为空 | 触发模式 1 自动 2 手动(默认自动) |
| status | int | 不允许为空 | 状态 0 正在执行 1 执行完成 |
| result | int | 不允许为空 | 执行结果 0 成功 1 失败 2 未知 |
| start_time | datetime | 不允许为空 | 开始时间 |
| end_time | datetime | 允许为空 | 结束时间 |
5.批处理作业
功能:保存批处理作业。
表名:batch_job
| 名称 | 类型 | 约束条件 | 说明 |
| id | int | 不允许为空 | 自增主键 |
| name | varchar | 不允许为空,不允许重复 | 名称 |
| description | varchar | 不允许为空 | 描述 |
| create_time | datetime | 不允许为空 | 创建时间 |
| modify_time | datetime | 不允许为空 | 修改时间 |
6.批处理作业详情
功能:保存批处理作业的各个子任务。
比如一个批处理作业包含8个数据同步任务,一个SQL脚本任务,则将这几个任务的id保存起来。
表名:batch_job_details
说明:字段subjob_id,对应其它子任务的ID。比如,类型为数据同步,则对应datax_job表的主键。类型为SQL脚本,则对应SQL脚本表的主键。(SQL脚本后期开发)
| 名称 | 类型 | 约束条件 | 说明 |
| id | int | 不允许为空 | 自增主键 |
| batch_job_id | int | 不允许为空 | 批处理作业ID,对应batch_job表的主键 |
| subjob_id | int | 不允许为空 | 子作业ID,对应其它子任务的主键。 |
| type | int | 不允许为空 | 类型 1 数据同步 2 SQL脚本 3 备份。 主要用于后期扩展 |
| create_time | datetime | 不允许为空 | 创建时间 |
| modify_time | datetime | 不允许为空 | 修改时间 |
7.批处理作业执行实例
功能:保存批处理作业的执行历史日志。功能同数据同步实例一样。
表名:batch_job_instance
| 名称 | 类型 | 约束条件 | 说明 |
| id | int | 不允许为空 | 自增主键 |
| instance_id | bigint | 不允许为空、不允许重复 | 实例ID(由batch_job表的id号+13位时间戳组成) |
| name | varchar | 不允许为空 | 名称 |
| description | varchar | 不允许为空 | 描述 |
| trigger_mode | int | 不允许为空 | 触发模式 1 自动 2 手动(默认自动) |
| status | int | 不允许为空 | 状态 0 正在执行 1 执行完成 |
| result | int | 不允许为空 | 执行结果 0 成功 1 失败 2 未知 |
| start_time | datetime | 不允许为空 | 开始时间 |
| end_time | datetime | 不允许为空 | 结束时间 |
8.批处理作业执行实例详情
功能:保存批处理作业执行实例的各个子任务实例
表名:batch_job_instance_details
说明:每个批处理作业执行时,实际是执行各个其它功能模块的子任务,而每个子任务都会保存子任务实例ID。
比如一个批处理作业有8个数据同步任务,1个备份任务(后期开发),执行后,datax_job_instance表会保存这8个数据同步任务的实例,备份实例表则保存备份实例ID。然后再将8个同步任务实例的ID及1个备份实例ID保存到batch_job_instance_details表里,查询时只要通过各个子任务的实例ID关联查询。
| 名称 | 类型 | 约束条件 | 说明 |
| id | int | 不允许为空 | 自增主键 |
| instance_id | bigint | 不允许为空 | 实例ID,对应batch_job_instance表的instance_id |
| subjob_instance_id | bigint | 不允许为空 | 子作业实例ID,比如datax_job_instance表的instance_id |
| type | int | 不允许为空 | 类型 1 数据同步 2 SQL脚本 3 备份。 主要用于后期扩展 |
9.建表语句
/* * 创建数据库 */ create database FirstBlood default character set utf8 collate utf8_bin; /* * 数据库信息 */ CREATE TABLE `databaseinfo` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL COMMENT '名称', `description` varchar(255) DEFAULT NULL COMMENT '描述', `host` varchar(255) DEFAULT NULL COMMENT '主机', `user` varchar(255) DEFAULT NULL COMMENT '用户', `passwd` varchar(255) DEFAULT NULL COMMENT '密码', `db` varchar(255) DEFAULT NULL COMMENT '数据库', `type` varchar(255) DEFAULT NULL COMMENT '类型', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `modify_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间', PRIMARY KEY (`id`), UNIQUE KEY `databaseinfo_host_c254f05e_uniq` (`host`), UNIQUE KEY `databaseinfo_name_a3bc8190_uniq` (`name`) ) ENGINE=InnoDB AUTO_INCREMENT=28 DEFAULT CHARSET=utf8 COMMENT='数据库信息'; /* * 数据同步任务 */ drop table if exists `datax_job`; CREATE TABLE `datax_job` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL COMMENT '名称', `description` varchar(255) DEFAULT NULL COMMENT '描述', `querySql` longtext COLLATE utf8_bin NOT NULL COMMENT '查询SQL语句', `reader_databaseinfo_id` int(11) NOT NULL COMMENT '读取数据库', `writer_table` varchar(255) DEFAULT NULL COMMENT '写入表名', `writer_databaseinfo_id` int(11) NOT NULL COMMENT '写入数据库', `writer_preSql` longtext COLLATE utf8_bin NOT NULL COMMENT '写入数据前执行的SQL语句', `writer_postSql` longtext COLLATE utf8_bin NOT NULL COMMENT '写入数据后执行的SQL语句', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `modify_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间', PRIMARY KEY (`id`), UNIQUE KEY `datax_job_name_uniq` (`name`) ) ENGINE=InnoDB AUTO_INCREMENT=28 DEFAULT CHARSET=utf8 COMMENT='datax数据同步任务'; /* * 写入表的列信息 */ drop table if exists `datax_job_writer_column`; CREATE TABLE `datax_job_writer_column` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL COMMENT '列名', `datax_job_id` int(11) NOT NULL COMMENT '数据同步任务ID', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `modify_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=28 DEFAULT CHARSET=utf8 COMMENT='写入表的列信息'; /* * 数据同步任务实例 */ drop table if exists `datax_job_instance`; CREATE TABLE `datax_job_instance` ( `id` int(11) NOT NULL AUTO_INCREMENT, `instance_id` bigint(20) NOT NULL COMMENT '任务实例ID', `name` varchar(255) DEFAULT NULL COMMENT '名称', `description` varchar(255) DEFAULT NULL COMMENT '描述', `querySql` longtext COLLATE utf8_bin NOT NULL COMMENT '查询SQL语句', `reader_databaseinfo_host` varchar(255) NOT NULL COMMENT '读取数据库IP', `reader_databaseinfo_description` varchar(255) NOT NULL COMMENT '读取数据库描述', `writer_table` varchar(255) DEFAULT NULL COMMENT '写入表名', `writer_databaseinfo_host` varchar(255) NOT NULL COMMENT '写入数据库IP', `writer_databaseinfo_description` varchar(255) NOT NULL COMMENT '写入数据库描述', `writer_preSql` longtext COLLATE utf8_bin NOT NULL COMMENT '写入数据前执行的SQL语句', `writer_postSql` longtext COLLATE utf8_bin NOT NULL COMMENT '写入数据后执行的SQL语句', `trigger_mode` int(2) DEFAULT '1' COMMENT '触发模式 1 自动 2 手动(默认自动)', `status` int(2) DEFAULT '0' COMMENT '状态 0 正在执行 1 执行完成', `result` int(2) DEFAULT '2' COMMENT '执行结果 0 成功 1 失败 2 未知', `start_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '开始时间', `end_time` datetime DEFAULT NULL COMMENT '结束时间', PRIMARY KEY (`id`), UNIQUE KEY `datax_job_instance_id_uniq` (`instance_id`) ) ENGINE=InnoDB AUTO_INCREMENT=28 DEFAULT CHARSET=utf8 COMMENT='datax数据同步任务实例'; /* * 批处理作业 */ drop table if exists `batch_job`; CREATE TABLE `batch_job` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL COMMENT '名称', `description` varchar(255) DEFAULT NULL COMMENT '描述', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `modify_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间', PRIMARY KEY (`id`), UNIQUE KEY `batch_job_name_uniq` (`name`) ) ENGINE=InnoDB AUTO_INCREMENT=28 DEFAULT CHARSET=utf8 COMMENT='批处理作业'; /* * 批处理作业详情 */ drop table if exists `batch_job_details`; CREATE TABLE `batch_job_details` ( `id` int(11) NOT NULL AUTO_INCREMENT, `batch_job_id` int(11) NOT NULL COMMENT '批处理作业ID', `subjob_id` int(11) NOT NULL COMMENT '子作业ID', `type` int(2) NOT NUll COMMENT '类型 1 数据同步 2 SQL脚本 3 备份。 主要用于后期扩展', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `modify_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=28 DEFAULT CHARSET=utf8 COMMENT='批处理作业详情'; /* * 批处理作业执行实例 */ drop table if exists `batch_job_instance`; CREATE TABLE `batch_job_instance` ( `id` int(11) NOT NULL AUTO_INCREMENT, `instance_id` bigint(20) NOT NULL COMMENT '实例ID', `name` varchar(255) DEFAULT NULL COMMENT '名称', `description` varchar(255) DEFAULT NULL COMMENT '描述', `trigger_mode` int(2) DEFAULT '1' COMMENT '触发模式 1 自动 2 手动(默认自动)', `status` int(2) DEFAULT '0' COMMENT '状态 0 正在执行 1 执行完成', `result` int(2) DEFAULT '2' COMMENT '执行结果 0 成功 1 失败 2 未知', `start_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '开始时间', `end_time` datetime DEFAULT NULL COMMENT '结束时间', PRIMARY KEY (`id`), UNIQUE KEY `batch_job_instance_id_uniq` (`instance_id`) ) ENGINE=InnoDB AUTO_INCREMENT=28 DEFAULT CHARSET=utf8 COMMENT='批处理作业执行实例'; /* * 批处理作业执行实例详情 */ drop table if exists `batch_job_instance_details`; CREATE TABLE `batch_job_instance_details` ( `id` int(11) NOT NULL AUTO_INCREMENT, `instance_id` bigint(20) NOT NULL COMMENT '实例ID', `subjob_instance_id` bigint(20) NOT NULL COMMENT '子作业实例ID', `type` int(2) NOT NUll COMMENT '类型 1 数据同步 2 SQL脚本 3 备份。 主要用于后期扩展', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=28 DEFAULT CHARSET=utf8 COMMENT='批处理作业执行实例详情';
五、功能详解
2、数据同步
功能:底层使用阿里的datax3.0工具进行同步。可以新增、修改同步任务。每个任务对应一张表。在页面添加任务后,执行时就在后台生成基于datax3.0的json配置文件。并且可以实时查看datax生成的同步日志,也可以查看任务的执行历史。
衍生:增量同步
需要源表里增加时间戳字段,两种方案。
(1)如果历史数据不变,每次只同步前一天的数据。
(2)如果历史数据变化,需要在目标库里加一张临时表,每次同步时将前一天或前一个小时的时间戳有变化的数据插入到临时表里。再将临时表里的数据更新或插入到目标表里。
操作
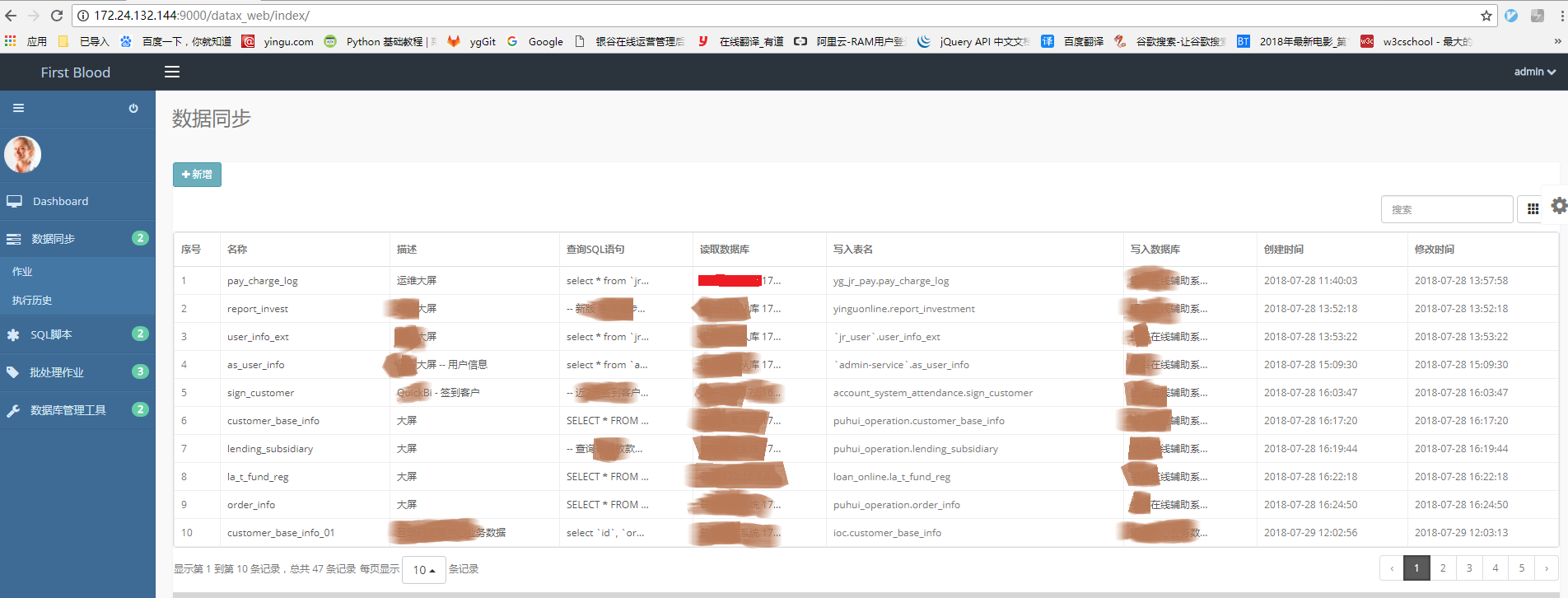
(1)首页
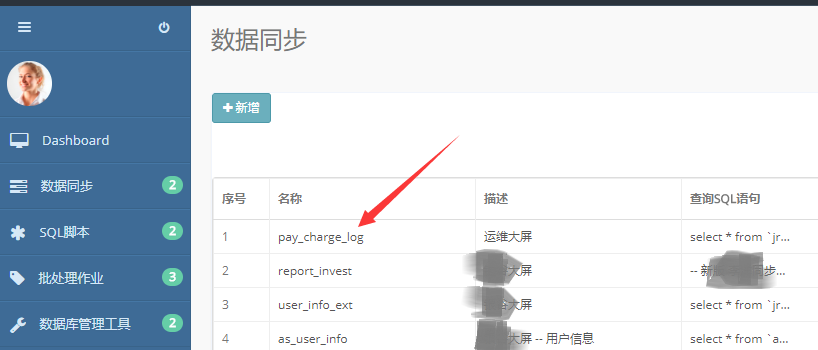
点击“数据同步->作业”,进入数据同步首页,可以查看所有的数据同步任务
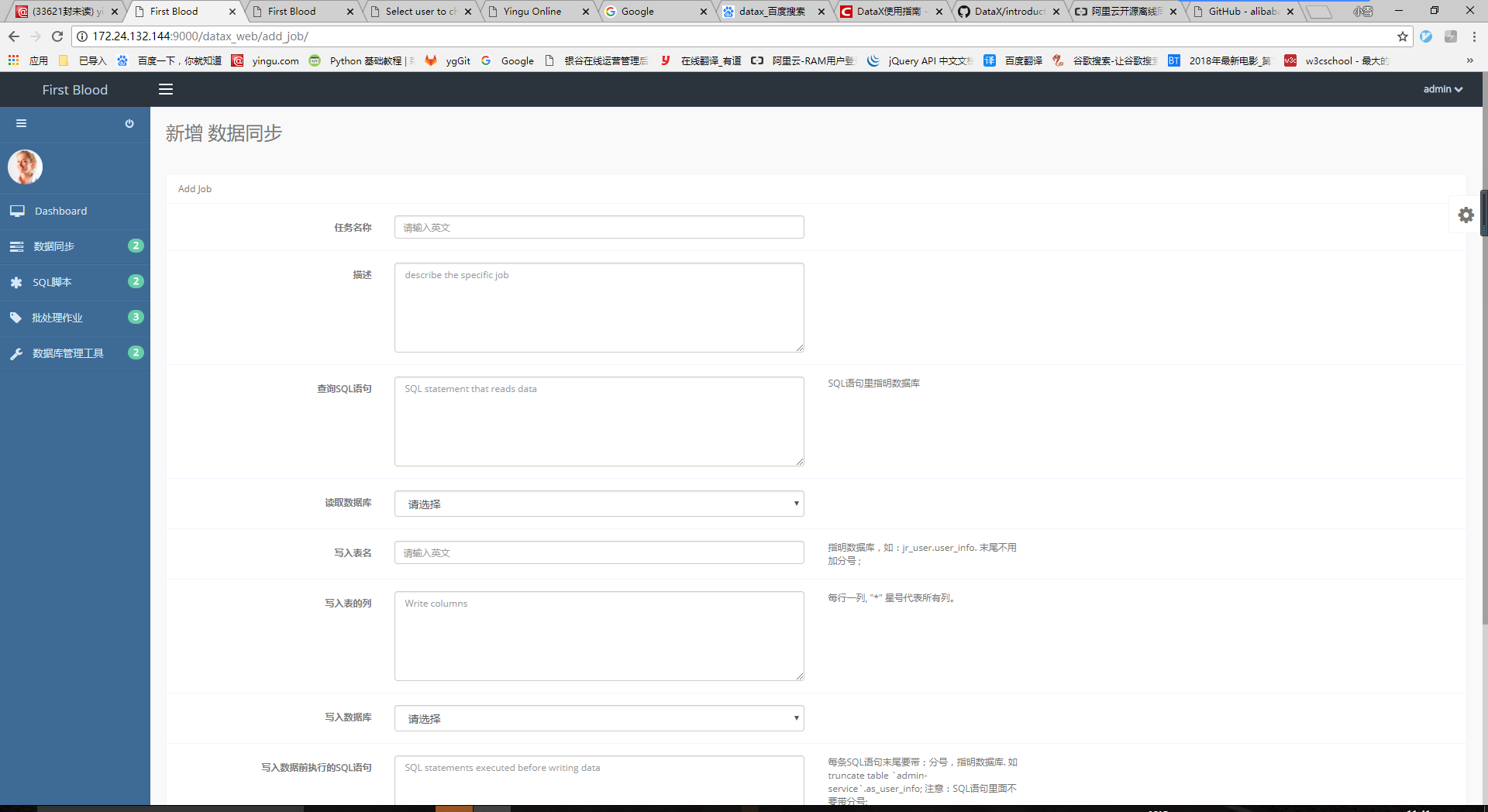
(2)新增同步任务
点击首页的“新增”按钮,进入新增任务页面,填完表单后点击保存。
(3) 更新、运行同步任务
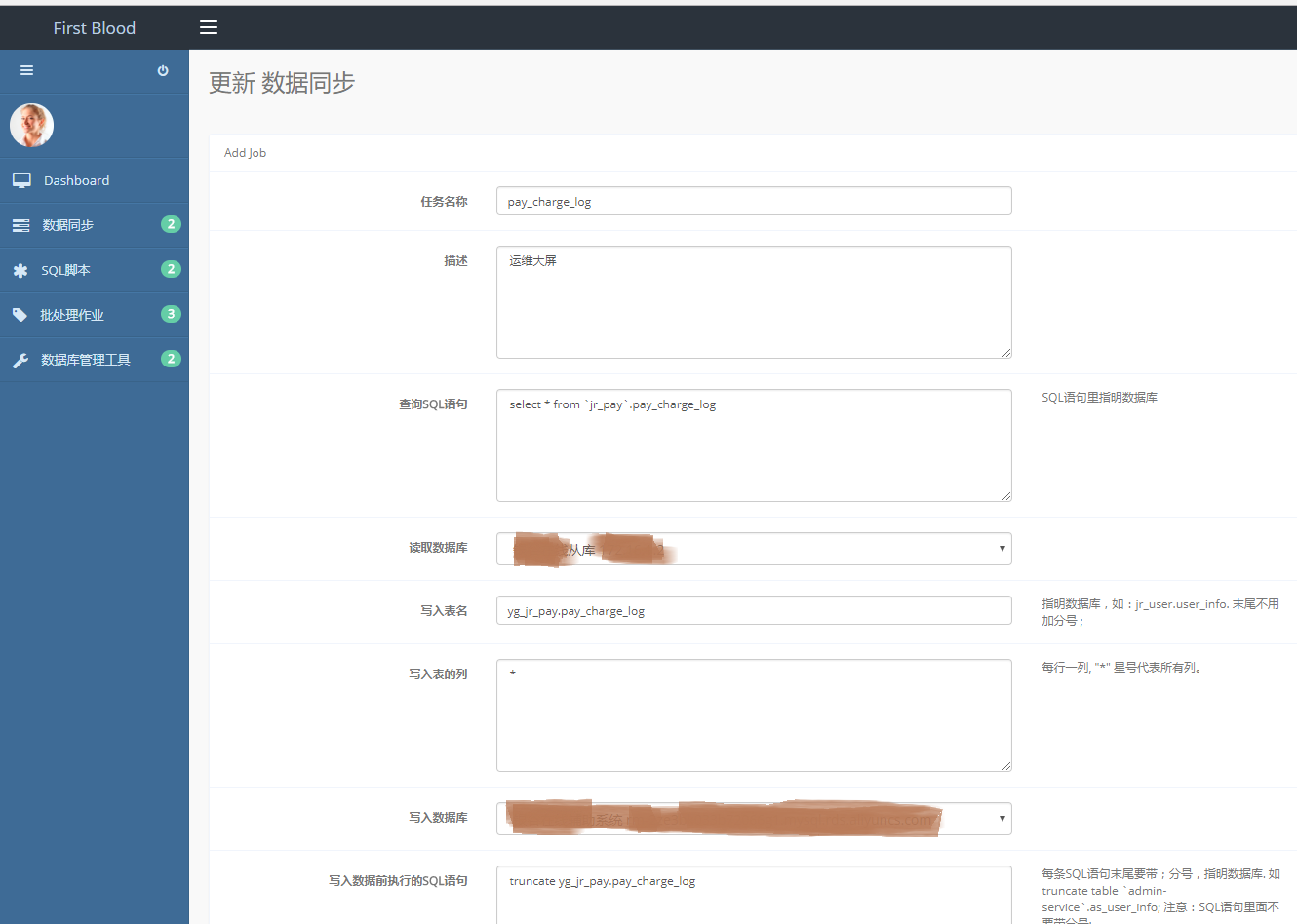
在数据同步首页点击“任务名称”,进入任务更新页面。可以对任务的SQL、数据库等等信息进行修改。
(1) 执行任务
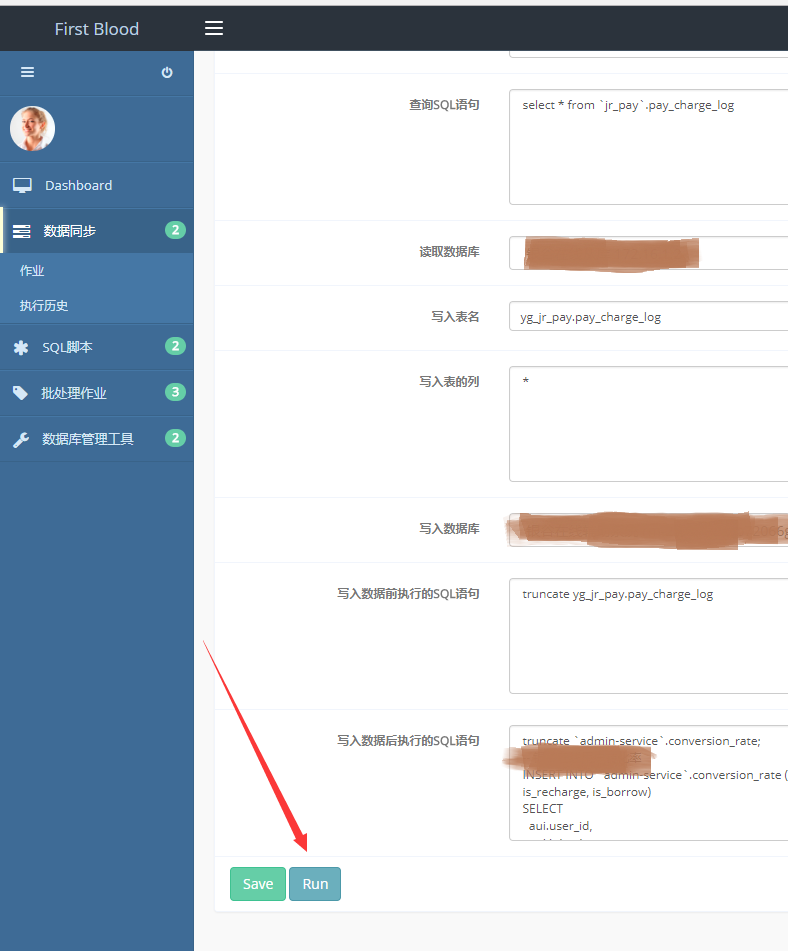
在更新页面点击“Run”按钮,可以执行任务。
(1)执行历史
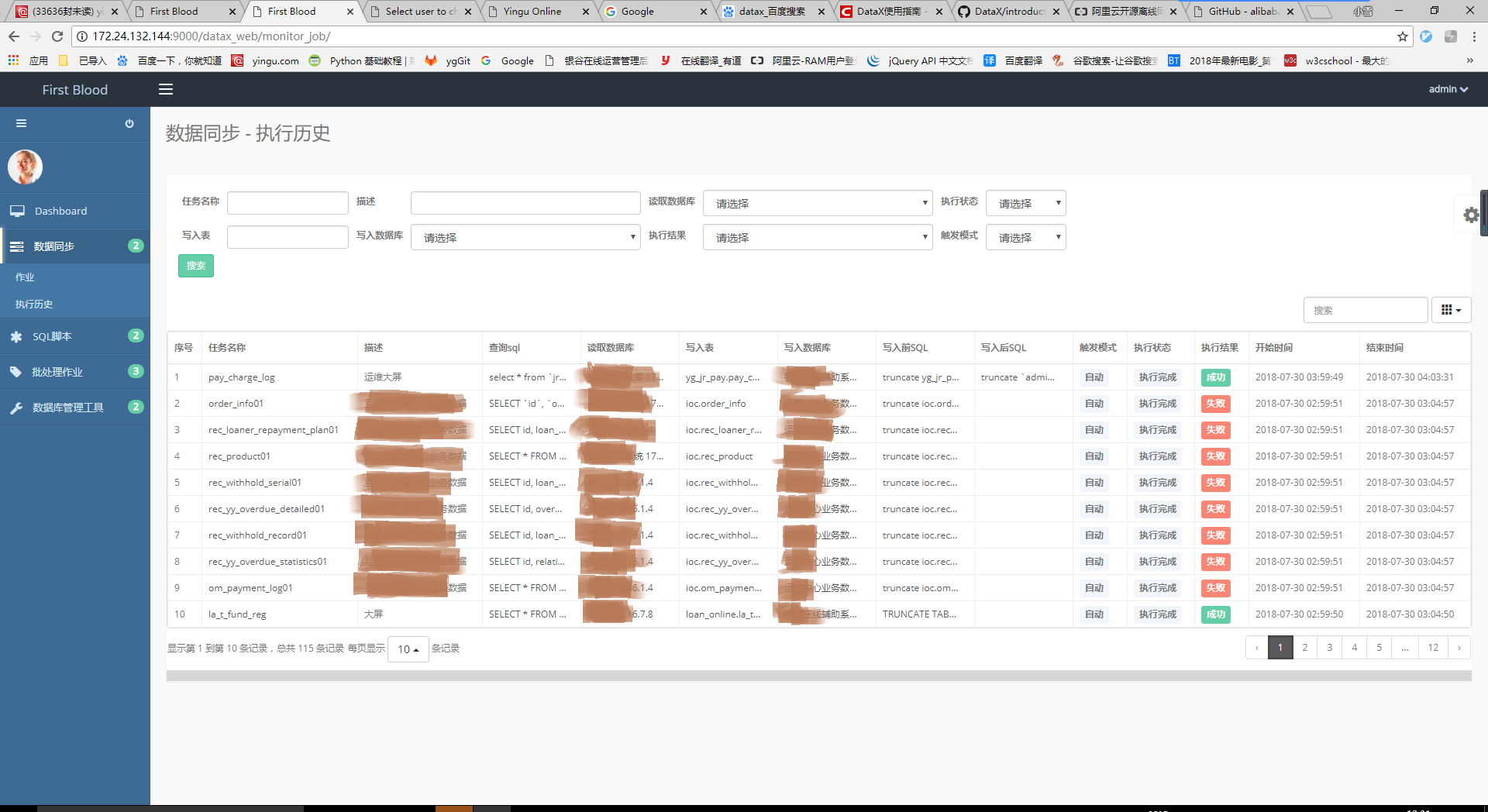
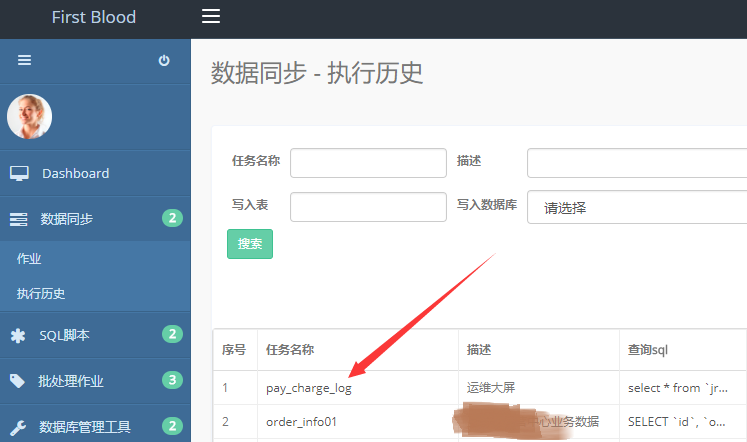
点击“数据同步->执行历史”,在执行历史首页可以查看数据同步任务的执行历史,并且可以按照任务名称、描述、读取数据库、执行状态等等进行搜索。
衍生:由于执行历史是一个日志记录,随着时间推移,数据量会越来越多,为了减小平台数据库的压力,按照业务量大小可以只保存一年、或者半年的数据。
(1)同步日志
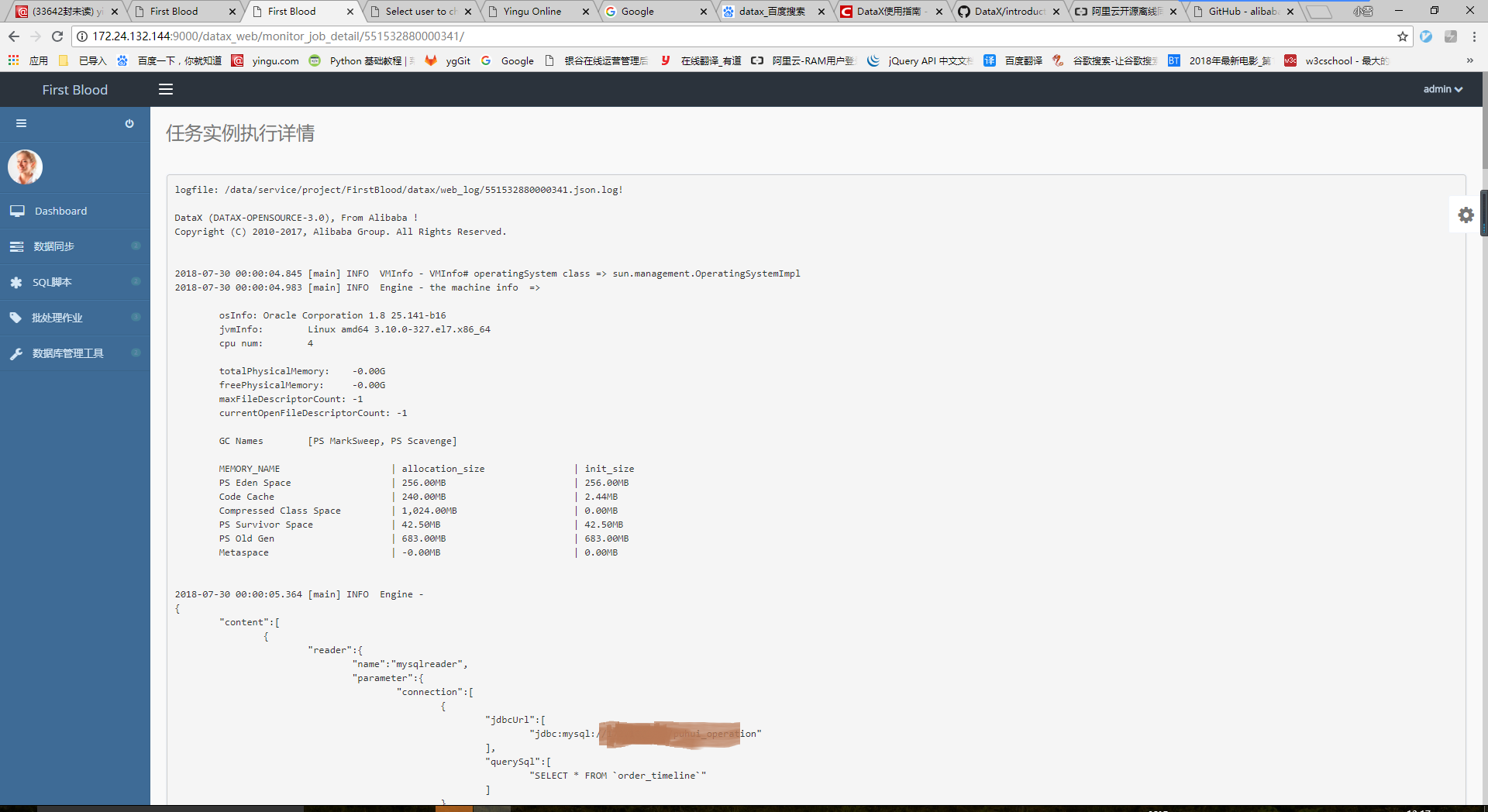
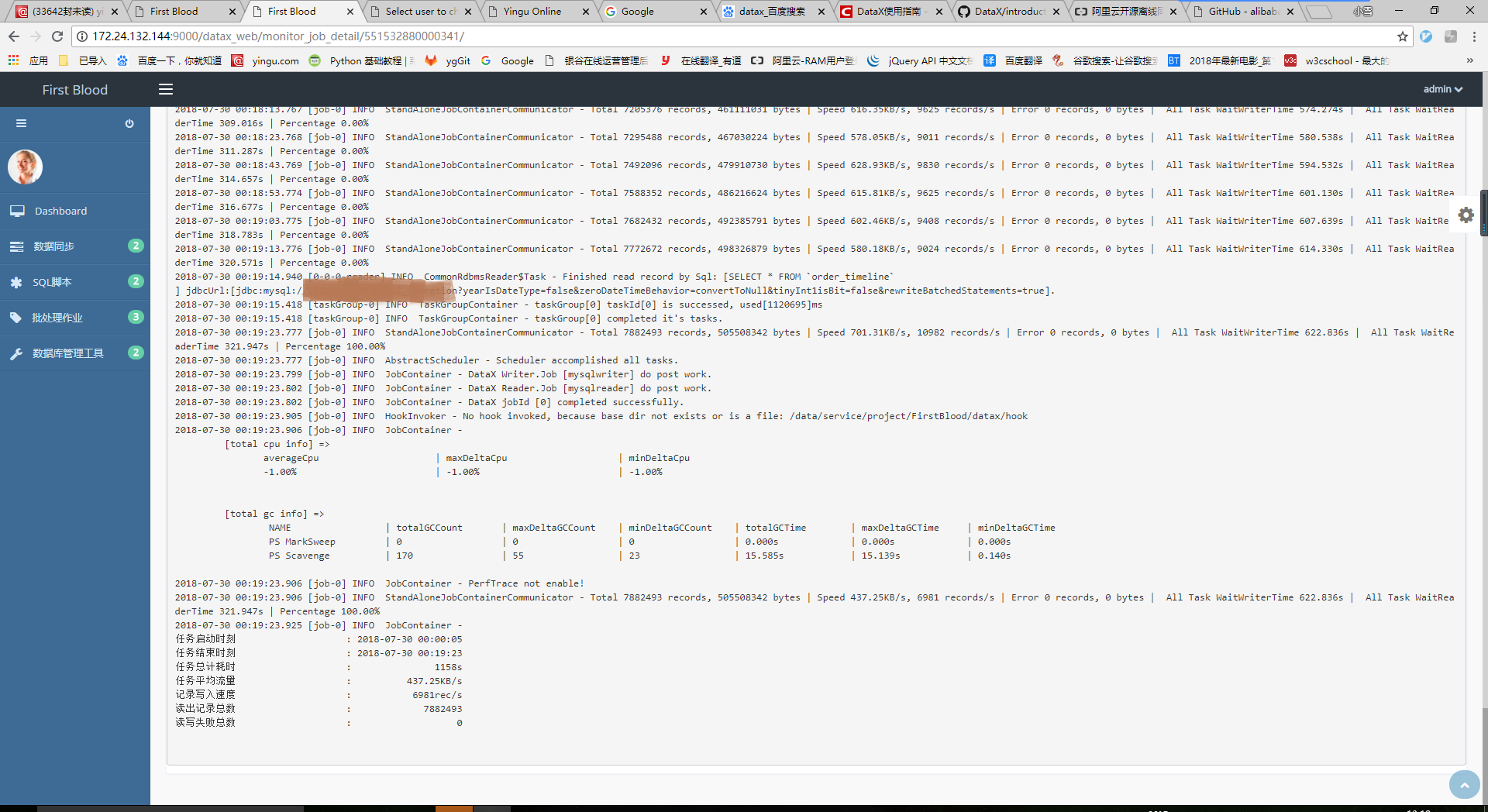
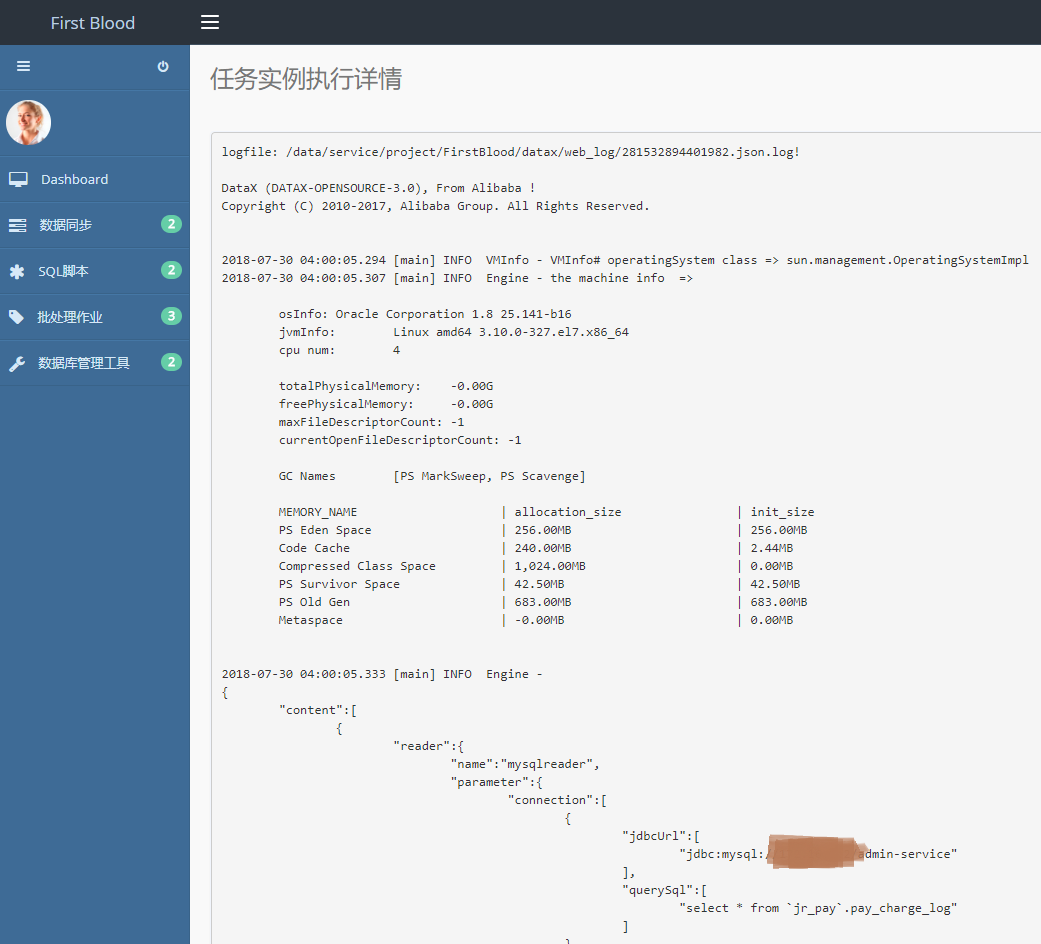
在执行历史首页点击“任务名称”,可以实时查看同步日志。
日志是由工具datax生成的日志文件,文件名为执行时任务的ID号+13位时间戳组成。平台只保存文件名,查看日志时,后台通过文件名将日志文件内容实时输出到页面。

2.批处理作业
功能描述:
将数据同步、SQL脚本(3.0版本后期开发)等等子任务组合成一个批处理作业,并发执行。并且支持linux crontab格式的定时执行。
时间紧迫,暂时不支持任务串行,或者任务之间的依赖,比如A执行完成,并且成功后才能执行B,类似功能后期3.0版本开发。
操作
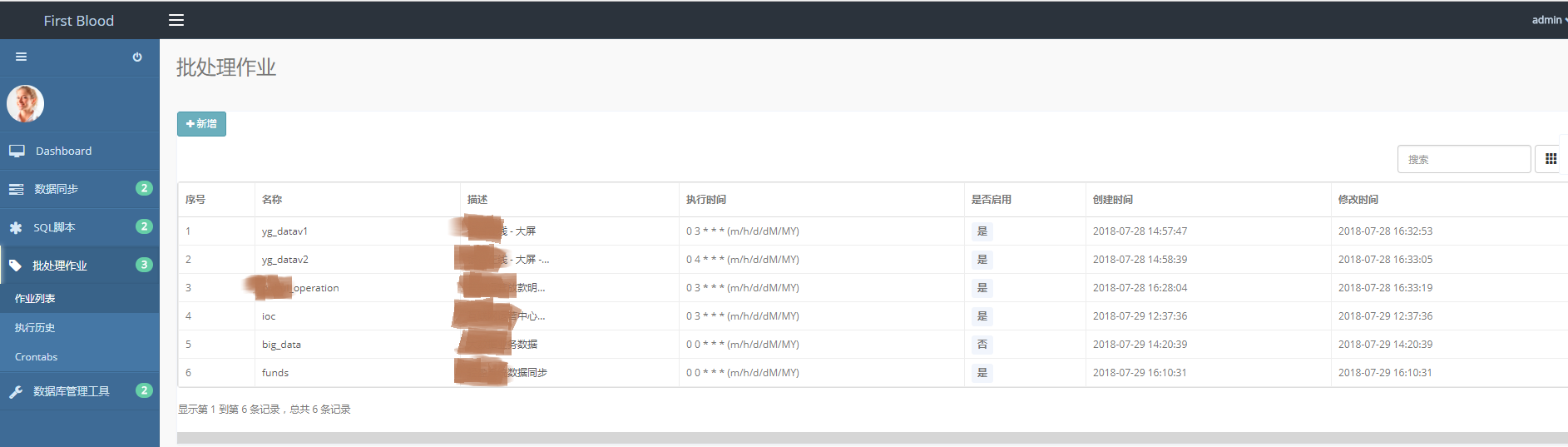
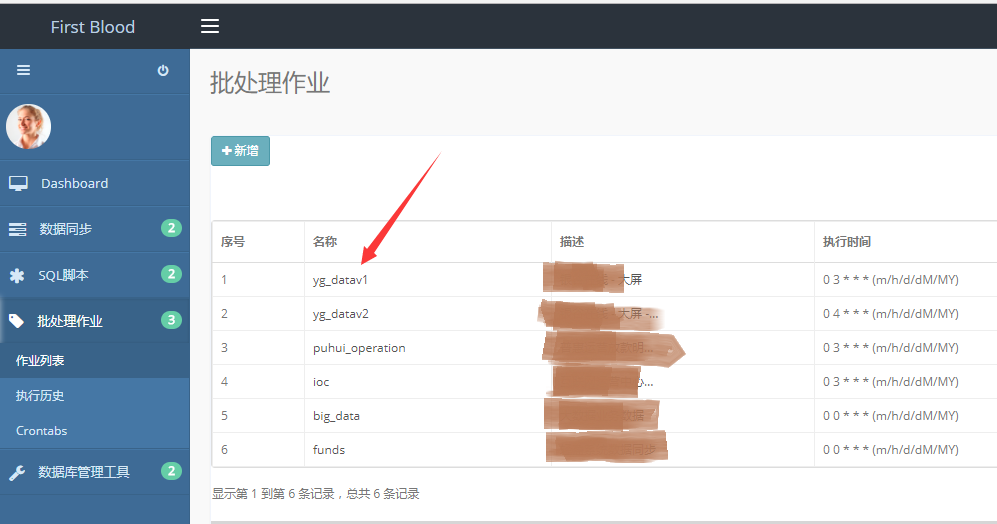
(1)批处理作业首页
点击“批处理作业->作业列表”,进入批处理作业首页
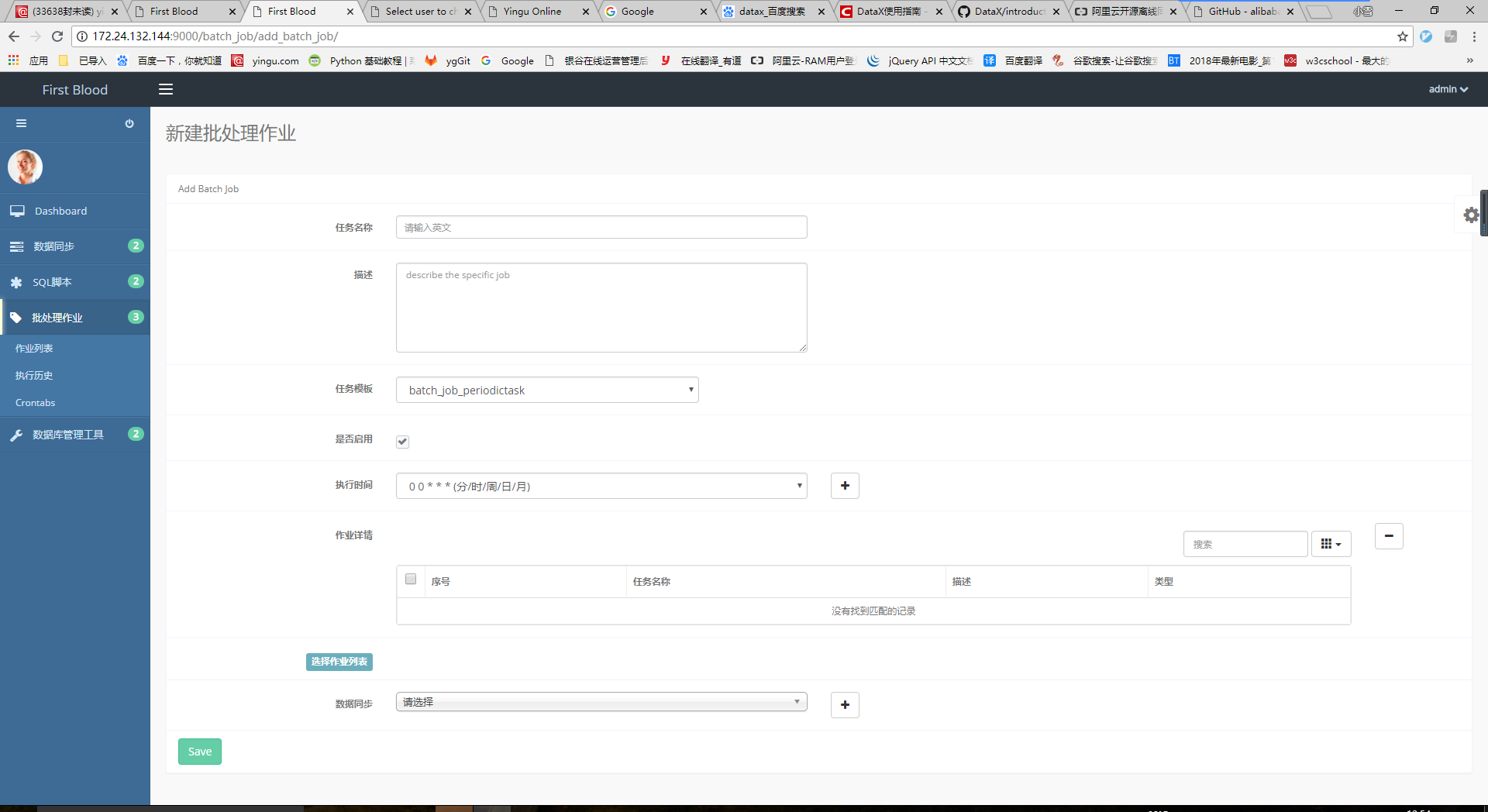
(2)新增批处理作业
点击“新增”按钮,进入新增批处理作业页面。
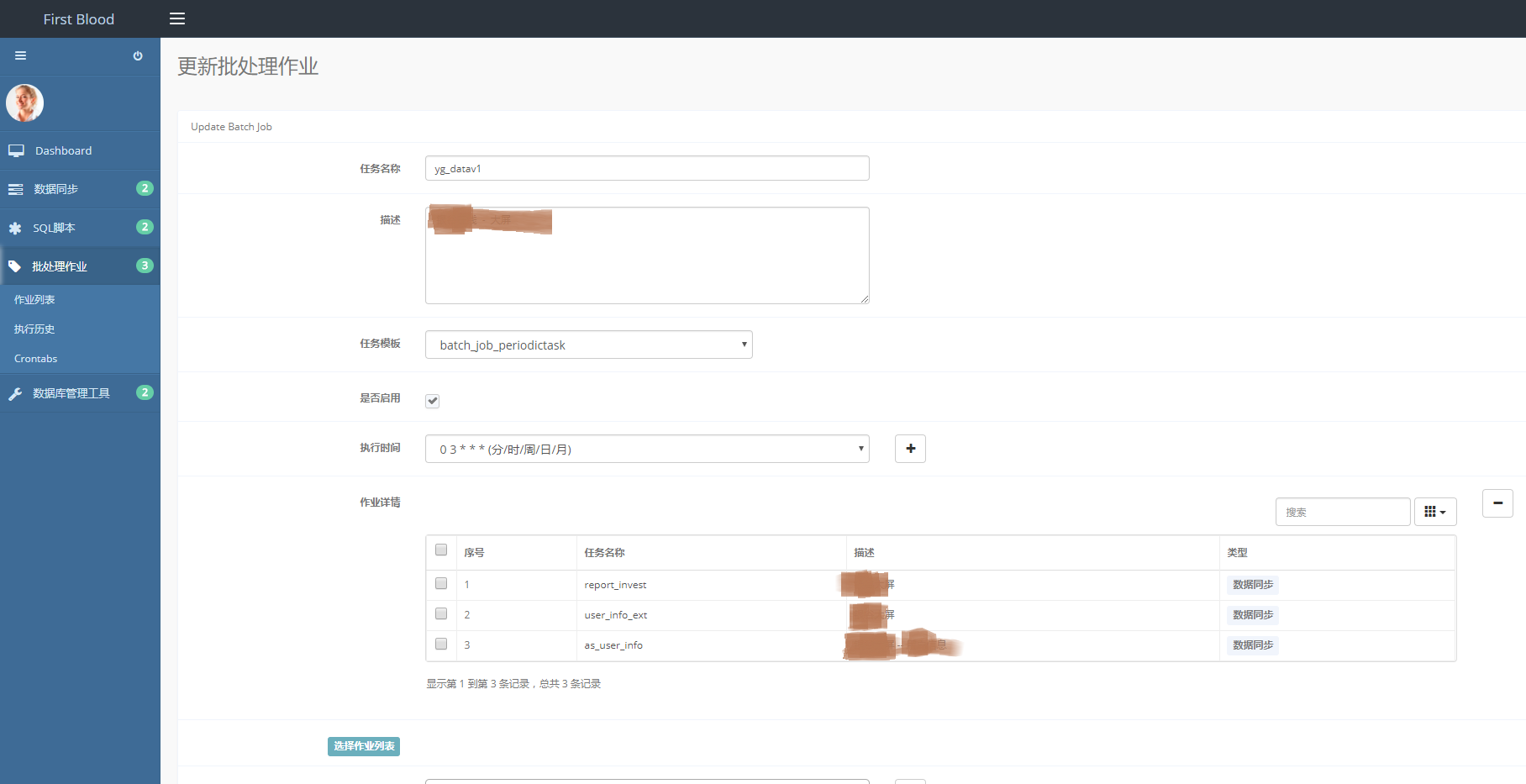
选择“执行时间”、勾选“是否启用”等等参数,填好表单后点击保存。后台会根据执行时间自动执行。
(3)更新、运行批处理作业
在批处理作业首页点击“任务名称”后,进入更新页面,可以修改批处理作业参数。
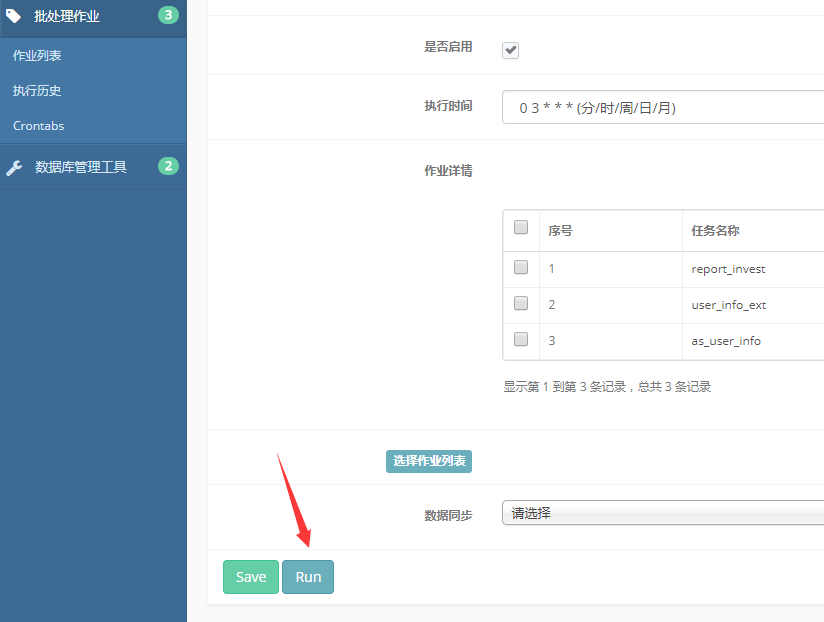
点击“Save”按钮,保存更新后的批处理作业。
在更新页面点击“Run”按钮可手动执行批处理作业。
(4)执行历史
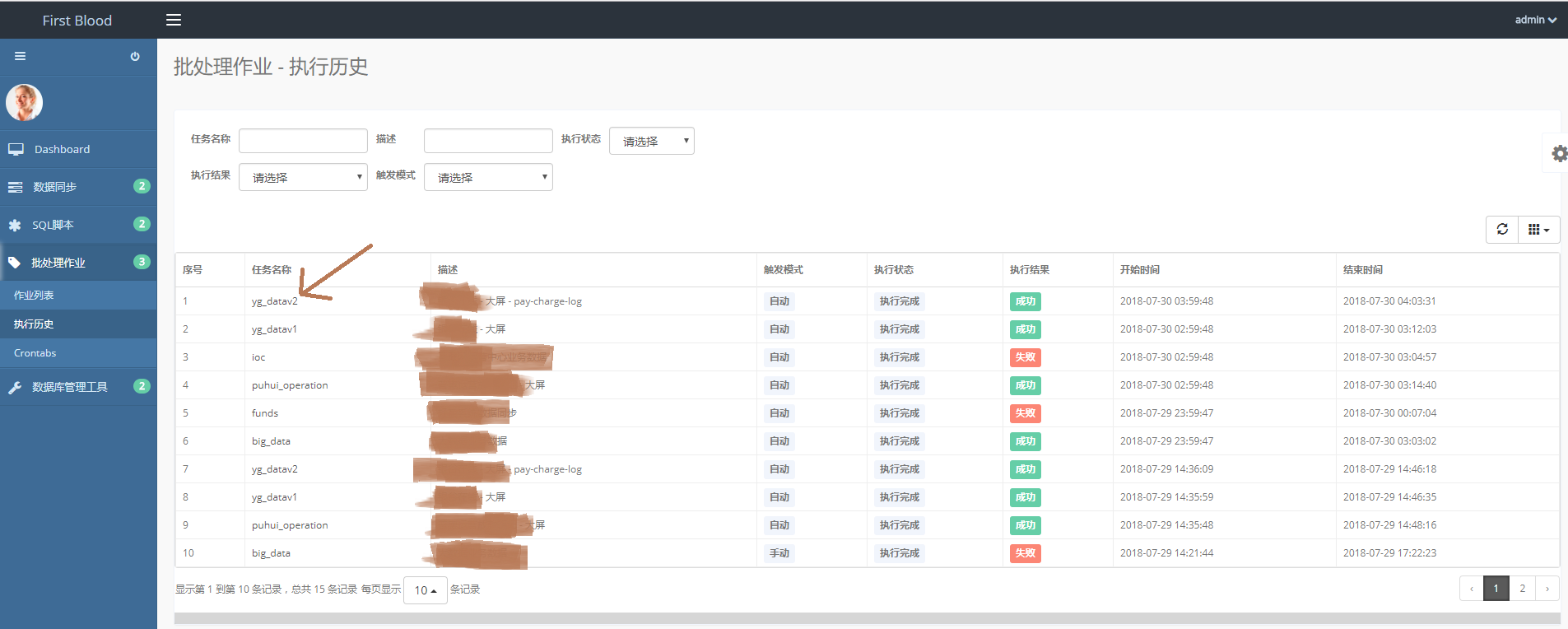
点击“批处理作业->执行历史”,即可进入批处理作业 - 执行历史首页。
可以按照任务名称、执行结果等等搜索历史的执行作业。
点击“任务名称”进入批处理作业详情 - 执行历史,可查看批处理作业执行时它的子任务。
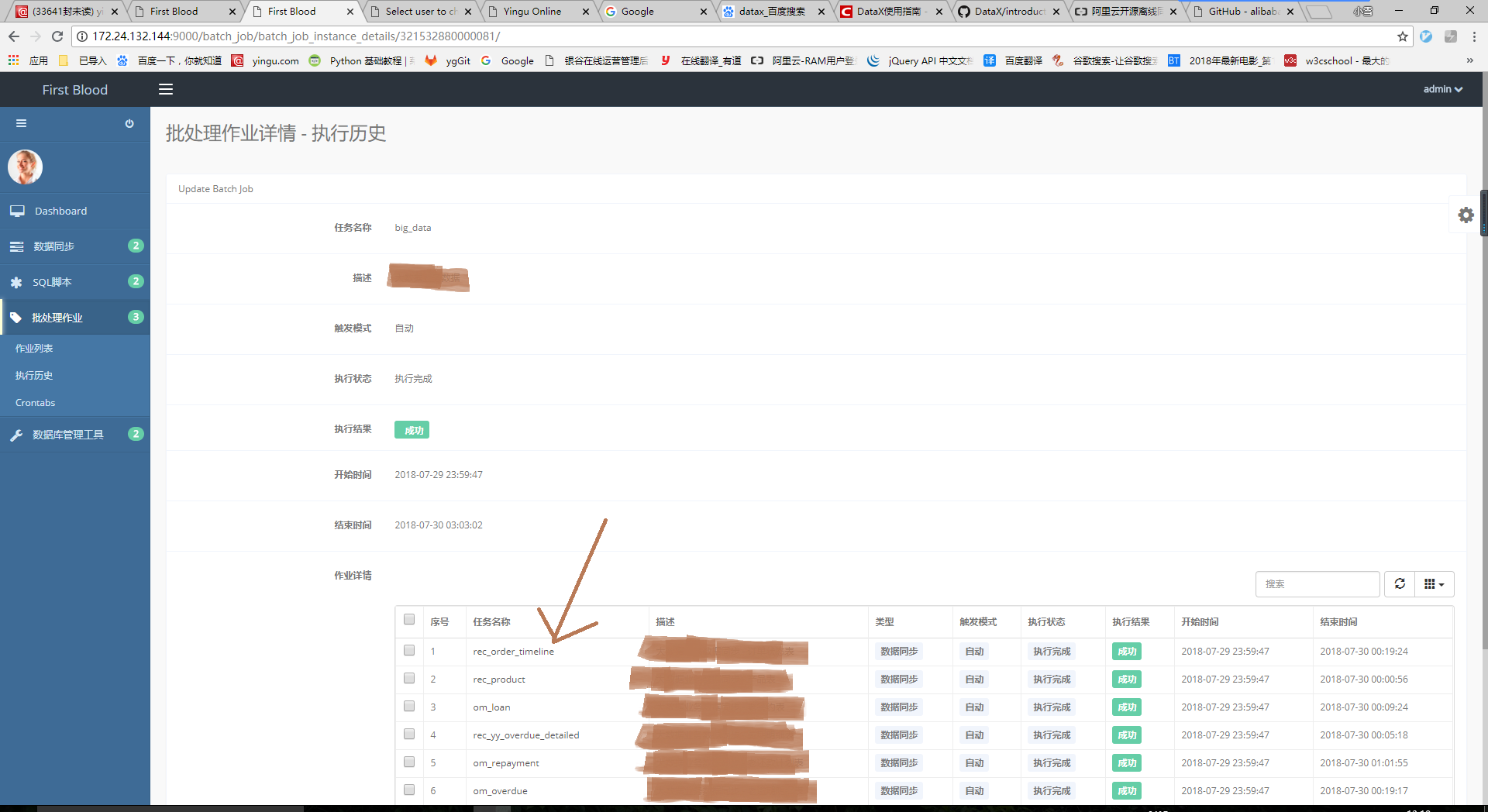
(5)执行日志
在“批处理作业详情 - 执行历史”页面,点击“任务名称”可查看每个子任务的日志。如类型为数据同步的子任务,它的日志就是调的datax的日志文件内容。