


OO第三单元(地铁,JML)单元总结
这是我们OO课程的第二个单元,这个单元的主要目的是让我们熟悉并了解JML来是我们具有规格化编程架构的思想。这个单元的主题一开始并不明了,从第一次作业的路径到第二次作业的图再到第三次作业的地铁系统,需求一步步提升,整个架构也变得复杂。这三次作业为我们模拟了一个需求不断进化的过程,也考验了我们在规格之下的架构能力。
一、JML语言的理论基础及应用工具链
1. 理论基础
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言。JML是一种行为接口规格语言 (Behavior Interface Specification Language,BISL),基于Larch方法构建。BISL提供了对方法和类型的规格定义 手段。所谓接口即一个方法或类型外部可见的内容。JML注释始终位于Java注解(comment)内部,因此它们不会对进行正常的编译代码产生影响。
注释结构 JML以javadoc注释的方式来表示规格,每行都以@起头。有两种注释方式,行注释和块注释。其中行注释的表示方式 为 //@annotation ,块注释的方式为 /* @ annotation @*/ 。
JML表达式(常用) \result表达式:表示一个非 void 类型的方法执行所获得的结果,即方法执行后的返回值。
\old( expr )表达式:用来表示一个表达式 expr 在相应方法执行前的取值。
\not_assigned(x,y,...)表达式:用来表示括号中的变量是否在方法执行过程中被赋值。
\forall表达式:全称量词修饰的表达式,表示对于给定范围内的元素,每个元素都满足相应的约束。
\exists表达式:存在量词修饰的表达式,表示对于给定范围内的元素,存在某个元素满足相应的约束。
集合构造表达式:可以在JML规格中构造一个局部的集合(容器),明确集合中可以包含的元素。例如 new JMLObjectSet {Integer i | s.contains(i) && 0 < i.intValue() } 表示构造一个JMLObjectSet对象。
操作符 子类型关系操作符: E1<:E2 ,如果类型E1是类型E2的子类型(sub type),则该表达式的结果为真,否则为假。
等价关系操作符: b_expr1<==>b_expr2 或者 b_expr1<=!=>b_expr2 ,其中b_expr1和b_expr2都是布尔表达 式,这两个表达式的意思是 b_expr1==b_expr2 或者 b_expr1!=b_expr2 。
推理操作符: b_expr1==>b_expr2 或者 b_expr2<==b_expr1 。对于表达式 b_expr1==>b_expr2 而言,当 b_expr1==false ,或者 b_expr1==true 且 b_expr2==true 时,整个表达式的值为 true 。
方法规格 前置条件(pre-condition):前置条件通过requires子句来表示: requires P; 。其中requires是JML关键词,表达的意思是“要求调用者确保P为 真”。
后置条件(post-condition):后置条件通过ensures子句来表示: ensures P; 。其中ensures是JML关键词,表达的意思是“方法实现者确保方法执 行返回结果一定满足谓词P的要求,即确保P为真”。
副作用范围限定(side-effects):副作用指方法在执行过程中会修改对象的属性数据或者类的静态成员数据,从而给后续方法的执行带来影响。JML提供了副作用约束子句,使用关键词 assignable 或者 modifiable 。
2.应用工具链
OpenJML 在IDEA中安装OpenJML插件以调用SMT solver进行规格检查
JMLUnit 在IDEA中安装JMLUnit插件以自动生成测试样例检查规格正确性
二、JMLUnitNG/JMLUnit
此次测试的类为我自己写的一个比较简易的Path类,类的具体内容如下:

生成的测试文件
测试结果
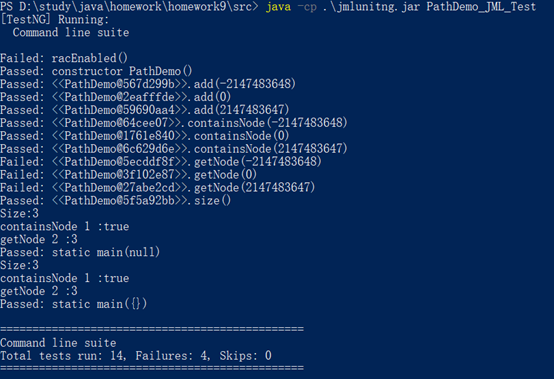
从结果上来看,自动生成的测试数据主要是0和正负的Integer型最大数这样的极限数据,其中add和containsNode的方法通过了测试而getNode方法并没有通过测试,但是对于getNode方法而言,它的JML规格中requires是要求传入的index要大于等于0,小于size的,所以其实生成的数据有些并不符合规格,需要自行对输入的数据进行规范。但另一方面这也是由于规格中没有规定对异常行为的处理才导致的问题,从侧面反映出JML不好用。

改进之后,getNode方法也通过了测试。
三、作业分析
第一次作业
第一次作业要求实现的是一个路径类和路径存储类,JML要求的方法也只是简单的存取查询方法,是JML入门级的理解和代码实现。

这次作业十分的简单,基本是用来让我们熟悉JML和这个单元作业的实现形式的。虽然只是此简单的作业,但就是个两个简单的类为之后的两次作业打了基础,算法和数据结构在这个单元中的重要性也在这次作业中初现端倪。这次作业的实现我基本按照常规思路让我在什么方法实现什么我就在这个方法里想办法实现,Path类由于需要按顺序存储我采用ArrayList进行存储。而PathContainer类由于有许多查询操作所以采用Map类进行存储会比较合适,考虑到我比较懒不想写HashCode,因此我采用了TreeMap作为存储的容器。这次偷懒明显导致了架构的延展性变差,为之后的作业造成了很大的麻烦,但我做这次作业的时候并没有这个认识,还以为这个单元的作业都非常的水,因此掉以轻心,并没有思考很多架构上的问题。而应付了事带来的另一个结果就是没有考虑算法上面的问题,在PathContainer类的distincNodeCount方法中采取for循环遍历的方式进行统计,使得时间复杂度非常高导致了在之后的强测中超时。这个bug其实还是可以归类到架构延展性的问题上,因为在这次作业中不解决这个问题,在下次作业中还是不得不面对。解决方法也并不复杂,就是再加一个TreeMap用以储存节点和节点被存入的次数,并且在每次add和remove方法被调用时更新。

由于这次作业我的态度很明显就是赶紧做完敷衍了事,所以并没有什么突出的优点,可以说做的和很多人一样甚至还要差。而这次作业的缺点则十分地明显,那就是偷懒用来TreeMap和没考虑distincNodeCount的时间复杂度,使得架构的延展性变差,为之后的作业造成了麻烦。
程序出现的bug:distincNodeCount导致的超时
查别人bug采用的策略:用大量的distincNodeCount来测别人有没有跟我一样没考虑时间复杂度导致超时。
第二次作业
这次作业在第一次作业的基础上将PathContainer类改进成了Graph类,属于一次架构上的延展。这次作业的规格要求相对上次作业也变得更为复杂,属于JML的进阶理解,考验了我们的架构能力。
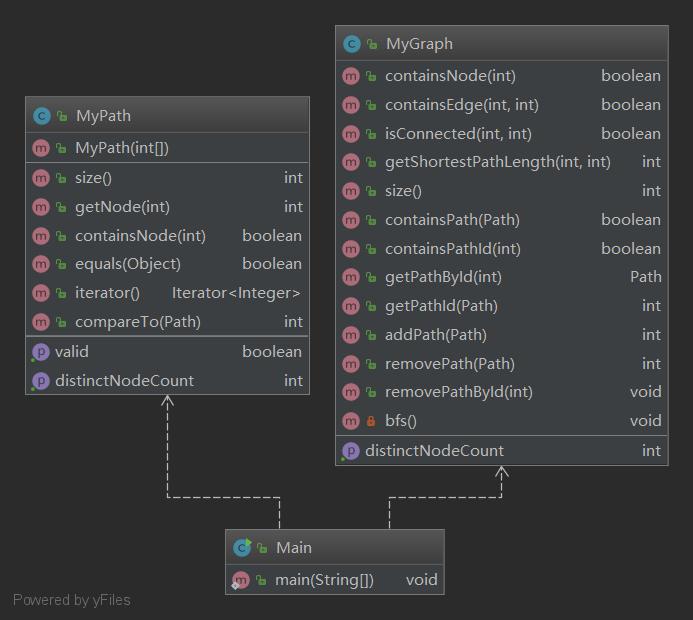
在这次作业中Path类和上次作业的Path类没有任何区别可以直接套用,Graph类相比上次的PathContainer类多了图结构的一些方法,比如说边的查询、节点之间是否相连和最短路径。要存储图就意味着需要一个邻接表,我的邻接表实现采用的时嵌套TreeMap,也就是第一个TreeMap的key是前一个节点,value是第二个TreeMap,第二个TreeMap的key是后一个节点,value是一个整型数据,用于存储前后两个节点之间是否存在一条边。之所以只记录是否存在边而不记录边的权值是因为这次作业的图比较特殊,所有边的权值都是1。而对于计算最短路问题,我吸取了上次,没有考虑时间复杂度的教训,采用了BFS算法来进行计算。然而,从我的类图中不难看出,我这次依然没有考虑架构上的问题,只是在兵来将挡水来土掩,这次作业最好的架构应当是将图单开一个类用来存储,而我依然将图和查询接口写在一起,这给最后作业带来了麻烦。
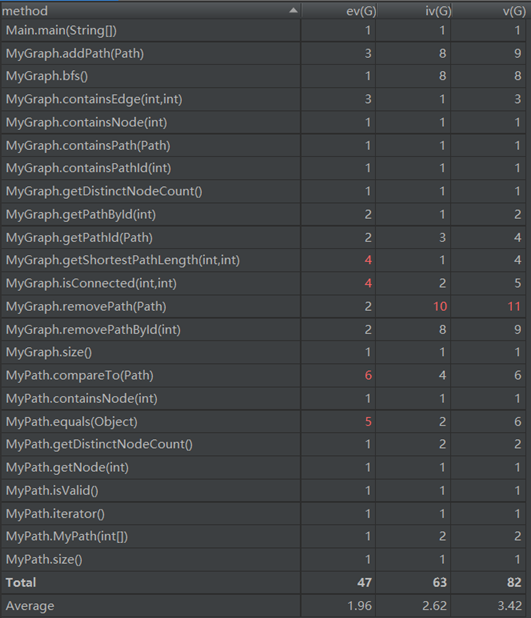

这次作业的优点就是用了BFS算法去计算最短路,有较好的时间复杂度。缺点就是没有思考架构的延展性。
这次作业出现的bug:没有出现bug
查别人bug采用的方法:用自己的测试集去测
第三次作业
这次作业是这个单元最后一次作业,这次作业将Graph再次升级成了RailwaySystem,要求实现一些地铁相关的方法,十分考验架构和对数据结构的掌握。
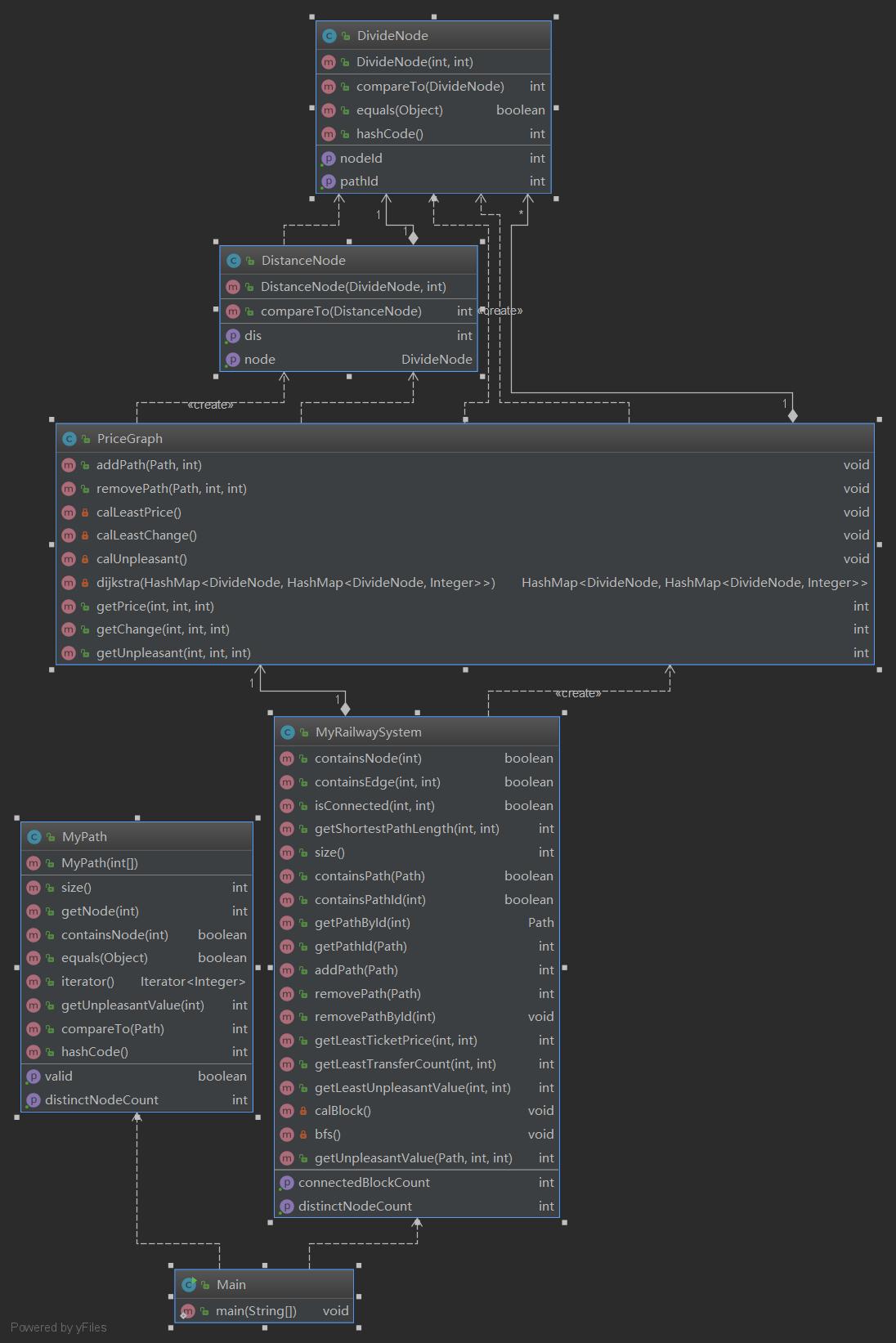
可以看到这次作业的类比较上次作业明显的变多了,相应的,这次作业的难度相对上次作业也有明显的提升。这次要在一个基础图的基础上生成不同的三张带权图并且计算各自的最短路。由于对于不同的存入的path存在地铁转乘的问题会导致不同的路径边的权值发生改变,因此我采用的是分点的方法,即将同一个点按所在路径不同分成不同的点,并且这些分出来的点之间都相连。其结果就是将所有边分成了两类,同一路径上不同点之间的边和不同路径同一个点之间的边,即一个点有两个属性——节点编号和节点所属的路径编号。因此我专门创建了一个DevideNode类用于存储分点。同时我开了一个新的类PriceGraph用于存储由基础图生成的图。由于规格要求的三种生成图其本质都是按照分点分出来的两类边赋上不同的权值产生的,所以其实是一张图不同的权值。而另一个要求实现的方法求连通块则可以由上次作业的BFS及其结果来进行计算。正因为要求实现的方法非常的多,再加之我第二次作业的时候没有将图单开一个类,导致这次架构崩盘,在RailwaySystem里存了一张图实现了BFS求最短路,又在PriceGraph里存了几张图实现了dijkstra求最短路算法,可以说是写了一坨屎。雪上加霜的是写出来的架构还存在超时的问题,其中最突出的就是得把所有TreeMap改成HashMap,另一方面,单纯的dijkstra显然是不满足作业对时间复杂度的要求的,因此还需要将起改为栈优化的dijkstra方法。再加上周末比较摸所以时间十分紧张最后写出来的架构不堪入目,至少我是不会去看第二遍的。

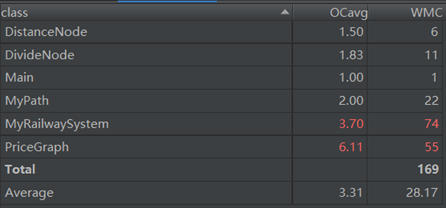
这次作业毫无优点可言,几乎就是一个拆了东墙补西墙强行拼凑起来的混合物。缺点则非常明显,那就是架构混乱。
本次作业的bug:会出现超时
查别人bug的方法:有边界数据测别人会不会超时
四、总结与感悟
这次作业又一次让我切身体会到了做一个好的架构的重要性,虽说这个单元的主要目的是了解和掌握JML,但架构和数据结构也和作业内容息息相关。
首先说一下对规格的感受,一开始我对规格的理解就是一个规范的注释,在切身体验了之后我发现规格确实可以作为一个规范的注释来帮助我看懂代码,理解我该做什么,该实现什么。但规格除了注释的作用还起到了规范和引导的作用,规格会告诉你你要实现什么但不会告诉你你该怎么实现,我作为一个程序员要做的就是在规格为我划定的范围内完成自己的架构。
再说一下对这次作业架构和数据结构的感受,首先不得不承认这次作业我轻敌了,这也导致了我第三次作业的失败,我一直以为这单元作业是一组很轻松的作业,所以并没有考虑很多架构上的事。另一方面,数据结构对这一单元的重要性如此之高我也是始料未及的,我对数据结构的掌握一直不是很熟练,所以第三次作业对我造成了不小的压力。
总而言之,做好架构才是OO的硬道理。
