

20220616 Python 语言 - 菜鸟教程
参考资料
文档环境
- Windows 10
- Python
3.10.1
# 查看python版本
python --version
Python 3.10.1
# 查看帮助命令
python -h
Python 交互模式
在终端输入 python 进入 Python 交互模式
>>> print("He123")
He123
基础语法
编码
默认情况下,Python 3 源码文件以 UTF-8 编码,所有字符串都是 unicode 字符串。 当然你也可以为源码文件指定不同的编码:
# -*- coding: cp-1252 -*-
标识符
- 第一个字符必须是字母表中字母或下划线
_ - 标识符的其他的部分由字母、数字和下划线组成
- 标识符对大小写敏感
在 Python 3 中,可以用中文作为变量名,非 ASCII 标识符也是允许的
Python 保留字
保留字即关键字,我们不能把它们用作任何标识符名称。Python 的标准库提供了一个 keyword 模块,可以输出当前版本的所有关键字:
>>> import keyword
>>> keyword.kwlist
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
注释
Python 中单行注释以 # 开头
多行注释可以用多个 # 号,还有 ''' 和 """
#!/usr/bin/python3
# 第一个注释
# 第二个注释
'''
第三注释
第四注释
'''
"""
第五注释
第六注释
"""
print("Hello, Python!")
行与缩进
Python 最具特色的就是使用缩进来表示代码块,不需要使用大括号 {}
缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数。
以下代码最后一行语句缩进数的空格数不一致,会导致运行错误:
if True:
print("Answer")
print("True")
else:
print("Answer")
print("False") # 缩进不一致,会导致运行错误
报错信息:
IndentationError: unindent does not match any outer indentation level
多行语句
Python 通常是一行写完一条语句,但如果语句很长,我们可以使用反斜杠 \ 来实现多行语句
在 [] , {} , 或 () 中的多行语句,不需要使用反斜杠 \
total = item_one + \
item_two + \
item_three
total = ['item_one', 'item_two', 'item_three',
'item_four', 'item_five']
数字 (Number) 类型
Python 中数字有四种类型:整数、布尔型、浮点数和复数。
- int (整数), 如
1, 只有一种整数类型int,表示为长整型,没有 python2 中的 Long - bool (布尔), 如
True - float (浮点数), 如
1.23、3E-2 - complex (复数), 如
1 + 2j、1.1 + 2.2j
字符串 (String)
-
Python 中单引号
'和双引号"使用完全相同。 -
使用三引号 (
'''或""") 可以指定一个多行字符串。 -
转义符
\ -
反斜杠可以用来转义,使用
r可以让反斜杠不发生转义- 如
r"this is a line with \n"则\n会显示,并不是换行
- 如
-
按字面意义级联字符串,如
"this " "is " "string"会被自动转换为this is string -
字符串可以用
+运算符连接在一起,用*运算符重复 -
Python 中的字符串有两种索引方式,从左往右以
0开始,从右往左以-1开始 -
Python 中的字符串不能改变。
-
Python 没有单独的字符类型,一个字符就是长度为 1 的字符串。
-
字符串的截取的语法格式如下:变量[头下标:尾下标:步长]
str = '123456789'
print(str) # 输出字符串 123456789
print(str[0:-1]) # 输出第一个到倒数第二个的所有字符 12345678
print(str[0]) # 输出字符串第一个字符 1
print(str[2:5]) # 输出从第三个开始到第五个的字符 345
print(str[2:]) # 输出从第三个开始后的所有字符 3456789
print(str[1:5:2]) # 输出从第二个开始到第五个且每隔一个的字符(步长为2) 24
print(str * 2) # 输出字符串两次 123456789123456789
print(str + '你好') # 连接字符串 123456789你好
print('------------------------------')
print('hello\nrunoob') # 使用反斜杠(\)+n转义特殊字符 hello 换行 runoob
print(r'hello\nrunoob') # 在字符串前面添加一个 r,表示原始字符串,不会发生转义 hello\nrunoob
这里的 r 指 raw ,即 raw string,会自动将反斜杠转义
>>> print('\n') # 输出空行
>>> print(r'\n') # 输出 \n
\n
空行
函数之间或类的方法之间用空行分隔,表示一段新的代码的开始。类和函数入口之间也用一行空行分隔,以突出函数入口的开始。
空行与代码缩进不同,空行并不是 Python 语法的一部分。书写时不插入空行,Python 解释器运行也不会出错。但是空行的作用在于分隔两段不同功能或含义的代码,便于日后代码的维护或重构。
记住:空行也是程序代码的一部分。
等待用户输入
#!/usr/bin/python3
input("\n\n按下 enter 键后退出。")
以上代码中 ,\n\n 在结果输出前会输出两个新的空行。一旦用户按下 enter 键时,程序将退出。
同一行显示多条语句
Python 可以在同一行中使用多条语句,语句之间使用分号 ; 分割
#!/usr/bin/python3
import sys; x = 'runoob'; sys.stdout.write(x + '\n')
使用交互式命令行执行,输出结果为:
>>> import sys; x = 'runoob'; sys.stdout.write(x + '\n')
runoob
7
此处的 7 表示字符数,runoob 有 6 个字符,\n 表示一个字符,加起来 7 个字符。
多个语句构成代码组
缩进相同的一组语句构成一个代码块,我们称之 代码组
像 if 、while 、def 和 class 这样的复合语句,首行以关键字开始,以冒号 : 结束,该行之后的一行或多行代码构成代码组
我们将首行及后面的代码组称为一个 子句(clause)
print 输出
print 默认输出是换行的,如果要实现不换行需要在变量末尾加上 end=""
#!/usr/bin/python3
x = "a"
y = "b"
# 换行输出
print(x)
print(y)
print('---------')
# 不换行输出
print(x, end=" ")
print(y, end=" ")
print()
执行结果为:
a
b
---------
a b
import 与 from...import
在 python 用 import 或者 from...import 来导入相应的模块。
-
将整个模块(somemodule)导入,格式为:
import somemodule -
从某个模块中导入某个函数,格式为:
from somemodule import somefunction -
从某个模块中导入多个函数,格式为:
from somemodule import firstfunc, secondfunc, thirdfunc -
将某个模块中的全部函数导入,格式为:
from somemodule import *
导入 sys 模块:
import sys
print('================Python import mode==========================')
print('命令行参数为:')
for i in sys.argv:
print(i)
print('\n python 路径为', sys.path)
导入 sys 模块的 argv,path 成员:
from sys import argv,path # 导入特定的成员
print('================python from import===================================')
print('path:', path) # 因为已经导入path成员,所以此处引用时不需要加sys.path
基本数据类型
Python 中的变量不需要声明。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
在 Python 中,变量就是变量,它没有类型,我们所说的"类型"是变量所指的内存中对象的类型。
等号 = 用来给变量赋值。
等号 = 运算符左边是一个变量名,等号 = 运算符右边是存储在变量中的值
#!/usr/bin/python3
counter = 100 # 整型变量
miles = 1000.0 # 浮点型变量
name = "runoob" # 字符串
print(counter) # 100
print(miles) # 1000.0
print(name) # runoob
多个变量赋值
a = b = c = 1
a, b, c = 1, 2, "runoob"
标准数据类型
Python3 中有六个标准的数据类型:
Number(数字)String(字符串)List(列表)Tuple(元组)Set(集合)Dictionary(字典)
Python3 的六个标准数据类型中:
- 不可变数据类型(3 个):
Number(数字)、String(字符串)、Tuple(元组) - 可变数据类型(3 个):
List(列表)、Dictionary(字典)、Set(集合)
Number(数字)
Python3 支持 int、float、bool、complex(复数)
在 Python3 里,只有一种整数类型 int ,表示为长整型
内置的 type() 函数可以用来查询变量所指的对象类型。
还可以用 isinstance 来判断
a, b, c, d = 20, 5.5, True, 4 + 3j
print(type(a), type(b), type(c), type(d)) # <class 'int'> <class 'float'> <class 'bool'> <class 'complex'>
print(isinstance(a, int)) # True
isinstance 和 type 的区别在于:
type不会认为子类是一种父类类型isinstance会认为子类是一种父类类型
Python3 中,bool 是 int 的子类,True 和 False 可以和数字相加, True1、False0 会返回 True ,但可以通过 is 来判断类型。
print(issubclass(bool, int)) # True
print(True == 1) # True
print(False == 0) # True
print(True + 1) # 2
print(False + 1) # 1
print(1 is True) # False
print(0 is False) # False
当你指定一个值时,Number 对象就会被创建:
var1 = 1
var2 = 10
您也可以使用 del 语句删除一些对象引用。
del 语句的语法是:
del var1[,var2[,var3[....,varN]]]
您可以通过使用 del 语句删除单个或多个对象。例如:
del var
del var_a, var_b
数值运算
>>> 5 + 4 # 加法
9
>>> 4.3 - 2 # 减法
2.3
>>> 3 * 7 # 乘法
21
>>> 2 / 4 # 除法,得到一个浮点数
0.5
>>> 2 // 4 # 除法,得到一个整数
0
>>> 17 % 3 # 取余
2
>>> 2 ** 5 # 乘方
32
注意:
- Python 可以同时为多个变量赋值,如
a, b = 1, 2 - 一个变量可以通过赋值指向不同类型的对象
- 数值的除法包含两个运算符:
/返回一个浮点数,//返回一个整数 - 在混合计算时,Python 会把整型转换成为浮点数
数值类型实例
| int | float | complex |
|---|---|---|
| 10 | 0.0 | 3.14j |
| 100 | 15.20 | 45.j |
| -786 | -21.9 | 9.322e-36j |
| 080 | 32.3e+18 | .876j |
| -0490 | -90. | -.6545+0J |
| -0x260 | -32.54e100 | 3e+26J |
| 0x69 | 70.2E-12 | 4.53e-7j |
Python 还支持复数,复数由实数部分和虚数部分构成,可以用 a + bj ,或者 complex(a,b) 表示, 复数的实部 a 和虚部 b 都是浮点型
String(字符串)
Python中的字符串用单引号 ' 或双引号 " 括起来,同时使用反斜杠 \ 转义特殊字符。如果你不想让反斜杠发生转义,可以在字符串前面添加一个 r ,表示原始字符串,例如 r'Ru\noob'
另外,反斜杠 \ 可以作为续行符,表示下一行是上一行的延续。也可以使用 """ 或者 ''' 跨越多行。
注意,Python 没有单独的字符类型,一个字符就是长度为 1 的字符串
字符串的截取的语法格式如下:
变量[头下标:尾下标]
索引值以 0 为开始值,-1 为从末尾的开始位置

加号 + 是字符串的连接符, 星号 * 表示复制当前字符串,与之结合的数字为复制的次数
#!/usr/bin/python3
str = 'Runoob'
print(str) # 输出字符串 Runoob
print(str[0:-1]) # 输出第一个到倒数第二个的所有字符 Runoo
print(str[0]) # 输出字符串第一个字符 R
print(str[2:5]) # 输出从第三个开始到第五个的字符 noo
print(str[2:]) # 输出从第三个开始的后的所有字符 noob
print(str * 2) # 输出字符串两次,也可以写成 print (2 * str) RunoobRunoob
print(str + "TEST") # 连接字符串 RunoobTEST
Python 字符串不能被改变。
向一个索引位置赋值,比如 word[0] = 'm' 会导致错误
注意:
- 反斜杠可以用来转义,使用
r可以让反斜杠不发生转义 - 字符串可以用
+运算符连接在一起,用*运算符重复 - Python 中的字符串有两种索引方式,从左往右以
0开始,从右往左以-1开始 - Python 中的字符串不能改变
List(列表)
List(列表) 是 Python 中使用最频繁的数据类型。
列表可以完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
列表是写在方括号 [] 之间、用逗号分隔开的元素列表。
和字符串一样,列表同样可以被索引和截取,列表被截取后返回一个包含所需元素的新列表。
列表截取的语法格式如下:
变量[头下标:尾下标]
索引值以 0 为开始值,-1 为从末尾的开始位置。
加号 + 是列表连接运算符,星号 * 是重复操作。
与 Python 字符串不一样的是,列表中的元素是可以改变的
List 内置了有很多方法,例如 append() 、pop()
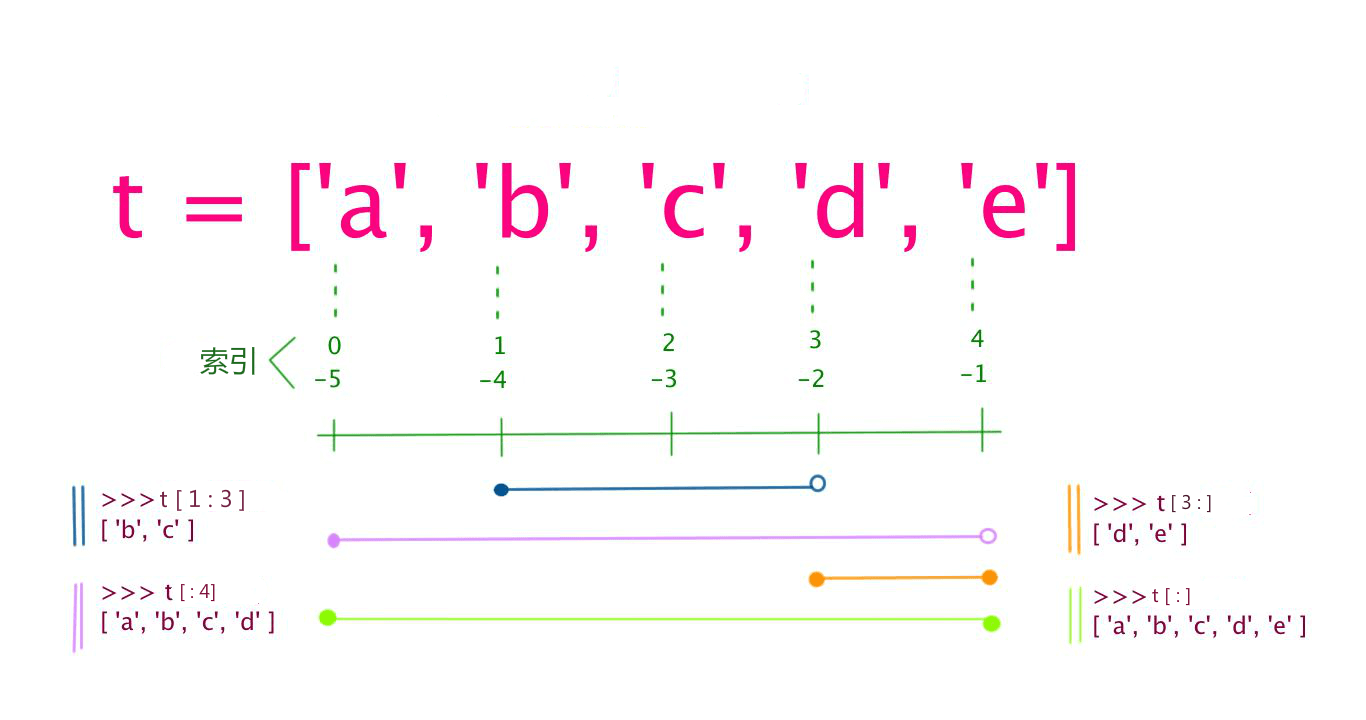
#!/usr/bin/python3
list = ['abcd', 786, 2.23, 'runoob', 70.2]
tinylist = [123, 'runoob']
print(list) # 输出完整列表 ['abcd', 786, 2.23, 'runoob', 70.2]
print(list[0]) # 输出列表第一个元素 abcd
print(list[1:3]) # 从第二个开始输出到第三个元素 [786, 2.23]
print(list[2:]) # 输出从第三个元素开始的所有元素 [2.23, 'runoob', 70.2]
print(tinylist * 2) # 输出两次列表 [123, 'runoob', 123, 'runoob']
print(list + tinylist) # 连接列表 ['abcd', 786, 2.23, 'runoob', 70.2, 123, 'runoob']
注意:
List写在方括号之间,元素用逗号隔开- 和字符串一样,
List可以被索引和切片 List可以使用+操作符进行拼接List中的元素是可以改变的
Python 列表截取可以接收第三个参数,参数作用是截取的步长,以下实例在索引 1 到索引 4 的位置并设置为步长为 2(间隔一个位置)来截取字符串
letters = ['r', 'u', 'n', 'o', 'a', 'b']
print(letters[1:4:2]) # ['u', 'o']
如果第三个参数为负数表示逆向读取,以下实例用于翻转字符串
def reverseWords(input):
# 通过空格将字符串分隔符,把各个单词分隔为列表
inputWords = input.split(" ")
# 翻转字符串
# 假设列表 list = [1,2,3,4],
# list[0]=1, list[1]=2 ,而 -1 表示最后一个元素 list[-1]=4 ( 与 list[3]=4 一样)
# inputWords[-1::-1] 有三个参数
# 第一个参数 -1 表示最后一个元素
# 第二个参数为空,表示移动到列表末尾
# 第三个参数为步长,-1 表示逆向
inputWords = inputWords[-1::-1]
# 重新组合字符串
output = ' '.join(inputWords)
return output
if __name__ == "__main__":
input = 'I like runoob'
rw = reverseWords(input)
print(rw) # runoob like I
Tuple(元组)
元组(tuple)与列表类似,不同之处在于元组的元素不能修改。元组写在小括号 () 里,元素之间用逗号隔开。
元组中的元素类型也可以不相同
元组与字符串类似,可以被索引且下标索引从 0 开始,-1 为从末尾开始的位置。也可以进行截取
其实,可以把字符串看作一种特殊的元组。
#!/usr/bin/python3
tuple = ('abcd', 786, 2.23, 'runoob', 70.2)
tinytuple = (123, 'runoob')
print(tuple) # 输出完整元组 ('abcd', 786, 2.23, 'runoob', 70.2)
print(tuple[0]) # 输出元组的第一个元素 abcd
print(tuple[1:3]) # 输出从第二个元素开始到第三个元素 (786, 2.23)
print(tuple[2:]) # 输出从第三个元素开始的所有元素 (2.23, 'runoob', 70.2)
print(tinytuple * 2) # 输出两次元组 (123, 'runoob', 123, 'runoob')
print(tuple + tinytuple) # 连接元组 ('abcd', 786, 2.23, 'runoob', 70.2, 123, 'runoob')
虽然 tuple 的元素不可改变,但它可以包含可变的对象,比如 list 列表。
构造包含 0 个或 1 个元素的元组比较特殊,所以有一些额外的语法规则:
tup1 = () # 空元组
tup2 = (20,) # 一个元素,需要在元素后添加逗号
string、list 和 tuple 都属于 sequence(序列)。
注意:
- 与字符串一样,元组的元素不能修改
- 元组也可以被索引和切片,方法一样
- 注意构造包含 0 或 1 个元素的元组的特殊语法规则
- 元组可以使用
+操作符进行拼接
Set(集合)
集合(set)是由一个或数个形态各异的大小整体组成的,构成集合的事物或对象称作元素或是成员。
基本功能是进行成员关系测试和删除重复元素。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { } ,因为 { } 是用来创建一个空字典。
创建格式:
parame = {value01,value02,...}
# 或者
set(value)
示例:
#!/usr/bin/python3
sites = {'Google', 'Taobao', 'Runoob', 'Runoob', 'Facebook', 'Zhihu', 'Baidu'}
print(sites) # 输出集合,重复的元素被自动去掉 {'Zhihu', 'Taobao', 'Baidu', 'Facebook', 'Google', 'Runoob'}
# 成员测试
if 'Runoob' in sites:
print('Runoob 在集合中') # true
else:
print('Runoob 不在集合中')
# set可以进行集合运算
a = set('abracadabra')
b = set('alacazam')
print(a) # {'c', 'a', 'd', 'b', 'r'}
print(a - b) # a 和 b 的差集 {'d', 'r', 'b'}
print(a | b) # a 和 b 的并集 {'c', 'm', 'a', 'd', 'z', 'b', 'l', 'r'}
print(a & b) # a 和 b 的交集 {'c', 'a'}
print(a ^ b) # a 和 b 中不同时存在的元素 {'r', 'm', 'l', 'd', 'z', 'b'}
Dictionary(字典)
字典(dictionary)是 Python 中另一个非常有用的内置数据类型。
列表是有序的对象集合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典是一种映射类型,字典用 { } 标识,它是一个无序的 键(key) : 值(value) 的集合。
键(key)必须使用不可变类型。
在同一个字典中,键(key)必须是唯一的。
#!/usr/bin/python3
dict = {}
dict['one'] = "1 - 菜鸟教程"
dict[2] = "2 - 菜鸟工具"
tinydict = {'name': 'runoob', 'code': 1, 'site': 'www.runoob.com'}
print(dict['one']) # 输出键为 'one' 的值 1 - 菜鸟教程
print(dict[2]) # 输出键为 2 的值 2 - 菜鸟工具
print(tinydict) # 输出完整的字典 {'name': 'runoob', 'code': 1, 'site': 'www.runoob.com'}
print(tinydict.keys()) # 输出所有键 dict_keys(['name', 'code', 'site'])
print(tinydict.values()) # 输出所有值 dict_values(['runoob', 1, 'www.runoob.com'])
构造函数 dict 可以直接从键值对序列中构建字典如下:
#!/usr/bin/python3
dict1 = dict([('Runoob', 1), ('Google', 2), ('Taobao', 3)])
dict2 = {x: x ** 2 for x in (2, 4, 6)}
dict3 = dict(Runoob=1, Google=2, Taobao=3)
print(dict1) # {'Runoob': 1, 'Google': 2, 'Taobao': 3}
print(dict2) # {2: 4, 4: 16, 6: 36}
print(dict3) # {'Runoob': 1, 'Google': 2, 'Taobao': 3}
{x: x**2 for x in (2, 4, 6)} 该代码使用的是字典推导式
字典类型也有一些内置的函数,例如 clear() 、keys() 、values() 等。
注意:
- 字典是一种映射类型,它的元素是键值对
- 字典的 key 必须为不可变类型,且不能重复
- 创建空字典使用
{ }
数据类型转换
数据类型的转换,一般情况下你只需要将数据类型作为函数名即可。
Python 数据类型转换可以分为两种:
- 隐式类型转换 - 自动完成
- 显式类型转换 - 需要使用类型函数来转换
隐式类型转换
在隐式类型转换中,Python 会自动将一种数据类型转换为另一种数据类型,不需要我们去干预。
以下实例中,我们对两种不同类型的数据进行运算,较低数据类型(整数)就会转换为较高数据类型(浮点数)以避免数据丢失。
num_int = 123
num_flo = 1.23
num_new = num_int + num_flo
print("datatype of num_int:", type(num_int)) # <class 'int'>
print("datatype of num_flo:", type(num_flo)) # <class 'float'>
print("Value of num_new:", num_new) # 124.23
print("datatype of num_new:", type(num_new)) # <class 'float'>
实例:整型数据与字符串类型的数据进行相加:
num_int = 123
num_str = "456"
print("Data type of num_int:", type(num_int))
print("Data type of num_str:", type(num_str))
print(num_int + num_str) # 异常:TypeError: unsupported operand type(s) for +: 'int' and 'str'
整型和字符串类型运算结果会报错,输出 TypeError。 Python 在这种情况下无法使用隐式转换。
但是,Python 为这些类型的情况提供了一种解决方案,称为显式转换。
显式类型转换
在显式类型转换中,用户将对象的数据类型转换为所需的数据类型。 我们使用 int()、float()、str() 等预定义函数来执行显式类型转换。
int() 强制转换为整型:
x = int(1) # x 输出结果为 1
y = int(2.8) # y 输出结果为 2
z = int("3") # z 输出结果为 3
float() 强制转换为浮点型:
x = float(1) # x 输出结果为 1.0
y = float(2.8) # y 输出结果为 2.8
z = float("3") # z 输出结果为 3.0
w = float("4.2") # w 输出结果为 4.2
str() 强制转换为字符串类型:
x = str("s1") # x 输出结果为 's1'
y = str(2) # y 输出结果为 '2'
z = str(3.0) # z 输出结果为 '3.0'
整型和字符串类型进行运算,就可以用强制类型转换来完成:
num_int = 123
num_str = "456"
print("num_int 数据类型为:", type(num_int)) # <class 'int'>
print("类型转换前,num_str 数据类型为:", type(num_str)) # <class 'str'>
num_str = int(num_str) # 强制转换为整型
print("类型转换后,num_str 数据类型为:", type(num_str)) # <class 'int'>
num_sum = num_int + num_str
print("num_int 与 num_str 相加结果为:", num_sum) # 579
print("sum 数据类型为:", type(num_sum)) # <class 'int'>
以下几个内置的函数可以执行数据类型之间的转换。这些函数返回一个新的对象,表示转换的值。
| 函数 | 描述 |
|---|---|
| int(x [,base]) | 将 x 转换为一个整数 |
| float(x) | 将 x 转换到一个浮点数 |
| complex(real [,imag]) | 创建一个复数 |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效 Python 表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个 (key, value)元组序列。 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
推导式
Python 推导式是一种独特的数据处理方式,可以从一个数据序列构建另一个新的数据序列的结构体。
Python 支持各种数据结构的推导式:
- 列表(list)推导式
- 字典(dict)推导式
- 集合(set)推导式
- 元组(tuple)推导式
列表推导式
列表推导式格式为:
[表达式 for 变量 in 列表]
[表达式 for 变量 in 列表 if 条件]
过滤掉长度小于或等于 3 的字符串列表,并将剩下的转换成大写字母:
names = ['Bob', 'Tom', 'alice', 'Jerry', 'Wendy', 'Smith']
new_names = [name.upper() for name in names if len(name) > 3]
print(new_names) # ['ALICE', 'JERRY', 'WENDY', 'SMITH']
计算 30 以内可以被 3 整除的整数:
multiples = [i for i in range(30) if i % 3 == 0]
print(multiples) # [0, 3, 6, 9, 12, 15, 18, 21, 24, 27]
字典推导式
字典推导基本格式:
{ key_expr: value_expr for value in collection }
# 或
{ key_expr: value_expr for value in collection if condition }
使用字符串及其长度创建字典:
listdemo = ['Google', 'Runoob', 'Taobao']
# 将列表中各字符串值为键,各字符串的长度为值,组成键值对
newdict = {key: len(key) for key in listdemo}
print(newdict) # {'Google': 6, 'Runoob': 6, 'Taobao': 6}
提供三个数字,以三个数字为键,三个数字的平方为值来创建字典:
dic = {x: x**2 for x in (2, 4, 6)}
print(dic) # {2: 4, 4: 16, 6: 36}
print(type(dic)) # <class 'dict'>
集合推导式
集合推导式基本格式:
{ expression for item in Sequence }
# 或
{ expression for item in Sequence if conditional }
计算数字 1,2,3 的平方数:
setnew = {i ** 2 for i in (1, 2, 3)}
print(setnew) # {1, 4, 9}
判断不是 abc 的字母并输出:
a = {x for x in 'abracadabra' if x not in 'abc'}
print(a) # {'r', 'd'}
print(type(a)) # <class 'set'>
元组推导式
元组推导式可以利用 range 区间、元组、列表、字典和集合等数据类型,快速生成一个满足指定需求的元组。
元组推导式基本格式:
(expression for item in Sequence )
# 或
(expression for item in Sequence if conditional )
元组推导式和列表推导式的用法也完全相同,只是元组推导式是用 () 圆括号将各部分括起来,而列表推导式用的是中括号 [] ,另外元组推导式返回的结果是一个生成器对象。
例如,我们可以使用下面的代码生成一个包含数字 1~9 的元组:
a = (x for x in range(1, 10))
print(a) # 返回的是生成器对象
# <generator object <genexpr> at 0x0000015F0DB15FC0>
print(tuple(a)) # 使用 tuple() 函数,可以直接将生成器对象转换成元组
# (1, 2, 3, 4, 5, 6, 7, 8, 9)
Python3 解释器
Linux/Unix的系统上,一般默认的 python 版本为 2.x,我们可以将 python3.x 安装在 /usr/local/python3 目录中。
安装完成后,我们可以将路径 /usr/local/python3/bin 添加到您的 Linux/Unix 操作系统的环境变量中,这样您就可以通过 shell 终端输入下面的命令来启动 Python3 。
$ PATH=$PATH:/usr/local/python3/bin/python3 # 设置环境变量
$ python3 --version
Python 3.4.0
在 Window 系统下你可以通过以下命令来设置 Python 的环境变量,假设你的 Python 安装在 C:\Python34 下:
set path=%path%;C:\python34
交互式编程
Linux 下:
$ python3
Python 3.6.8 (default, Apr 19 2021, 17:20:37)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
Windows 下:
> python
Python 3.10.1 (tags/v3.10.1:2cd268a, Dec 6 2021, 19:10:37) [MSC v.1929 64 bit (AMD64)] on win32
脚本式编程
通过以下命令执行该脚本:
$ python3 hello.py
在 Linux/Unix 系统中,你可以在脚本顶部添加以下命令让 Python 脚本可以像 SHELL 脚本一样可直接执行:
#! /usr/bin/env python3
然后修改脚本权限,使其有执行权限,命令如下:
$ chmod +x hello.py
执行以下命令:
./hello.py
注释
单行注释以 # 开头
多行注释用三个单引号 ''' 或者三个双引号 """ 将注释括起来
运算符
Python 语言支持以下类型的运算符:
- 算术运算符
- 比较(关系)运算符
- 赋值运算符
- 逻辑运算符
- 位运算符
- 成员运算符
- 身份运算符
- 运算符优先级
算术运算符
以下假设变量 a=10 ,变量 b=21 :
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 - 两个对象相加 | a + b 输出结果 31 |
| - | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -11 |
| * | 乘 - 两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 210 |
| / | 除 - x 除以 y | b / a 输出结果 2.1 |
| % | 取模 - 返回除法的余数 | b % a 输出结果 1 |
| ** | 幂 - 返回x的y次幂 | a**b 为 10 的21次方 |
| // | 取整除 - 向下取接近商的整数 | >>> 9//2 4 >>> -9//2 -5 |
#!/usr/bin/python3
a = 21
b = 10
c = 0
print("a 的值位:", a) # 21
print("b 的值位:", b) # 10
c = a + b
print("a + b 的值为:", c) # 31
c = a - b
print("a - b 的值为:", c) # 11
c = a * b
print("a * b 的值为:", c) # 210
c = a / b
print("a / b 的值为:", c) # 2.1
c = a % b
print("a % b 的值为:", c) # 1
# 修改变量 a 、b 、c
a = 2
b = 3
c = a ** b
print("a ** b 的值为:", c) # 8
a = 10
b = 5
c = a // b
print("a // b 的值为:", c) # 2
比较运算符
以下假设变量 a 为 10 ,变量 b 为 20 :
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于 - 比较对象是否相等 | (a == b) 返回 False |
| != | 不等于 - 比较两个对象是否不相等 | (a != b) 返回 True |
| > | 大于 - 返回 x 是否大于 y | (a > b) 返回 False |
| < | 小于 - 返回 x 是否小于 y 。所有比较运算符返回 1 表示真,返回0表示假。这分别与特殊的变量 True 和 False 等价。注意,这些变量名的大写。 | (a < b) 返回 True |
| >= | 大于等于 - 返回 x 是否大于等于 y | (a >= b) 返回 False |
| <= | 小于等于 - 返回 x 是否小于等于 y | (a <= b) 返回 True |
赋值运算符
以下假设变量 a 为 10 ,变量 b 为 20 :
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
| := | 海象运算符,可在表达式内部为变量赋值。Python3.8 版本新增运算符 | 在这个示例中,赋值表达式可以避免调用 len() 两次:if (n := len(a)) > 10: print(f"List is too long ({n} elements, expected <= 10)") |
位运算符
按位运算符是把数字看作二进制来进行计算的。Python中的按位运算法则如下:
下表中变量 a 为 60,b 为 13二进制格式如下:
a = 0011 1100
b = 0000 1101
-----------------
a&b = 0000 1100
a|b = 0011 1101
a^b = 0011 0001
~a = 1100 0011
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符:参与运算的两个值,如果两个相应位都为 1 ,则该位的结果为 1 ,否则为 0 | (a & b) 输出结果 12 ,二进制解释: 0000 1100 |
| | | 按位或运算符:只要对应的二个二进位有一个为 1 时,结果位就为 1 | (a | b) 输出结果 61 ,二进制解释: 0011 1101 |
| ^ | 按位异或运算符:当两对应的二进位相异时,结果为 1 | (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
| ~ | 按位取反运算符:对数据的每个二进制位取反,即把 1 变为 0 ,把 0 变为 1。~x 类似于 -x-1 | (~a) 输出结果 -61 ,二进制解释: 1100 0011, 在一个有符号二进制数的补码形式。 |
| << | 左移动运算符:运算数的各二进位全部左移若干位,由 << 右边的数指定移动的位数,高位丢弃,低位补 0 |
a << 2 输出结果 240 ,二进制解释: 1111 0000 |
| >> | 右移动运算符:把 >> 左边的运算数的各二进位全部右移若干位, >> 右边的数指定移动的位数 |
a >> 2 输出结果 15 ,二进制解释: 0000 1111 |
逻辑运算符
Python 语言支持逻辑运算符,以下假设变量 a 为 10 ,b为 20 :
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔"与" - 如果 x 为 False,x and y 返回 x 的值,否则返回 y 的计算值。 | (a and b) 返回 20。 |
| or | x or y | 布尔"或" - 如果 x 是 True,它返回 x 的值,否则它返回 y 的计算值。 | (a or b) 返回 10。 |
| not | not x | 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not(a and b) 返回 False |
成员运算符
除了以上的一些运算符之外,Python 还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组。
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True ,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True |
| not in | 如果在指定的序列中没有找到值返回 True ,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True |
#!/usr/bin/python3
a = 10
b = 20
list = [1, 2, 3, 4, 5]
if (a in list):
print("1 - 变量 a 在给定的列表中 list 中")
else:
print("1 - 变量 a 不在给定的列表中 list 中") # true
if (b not in list):
print("2 - 变量 b 不在给定的列表中 list 中") # true
else:
print("2 - 变量 b 在给定的列表中 list 中")
# 修改变量 a 的值
a = 2
if (a in list):
print("3 - 变量 a 在给定的列表中 list 中") # true
else:
print("3 - 变量 a 不在给定的列表中 list 中")
身份运算符
身份运算符用于比较两个对象的存储单元
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y , 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 id(x) != id(y)。如果引用的不是同一个对象则返回结果 True,否则返回 False。 |
id() 函数用于获取对象内存地址
#!/usr/bin/python3
a = 20
b = 20
if (a is b):
print("1 - a 和 b 有相同的标识") # true
else:
print("1 - a 和 b 没有相同的标识")
if (id(a) == id(b)):
print("2 - a 和 b 有相同的标识") # true
else:
print("2 - a 和 b 没有相同的标识")
# 修改变量 b 的值
b = 30
if (a is b):
print("3 - a 和 b 有相同的标识")
else:
print("3 - a 和 b 没有相同的标识") # true
if (a is not b):
print("4 - a 和 b 没有相同的标识") # true
else:
print("4 - a 和 b 有相同的标识")
is 与 == 区别:is 用于判断两个变量引用对象是否为同一个, == 用于判断引用变量的值是否相等
运算符优先级
以下表格列出了从最高到最低优先级的所有运算符, 相同单元格内的运算符具有相同优先级。
| 运算符 | 描述 |
|---|---|
(expressions...) , [expressions...] , {key: value...} , {expressions...} |
圆括号的表达式 |
x[index] , x[index:index] , x(arguments...) , x.attribute |
读取,切片,调用,属性引用 |
await x |
await 表达式 |
** |
乘方(指数) |
+x , -x , ~x |
正,负,按位非 NOT |
* , @ , / , // , % |
乘,矩阵乘,除,整除,取余 |
+ , - |
加和减 |
<< , >> |
移位 |
& |
按位与 AND |
^ |
按位异或 XOR |
| ` | ` |
in , not in , is , is not , < , <= , > , >= , != , == |
比较运算,包括成员检测和标识号检测 |
not x |
逻辑非 NOT |
and |
逻辑与 AND |
or |
逻辑或 OR |
if -- else |
条件表达式 |
lambda |
lambda 表达式 |
:= |
赋值表达式 |
Pyhton3 已不支持 <> 运算符,可以使用 != 代替
数字(Number)
数据类型是不允许改变的,这就意味着如果改变数字数据类型的值,将重新分配内存空间。
以下实例在变量赋值时 Number 对象将被创建:
var1 = 1
var2 = 10
也可以使用 del 语句删除一些数字对象的引用
del var
del var_a, var_b
Python 支持三种不同的数值类型:
- 整型(int) - 通常被称为是整型或整数,是正或负整数,不带小数点。Python3 整型是没有限制大小的,可以当作 Long 类型使用,所以 Python3 没有 Python2 的 Long 类型。布尔(bool) 是整型的子类型
- 浮点型(float) - 浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 * 10^2 = 250)
- 复数(complex) - 复数由实数部分和虚数部分构成,可以用
a + bj,或者complex(a,b)表示, 复数的实部 a 和虚部 b 都是浮点型
可以使用十六进制和八进制来代表整数:
print(0xA0F) # 十六进制 2575
print(0o37) # 八进制 31
数字类型转换
有时候,我们需要对数据内置的类型进行转换,数据类型的转换,你只需要将数据类型作为函数名即可。
- int(x) 将 x 转换为一个整数
- float(x) 将 x 转换到一个浮点数
- complex(x) 将 x 转换到一个复数,实数部分为 x ,虚数部分为 0
- complex(x, y) 将 x 和 y 转换到一个复数,实数部分为 x,虚数部分为 y。x 和 y 是数字表达式
数字运算
在整数除法中,除法 / 总是返回一个浮点数,如果只想得到整数的结果,丢弃可能的分数部分,可以使用运算符 //
// 得到的并不一定是整数类型的数,它与分母分子的数据类型有关系
print(17 / 3) # 5.666666666666667
print(17 // 3) # 5
print(17 % 3) # 2
print(7 // 2) # 3
print(7.0 // 2) # 3.0
print(7 // 2.0) # 3.0
print(7.0 // 2.0) # 3.0
不同类型的数混合运算时会将整数转换为浮点数
print(3 * 3.75 / 1.5) # 7.5
print(7.0 / 2) # 3.5
在交互模式中,最后被输出的表达式结果被赋值给变量 _ 。例如:
>>> tax = 12.5 / 100
>>> price = 100.50
>>> price * tax
12.5625
>>> price + _
113.0625
>>> round(_, 2)
113.06
此处, _ 变量应被用户视为只读变量
数学函数
| 函数 | 返回值 ( 描述 ) |
|---|---|
| abs(x) | 返回数字的绝对值,如 abs(-10) 返回 10 |
| ceil(x) | 返回数字的上入整数,如 math.ceil(4.1) 返回 5 |
| cmp(x, y) | 如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1。 Python 3 已废弃,使用 (x>y)-(x<y) 替换。 |
| exp(x) | 返回 e 的 x 次幂,如 math.exp(1) 返回 2.718281828459045 |
| fabs(x) | 返回数字的绝对值,如 math.fabs(-10) 返回 10.0 |
| floor(x) | 返回数字的下舍整数,如 math.floor(4.9) 返回 4 |
| log(x) | 如 math.log(math.e) 返回 1.0 ,math.log(100,10) 返回 2.0 |
| log10(x) | 返回以 10 为基数的 x 的对数,如 math.log10(100) 返回 2.0 |
| max(x1, x2,...) | 返回给定参数的最大值,参数可以为序列 |
| min(x1, x2,...) | 返回给定参数的最小值,参数可以为序列 |
| modf(x) | 返回 x 的整数部分与小数部分,两部分的数值符号与 x 相同,整数部分以浮点型表示 |
| pow(x, y) | x**y 运算后的值 |
| round(x [,n]) | 返回浮点数 x 的四舍五入值,如给出 n 值,则代表舍入到小数点后的位数。其实准确的说是保留值将保留到离上一位更近的一端 |
| sqrt(x) | 返回数字 x 的平方根 |
随机数函数
随机数可以用于数学,游戏,安全等领域中,还经常被嵌入到算法中,用以提高算法效率,并提高程序的安全性。
Python 包含以下常用随机数函数:
| 函数 | 描述 |
|---|---|
| choice(seq) | 从序列的元素中随机挑选一个元素,比如 random.choice(range(10)) ,从 0 到 9 中随机挑选一个整数 |
| [randrange (start,] stop [,step]) | 从指定范围内,按指定基数递增的集合中获取一个随机数,基数默认值为 1 |
| random() | 随机生成下一个实数,它在 [0,1) 范围内 |
| seed([x]) | 改变随机数生成器的种子 seed 。如果你不了解其原理,你不必特别去设定 seed ,Python 会帮你选择 seed |
| shuffle(lst) | 将序列的所有元素随机排序 |
| uniform(x, y) | 随机生成下一个实数,它在 [x,y] 范围内 |
三角函数
Python包括以下三角函数:
| 函数 | 描述 |
|---|---|
| acos(x) | 返回 x 的反余弦弧度值 |
| asin(x) | 返回 x 的反正弦弧度值。 |
| atan(x) | 返回 x 的反正切弧度值。 |
| atan2(y, x) | 返回给定的 X 及 Y 坐标值的反正切值。 |
| cos(x) | 返回 x 的弧度的余弦值。 |
| hypot(x, y) | 返回欧几里德范数 sqrt(x*x + y*y) |
| sin(x) | 返回的 x 弧度的正弦值。 |
| tan(x) | 返回 x 弧度的正切值。 |
| degrees(x) | 将弧度转换为角度,如 degrees(math.pi/2) , 返回 90.0 |
| radians(x) | 将角度转换为弧度 |
数学常量
| 常量 | 描述 |
|---|---|
pi |
数学常量 pi(圆周率,一般以 π 来表示) |
e |
数学常量 e,e 即自然常数(自然常数) |
字符串
字符串是 Python 中最常用的数据类型。我们可以使用引号( ' 或 " )来创建字符串。
创建字符串很简单,只要为变量分配一个值即可。例如:
var1 = 'Hello World!'
var2 = "Runoob"
Python 访问字符串中的值
Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。
Python 访问子字符串,可以使用方括号 [] 来截取字符串,字符串的截取的语法格式如下:
变量[头下标:尾下标]
索引值以 0 为开始值,-1 为从末尾的开始位置。
#!/usr/bin/python3
var1 = 'Hello World!'
var2 = "Runoob"
print("var1[0]: ", var1[0]) # H
print("var2[1:5]: ", var2[1:5]) # unoo
print("已更新字符串 : ", var1[:6] + 'Runoob!') # Hello Runoob!
转义字符
在需要在字符中使用特殊字符时,python 用反斜杠 \ 转义字符
| 转义字符 | 描述 | 实例 |
|---|---|---|
\ (在行尾时) |
续行符 | >>> print("line1 \ ... line2 \ ... line3") line1 line2 line3 >>> |
\\ |
反斜杠符号 | >>> print("\\") \ |
\' |
单引号 | >>> print('\'') ' |
\" |
双引号 | >>> print("\"") " |
\a |
响铃 | >>> print("\a")执行后电脑有响声。 |
\b |
退格(Backspace) | >>> print("Hello \b World!") Hello World! |
\000 |
空 | >>> print("\000") >>> |
\n |
换行 | >>> print("\n") >>> |
\v |
纵向制表符 | >>> print("Hello \v World!") Hello World! >>> |
\t |
横向制表符 | >>> print("Hello \t World!") Hello World! >>> |
\r |
回车,将 \r 后面的内容移到字符串开头,并逐一替换开头部分的字符,直至将 \r 后面的内容完全替换完成。 | >>> print("Hello\rWorld!") World! >>> print('google runoob taobao\r123456') 123456 runoob taobao |
\f |
换页 | >>> print("Hello \f World!") Hello World! >>> |
\yyy |
八进制数,y 代表 0~7 的字符,例如:\012 代表换行。 | >>> print("\110\145\154\154\157\40\127\157\162\154\144\41") Hello World! |
\xyy |
十六进制数,以 \x 开头,y 代表的字符,例如:\x0a 代表换行 | >>> print("\x48\x65\x6c\x6c\x6f\x20\x57\x6f\x72\x6c\x64\x21") Hello World! |
\other |
其它的字符以普通格式输出 |
#!/usr/bin/python3
print("line1 \
line2 \
line3") # line1 line2 line3
print("\\") # \
print('\'') # '
print("\"") # "
print("\a") # 执行后电脑有响声
print("Hello \b World!") # Hello World!
print("\000") #
print("\n")
print("Hello \v World!") # Hello
World!
print("Hello \t World!") # Hello World!
print("Hello\rWorld!") # World!
print('google runoob taobao\r123456') # 123456
print("Hello \f World!") # Hello
World!
print("\110\145\154\154\157\40\127\157\162\154\144\41") # Hello World!
print("\x48\x65\x6c\x6c\x6f\x20\x57\x6f\x72\x6c\x64\x21") # Hello World!
print("\cdef") # \cdef
字符串运算符
下表实例变量 a 值为字符串 "Hello",b 变量值为 "Python"
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | a + b 输出结果: HelloPython |
| * | 重复输出字符串 | a*2 输出结果:HelloHello |
| [] | 通过索引获取字符串中字符 | a[1] 输出结果 e |
| [ : ] | 截取字符串中的一部分,遵循左闭右开原则,str[0:2] 是不包含第 3 个字符的。 | a[1:4] 输出结果 ell |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | 'H' in a 输出结果 True |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | 'M' not in a 输出结果 True |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母 r(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | print( r'\n' ) print( R'\n' ) |
| % | 格式字符串 | 请看下一节内容。 |
字符串格式化
Python 支持格式化字符串的输出 。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
在 Python 中,字符串格式化使用与 C 中 sprintf 函数一样的语法
#!/usr/bin/python3
print("我叫 %s 今年 %d 岁!" % ('小明', 10)) # 我叫 小明 今年 10 岁!
python字符串格式化符号:
| 符 号 | 描述 |
|---|---|
%c |
格式化字符及其 ASCII 码 |
%s |
格式化字符串 |
%d |
格式化整数 |
%u |
格式化无符号整型 |
%o |
格式化无符号八进制数 |
%x |
格式化无符号十六进制数 |
%X |
格式化无符号十六进制数(大写) |
%f |
格式化浮点数字,可指定小数点后的精度 |
%e |
用科学计数法格式化浮点数 |
%E |
作用同 %e ,用科学计数法格式化浮点数 |
%g |
%f 和 %e 的简写 |
%G |
%f 和 %E 的简写 |
%p |
用十六进制数格式化变量的地址 |
格式化操作符辅助指令:
| 符号 | 功能 |
|---|---|
* |
定义宽度或者小数点精度 |
- |
用做左对齐 |
+ |
在正数前面显示加号( + ) |
<sp> |
在正数前面显示空格 |
# |
在八进制数前面显示零('0'),在十六进制前面显示'0x'或者'0X'(取决于用的是'x'还是'X') |
0 |
显示的数字前面填充 0 而不是默认的空格 |
% |
'%%'输出一个单一的'%' |
(var) |
映射变量(字典参数) |
m.n. |
m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
Python2.6 开始,新增了一种格式化字符串的函数 str.format() ,它增强了字符串格式化的功能
三引号
python 三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符
一个典型的用例是,当你需要一块 HTML 或者 SQL 时
#!/usr/bin/python3
para_str = """这是一个多行字符串的实例
多行字符串可以使用制表符
TAB ( \t )。
也可以使用换行符 [ \n ]。
"""
print (para_str)
f-string
f-string 是 python3.6 之后版本添加的,称之为字面量格式化字符串,是新的格式化字符串的语法。
之前我们习惯用百分号 %
f-string 格式化字符串以 f 开头,后面跟着字符串,字符串中的表达式用大括号 {} 包起来,它会将变量或表达式计算后的值替换进去,不用再去判断使用 %s 还是 %d
#!/usr/bin/python3
name = 'Runoob'
# 之前的做法
print('Hello %s' % name) # Hello Runoob
# 替换变量
print(f'Hello {name}') # Hello Runoob
# 使用表达式
print(f'{1 + 2}')
w = {'name': 'Runoob', 'url': 'www.runoob.com'}
print(f'{w["name"]}: {w["url"]}') # Runoob: www.runoob.com
在 Python 3.8 的版本中可以使用 = 符号来拼接运算表达式与结果:
x = 1
print(f'{x + 1}') # Python 3.6 2
x = 1
print(f'{x+1=}') # Python 3.8 x+1=2
Unicode 字符串
在 Python2 中,普通字符串是以 8 位 ASCII 码进行存储的,而 Unicode 字符串则存储为 16 位 unicode 字符串,这样能够表示更多的字符集。使用的语法是在字符串前面加上前缀 u
在 Python3 中,所有的字符串都是 Unicode 字符串。
Python 的字符串内建函数
Python 的字符串常用内建函数如下:
| 方法 | 描述 |
|---|---|
| capitalize() | 将字符串的第一个字符转换为大写 |
| center(width, fillchar) | 返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。 |
| count(str, beg= 0,end=len(string)) | 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| bytes.decode(encoding="utf-8", errors="strict") | Python3 中没有 decode 方法,但我们可以使用 bytes 对象的 decode() 方法来解码给定的 bytes 对象,这个 bytes 对象可以由 str.encode() 来编码返回。 |
| encode(encoding='UTF-8',errors='strict') | 以 encoding 指定的编码格式编码字符串,如果出错默认报一个 ValueError 的异常,除非 errors 指定的是 ignore 或者 replace |
| endswith(suffix, beg=0, end=len(string)) | 检查字符串是否以 obj 结束,如果 beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True ,否则返回 False |
| expandtabs(tabsize=8) | 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8 |
| find(str, beg=0, end=len(string)) | 检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回 -1 |
| index(str, beg=0, end=len(string)) | 跟 find() 方法一样,只不过如果 str 不在字符串中会报一个异常 |
| isalnum() | 如果字符串至少有一个字符并且所有字符都是字母或数字则返回 True ,否则返回 False |
| isalpha() | 如果字符串至少有一个字符并且所有字符都是字母或中文字则返回 True ,否则返回 False |
| isdigit() | 如果字符串只包含数字则返回 True 否则返回 False |
| islower() | 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| isnumeric() | 如果字符串中只包含数字字符,则返回 True,否则返回 False |
| isspace() | 如果字符串中只包含空白,则返回 True,否则返回 False |
| istitle() | 如果字符串是标题化的(见 title() )则返回 True,否则返回 False |
| isupper() | 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| join(seq) | 以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| len(string) | 返回字符串长度 |
| ljust(width[, fillchar]) | 返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格 |
| lower() | 转换字符串中所有大写字符为小写 |
| lstrip() | 截掉字符串左边的空格或指定字符 |
| maketrans() | 创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标 |
| max(str) | 返回字符串 str 中最大的字母 |
| min(str) | 返回字符串 str 中最小的字母 |
| replace(old, new [, max]) | 把 将字符串中的 old 替换成 new , 如果 max 指定,则替换不超过 max 次 |
| rfind(str, beg=0,end=len(string)) | 类似于 find() 函数,不过是从右边开始查找 |
| rindex( str, beg=0, end=len(string)) | 类似于 index() ,不过是从右边开始 |
| rjust(width,[, fillchar]) | 返回一个原字符串右对齐,并使用 fillchar (默认空格)填充至长度 width 的新字符串 |
| rstrip() | 删除字符串末尾的空格或指定字符 |
| split(str="", num=string.count(str)) | 以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num+1 个子字符串 |
| splitlines([keepends]) | 按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符 |
| startswith(substr, beg=0,end=len(string)) | 检查字符串是否是以指定子字符串 substr 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查 |
| strip([chars]) | 在字符串上执行 lstrip() 和 rstrip() |
| swapcase() | 将字符串中大写转换为小写,小写转换为大写 |
| title() | 返回"标题化"的字符串,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle() ) |
| translate(table, deletechars="") | 根据 table 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 deletechars 参数中 |
| upper() | 转换字符串中的小写字母为大写 |
| zfill (width) | 返回长度为 width 的字符串,原字符串右对齐,前面填充 0 |
| isdecimal() | 检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false |
列表
序列是 Python 中最基本的数据结构。
序列中的每个值都有对应的位置值,称之为索引,第一个索引是 0,第二个索引是 1,依此类推。
Python 有 6 个序列的内置类型,但最常见的是列表和元组。
列表都可以进行的操作包括索引,切片,加,乘,检查成员。
此外,Python 已经内置确定序列的长度以及确定最大和最小的元素的方法。
列表是最常用的 Python 数据类型,它可以作为一个方括号内的逗号分隔值出现。
列表的数据项不需要具有相同的类型
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示:
list1 = ['Google', 'Runoob', 1997, 2000]
list2 = [1, 2, 3, 4, 5 ]
list3 = ["a", "b", "c", "d"]
list4 = ['red', 'green', 'blue', 'yellow', 'white', 'black']
访问列表中的值
与字符串的索引一样,列表索引从 0 开始
索引也可以从尾部开始,最后一个元素的索引为 -1,往前一位为 -2
#!/usr/bin/python3
list = ['red', 'green', 'blue', 'yellow', 'white', 'black']
print(list[0]) # red
print(list[1]) # green
print(list[2]) # blue
print(list[-1]) # black
print(list[-2]) # white
print(list[-3]) # yellow
使用下标索引来访问列表中的值,同样你也可以使用方括号 [] 的形式截取字符
也可以使用负数索引值截取
#!/usr/bin/python3
nums = [10, 20, 30, 40, 50, 60, 70, 80, 90]
print(nums[0:4]) # [10, 20, 30, 40]
list = ['Google', 'Runoob', "Zhihu", "Taobao", "Wiki"]
# 读取第二位
print("list[1]: ", list[1]) # Runoob
# 从第二位开始(包含)截取到倒数第二位(不包含)
print("list[1:-2]: ", list[1:-2]) # ['Runoob', 'Zhihu']
更新列表
你可以对列表的数据项进行修改或更新,你也可以使用 append() 方法来添加列表项
#!/usr/bin/python3
list = ['Google', 'Runoob', 1997, 2000]
print("第三个元素为 : ", list[2]) # 1997
list[2] = 2001
print("更新后的第三个元素为 : ", list[2]) # 2001
list1 = ['Google', 'Runoob', 'Taobao']
list1.append('Baidu')
print("更新后的列表 : ", list1) # ['Google', 'Runoob', 'Taobao', 'Baidu']
删除列表元素
可以使用 del 语句来删除列表的的元素
#!/usr/bin/python3
list = ['Google', 'Runoob', 1997, 2000]
print("原始列表 : ", list) # ['Google', 'Runoob', 1997, 2000]
del list[2]
print("删除第三个元素 : ", list) # ['Google', 'Runoob', 2000]
列表脚本操作符
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | 长度 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
| ['Hi!'] * 4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] | 重复 |
| 3 in [1, 2, 3] | True | 元素是否存在于列表中 |
| for x in [1, 2, 3]: print(x, end=" ") | 1 2 3 | 迭代 |
列表截取与拼接
列表截取与字符串操作类似
L=['Google', 'Runoob', 'Taobao']
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| L[2] | 'Taobao' | 读取第三个元素 |
| L[-2] | 'Runoob' | 从右侧开始读取倒数第二个元素: count from the right |
| L[1:] | ['Runoob', 'Taobao'] | 输出从第二个元素开始后的所有元素 |
列表还支持拼接操作:
squares = [1, 4, 9, 16, 25]
squares += [36, 49, 64, 81, 100]
print(squares) # [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
嵌套列表
使用嵌套列表即在列表里创建其它列表
a = ['a', 'b', 'c']
n = [1, 2, 3]
x = [a, n]
print(x) # [['a', 'b', 'c'], [1, 2, 3]]
print(x[0]) # ['a', 'b', 'c']
print(x[0][1]) # b
列表函数&方法
| 方法 | 描述 |
|---|---|
| list.append(obj) | 在列表末尾添加新的对象 |
| list.count(obj) | 统计某个元素在列表中出现的次数 |
| list.extend(seq) | 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| list.index(obj) | 从列表中找出某个值第一个匹配项的索引位置 |
| list.insert(index, obj) | 将对象插入列表 |
| list.pop([index=-1]) | 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| list.remove(obj) | 移除列表中某个值的第一个匹配项 |
| list.reverse() | 反向列表中元素 |
| list.sort( key=None, reverse=False) | 对原列表进行排序 |
| list.clear() | 清空列表 |
| list.copy() | 复制列表 |
元组
Python 的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号 ( ) ,列表使用方括号 [ ]
tup1 = ('Google', 'Runoob', 1997, 2000)
tup2 = (1, 2, 3, 4, 5)
tup3 = "a", "b", "c", "d" # 不需要括号也可以
tup4 = () # 空元组
print(type(tup3)) # <class 'tuple'>
tup1 = (50)
print(type(tup1)) # 不加逗号,类型为整型 <class 'int'>
tup1 = (50,)
print(type(tup1)) # 加上逗号,类型为元组 <class 'tuple'>
元组与字符串类似,下标索引从 0 开始,可以进行截取,组合等。
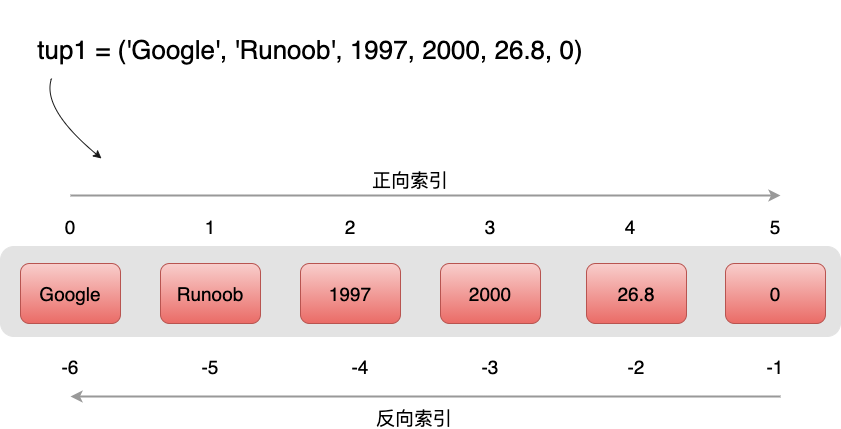
访问元组
元组可以使用下标索引来访问元组中的值
tup1 = ('Google', 'Runoob', 1997, 2000)
tup2 = (1, 2, 3, 4, 5, 6, 7)
print("tup1[0]: ", tup1[0]) # Google
print("tup2[1:5]: ", tup2[1:5]) # (2, 3, 4, 5)
修改元组
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合
tup1 = (12, 34.56)
tup2 = ('abc', 'xyz')
# 修改元组元素操作是非法的。
# tup1[0] = 100
# 创建一个新的元组
tup3 = tup1 + tup2
print(tup3) # (12, 34.56, 'abc', 'xyz')
删除元组
元组中的元素值是不允许删除的,但可以使用 del 语句来删除整个元组
tup = ('Google', 'Runoob', 1997, 2000)
print(tup) # ('Google', 'Runoob', 1997, 2000)
del tup
print("删除后的元组 tup : ")
print(tup) # NameError: name 'tup' is not defined
元组运算符
与字符串一样,元组之间可以使用 + 号和 * 号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。
| Python 表达式 | 结果 | 描述 |
|---|---|---|
len((1, 2, 3)) |
3 | 计算元素个数 |
(1, 2, 3) + (4, 5, 6) |
(1, 2, 3, 4, 5, 6) | 连接 |
('Hi!',) * 4 |
('Hi!', 'Hi!', 'Hi!', 'Hi!') | 复制 |
3 in (1, 2, 3) |
True | 元素是否存在 |
for x in (1, 2, 3): print (x, end=" ") |
1 2 3 | 迭代 |
元组索引,截取
因为元组也是一个序列,所以我们可以访问元组中的指定位置的元素,也可以截取索引中的一段元素
tup = ('Google', 'Runoob', 'Taobao', 'Wiki', 'Weibo', 'Weixin')
print(tup[1]) # Runoob
print(tup[-2]) # Weibo
print(tup[1:]) # ('Runoob', 'Taobao', 'Wiki', 'Weibo', 'Weixin')
print(tup[1:4]) # ('Runoob', 'Taobao', 'Wiki')
元组内置函数
Python 元组包含了以下内置函数
| 方法 | 描述 |
|---|---|
len(tuple) |
计算元组元素个数。 |
max(tuple) |
返回元组中元素最大值。 |
min(tuple) |
返回元组中元素最小值。 |
tuple(iterable) |
将可迭代系列转换为元组。 |
tuple1 = ('Google', 'Runoob', 'Taobao')
print(len(tuple1)) # 3
tuple2 = ('5', '4', '8')
print(max(tuple2)) # 8
print(min(tuple2)) # 4
list1 = ['Google', 'Taobao', 'Runoob', 'Baidu']
tuple3 = tuple(list1)
print(tuple3) # ('Google', 'Taobao', 'Runoob', 'Baidu')
关于元组是不可变的
所谓元组的不可变指的是元组所指向的内存中的内容不可变。
tup = ('r', 'u', 'n', 'o', 'o', 'b')
# tup[0] = 'g' # 不支持修改元素
# TypeError: 'tuple' object does not support item assignment
print(id(tup)) # 查看内存地址
tup = (1, 2, 3)
print(id(tup)) # 内存地址改变
从以上实例可以看出,重新赋值的元组 tup ,绑定到新的对象了,不是修改了原来的对象。
字典
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值 key=>value 对用冒号 : 分割,每个对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示:
d = {key1 : value1, key2 : value2, key3 : value3 }
注意:dict 作为 Python 的关键字和内置函数,变量名不建议命名为 dict
键必须是唯一的,但值则不必。
值可以取任何数据类型,但键必须是不可变的,如字符串,数字。
简单的字典实例:
tinydict = {'name': 'runoob', 'likes': 123, 'url': 'www.runoob.com'}
tinydict1 = {'abc': 456}
tinydict2 = {'abc': 123, 98.6: 37}
创建空字典
使用大括号 { } 创建空字典
# 使用大括号 {} 来创建空字典
emptyDict = {}
# emptyDict = dict() # 另一种方式
# 打印字典
print(emptyDict) # {}
# 查看字典的数量
print("Length:", len(emptyDict)) # 0
# 查看类型
print(type(emptyDict)) # <class 'dict'>
访问字典里的值
tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
print("tinydict['Name']: ", tinydict['Name']) # Runoob
print("tinydict['Age']: ", tinydict['Age']) # 7
print ("tinydict['Alice']: ", tinydict['Alice']) # 不存在的键会报错 KeyError: 'Alice'
修改字典
tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
tinydict['Age'] = 8 # 更新 Age
tinydict['School'] = "菜鸟教程" # 添加信息
print("tinydict['Age']: ", tinydict['Age']) # 8
print("tinydict['School']: ", tinydict['School']) # 菜鸟教程
删除字典元素
tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
del tinydict['Name'] # 删除键 'Name'
tinydict.clear() # 清空字典
del tinydict # 删除字典
print("tinydict['Age']: ", tinydict['Age']) # NameError: name 'tinydict' is not defined
print("tinydict['School']: ", tinydict['School'])
字典键的特性
字典值可以是任何的 python 对象,既可以是标准的对象,也可以是用户定义的,但键不行。
两个重要的点需要记住:
- 不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住
- 键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行
字典内置函数&方法
Python字典包含了以下内置函数:
| 函数 | 描述 |
|---|---|
len(dict) |
计算字典元素个数,即键的总数。 |
str(dict) |
输出字典,可以打印的字符串表示。 |
type(variable) |
返回输入的变量类型,如果变量是字典就返回字典类型。 |
tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
print(len(tinydict)) # 3
print(tinydict) # {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
print(str(tinydict)) # {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
print(type(tinydict)) # <class 'dict'>
Python 字典包含了以下内置方法:
| 函数 | 描述 |
|---|---|
| dict.clear() | 删除字典内所有元素 |
| dict.copy() | 返回一个字典的浅复制 |
| dict.fromkeys() | 创建一个新字典,以序列 seq 中元素做字典的键,val 为字典所有键对应的初始值 |
| dict.get(key, default=None) | 返回指定键的值,如果键不在字典中返回 default 设置的默认值 |
| key in dict | 如果键在字典 dict 里返回 true ,否则返回 false |
| dict.items() | 以列表返回一个视图对象 |
| dict.keys() | 返回一个视图对象 |
| dict.setdefault(key, default=None) | 和 get() 类似, 但如果键不存在于字典中,将会添加键并将值设为 default |
| dict.update(dict2) | 把字典 dict2 的键/值对更新到 dict 里 |
| dict.values() | 返回一个视图对象 |
| pop(key[,default]) | 删除字典给定键 key 所对应的值,返回值为被删除的值。key 值必须给出。 否则,返回 default 值。 |
| popitem() | 随机返回并删除字典中的最后一对键和值。 |
集合
集合(set)是一个无序的不重复元素序列。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { } ,因为 { } 是用来创建一个空字典。
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
print(basket) # 这里演示的是去重功能 {'apple', 'orange', 'banana', 'pear'}
print('orange' in basket) # 快速判断元素是否在集合内 True
print('crabgrass' in basket) # False
# 下面展示两个集合间的运算.
a = set('abracadabra')
b = set('alacazam')
print(a) # {'r', 'a', 'c', 'd', 'b'}
print(b) # {'z', 'a', 'l', 'c', 'm'}
print(a - b) # 集合a中包含而集合b中不包含的元素 {'b', 'r', 'd'}
print(a | b) # 集合a或b中包含的所有元素 {'r', 'm', 'z', 'a', 'c', 'l', 'd', 'b'}
print(a & b) # 集合a和b中都包含了的元素 {'a', 'c'}
print(a ^ b) # 不同时包含于a和b的元素 {'r', 'm', 'l', 'd', 'z', 'b'}
类似列表推导式,同样集合支持集合推导式 (Set comprehension) :
a = {x for x in 'abracadabra' if x not in 'abc'}
print(a) # {'r', 'd'}
集合的基本操作
添加元素
thisset = set(("Google", "Runoob", "Taobao"))
thisset.add("Facebook") # 添加元素,如果元素已存在,则不进行任何操作
print(thisset) # {'Facebook', 'Runoob', 'Taobao', 'Google'}
thisset.update({1, 3}) # 可以添加元素,且参数可以是列表,元组,字典等
print(thisset) # {'Facebook', 1, 3, 'Taobao', 'Google', 'Runoob'}
thisset.update([1, 4], [5, 6])
print(thisset) # {1, 3, 4, 5, 6, 'Facebook', 'Runoob', 'Taobao', 'Google'}
移除元素
thisset = set(("Google", "Runoob", "Taobao"))
thisset.remove("Taobao")
print(thisset)
# thisset.remove("Facebook") # 不存在会发生错误 KeyError: 'Facebook'
thisset.discard("Facebook") # 移除集合中的元素,且如果元素不存在,不会发生错误
x = thisset.pop() # 随机删除集合中的一个元素
print(x)
set 集合的 pop 方法会对集合进行无序的排列,然后将这个无序排列集合的左面第一个元素进行删除。
计算集合元素个数
thisset = set(("Google", "Runoob", "Taobao"))
print(len(thisset)) # 3
清空集合
s.clear()
判断元素是否在集合中存在
x in s
判断元素 x 是否在集合 s 中,存在返回 True ,不存在返回 False 。
集合内置方法完整列表
| 方法 | 描述 |
|---|---|
| add() | 为集合添加元素 |
| clear() | 移除集合中的所有元素 |
| copy() | 拷贝一个集合 |
| difference() | 返回多个集合的差集 |
| difference_update() | 移除集合中的元素,该元素在指定的集合也存在。 |
| discard() | 删除集合中指定的元素 |
| intersection() | 返回集合的交集 |
| intersection_update() | 返回集合的交集。 |
| isdisjoint() | 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。 |
| issubset() | 判断指定集合是否为该方法参数集合的子集。 |
| issuperset() | 判断该方法的参数集合是否为指定集合的子集 |
| pop() | 随机移除元素 |
| remove() | 移除指定元素 |
| symmetric_difference() | 返回两个集合中不重复的元素集合。 |
| symmetric_difference_update() | 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。 |
| union() | 返回两个集合的并集 |
| update() | 给集合添加元素 |
编程第一步
#!/usr/bin/python3
# Fibonacci series: 斐波纳契数列
# 两个元素的总和确定了下一个数
a, b = 0, 1
while b < 1000:
print(b, end=', ')
a, b = b, a + b
条件控制
if 语句
Python 中用 elif 代替了 else if ,所以 if 语句的关键字为:if – elif – else
注意:
- 每个条件后面要使用冒号
:,表示接下来是满足条件后要执行的语句块 - 使用缩进来划分语句块,相同缩进数的语句在一起组成一个语句块
- 在 Python 中没有
switch - case语句
简单的 if 实例:
#!/usr/bin/python3
var1 = 100
if var1: # true
print("1 - if 表达式条件为 true")
print(var1)
var2 = 0
if var2: # false
print("2 - if 表达式条件为 true")
print(var2)
print("Good bye!")
狗的年龄计算判断:
#!/usr/bin/python3
age = int(input("请输入你家狗狗的年龄: "))
print("")
if age <= 0:
print("你是在逗我吧!")
elif age == 1:
print("相当于 14 岁的人。")
elif age == 2:
print("相当于 22 岁的人。")
elif age > 2:
human = 22 + (age - 2) * 5
print("对应人类年龄: ", human)
### 退出提示
input("点击 enter 键退出")
数字的比较运算:
#!/usr/bin/python3
# 该实例演示了数字猜谜游戏
number = 7
guess = -1
print("数字猜谜游戏!")
while guess != number:
guess = int(input("请输入你猜的数字:"))
if guess == number:
print("恭喜,你猜对了!")
elif guess < number:
print("猜的数字小了...")
elif guess > number:
print("猜的数字大了...")
if 嵌套
# !/usr/bin/python3
num = int(input("输入一个数字:"))
if num % 2 == 0:
if num % 3 == 0:
print("你输入的数字可以整除 2 和 3")
else:
print("你输入的数字可以整除 2,但不能整除 3")
else:
if num % 3 == 0:
print("你输入的数字可以整除 3,但不能整除 2")
else:
print("你输入的数字不能整除 2 和 3")
循环语句
Python 中的循环语句有 for 和 while
while 循环
同样需要注意冒号和缩进。另外,在 Python 中没有 do..while 循环。
无限循环
#!/usr/bin/python3
var = 1
while var == 1: # 表达式永远为 true
num = int(input("输入一个数字 :"))
print("你输入的数字是: ", num)
print("Good bye!")
无限循环在服务器上客户端的实时请求非常有用。
简单语句组
类似 if 语句的语法,如果你的 while 循环体中只有一条语句,你可以将该语句与 while 写在同一行中
#!/usr/bin/python
flag = 1
while (flag): print('欢迎访问菜鸟教程!')
print("Good bye!")
for 语句
for 循环可以遍历任何可迭代对象,如一个列表或者一个字符串
break 语句用于跳出当前循环体
#!/usr/bin/python3
sites = ["Baidu", "Google", "Runoob", "Taobao"]
for site in sites:
if site == "Runoob":
print("菜鸟教程!")
break
print("循环数据 " + site)
else:
print("没有循环数据!")
print("完成循环!")
range() 函数
如果你需要遍历数字序列,可以使用内置 range() 函数。它会生成数列
# 指定上限,下限默认 0
for i in range(5): # [0,4]
print(i)
# 指定上下限
for i in range(5, 9): # [5,8]
print(i)
# 指定步长
for i in range(0, 10, 3): # {0,3,6,9}
print(i)
# 负数
for i in range(-10, -100, -30): # {-10,-40,-70}
print(i)
结合 range() 和 len() 函数以遍历一个序列的索引
a = ['Google', 'Baidu', 'Runoob', 'Taobao', 'QQ']
for i in range(len(a)):
print(i, a[i])
输出结果:
0 Google
1 Baidu
2 Runoob
3 Taobao
4 QQ
使用 range() 函数来创建一个列表
print(list(range(5))) # [0, 1, 2, 3, 4]
break 和 continue 语句及循环中的 else 子句
break 语句可以跳出 for 和 while 的循环体。如果你从 for 或 while 循环中终止,任何对应的循环 else 块将不执行。
continue 语句被用来告诉 Python 跳过当前循环块中的剩余语句,然后继续进行下一轮循环。
用于查询质数的循环例子:
#!/usr/bin/python3
for n in range(2, 10):
for x in range(2, n):
if n % x == 0:
print(n, '等于', x, '*', n // x)
break
else:
# 循环中没有找到元素
print(n, ' 是质数')
pass 语句
pass 是空语句,是为了保持程序结构的完整性。
pass 不做任何事情,一般用做占位语句
以下实例在字母为 o 时,执行 pass 语句块:
#!/usr/bin/python3
for letter in 'Runoob':
if letter == 'o':
pass
print('执行 pass 块')
print('当前字母 :', letter)
print("Good bye!")
输出结果为:
当前字母 : R
当前字母 : u
当前字母 : n
执行 pass 块
当前字母 : o
执行 pass 块
当前字母 : o
当前字母 : b
Good bye!
迭代器与生成器
迭代器
迭代是 Python 最强大的功能之一,是访问集合元素的一种方式。
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
迭代器有两个基本的方法:iter() 和 next()
字符串,列表或元组对象都可用于创建迭代器:
list = [1, 2, 3, 4]
it = iter(list) # 创建迭代器对象
print(next(it)) # 输出迭代器的下一个元素 1
print(next(it)) # 2
迭代器对象可以使用常规 for 语句进行遍历:
#!/usr/bin/python3
list = [1, 2, 3, 4]
it = iter(list) # 创建迭代器对象
for x in it:
print(x, end=", ")
也可以使用 next() 函数:
#!/usr/bin/python3
import sys # 引入 sys 模块
list = [1, 2, 3, 4]
it = iter(list) # 创建迭代器对象
while True:
try:
print(next(it))
except StopIteration:
sys.exit()
创建一个迭代器
把一个类作为一个迭代器使用需要在类中实现两个方法 __iter__() 与 __next__()
类都有一个构造函数,Python 的构造函数为 __init__() ,它会在对象初始化的时候执行。
__iter__() 方法返回一个特殊的迭代器对象, 这个迭代器对象实现了 __next__() 方法并通过 StopIteration 异常标识迭代的完成。
__next__() 方法(Python 2 里是 next() )会返回下一个迭代器对象。
创建一个返回数字的迭代器,初始值为 1,逐步递增 1:
class MyNumbers:
def __iter__(self):
self.a = 1
return self
def __next__(self):
x = self.a
self.a += 1
return x
myclass = MyNumbers()
myiter = iter(myclass)
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
输出结果为:
1
2
3
4
5
StopIteration
StopIteration 异常用于标识迭代的完成,防止出现无限循环的情况,在 __next__() 方法中我们可以设置在完成指定循环次数后触发 StopIteration 异常来结束迭代。
在 20 次迭代后停止执行:
class MyNumbers:
def __iter__(self):
self.a = 1
return self
def __next__(self):
if self.a <= 20:
x = self.a
self.a += 1
return x
else:
raise StopIteration
myclass = MyNumbers()
myiter = iter(myclass)
for x in myiter:
print(x)
生成器
在 Python 中,使用了 yield 的函数被称为生成器(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值,并在下一次执行 next() 方法时从当前位置继续运行。
调用一个生成器函数,返回的是一个迭代器对象。
#!/usr/bin/python3
import sys
def fibonacci(n): # 生成器函数 - 斐波那契
a, b, counter = 0, 1, 0
while True:
if (counter > n):
return
yield a
a, b = b, a + b
counter += 1
f = fibonacci(10) # f 是一个迭代器,由生成器返回生成
while True:
try:
print(next(f), end=" ")
except StopIteration:
sys.exit()
函数
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
Python 提供了许多内建函数,比如 print() 。但你也可以自己创建函数,这被叫做用户自定义函数。
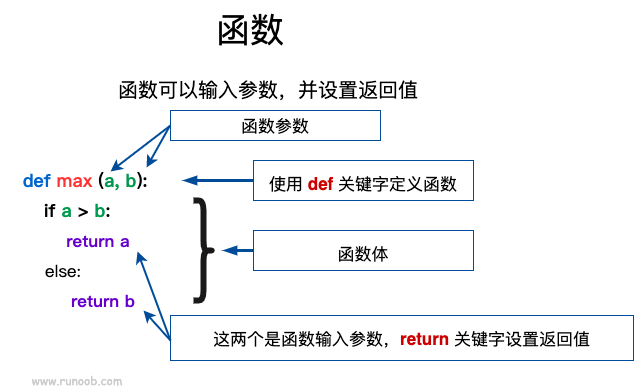
定义一个函数
定义一个函数,以下是简单的规则:
- 函数代码块以
def关键词开头,后接函数标识符名称和圆括号() - 任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数
- 函数的第一行语句可以选择性地使用文档字符串:用于存放函数说明
- 函数内容以冒号
:起始,并且缩进 return [表达式]结束函数,选择性地返回一个值给调用方,不带表达式的return相当于返回None
语法
Python 定义函数使用 def 关键字,一般格式如下:
def 函数名(参数列表):
函数体
默认情况下,参数值和参数名称是按函数声明中定义的顺序匹配起来的。
实例
使用函数来输出"Hello World!":
#!/usr/bin/python3
def hello():
print("Hello World!")
hello()
hello()
函数中带上参数变量:
#!/usr/bin/python3
def max(a, b):
if a > b:
return a
else:
return b
a = 4
b = 5
print(max(a, b))
函数调用
定义一个函数:给了函数一个名称,指定了函数里包含的参数,和代码块结构。
这个函数的基本结构完成以后,你可以通过另一个函数调用执行,也可以直接从 Python 命令提示符执行。
#!/usr/bin/python3
# 定义函数
def printme(str):
# 打印任何传入的字符串
print(str)
return
# 调用函数
printme("我要调用用户自定义函数!")
printme("再次调用同一函数")
参数传递
在 python 中,类型属于对象,对象有不同类型的区分,变量是没有类型的:
a=[1,2,3]
a="Runoob"
变量 a 是没有类型,它仅仅是一个对象的引用(一个指针),可以是指向 List 类型对象,也可以是指向 String 类型对象
可更改(mutable)与不可更改(immutable)对象
在 python 中,strings, tuples 和 numbers 是不可更改的对象,而 list, dict 等则是可以修改的对象。
- 不可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变 a 的值,相当于新生成了 a
- 可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了
python 函数的参数传递:
- 不可变类型:类似 C++ 的值传递,如整数、字符串、元组。如
fun(a),传递的只是 a 的值,没有影响 a 对象本身。如果在fun(a)内部修改 a 的值,则是新生成一个 a 的对象 - 可变类型:类似 C++ 的引用传递,如 列表,字典。如
fun(la),则是将 la 真正的传过去,修改后fun外部的 la 也会受影响
python 中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象。
传不可变对象实例
通过 id() 函数来查看内存地址变化:
def change(a):
print(1, id(a)) # 指向的是同一个对象
a = 10
print(2, id(a)) # 一个新对象
a = 1
print(0, id(a))
change(a)
print(3, id(a))
输出结果为:
0 2682404864240
1 2682404864240
2 2682404864528
3 2682404864240
传可变对象实例
#!/usr/bin/python3
# 可写函数说明
def changeme(mylist):
"修改传入的列表"
mylist.append([1, 2, 3, 4])
print("函数内取值: ", mylist)
return
# 调用changeme函数
mylist = [10, 20, 30]
changeme(mylist)
print("函数外取值: ", mylist)
输出结果如下:
函数内取值: [10, 20, 30, [1, 2, 3, 4]]
函数外取值: [10, 20, 30, [1, 2, 3, 4]]
参数
以下是调用函数时可使用的正式参数类型:
- 必需参数
- 关键字参数
- 默认参数
- 不定长参数
必需参数
必需参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
关键字参数
关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值。
使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
函数参数的使用不需要使用指定顺序:
#!/usr/bin/python3
# 可写函数说明
def printinfo(name, age):
"打印任何传入的字符串"
print("名字: ", name)
print("年龄: ", age)
return
# 调用printinfo函数
printinfo(age=50, name="runoob")
默认参数
调用函数时,如果没有传递参数,则会使用默认参数。
#!/usr/bin/python3
# 可写函数说明
def printinfo(name, age=35):
"打印任何传入的字符串"
print("名字: ", name)
print("年龄: ", age)
return
# 调用printinfo函数
printinfo(age=50, name="runoob")
print("------------------------")
printinfo(name="runoob")
输出结果:
名字: runoob
年龄: 50
------------------------
名字: runoob
年龄: 35
不定长参数
基本语法如下:
def functionname([formal_args,] *var_args_tuple ):
"函数_文档字符串"
function_suite
return [expression]
加了星号 * 的参数会以元组(tuple) 的形式导入,存放所有未命名的变量参数。
#!/usr/bin/python3
# 可写函数说明
def printinfo(arg1, *vartuple):
"打印任何传入的参数"
print("输出: ")
print(arg1)
print(vartuple)
# 调用 printinfo 函数
printinfo(70, 60, 50)
输出结果:
输出:
70
(60, 50)
如果在函数调用时没有指定参数,它就是一个空元组。
我们也可以不向函数传递未命名的变量。
#!/usr/bin/python3
# 可写函数说明
def printinfo(arg1, *vartuple):
"打印任何传入的参数"
print("输出: ")
print(arg1)
print(vartuple)
for var in vartuple:
print(var)
return
# 调用printinfo 函数
printinfo(10)
输出结果:
输出:
10
()
还有一种就是参数带两个星号 ** 基本语法如下:
def functionname([formal_args,] **var_args_dict ):
"函数_文档字符串"
function_suite
return [expression]
加了两个星号 ** 的参数会以字典的形式导入。
#!/usr/bin/python3
# 可写函数说明
def printinfo(arg1, **vardict):
"打印任何传入的参数"
print("输出: ")
print(arg1)
print(vardict)
# 调用printinfo 函数
printinfo(1, a=2, b=3)
输出结果:
输出:
1
{'a': 2, 'b': 3}
声明函数时,参数中星号 * 可以单独出现,例如:
def f(a,b,*,c):
return a+b+c
如果单独出现星号 * 后的参数必须用关键字传入。
def f(a, b, *, c):
return a + b + c
# f(1, 2, 3) # TypeError: f() takes 2 positional arguments but 3 were given
f(1, 2, c=3) # 正常
匿名函数
Python 使用 lambda 来创建匿名函数。
所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数。
lambda只是一个表达式,函数体比def简单很多lambda的主体是一个表达式,而不是一个代码块。仅仅能在 lambda 表达式中封装有限的逻辑进去- lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数
- 虽然 lambda 函数看起来只能写一行,却不等同于 C 或 C++ 的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率
语法
lambda 函数的语法只包含一个语句,如下:
lambda [arg1 [,arg2,.....argn]]:expression
设置参数 a 加上 10 :
x = lambda a: a + 10
print(x(5)) # 15
以下实例匿名函数设置两个参数:
#!/usr/bin/python3
# 可写函数说明
sum = lambda arg1, arg2: arg1 + arg2
# 调用sum函数
print("相加后的值为 : ", sum(10, 20)) # 30
print("相加后的值为 : ", sum(20, 20)) # 40
我们可以将匿名函数封装在一个函数内,这样可以使用同样的代码来创建多个匿名函数。
以下实例将匿名函数封装在 myfunc 函数中,通过传入不同的参数来创建不同的匿名函数:
def myfunc(n):
return lambda a: a * n
mydoubler = myfunc(2)
mytripler = myfunc(3)
print(mydoubler(11)) # 22
print(mytripler(11)) # 33
return 语句
return [表达式] 语句用于退出函数,选择性地向调用方返回一个表达式。不带参数值的 return 语句返回 None
强制位置参数
Python3.8 新增了一个函数形参语法 / 用来指明函数形参必须使用指定位置参数,不能使用关键字参数的形式。
在以下的例子中,形参 a 和 b 必须使用指定位置参数,c 或 d 可以是位置形参或关键字形参,而 e 和 f 要求为关键字形参:
def f(a, b, /, c, d, *, e, f):
print(a, b, c, d, e, f)
以下使用方法是正确的:
f(10, 20, 30, d=40, e=50, f=60)
以下使用方法会发生错误:
f(10, b=20, c=30, d=40, e=50, f=60) # b 不能使用关键字参数的形式
f(10, 20, 30, 40, 50, f=60) # e 必须使用关键字参数的形式
数据结构
列表
Python 中列表是可变的,这是它区别于字符串和元组的最重要的特点,一句话概括即:列表可以修改,而字符串和元组不能。
| 方法 | 描述 |
|---|---|
list.append(x) |
把一个元素添加到列表的结尾,相当于 a[len(a):] = [x] |
list.extend(L) |
通过添加指定列表的所有元素来扩充列表,相当于 a[len(a):] = L |
list.insert(i, x) |
在指定位置插入一个元素。第一个参数是准备插入到其前面的那个元素的索引,例如 a.insert(0, x) 会插入到整个列表之前,而 a.insert(len(a), x) 相当于 a.append(x) |
list.remove(x) |
删除列表中值为 x 的第一个元素。如果没有这样的元素,就会返回一个错误 |
list.pop([i]) |
从列表的指定位置移除元素,并将其返回。如果没有指定索引,a.pop() 返回最后一个元素。元素随即从列表中被移除。(方法中 i 两边的方括号表示这个参数是可选的,而不是要求你输入一对方括号) |
list.clear() |
移除列表中的所有项,等于del a[:] |
list.index(x) |
返回列表中第一个值为 x 的元素的索引。如果没有匹配的元素就会返回一个错误 |
list.count(x) |
返回 x 在列表中出现的次数 |
list.sort() |
对列表中的元素进行排序 |
list.reverse() |
倒排列表中的元素 |
list.copy() |
返回列表的浅复制,等于 a[:] |
a = [66.25, 333, 333, 1, 1234.5]
print(0, a) # [66.25, 333, 333, 1, 1234.5]
print(1, a.count(333), a.count(66.25), a.count("x")) # 2 1 0
a.insert(2, -1)
a.append(333)
# a[len(a):] = [444]
print(2, a) # [66.25, 333, -1, 333, 1, 1234.5, 333]
print(3, a.index(333)) # 1
a.remove(333)
print(4, a) # [66.25, -1, 333, 1, 1234.5, 333]
a.reverse()
print(5, a) # [333, 1234.5, 1, 333, -1, 66.25]
a.sort()
print(6, a) # [-1, 1, 66.25, 333, 333, 1234.5]
注意:类似 insert , remove 或 sort 等修改列表的方法没有返回值。
将列表当做堆栈使用
列表方法使得列表可以很方便的作为一个堆栈来使用,堆栈作为特定的数据结构,最先进入的元素最后一个被释放(后进先出)。用 append() 方法可以把一个元素添加到堆栈顶。用不指定索引的 pop() 方法可以把一个元素从堆栈顶释放出来。
stack = [3, 4, 5]
print(stack.append(6)) # None
stack.append(7)
print(stack) # [3, 4, 5, 6, 7]
print(stack.pop()) # 7
print(stack) # [3, 4, 5, 6]
print(stack.pop()) # 6
print(stack.pop()) # 5
print(stack) # [3, 4]
将列表当作队列使用
也可以把列表当做队列用,只是在队列里第一加入的元素,第一个取出来;但是拿列表用作这样的目的效率不高。在列表的最后添加或者弹出元素速度快,然而在列表里插入或者从头部弹出速度却不快(因为所有其他的元素都得一个一个地移动)。
from collections import deque
queue = deque(["Eric", "John", "Michael"])
queue.append("Terry")
queue.append("Graham")
print(queue.popleft()) # Eric
print(queue.popleft()) # John
print(queue) # deque(['Michael', 'Terry', 'Graham'])
列表推导式
列表推导式提供了从序列创建列表的简单途径。通常应用程序将一些操作应用于某个序列的每个元素,用其获得的结果作为生成新列表的元素,或者根据确定的判定条件创建子序列。
每个列表推导式都在 for 之后跟一个表达式,然后有零到多个 for 或 if 子句。返回结果是一个根据表达从其后的 for 和 if 上下文环境中生成出来的列表。如果希望表达式推导出一个元组,就必须使用括号。
这里我们将列表中每个数值乘三,获得一个新的列表:
vec = [2, 4, 6]
l = [3 * x for x in vec]
print(l) # [6, 12, 18]
print([[x, x ** 2] for x in vec]) # [[2, 4], [4, 16], [6, 36]]
对序列里每一个元素逐个调用某方法:
freshfruit = [' banana', ' loganberry ', 'passion fruit ']
print([weapon.strip() for weapon in freshfruit]) # ['banana', 'loganberry', 'passion fruit']
用 if 子句作为过滤器:
vec = [2, 4, 6]
print([3 * x for x in vec if x > 3]) # [12, 18]
print([3 * x for x in vec if x < 2]) # []
一些关于循环和其它技巧的演示:
vec1 = [2, 4, 6]
vec2 = [4, 3, -9]
print([x * y for x in vec1 for y in vec2]) # [8, 6, -18, 16, 12, -36, 24, 18, -54]
print([x + y for x in vec1 for y in vec2]) # [6, 5, -7, 8, 7, -5, 10, 9, -3]
print([vec1[i] * vec2[i] for i in range(len(vec1))]) # [8, 12, -54]
列表推导式可以使用复杂表达式或嵌套函数:
print([str(round(355 / 113, i)) for i in range(1, 6)]) # ['3.1', '3.14', '3.142', '3.1416', '3.14159']
嵌套列表解析
Python的列表还可以嵌套。
# 3*4 的矩阵列表
matrix = [
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
]
# 转换成 4*3 的列表
print([[row[i] for row in matrix] for i in range(4)]) # [[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
# 另一种实现
transposed = []
for i in range(4):
transposed.append([row[i] for row in matrix])
print(transposed) # [[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
# 另一种实现
transposed = []
for i in range(4):
# the following 3 lines implement the nested listcomp
transposed_row = []
for row in matrix:
transposed_row.append(row[i])
transposed.append(transposed_row)
print(transposed) # [[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
del 语句
使用 del 语句可以从一个列表中根据索引来删除一个元素,而不是值来删除元素。这与使用 pop() 返回一个值不同。可以用 del 语句从列表中删除一个切割,或清空整个列表。
a = [-1, 1, 66.25, 333, 333, 1234.5]
del a[0]
print(a) # [1, 66.25, 333, 333, 1234.5]
del a[2:4]
print(a) # [1, 66.25, 1234.5]
del a[:]
print(a) # []
也可以用 del 删除实体变量:
del a
元组和序列
元组由若干逗号分隔的值组成
t = 12345, 54321, 'hello!'
print(t[0]) # 12345
print(t) # (12345, 54321, 'hello!')
# Tuples may be nested:
u = t, (1, 2, 3, 4, 5)
print(u) # ((12345, 54321, 'hello!'), (1, 2, 3, 4, 5))
元组在输出时总是有括号的,以便于正确表达嵌套结构。在输入时可能有或没有括号, 不过括号通常是必须的(如果元组是更大的表达式的一部分)。
集合
集合是一个无序不重复元素的集。基本功能包括关系测试和消除重复元素。
可以用大括号 {} 创建集合。注意:如果要创建一个空集合,你必须用 set() 而不是 {} ;后者创建一个空的字典
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
print(basket) # 删除重复的
# {'apple', 'banana', 'pear', 'orange'}
print('orange' in basket) # 检测成员
# True
print('crabgrass' in basket)
# False
# 以下演示了两个集合的操作
a = set('abracadabra')
b = set('alacazam')
print(a) # a 中唯一的字母
# {'a', 'd', 'c', 'r', 'b'}
print(a - b) # 在 a 中的字母,但不在 b 中
# {'d', 'r', 'b'}
print(a | b) # 在 a 或 b 中的字母
# {'a', 'l', 'z', 'd', 'c', 'm', 'r', 'b'}
print(a & b) # 在 a 和 b 中都有的字母
# {'a', 'c'}
print(a ^ b) # 在 a 或 b 中的字母,但不同时在 a 和 b 中
# {'l', 'z', 'm', 'b', 'r', 'd'}
集合也支持推导式:
a = {x for x in 'abracadabra' if x not in 'abc'}
print(a) # {'r', 'd'}
字典
序列是以连续的整数为索引,与此不同的是,字典以关键字为索引,关键字可以是任意不可变类型,通常用字符串或数值。
理解字典的最佳方式是把它看做无序的键=>值对集合。在同一个字典之内,关键字必须是互不相同。
一对大括号创建一个空的字典:{}
tel = {'jack': 4098, 'sape': 4139}
tel['guido'] = 4127
print(tel) # {'jack': 4098, 'sape': 4139, 'guido': 4127}
print(tel['jack']) # 4098
del tel['sape']
tel['irv'] = 4127
print(tel) # {'jack': 4098, 'guido': 4127, 'irv': 4127}
print(list(tel.keys())) # ['jack', 'guido', 'irv']
print(sorted(tel.keys())) # ['guido', 'irv', 'jack']
print('guido' in tel) # True
print('jack' not in tel) # False
构造函数 dict() 直接从键值对元组列表中构建字典。如果有固定的模式,列表推导式指定特定的键值对:
dict([('sape', 4139), ('guido', 4127), ('jack', 4098)])
字典推导可以用来创建任意键和值的表达式词典:
m = {x: x ** 2 for x in (2, 4, 6)}
print(m) # {2: 4, 4: 16, 6: 36}
如果关键字只是简单的字符串,使用关键字参数指定键值对有时候更方便:
d = dict(sape=4139, guido=4127, jack=4098)
print(d)
遍历技巧
在字典中遍历时,关键字和对应的值可以使用 items() 方法同时解读出来:
knights = {'gallahad': 'the pure', 'robin': 'the brave'}
for k, v in knights.items():
print(k, v)
"""
gallahad the pure
robin the brave
"""
在序列中遍历时,索引位置和对应值可以使用 enumerate() 函数同时得到:
for i, v in enumerate(['tic', 'tac', 'toe']):
print(i, v)
"""
0 tic
1 tac
2 toe
"""
同时遍历两个或更多的序列,可以使用 zip() 组合:
questions = ['name', 'quest', 'favorite color']
answers = ['lancelot', 'the holy grail', 'blue']
for q, a in zip(questions, answers):
print('{0} :: {1}'.format(q, a))
"""
name :: lancelot
quest :: the holy grail
favorite color :: blue
"""
要反向遍历一个序列,首先指定这个序列,然后调用 reversed() 函数:
for i in reversed(range(1, 10, 2)):
print(i, end=", ")
# 9, 7, 5, 3, 1,
要按顺序遍历一个序列,使用 sorted() 函数返回一个已排序的序列,并不修改原值:
basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
for f in sorted(set(basket)):
print(f)
"""
apple
banana
orange
pear
"""
模块
模块是一个包含所有你定义的函数和变量的文件,其后缀名是 .py 。模块可以被别的程序引入,以使用该模块中的函数等功能。这也是使用 python 标准库的方法。
使用 python 标准库中模块的例子:
#!/usr/bin/python3
# 文件名: using_sys.py
import sys
print('命令行参数如下:')
for i in sys.argv:
print(i)
print('\n\nPython 路径为:', sys.path, '\n')
执行结果如下所示:
$ python using_sys.py 参数1 参数2
命令行参数如下:
using_sys.py
参数1
参数2
Python 路径为: ['/root', '/usr/lib/python3.4', '/usr/lib/python3.4/plat-x86_64-linux-gnu', '/usr/lib/python3.4/lib-dynload', '/usr/local/lib/python3.4/dist-packages', '/usr/lib/python3/dist-packages']
import sys引入 python 标准库中的sys.py模块;这是引入某一模块的方法sys.argv是一个包含命令行参数的列表sys.path包含了一个 Python 解释器自动查找所需模块的路径的列表
import 语句
想使用 Python 源文件,只需在另一个源文件里执行 import 语句,语法如下:
import module1[, module2[,... moduleN]
当解释器遇到 import 语句,如果模块在当前的搜索路径就会被导入。
搜索路径是一个解释器会先进行搜索的所有目录的列表。如想要导入模块 support ,需要把命令放在脚本的顶端:
support.py 文件代码
#!/usr/bin/python3
# Filename: support.py
def print_func(par):
print("Hello : ", par)
return
test.py 引入 support 模块:
#!/usr/bin/python3
# Filename: test.py
# 导入模块
import support
# 现在可以调用模块里包含的函数了
support.print_func("Runoob") # Hello : Runoob
一个模块只会被导入一次,不管你执行了多少次 import 。这样可以防止导入模块被一遍又一遍地执行。
当我们使用 import 语句的时候,Python 解释器是怎样找到对应的文件的呢?
这就涉及到 Python 的搜索路径,搜索路径是由一系列目录名组成的,Python 解释器就依次从这些目录中去寻找所引入的模块。
这看起来很像环境变量,事实上,也可以通过定义环境变量的方式来确定搜索路径。
搜索路径是在 Python 编译或安装的时候确定的,安装新的库应该也会修改。搜索路径被存储在 sys 模块中的 path 变量
import sys
print(sys.path)
sys.path 输出是一个列表,其中第一项可能是空串 '' ,代表当前目录,亦即我们执行 python 解释器的目录(对于脚本的话就是运行的脚本所在的目录)。
因此若在当前目录下存在与要引入模块同名的文件,就会把要引入的模块屏蔽掉。
了解了搜索路径的概念,就可以在脚本中修改 sys.path 来引入一些不在搜索路径中的模块。
在解释器的当前目录或者 sys.path 中的一个目录里面来创建一个 fibo.py 的文件,代码如下:
# 斐波那契(fibonacci)数列模块
def fib(n): # 定义到 n 的斐波那契数列
a, b = 0, 1
while b < n:
print(b, end=' ')
a, b = b, a + b
print()
def fib2(n): # 返回到 n 的斐波那契数列
result = []
a, b = 0, 1
while b < n:
result.append(b)
a, b = b, a + b
return result
在其他地方导入:
import fibo
这样做并没有把直接定义在 fibo 中的函数名称写入到当前符号表里,只是把模块 fibo 的名字写到了那里。
可以使用模块名称来访问函数:
import fibo
fibo.fib(1000)
fibo.fib2(1000)
from … import 语句
from 语句让你从模块中导入一个指定的部分到当前命名空间中,语法如下:
from modname import name1[, name2[, ... nameN]]
要导入模块 fibo 的 fib 函数,使用如下语句:
from fibo import fib, fib2
fib(1000)
fib2(1000)
from … import * 语句
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:
from modname import *
深入模块
模块除了方法定义,还可以包括可执行的代码。这些代码一般用来初始化这个模块。这些代码只有在第一次被导入时才会被执行。
每个模块有各自独立的符号表,在模块内部为所有的函数当作全局符号表来使用。
所以,模块的作者可以放心大胆的在模块内部使用这些全局变量,而不用担心把其他用户的全局变量搞混。
从另一个方面,当你确实知道你在做什么的话,你也可以通过 modname.itemname 这样的表示法来访问模块内的函数
模块是可以导入其他模块的。在一个模块(或者脚本,或者其他地方)的最前面使用 import 来导入一个模块,当然这只是一个惯例,而不是强制的。被导入的模块的名称将被放入当前操作的模块的符号表中。
还有一种导入的方法,可以使用 import 直接把模块内(函数,变量的)名称导入到当前操作模块。
from fibo import fib, fib2
fib(1000)
fib2(1000)
这种导入的方法不会把被导入的模块的名称放在当前的字符表中(所以在这个例子里面,fibo 这个名称是没有定义的)。
这还有一种方法,可以一次性的把模块中的所有(函数,变量)名称都导入到当前模块的字符表:
from fibo import *
fib(500)
这将把所有的名字都导入进来,但是那些由单一下划线 _ 开头的名字不在此例。大多数情况, Python 程序员不使用这种方法,因为引入的其它来源的命名,很可能覆盖了已有的定义。
__name__ 属性
一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用 __name__ 属性来使该程序块仅在该模块自身运行时执行。
#!/usr/bin/python3
# Filename: using_name.py
if __name__ == '__main__':
print('程序自身在运行')
else:
print('我来自另一模块', __name__)
$ python using_name.py
程序自身在运行
$ python
>>> import using_name
我来自另一模块
>>>
说明: 每个模块都有一个 __name__ 属性,当其值是 __main__ 时,表明该模块自身在运行,否则是被引入。
说明: __name__ 与 __main__ 底下是双下划线
dir() 函数
内置的函数 dir() 可以找到模块内定义的所有名称。以一个字符串列表的形式返回
import fibo
import sys
d = dir(fibo)
print(d)
d = dir(sys)
print(d)
如果没有给定参数,那么 dir() 函数会罗列出当前定义的所有名称:
a = [1, 2, 3, 4, 5]
import fibo
fib = fibo.fib
print(dir()) # 得到一个当前模块中定义的属性列表
a = 5 # 建立一个新的变量 'a'
print(dir())
del a # 删除变量名a
print(dir())
标准模块
Python 本身带着一些标准的模块库
有些模块直接被构建在解析器里,这些虽然不是一些语言内置的功能,但是他却能很高效的使用,甚至是系统级调用也没问题。
这些组件会根据不同的操作系统进行不同形式的配置,比如 winreg 这个模块就只会提供给 Windows 系统。
应该注意到这有一个特别的模块 sys ,它内置在每一个 Python 解析器中。变量 sys.ps1 和 sys.ps2 定义了主提示符和副提示符所对应的字符串:
>>> import sys
>>> sys.ps1
'>>> '
>>> sys.ps2
'... '
>>> sys.ps1 = 'C> '
C> print('Runoob!')
Runoob!
C>
包
包是一种管理 Python 模块命名空间的形式,采用"点模块名称"。
比如一个模块的名称是 A.B , 那么他表示一个包 A 中的子模块 B 。
针对不同的音频文件格式(基本上都是通过后缀名区分的,例如: .wav ,.aiff ,.au ),并且针对这些音频数据,还有很多不同的操作(比如混音,添加回声,增加均衡器功能,创建人造立体声效果),这里给出了一种可能的包结构(在分层的文件系统中):
sound/ 顶层包
__init__.py 初始化 sound 包
formats/ 文件格式转换子包
__init__.py
wavread.py
wavwrite.py
aiffread.py
aiffwrite.py
auread.py
auwrite.py
...
effects/ 声音效果子包
__init__.py
echo.py
surround.py
reverse.py
...
filters/ filters 子包
__init__.py
equalizer.py
vocoder.py
karaoke.py
...
在导入一个包的时候,Python 会根据 sys.path 中的目录来寻找这个包中包含的子目录。
目录只有包含一个叫做 __init__.py 的文件才会被认作是一个包
最简单的情况,放一个空的 __init__.py 就可以了。当然这个文件中也可以包含一些初始化代码或者为 __all__ 变量赋值。
用户可以每次只导入一个包里面的特定模块,比如:
import sound.effects.echo
这将会导入子模块: sound.effects.echo 。 他必须使用全名去访问:
sound.effects.echo.echofilter(input, output, delay=0.7, atten=4)
还有一种导入子模块的方法是:
from sound.effects import echo
这同样会导入子模块: echo ,并且他不需要那些冗长的前缀,所以他可以这样使用:
echo.echofilter(input, output, delay=0.7, atten=4)
还有一种变化就是直接导入一个函数或者变量:
from sound.effects.echo import echofilter
同样的,这种方法会导入子模块: echo ,并且可以直接使用他的 echofilter() 函数:
echofilter(input, output, delay=0.7, atten=4)
注意当使用 from package import item 这种形式的时候,对应的 item 既可以是包里面的子模块(子包),或者包里面定义的其他名称,比如函数,类或者变量。
import 语法会首先把 item 当作一个包定义的名称,如果没找到,再试图按照一个模块去导入。如果还没找到,抛出一个 :exc:ImportError 异常。
反之,如果使用形如 import item.subitem.subsubitem 这种导入形式,除了最后一项,都必须是包,而最后一项则可以是模块或者是包,但是不可以是类,函数或者变量的名字。
从一个包中导入 *
如果我们使用 from sound.effects import * 会发生什么呢?
Python 会进入文件系统,找到这个包里面所有的子模块,然后一个一个的把它们都导入进来。
但这个方法在 Windows 平台上工作的就不是非常好,因为 Windows 是一个不区分大小写的系统。
在 Windows 平台上,我们无法确定一个叫做 ECHO.py 的文件导入为模块是 echo 还是 Echo ,或者是 ECHO 。
为了解决这个问题,我们只需要提供一个精确包的索引。
导入语句遵循如下规则:如果包定义文件 __init__.py 存在一个叫做 __all__ 的列表变量,那么在使用 from package import * 的时候就把这个列表中的所有名字作为包内容导入。
作为包的作者,可别忘了在更新包之后保证 __all__ 也更新了啊。
在 sounds/effects/__init__.py 中包含如下代码:
__all__ = ["echo", "surround", "reverse"]
这表示当你使用 from sound.effects import * 这种用法时,你只会导入包里面这三个子模块。
如果 __all__ 真的没有定义,那么使用 from sound.effects import * 这种语法的时候,就不会导入包 sound.effects 里的任何子模块。他只是把包 sound.effects 和它里面定义的所有内容导入进来(可能运行__init__.py里定义的初始化代码)。
通常我们并不主张使用 * 这种方法来导入模块,因为这种方法经常会导致代码的可读性降低。不过这样倒的确是可以省去不少敲键的功夫,而且一些模块都设计成了只能通过特定的方法导入。
记住,使用 from Package import specific_submodule 这种方法永远不会有错。事实上,这也是推荐的方法。除非是你要导入的子模块有可能和其他包的子模块重名。
如果在结构中包是一个子包(比如这个例子中对于包 sound 来说),而你又想导入兄弟包(同级别的包)你就得使用导入绝对的路径来导入。比如,如果模块 sound.filters.vocoder 要使用包 sound.effects 中的模块 echo ,你就要写成 from sound.effects import echo
from . import echo
from .. import formats
from ..filters import equalizer
无论是隐式的还是显式的相对导入都是从当前模块开始的。主模块的名字永远是 __main__ ,一个 Python 应用程序的主模块,应当总是使用绝对路径引用。
包还提供一个额外的属性 __path__ 。这是一个目录列表,里面每一个包含的目录都有为这个包服务的 __init__.py ,你得在其他 __init__.py 被执行前定义。可以修改这个变量,用来影响包含在包里面的模块和子包。
这个功能并不常用,一般用来扩展包里面的模块。
输入和输出
输出格式美化
Python 两种输出值的方式: 表达式语句和 print() 函数。
第三种方式是使用文件对象的 write() 方法,标准输出文件可以用 sys.stdout 引用。
如果你希望输出的形式更加多样,可以使用 str.format() 函数来格式化输出值。
如果你希望将输出的值转成字符串,可以使用 repr() 或 str() 函数来实现。
str(): 函数返回一个用户易读的表达形式repr(): 产生一个解释器易读的表达形式
s = 'Hello, Runoob'
print(str(s)) # Hello, Runoob
print(repr(s)) # 'Hello, Runoob'
print(str(1 / 7)) # 0.14285714285714285
x = 10 * 3.25
y = 200 * 200
s = 'x 的值为: ' + repr(x) + ', y 的值为:' + repr(y) + '...'
print(s) # x 的值为: 32.5, y 的值为:40000...
# repr() 函数可以转义字符串中的特殊字符
hello = 'hello, runoob\n'
hellos = repr(hello)
print(hellos) # 'hello, runoob\n'
# repr() 的参数可以是 Python 的任何对象
print(repr((x, y, ('Google', 'Runoob')))) # (32.5, 40000, ('Google', 'Runoob'))
两种方式输出一个平方与立方的表
for x in range(1, 11):
print(repr(x).rjust(2), repr(x * x).rjust(3), end=' ')
# 注意前一行 'end' 的使用
print(repr(x * x * x).rjust(4))
print("==============================")
for x in range(1, 11):
print('{0:2d} {1:3d} {2:4d}'.format(x, x * x, x * x * x))
字符串对象的 rjust() 方法, 它可以将字符串靠右, 并在左边填充空格。
还有类似的方法, 如 ljust() 和 center() 。 这些方法并不会写任何东西, 它们仅仅返回新的字符串。
另一个方法 zfill() , 它会在数字的左边填充 0 ,如下所示:
z = '12'.zfill(5)
print(z) # 00012
z = '-3.14'.zfill(7)
print(z) # -003.14
z = '3.14159265359'.zfill(5)
print(z) # 3.14159265359
str.format() 的基本使用如下:
print('{}网址: "{}!"'.format('菜鸟教程', 'www.runoob.com')) # 菜鸟教程网址: "www.runoob.com!"
在括号中的数字用于指向传入对象在 format() 中的位置,如下所示:
print('{0} 和 {1}'.format('Google', 'Runoob')) # Google 和 Runoob
print('{1} 和 {0}'.format('Google', 'Runoob')) # Runoob 和 Google
如果在 format() 中使用了关键字参数, 那么它们的值会指向使用该名字的参数。
print('{name}网址: {site}'.format(name='菜鸟教程', site='www.runoob.com'))
菜鸟教程网址: www.runoob.com
位置及关键字参数可以任意的结合:
>>> print('站点列表 {0}, {1}, 和 {other}。'.format('Google', 'Runoob', other='Taobao'))
站点列表 Google, Runoob, 和 Taobao。
!a (使用 ascii() ), !s (使用 str() ) 和 !r (使用 repr() ) 可以用于在格式化某个值之前对其进行转化
可选项 : 和格式标识符可以跟着字段名。 这就允许对值进行更好的格式化
在 : 后传入一个整数,可以保证该域至少有这么多的宽度。 用于美化表格时很有用。
如果你有一个很长的格式化字符串,而你不想将它们分开, 那么在格式化时通过变量名而非位置会是很好的事情。
最简单的就是传入一个字典, 然后使用方括号 [] 来访问键值
也可以通过在 table 变量前使用 ** 来实现相同的功能:
import math
print('常量 PI 的值近似为: {}。'.format(math.pi)) # 常量 PI 的值近似为: 3.141592653589793。
# !r 使用 repr()
print('常量 PI 的值近似为: {!r}。'.format(math.pi)) # 常量 PI 的值近似为: 3.141592653589793。
# 可选项 : 和格式标识符可以跟着字段名
print('常量 PI 的值近似为 {0:.3f}。'.format(math.pi)) # 常量 PI 的值近似为 3.142。
# 在 : 后传入一个整数, 可以保证该域至少有这么多的宽度
table = {'Google': 1, 'Runoob': 2, 'Taobao': 3}
for name, number in table.items():
print('{0:10} ==> {1:10d}'.format(name, number))
"""
Google ==> 1
Runoob ==> 2
Taobao ==> 3
"""
# 传入一个字典, 然后使用方括号 [] 来访问键值
table = {'Google': 1, 'Runoob': 2, 'Taobao': 3}
print('Runoob: {0[Runoob]:d}; Google: {0[Google]:d}; Taobao: {0[Taobao]:d}'.format(table)) # Runoob: 2; Google: 1; Taobao: 3
# 也可以通过在 table 变量前使用 ** 来实现相同的功能
table = {'Google': 1, 'Runoob': 2, 'Taobao': 3}
print('Runoob: {Runoob:d}; Google: {Google:d}; Taobao: {Taobao:d}'.format(**table)) # Runoob: 2; Google: 1; Taobao: 3
旧式字符串格式化
% 操作符也可以实现字符串格式化。 它将左边的参数作为类似 sprintf() 式的格式化字符串,而将右边的代入,然后返回格式化后的字符串
import math
print('常量 PI 的值近似为:%5.3f。' % math.pi) # 常量 PI 的值近似为:3.142。
因为 str.format() 是比较新的函数, 大多数的 Python 代码仍然使用 % 操作符。但是因为这种旧式的格式化最终会从该语言中移除, 应该更多的使用 str.format()
读取键盘输入
Python 提供了 input() 内置函数 从标准输入读入一行文本,默认的标准输入是键盘。
#!/usr/bin/python3
str = input("请输入:")
print("你输入的内容是: ", str)
读和写文件
open() 将会返回一个 file 对象,基本语法格式如下:
open(filename, mode)
filename:包含了你要访问的文件名称的字符串值mode:决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读r
不同模式打开文件的完全列表:
| 模式 | 描述 |
|---|---|
r |
以只读方式打开文件。文件的指针将会放在文件的开头。这是 默认模式 。 |
rb |
以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。 |
r+ |
打开一个文件用于读写。文件指针将会放在文件的开头。 |
rb+ |
以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
w |
打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
wb |
以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
w+ |
打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
wb+ |
以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
a |
打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
ab |
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
a+ |
打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
ab+ |
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |

| 模式 | r | r+ | w | w+ | a | a+ |
|---|---|---|---|---|---|---|
| 读 | + | + | + | + | ||
| 写 | + | + | + | + | + | |
| 创建 | + | + | + | + | ||
| 覆盖 | + | + | ||||
| 指针在开始 | + | + | + | + | ||
| 指针在结尾 | + | + |
以下实例将字符串写入到文件 foo.txt 中:
#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo.txt", "w")
f.write("Python 是一个非常好的语言。\n是的,的确非常好!!\n")
# 关闭打开的文件
f.close()
文件对象的方法
假设已经创建了一个称为 f 的文件对象
| 方法 | 描述 |
|---|---|
f.read() |
为了读取一个文件的内容,调用 f.read(size) , 这将读取一定数目的数据, 然后作为字符串或字节对象返回。size 是一个可选的数字类型的参数。 当 size 被忽略了或者为负, 那么该文件的所有内容都将被读取并且返回。 |
f.readline() |
f.readline() 会从文件中读取单独的一行。换行符为 \n 。f.readline() 如果返回一个空字符串, 说明已经已经读取到最后一行。 |
f.readlines() |
f.readlines() 将返回该文件中包含的所有行。如果设置可选参数 sizehint , 则读取指定长度的字节, 并且将这些字节按行分割。 |
f.write() |
f.write(string) 将 string 写入到文件中, 然后返回写入的字符数。 |
f.tell() |
f.tell() 返回文件对象当前所处的位置, 它是从文件开头开始算起的字节数。 |
f.seek() |
如果要改变文件当前的位置, 可以使用 f.seek(offset, from_what) 函数。from_what 的值, 如果是 0 表示开头, 如果是 1 表示当前位置, 2 表示文件的结尾,例如:seek(x,0) : 从起始位置即文件首行首字符开始移动 x 个字符 seek(x,1) : 表示从当前位置往后移动 x 个字符 seek(-x,2) :表示从文件的结尾往前移动 x 个字符 from_what 值为默认为 0 ,即文件开头 |
f.close() |
在文本文件中 (那些打开文件的模式下没有 b 的), 只会相对于文件起始位置进行定位。当你处理完一个文件后, 调用 f.close() 来关闭文件并释放系统的资源,如果尝试再调用该文件,则会抛出异常。 |
当处理一个文件对象时, 使用 with 关键字是非常好的方式。在结束后, 它会帮你正确的关闭文件。
文件对象还有其他方法, 如 isatty() 和 trucate() , 但这些通常比较少用。
pickle 模块
python 的 pickle 模块实现了基本的数据序列和反序列化。
基本接口:
pickle.dump(obj, file, [,protocol])
有了 pickle 这个对象,就能对 file 以读取的形式打开:
x = pickle.load(file)
注解: 从 file 中读取一个字符串,并将它重构为原来的 python 对象。
file: 类文件对象,有 read() 和 readline() 接口。
#!/usr/bin/python3
import pickle
# 使用pickle模块将数据对象保存到文件
import pprint
data1 = {'a': [1, 2.0, 3, 4 + 6j], 'b': ('string', u'Unicode string'), 'c': None}
selfref_list = [1, 2, 3]
selfref_list.append(selfref_list)
output = open('data.pkl', 'wb')
# Pickle dictionary using protocol 0.
pickle.dump(data1, output)
# Pickle the list using the highest protocol available.
pickle.dump(selfref_list, output, -1)
output.close()
########################################
# 使用pickle模块从文件中重构python对象
pkl_file = open('data.pkl', 'rb')
data1 = pickle.load(pkl_file)
pprint.pprint(data1) # {'a': [1, 2.0, 3, (4+6j)], 'b': ('string', 'Unicode string'), 'c': None}
data2 = pickle.load(pkl_file)
pprint.pprint(data2) # [1, 2, 3, <Recursion on list with id=2928862444352>]
pkl_file.close()
File(文件) 方法
open() 方法
open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
注意:使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
open(file, mode='r')
完整的语法格式为:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
file: 必需,文件路径(相对或者绝对路径)mode: 可选,文件打开模式buffering: 设置缓冲encoding: 一般使用 utf8errors: 报错级别newline: 区分换行符closefd: 传入的 file 参数类型opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符
file 对象
file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数:
| 方法 | 描述 |
|---|---|
| file.close() | 关闭文件。关闭后文件不能再进行读写操作。 |
| file.flush() | 刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| file.fileno() | 返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| file.isatty() | 如果文件连接到一个终端设备返回 True,否则返回 False。 |
| file.next() | Python 3 中的 File 对象不支持 next() 方法。返回文件下一行。 |
| file.read([size]) | 从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| file.readline([size]) | 读取整行,包括 \n 字符。 |
| file.readlines([sizeint]) | 读取所有行并返回列表,若给定 sizeint>0 ,返回总和大约为 sizeint 字节的行,实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。 |
| file.seek(offset[, whence]) | 移动文件读取指针到指定位置 |
| file.tell() | 返回文件当前位置。 |
| file.truncate([size]) | 从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后后面的所有字符被删除,其中 Windows 系统下的换行代表2个字符大小。 |
| file.write(str) | 将字符串写入文件,返回的是写入的字符长度。 |
| file.writelines(sequence) | 向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
OS 文件/目录方法
os 模块提供了非常丰富的方法用来处理文件和目录。常用的方法如下表所示:
| 方法 | 描述 |
|---|---|
| os.access(path, mode) | 检验权限模式 |
| os.chdir(path) | 改变当前工作目录 |
| os.chflags(path, flags) | 设置路径的标记为数字标记。 |
| os.chmod(path, mode) | 更改权限 |
| os.chown(path, uid, gid) | 更改文件所有者 |
| os.chroot(path) | 改变当前进程的根目录 |
| os.close(fd) | 关闭文件描述符 fd |
| os.closerange(fd_low, fd_high) | 关闭所有文件描述符,从 fd_low (包含) 到 fd_high (不包含), 错误会忽略 |
| os.dup(fd) | 复制文件描述符 fd |
| os.dup2(fd, fd2) | 将一个文件描述符 fd 复制到另一个 fd2 |
| os.fchdir(fd) | 通过文件描述符改变当前工作目录 |
| os.fchmod(fd, mode) | 改变一个文件的访问权限,该文件由参数 fd 指定,参数 mode 是 Unix 下的文件访问权限。 |
| os.fchown(fd, uid, gid) | 修改一个文件的所有权,这个函数修改一个文件的用户 ID 和用户组 ID ,该文件由文件描述符 fd 指定。 |
| os.fdatasync(fd) | 强制将文件写入磁盘,该文件由文件描述符 fd 指定,但是不强制更新文件的状态信息。 |
| [os.fdopen(fd, mode[, bufsize]]) | 通过文件描述符 fd 创建一个文件对象,并返回这个文件对象 |
| os.fpathconf(fd, name) | 返回一个打开的文件的系统配置信息。name 为检索的系统配置的值,它也许是一个定义系统值的字符串,这些名字在很多标准中指定(POSIX.1, Unix 95, Unix 98, 和其它)。 |
| os.fstat(fd) | 返回文件描述符 fd 的状态,像 stat() 。 |
| os.fstatvfs(fd) | 返回包含文件描述符 fd 的文件的文件系统的信息,Python 3.3 相等于 statvfs() 。 |
| os.fsync(fd) | 强制将文件描述符为 fd 的文件写入硬盘。 |
| os.ftruncate(fd, length) | 裁剪文件描述符 fd 对应的文件, 所以它最大不能超过文件大小。 |
| os.getcwd() | 返回当前工作目录 |
| os.getcwdb() | 返回一个当前工作目录的 Unicode 对象 |
| os.isatty(fd) | 如果文件描述符 fd 是打开的,同时与 tty(-like) 设备相连,则返回 true , 否则 False 。 |
| os.lchflags(path, flags) | 设置路径的标记为数字标记,类似 chflags() ,但是没有软链接 |
| os.lchmod(path, mode) | 修改连接文件权限 |
| os.lchown(path, uid, gid) | 更改文件所有者,类似 chown ,但是不追踪链接。 |
| os.link(src, dst) | 创建硬链接,名为参数 dst ,指向参数 src |
| os.listdir(path) | 返回path指定的文件夹包含的文件或文件夹的名字的列表。 |
| os.lseek(fd, pos, how) | 设置文件描述符 fd 当前位置为 pos , how 方式修改: SEEK_SET 或者 0 设置从文件开始的计算的 pos ; SEEK_CUR 或者 1 则从当前位置计算; os.SEEK_END 或者 2 则从文件尾部开始。在 Unix ,Windows 中有效 |
| os.lstat(path) | 像 stat() , 但是没有软链接 |
| os.major(device) | 从原始的设备号中提取设备 major 号码 (使用 stat 中的 st_dev 或者 st_rdev field )。 |
| os.makedev(major, minor) | 以 major 和 minor 设备号组成一个原始设备号 |
| os.makedirs(path[, mode]) | 递归文件夹创建函数。像 mkdir() , 但创建的所有 intermediate-level 文件夹需要包含子文件夹。 |
| os.minor(device) | 从原始的设备号中提取设备 minor 号码 (使用 stat 中的 st_dev 或者 st_rdev field )。 |
| os.mkdir(path[, mode]) | 以数字 mode 的 mode 创建一个名为 path 的文件夹.默认的 mode 是 0777 (八进制)。 |
| os.mkfifo(path[, mode]) | 创建命名管道,mode 为数字,默认为 0666 (八进制) |
| os.mknod(filename[, mode=0600, device]) | 创建一个名为 filename 文件系统节点(文件,设备特别文件或者命名pipe)。 |
| os.open(file, flags[, mode]) | 打开一个文件,并且设置需要的打开选项, mode 参数是可选的 |
| os.openpty() | 打开一个新的伪终端对。返回 pty 和 tty 的文件描述符。 |
| os.pathconf(path, name) | 返回相关文件的系统配置信息。 |
| os.pipe() | 创建一个管道。返回一对文件描述符 (r, w) 分别为读和写 |
| [os.popen(command, mode[, bufsize]]) | 从一个 command 打开一个管道 |
| os.read(fd, n) | 从文件描述符 fd 中读取最多 n 个字节,返回包含读取字节的字符串,文件描述符 fd 对应文件已达到结尾, 返回一个空字符串。 |
| os.readlink(path) | 返回软链接所指向的文件 |
| os.remove(path) | 删除路径为 path 的文件。如果 path 是一个文件夹,将抛出 OSError ; 查看下面的 rmdir() 删除一个 directory。 |
| os.removedirs(path) | 递归删除目录。 |
| os.rename(src, dst) | 重命名文件或目录,从 src 到 dst |
| os.renames(old, new) | 递归地对目录进行更名,也可以对文件进行更名。 |
| os.rmdir(path) | 删除path指定的空目录,如果目录非空,则抛出一个 OSError 异常。 |
| os.stat(path) | 获取path指定的路径的信息,功能等同于 C API 中的 stat() 系统调用。 |
| os.stat_float_times([newvalue]) | 决定 stat_result 是否以 float 对象显示时间戳 |
| os.statvfs(path) | 获取指定路径的文件系统统计信息 |
| os.symlink(src, dst) | 创建一个软链接 |
| os.tcgetpgrp(fd) | 返回与终端 fd(一个由 os.open() 返回的打开的文件描述符)关联的进程组 |
| os.tcsetpgrp(fd, pg) | 设置与终端 fd(一个由 os.open() 返回的打开的文件描述符)关联的进程组为 pg 。 |
| os.ttyname(fd) | 返回一个字符串,它表示与文件描述符 fd 关联的终端设备。如果 fd 没有与终端设备关联,则引发一个异常。 |
| os.unlink(path) | 删除文件路径 |
| os.utime(path, times) | 返回指定的 path 文件的访问和修改的时间。 |
os.walk(top[, topdown=True[, onerror=None[, followlinks=False\]]]) |
输出在文件夹中的文件名通过在树中游走,向上或者向下。 |
| os.write(fd, str) | 写入字符串到文件描述符 fd 中。返回实际写入的字符串长度 |
| os.path 模块 | 获取文件的属性信息。 |
| os.pardir() | 获取当前目录的父目录,以字符串形式显示目录名。 |
错误和异常
Python 有两种错误很容易辨认:语法错误和异常。
Python assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常。

语法错误
Python 的语法错误或者称之为解析错
异常
即便 Python 程序的语法是正确的,在运行它的时候,也有可能发生错误。运行期检测到的错误被称为异常。
大多数的异常都不会被程序处理
10 * (1 / 0) # 0 不能作为除数,触发异常
# ZeroDivisionError: division by zero
4 + spam * 3 # spam 未定义,触发异常
# NameError: name 'spam' is not defined
'2' + 2 # int 不能与 str 相加,触发异常
# TypeError: can only concatenate str (not "int") to str
异常以不同的类型出现,这些类型都作为信息的一部分打印出来: 例子中的类型有 ZeroDivisionError ,NameError 和 TypeError 。
错误信息的前面部分显示了异常发生的上下文,并以调用栈的形式显示具体信息。
异常处理
try/except
异常捕捉可以使用 try/except 语句
以下例子中,让用户输入一个合法的整数,但是允许用户中断这个程序(使用 Control-C 或者操作系统提供的方法)。用户中断的信息会引发一个 KeyboardInterrupt 异常。
while True:
try:
x = int(input("请输入一个数字: "))
break
except ValueError:
print("您输入的不是数字,请再次尝试输入!")
try 语句按照如下方式工作;
- 首先,执行 try 子句(在关键字 try 和关键字 except 之间的语句)。
- 如果没有异常发生,忽略 except 子句,try 子句执行后结束。
- 如果在执行 try 子句的过程中发生了异常,那么 try 子句余下的部分将被忽略。如果异常的类型和 except 之后的名称相符,那么对应的 except 子句将被执行。
- 如果一个异常没有与任何的 except 匹配,那么这个异常将会传递给上层的 try 中。
一个 try 语句可能包含多个 except 子句,分别来处理不同的特定的异常。最多只有一个分支会被执行。
处理程序将只针对对应的 try 子句中的异常进行处理,而不是其他的 try 的处理程序中的异常。
一个 except 子句可以同时处理多个异常,这些异常将被放在一个括号里成为一个元组
except (RuntimeError, TypeError, NameError):
pass
最后一个 except 子句可以忽略异常的名称,它将被当作通配符使用。你可以使用这种方法打印一个错误信息,然后再次把异常抛出。
import sys
try:
f = open('myfile.txt')
s = f.readline()
i = int(s.strip())
except OSError as err:
print("OS error: {0}".format(err))
except ValueError:
print("Could not convert data to an integer.")
except:
print("Unexpected error:", sys.exc_info()[0])
raise
try/except...else
try/except 语句还有一个可选的 else 子句,如果使用这个子句,那么必须放在所有的 except 子句之后。
else 子句将在 try 子句没有发生任何异常的时候执行。

以下实例在 try 语句中判断文件是否可以打开,如果打开文件时正常的没有发生异常则执行 else 部分的语句,读取文件内容:
for arg in sys.argv[1:]:
try:
f = open(arg, 'r')
except IOError:
print('cannot open', arg)
else:
print(arg, 'has', len(f.readlines()), 'lines')
f.close()
使用 else 子句比把所有的语句都放在 try 子句里面要好,这样可以避免一些意想不到,而 except 又无法捕获的异常。
异常处理并不仅仅处理那些直接发生在 try 子句中的异常,而且还能处理子句中调用的函数(甚至间接调用的函数)里抛出的异常。
>>> def this_fails():
x = 1/0
>>> try:
this_fails()
except ZeroDivisionError as err:
print('Handling run-time error:', err)
Handling run-time error: int division or modulo by zero
try-finally 语句
try-finally 语句无论是否发生异常都将执行最后的代码。

抛出异常
Python 使用 raise 语句抛出一个指定的异常。
raise语法格式如下:
raise [Exception [, args [, traceback]]]
以下实例如果 x 大于 5 就触发异常:
x = 10
if x > 5:
raise Exception('x 不能大于 5。x 的值为: {}'.format(x))
raise 唯一的一个参数指定了要被抛出的异常。它必须是一个异常的实例或者是异常的类(也就是 Exception 的子类)。
如果你只想知道这是否抛出了一个异常,并不想去处理它,那么一个简单的 raise 语句就可以再次把它抛出。
try:
raise NameError('HiThere')
except NameError:
print('An exception flew by!')
raise
用户自定义异常
你可以通过创建一个新的异常类来拥有自己的异常。异常类继承自 Exception 类,可以直接继承,或者间接继承
class MyError(Exception):
def __init__(self, value):
self.value = value
def __str__(self):
return repr(self.value)
try:
raise MyError(2 * 2)
except MyError as e:
print('My exception occurred, value:', e.value)
raise MyError('oops!')
当创建一个模块有可能抛出多种不同的异常时,一种通常的做法是为这个包建立一个基础异常类,然后基于这个基础类为不同的错误情况创建不同的子类:
class Error(Exception):
"""Base class for exceptions in this module."""
pass
class InputError(Error):
"""Exception raised for errors in the input.
Attributes:
expression -- input expression in which the error occurred
message -- explanation of the error
"""
def __init__(self, expression, message):
self.expression = expression
self.message = message
class TransitionError(Error):
"""Raised when an operation attempts a state transition that's not
allowed.
Attributes:
previous -- state at beginning of transition
next -- attempted new state
message -- explanation of why the specific transition is not allowed
"""
def __init__(self, previous, next, message):
self.previous = previous
self.next = next
self.message = message
大多数的异常的名字都以 Error 结尾,就跟标准的异常命名一样。
定义清理行为
如果一个异常在 try 子句里(或者在 except 和 else 子句里)被抛出,而又没有任何的 except 把它截住,那么这个异常会在 finally 子句执行后被抛出。
预定义的清理行为
一些对象定义了标准的清理行为,无论系统是否成功的使用了它,一旦不需要它了,那么这个标准的清理行为就会执行。
关键词 with 语句就可以保证诸如文件之类的对象在使用完之后一定会正确的执行他的清理方法:
with open("myfile.txt") as f:
for line in f:
print(line, end="")
以上这段代码执行完毕后,就算在处理过程中出问题了,文件 f 总是会关闭。
面向对象
面向对象技术简介
- 类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
- 方法:类中定义的函数。
- 类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
- 数据成员:类变量或者实例变量用于处理类及其实例对象的相关的数据。
- 方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
- 局部变量:定义在方法中的变量,只作用于当前实例的类。
- 实例变量:在类的声明中,属性是用变量来表示的,这种变量就称为实例变量,实例变量就是一个用 self 修饰的变量。
- 继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个 Dog 类型的对象派生自 Animal 类,这是模拟"是一个(is-a)"关系(例图,Dog是一个Animal)。
- 实例化:创建一个类的实例,类的具体对象。
- 对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
和其它编程语言相比,Python 在尽可能不增加新的语法和语义的情况下加入了类机制。
Python 中的类提供了面向对象编程的所有基本功能:类的继承机制允许多个基类,派生类可以覆盖基类中的任何方法,方法中可以调用基类中的同名方法。
对象可以包含任意数量和类型的数据。
类定义
语法格式如下:
class ClassName:
<statement-1>
.
.
.
<statement-N>
类实例化后,可以使用其属性,实际上,创建一个类之后,可以通过类名访问其属性。
类对象
类对象支持两种操作:属性引用和实例化。
属性引用使用和 Python 中所有的属性引用一样的标准语法:obj.name
类对象创建后,类命名空间中所有的命名都是有效属性名。
#!/usr/bin/python3
class MyClass:
"""一个简单的类实例"""
i = 12345
def f(self):
return 'hello world'
# 实例化类
x = MyClass()
# 访问类的属性和方法
print("MyClass 类的属性 i 为:", x.i) # 12345
print("MyClass 类的方法 f 输出为:", x.f()) # hello world
类有一个名为 __init__() 的特殊方法(构造方法),该方法在类实例化时会自动调用
def __init__(self):
self.data = []
__init__() 方法可以有参数,参数通过 __init__() 传递到类的实例化操作上
#!/usr/bin/python3
class Complex:
def __init__(self, realpart, imagpart):
self.r = realpart
self.i = imagpart
x = Complex(3.0, -4.5)
print(x.r, x.i) # 输出结果:3.0 -4.5
self 代表类的实例,而非类
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的 第一个参数名称 , 按照惯例它的名称是 self
class Test:
def prt(self):
print(self)
print(self.__class__)
t = Test()
t.prt()
执行结果为:
<__main__.Test object at 0x000001991DD32BC0>
<class '__main__.Test'>
从执行结果可以很明显的看出,self 代表的是类的实例,代表当前对象的地址,而 self.__class__ 则指向类。
self 不是 python 关键字,我们把他换成 runoob 也是可以正常执行的:
类的方法
在类的内部,使用 def 关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数 self , 且为第一个参数,self 代表的是类的实例。
#!/usr/bin/python3
# 类定义
class people:
# 定义基本属性
name = ''
age = 0
# 定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
# 定义构造方法
def __init__(self, n, a, w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁,重 %d kg" % (self.name, self.age, self.__weight))
# 实例化类
p = people('runoob', 10, 30)
p.speak() # runoob 说: 我 10 岁,我重 30 kg
继承
派生类的定义如下所示:
class DerivedClassName(BaseClassName):
<statement-1>
.
.
.
<statement-N>
子类(派生类 DerivedClassName )会继承父类(基类 BaseClassName )的属性和方法。
BaseClassName(实例中的基类名)必须与派生类定义在一个作用域内。除了类,还可以用表达式,基类定义在另一个模块中时这一点非常有用:
class DerivedClassName(modname.BaseClassName):
实例:
#!/usr/bin/python3
# 类定义
class people:
# 定义基本属性
name = ''
age = 0
# 定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
# 定义构造方法
def __init__(self, n, a, w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" % (self.name, self.age))
# 单继承示例
class student(people):
grade = ''
def __init__(self, n, a, w, g):
# 调用父类的构函
people.__init__(self, n, a, w)
self.grade = g
# 覆写父类的方法
def speak(self):
print("%s 说: 我 %d 岁了,我在读 %d 年级" % (self.name, self.age, self.grade))
s = student('ken', 10, 60, 3)
s.speak() # ken 说: 我 10 岁了,我在读 3 年级
多继承
Python 同样有限的支持多继承形式。多继承的类定义形如下例:
class DerivedClassName(Base1, Base2, Base3):
<statement-1>
.
.
.
<statement-N>
需要注意圆括号中父类的顺序,若是父类中有相同的方法名,而在子类使用时未指定,python 从左至右 搜索 ,即方法在子类中未找到时,从左到右查找父类中是否包含方法。
#!/usr/bin/python3
# 类定义
class people:
# 定义基本属性
name = ''
age = 0
# 定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
# 定义构造方法
def __init__(self, n, a, w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" % (self.name, self.age))
# 单继承示例
class student(people):
grade = ''
def __init__(self, n, a, w, g):
# 调用父类的构函
people.__init__(self, n, a, w)
self.grade = g
# 覆写父类的方法
def speak(self):
print("%s 说: 我 %d 岁了,我在读 %d 年级" % (self.name, self.age, self.grade))
# 另一个类,多重继承之前的准备
class speaker():
topic = ''
name = ''
def __init__(self, n, t):
self.name = n
self.topic = t
def speak(self):
print("我叫 %s,我是一个演说家,我演讲的主题是 %s" % (self.name, self.topic))
# 多重继承
class sample(speaker, student):
a = ''
def __init__(self, n, a, w, g, t):
student.__init__(self, n, a, w, g)
speaker.__init__(self, n, t)
test = sample("Tim", 25, 80, 4, "Python")
test.speak() # 方法名同,默认调用的是在括号中参数位置排前父类的方法
方法重写
#!/usr/bin/python3
class Parent: # 定义父类
def myMethod(self):
print('调用父类方法')
class Child(Parent): # 定义子类
def myMethod(self):
print('调用子类方法')
c = Child() # 子类实例
c.myMethod() # 子类调用重写方法
super(Child, c).myMethod() # 用子类对象调用父类已被覆盖的方法
super() 函数 是用于调用父类(超类)的一个方法。
类属性与方法
类的私有属性
__private_attrs :两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs
类的方法
在类的内部,使用 def 关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数 self,且为第一个参数,self 代表的是类的实例。
self 的名字并不是规定死的,也可以使用 this,但是最好还是按照约定使用 self
类的私有方法
__private_method:两个下划线开头,声明该方法为私有方法,只能在类的内部调用 ,不能在类的外部调用。self.__private_methods
类的专有方法:
__init__: 构造函数,在生成对象时调用__del__: 析构函数,释放对象时使用__repr__: 打印,转换__setitem__: 按照索引赋值__getitem__: 按照索引获取值__len__: 获得长度__cmp__: 比较运算__call__: 函数调用__add__: 加运算__sub__: 减运算__mul__: 乘运算__truediv__: 除运算__mod__: 求余运算__pow__: 乘方
运算符重载
Python 同样支持运算符重载,我们可以对类的专有方法进行重载
#!/usr/bin/python3
class Vector:
def __init__(self, a, b):
self.a = a
self.b = b
def __str__(self):
return 'Vector (%d, %d)' % (self.a, self.b)
def __add__(self, other):
return Vector(self.a + other.a, self.b + other.b)
v1 = Vector(2, 10)
v2 = Vector(5, -2)
print(v1 + v2) # 这里 + 重载
命名空间和作用域
命名空间
命名空间(Namespace) 是从名称到对象的映射,大部分的命名空间都是通过 Python 字典来实现的。
命名空间提供了在项目中避免名字冲突的一种方法。各个命名空间是独立的,没有任何关系的,所以一个命名空间中不能有重名,但不同的命名空间是可以重名而没有任何影响。
一般有三种命名空间:
- 内置名称(built-in names), Python 语言内置的名称,比如函数名 abs、char 和异常名称 BaseException、Exception 等等。
- 全局名称(global names),模块中定义的名称,记录了模块的变量,包括函数、类、其它导入的模块、模块级的变量和常量。
- 局部名称(local names),函数中定义的名称,记录了函数的变量,包括函数的参数和局部定义的变量。(类中定义的也是)
命名空间查找顺序:
假设我们要使用变量 runoob ,则 Python 的查找顺序为:局部的命名空间 -> 全局命名空间 -> 内置命名空间
如果找不到变量 runoob ,它将放弃查找并引发一个 NameError 异常
命名空间的生命周期:
命名空间的生命周期取决于对象的作用域,如果对象执行完成,则该命名空间的生命周期就结束。
因此,我们无法从外部命名空间访问内部命名空间的对象。
# var1 是全局名称
var1 = 5
def some_func():
# var2 是局部名称
var2 = 6
def some_inner_func():
# var3 是内嵌的局部名称
var3 = 7
作用域
作用域就是一个 Python 程序可以直接访问命名空间的正文区域。
在一个 python 程序中,直接访问一个变量,会从内到外依次访问所有的作用域直到找到,否则会报未定义的错误。
Python 中,程序的变量并不是在哪个位置都可以访问的,访问权限决定于这个变量是在哪里赋值的。
变量的作用域决定了在哪一部分程序可以访问哪个特定的变量名称。Python 的作用域一共有4种,分别是:
有四种作用域:
- L(Local):最内层,包含局部变量,比如一个函数/方法内部。
- E(Enclosing):包含了非局部(non-local) 也非全局(non-global) 的变量。比如两个嵌套函数,一个函数(或类) A 里面又包含了一个函数 B ,那么对于 B 中的名称来说 A 中的作用域就为 nonlocal
- G(Global):当前脚本的最外层,比如当前模块的全局变量。
- B(Built-in): 包含了内建的变量/关键字等,最后被搜索。
规则顺序: L –> E –> G –> B
在局部找不到,便会去局部外的局部找(例如闭包),再找不到就会去全局找,再者去内置中找。

g_count = 0 # 全局作用域
def outer():
o_count = 1 # 闭包函数外的函数中
def inner():
i_count = 2 # 局部作用域
内置作用域是通过一个名为 builtin 的标准模块来实现的,但是这个变量名自身并没有放入内置作用域内,所以必须导入这个文件才能够使用它。在 Python3.0 中,可以使用以下的代码来查看到底预定义了哪些变量:
>>> import builtins
>>> dir(builtins)
Python 中只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域,其它的代码块(如 if/elif/else/、try/except、for/while等)是不会引入新的作用域的,也就是说这些语句内定义的变量,外部也可以访问
>>> if True:
... msg = 'I am from Runoob'
...
>>> msg
'I am from Runoob'
实例中 msg 变量定义在 if 语句块中,但外部还是可以访问的。
如果将 msg 定义在函数中,则它就是局部变量,外部不能访问
全局变量和局部变量
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中
#!/usr/bin/python3
total = 0 # 这是一个全局变量
# 可写函数说明
def sum(arg1, arg2):
# 返回2个参数的和."
total = arg1 + arg2 # total在这里是局部变量.
print("函数内是局部变量 : ", total) # 30
return total
# 调用sum函数
sum(10, 20)
print("函数外是全局变量 : ", total) # 0
global 和 nonlocal关键字
当内部作用域想修改外部作用域的变量时,就要用到 global 和 nonlocal 关键字了。
#!/usr/bin/python3
num = 1
def fun1():
global num # 需要使用 global 关键字声明
print(num)
num = 123
print(num)
fun1()
print(num)
输出结果:
1
123
123
如果要修改嵌套作用域(enclosing 作用域,外层非全局作用域)中的变量则需要 nonlocal 关键字了
#!/usr/bin/python3
def outer():
num = 10
def inner():
nonlocal num # nonlocal关键字声明
num = 100
print(num)
inner()
print(num)
outer()
输出结果:
100
100
有一种特殊情况:
#!/usr/bin/python3
a = 10
def test():
a = a + 1
print(a)
test()
以上程序执行,报错信息如下:
Traceback (most recent call last):
File "test.py", line 7, in <module>
test()
File "test.py", line 5, in test
a = a + 1
UnboundLocalError: local variable 'a' referenced before assignment
错误信息为局部作用域引用错误,因为 test 函数中的 a 使用的是局部,未定义,无法修改。
标准库概览
操作系统接口
os 模块
建议使用 import os 风格而非 from os import * 。这样可以保证随操作系统不同而有所变化的 os.open() 不会覆盖内置函数 open()
import os
print(dir(os))
print("========================================")
help(os)
针对日常的文件和目录管理任务,shutil 模块提供了一个易于使用的高级接口:
>>> import shutil
>>> shutil.copyfile('data.db', 'archive.db')
>>> shutil.move('/build/executables', 'installdir')
文件通配符
glob 模块提供了一个函数用于从目录通配符搜索中生成文件列表:
import glob
print(glob.glob('*.py'))
命令行参数
通用工具脚本经常调用命令行参数。这些命令行参数以链表形式存储于 sys 模块的 argv 变量。例如在命令行中执行 python demo.py one two three 后可以得到以下输出结果:
>>> import sys
>>> print(sys.argv)
['demo.py', 'one', 'two', 'three']
错误输出重定向和程序终止
sys 还有 stdin ,stdout 和 stderr 属性,即使在 stdout 被重定向时,后者也可以用于显示警告和错误信息。
import sys
sys.stderr.write('Warning, log file not found starting a new one\n')
大多脚本的定向终止都使用 sys.exit()
字符串正则匹配
re 模块为高级字符串处理提供了正则表达式工具。
>>> import re
>>> re.findall(r'\bf[a-z]*', 'which foot or hand fell fastest')
['foot', 'fell', 'fastest']
>>> re.sub(r'(\b[a-z]+) \1', r'\1', 'cat in the the hat')
'cat in the hat'
如果只需要简单的功能,应该首先考虑字符串方法
>>> 'tea for too'.replace('too', 'two')
'tea for two'
数学
math 模块为浮点运算提供了对底层 C 函数库的访问:
>>> import math
>>> math.cos(math.pi / 4)
0.70710678118654757
>>> math.log(1024, 2)
10.0
random 提供了生成随机数的工具
>>> import random
>>> random.choice(['apple', 'pear', 'banana'])
'apple'
>>> random.sample(range(100), 10) # sampling without replacement
[30, 83, 16, 4, 8, 81, 41, 50, 18, 33]
>>> random.random() # random float
0.17970987693706186
>>> random.randrange(6) # random integer chosen from range(6)
4
访问互联网
有几个模块用于访问互联网以及处理网络通信协议。其中最简单的两个是用于处理从 urls 接收的数据的 urllib.request 以及用于发送电子邮件的 smtplib :
>>> from urllib.request import urlopen
>>> for line in urlopen('http://tycho.usno.navy.mil/cgi-bin/timer.pl'):
... line = line.decode('utf-8') # Decoding the binary data to text.
... if 'EST' in line or 'EDT' in line: # look for Eastern Time
... print(line)
<BR>Nov. 25, 09:43:32 PM EST
>>> import smtplib
>>> server = smtplib.SMTP('localhost')
>>> server.sendmail('soothsayer@example.org', 'jcaesar@example.org',
... """To: jcaesar@example.org
... From: soothsayer@example.org
...
... Beware the Ides of March.
... """)
>>> server.quit()
第二个例子需要本地有一个在运行的邮件服务器。
日期和时间
datetime 模块为日期和时间处理同时提供了简单和复杂的方法。
支持日期和时间算法的同时,实现的重点放在更有效的处理和格式化输出。
该模块还支持时区处理:
>>> # dates are easily constructed and formatted
>>> from datetime import date
>>> now = date.today()
>>> now
datetime.date(2003, 12, 2)
>>> now.strftime("%m-%d-%y. %d %b %Y is a %A on the %d day of %B.")
'12-02-03. 02 Dec 2003 is a Tuesday on the 02 day of December.'
>>> # dates support calendar arithmetic
>>> birthday = date(1964, 7, 31)
>>> age = now - birthday
>>> age.days
14368
数据压缩
以下模块直接支持通用的数据打包和压缩格式:zlib ,gzip ,bz2 ,zipfile 以及 tarfile
>>> import zlib
>>> s = b'witch which has which witches wrist watch'
>>> len(s)
41
>>> t = zlib.compress(s)
>>> len(t)
37
>>> zlib.decompress(t)
b'witch which has which witches wrist watch'
>>> zlib.crc32(s)
226805979
性能度量
timeit
>>> from timeit import Timer
>>> Timer('t=a; a=b; b=t', 'a=1; b=2').timeit()
0.57535828626024577
>>> Timer('a,b = b,a', 'a=1; b=2').timeit()
0.54962537085770791
相对于 timeit 的细粒度,profile 和 pstats 模块提供了针对更大代码块的时间度量工具。
测试模块
doctest 模块提供了一个工具,扫描模块并根据程序中内嵌的文档字符串执行测试。
unittest 模块不像 doctest 模块那么容易使用,不过它可以在一个独立的文件里提供一个更全面的测试集


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异