

20210404 4. 玩转 Elasticsearch 之企业级高可用分布式集群 - 拉勾教育
玩转 Elasticsearch 之企业级高可用分布式集群
核心概念
-
集群(Cluster)
一个 Elasticsearch 集群由多个节点(Node)组成,每个集群都有一个共同的集群名称作为标识
-
节点(Node)
- 一个 Elasticsearch 实例即一个 Node ,一台机器可以有多个实例,正常使用下每个实例都应该会部署在不同的机器上。 Elasticsearch 的配置文件中可以通过
node.master、node.data来设置节点类型。 node.master:表示节点是否具有成为主节点的资格true代表的是有资格竞选主节点false代表的是没有资格竞选主节点
node.data:表示节点是否存储数据
- 一个 Elasticsearch 实例即一个 Node ,一台机器可以有多个实例,正常使用下每个实例都应该会部署在不同的机器上。 Elasticsearch 的配置文件中可以通过
-
Node 节点组合:
-
主节点 + 数据节点( master + data ) ,默认
节点既有成为主节点的资格,又存储数据
node.master: true node.data: true -
数据节点(data)
节点没有成为主节点的资格,不参与选举,只会存储数据
node.master: false node.data: true -
客户端节点(client)
不会成为主节点,也不会存储数据,主要是针对海量请求的时候可以进行负载均衡
node.master: false node.data: false
-
-
分片
每个索引有 1 个或多个分片,每个分片存储不同的数据。分片可分为主分片( primaryshard )和复制分片( replica shard ),复制分片是主分片的拷贝。默认每个主分片有一个复制分片,每个索引的复制分片的数量可以动态地调整,复制分片从不与它的主分片在同一个节点上
-
副本
这里指主分片的副本分片(主分片的拷贝),作用是:
- 提高恢复能力:当主分片挂掉时,某个复制分片可以变成主分片;
- 提高性能:
get和search请求既可以由主分片又可以由复制分片处理;
Elasticsearch 分布式架构
Elasticseasrch 的架构遵循其基本概念:一个采用 Restful API 标准的高扩展性和高可用性的实时数据分析的全文搜索引擎。
特性
- 高扩展性:体现在 Elasticsearch 添加节点非常简单,新节点无需做复杂的配置,只要配置好集群信息将会被集群自动发现。
- 高可用性:因为 Elasticsearch 是分布式的,每个节点都会有备份,所以宕机一两个节点也不会出现问题,集群会通过备份进行自动复盘。
- 实时性:使用倒排索引来建立存储结构,搜索时常在百毫秒内就可完成。
分层
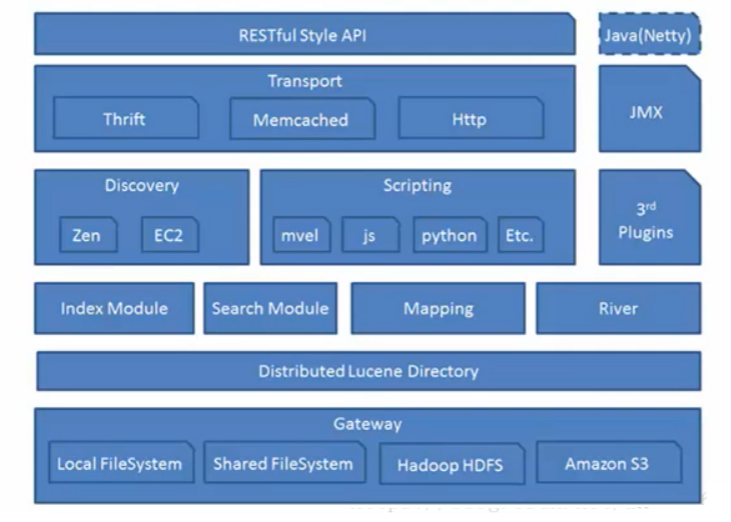
Gateway
Elasticsearch 支持的索引快照的存储格式, ES 默认是先把索引存放到内存中,当内存满了之后再持久化到本地磁盘。 Gateway 对索引快照进行存储,当 Elasticsearch 关闭再启动的时候,它就会从这个 Gateway 里面读取索引数据;支持的格式有:本地的 Local FileSystem 、分布式的 Shared FileSystem 、 Hadoop 的文件系统 HDFS 、 Amazon (亚马逊)的 S3 。
Lucene 框架
Elasticsearch 基于 Lucene (基于 Java 开发)框架。
Elasticsearch 数据的加工处理方式
Index Module (创建 Index 模块)、 Search Module (搜索模块)、 Mapping (映射)、 River 代表 ES 的一个数据源(运行在 Elasticsearch 集群内部的一个插件,主要用来从外部获取获取异构数据,然后在 Elasticsearch 里创建索引;常见的插件有 RabbitMQ River 、 Twitter River )。
Elasticsearch 发现机制、脚本
Discovery 是 Elasticsearch 自动发现节点的机制的模块, Zen Discovery 和 EC2 discovery 。
- EC2 :亚马逊弹性计算云 EC2 discovery 主要在亚马云平台中使用。
- Zen Discovery 作用就相当于 solrcloud 中的 ZooKeeper 。 Zen Discovery 从功能上可以分为两部分,第一部分是集群刚启动时的选主,或者是新加入集群的节点发现当前集群的 Master 。第二部分是选主完成后, Master 和 Folower 的相互探活。
Scripting 是脚本执行功能,有这个功能能很方便对查询出来的数据进行加工处理。
3rd Plugins 表示 Elasticsearch 支持安装很多第三方的插件,例如 elasticsearch-ik 分词插件、 elasticsearch-sql sql 插件。
Elasticsearch 的交互方式
有 Thrift 、 Memcached 、 Http 三种协议,默认的是用 Http 协议传输
Elasticsearch 的 API 支持模式
RESTFul Style API 风格的 API 接口标准是当下十分流行的。 Elasticsearch 作为分布式集群,客户端到服务端,节点与节点间通信有 TCP 和 Http 通信协议,底层实现为 Netty 框架
解析 Elasticsearch 的分布式架构
分布式架构的透明隐藏特性
Elasticsearch 是一个分布式系统,隐藏了复杂的处理机制:
- 分片机制:将文本数据切割成n个小份存储在不同的节点上,减少大文件存储在单个节点上对设备带来的压力。
- 分片的副本:在集群中某个节点宕掉后,通过副本可以快速对缺失数据进行复盘。
- 集群发现机制( cluster discovery ):在当前启动了一个 Elasticsearch 进程,在启动第二个 Elasticsearch 进程时,这个进程将作为一个 node 自动就发现了集群,并自动加入,前提是这些 node 都必须配置一套集群信息。
- Shard 负载均衡:例如现在由 10 个 shard (分片),集群中有三个节点, Elasticsearch 会进行均衡的分配,以保持每个节点均衡的负载请求。
扩容机制
- 垂直扩容:用新机器替换已有的机器,服务器台数不变容量增加。
- 水平扩容:直接增加新机器,服务器台数和容量都增加。
rebalance
增加或减少节点时会自动负载
主节点
主节点的主要职则是和集群操作的相关内容,如创建或删除索引,跟踪哪些节点是集群的一部分,并决定哪些分片分配给相关的节点。稳定的主节点对集群的健康是非常重要的。
节点对等
每个节点都能接受请求,每个节点接受到请求后都能把该请求路由到有相关数据的其它节点上,接受原始请求的节点负责采集数据并返回给客户端。
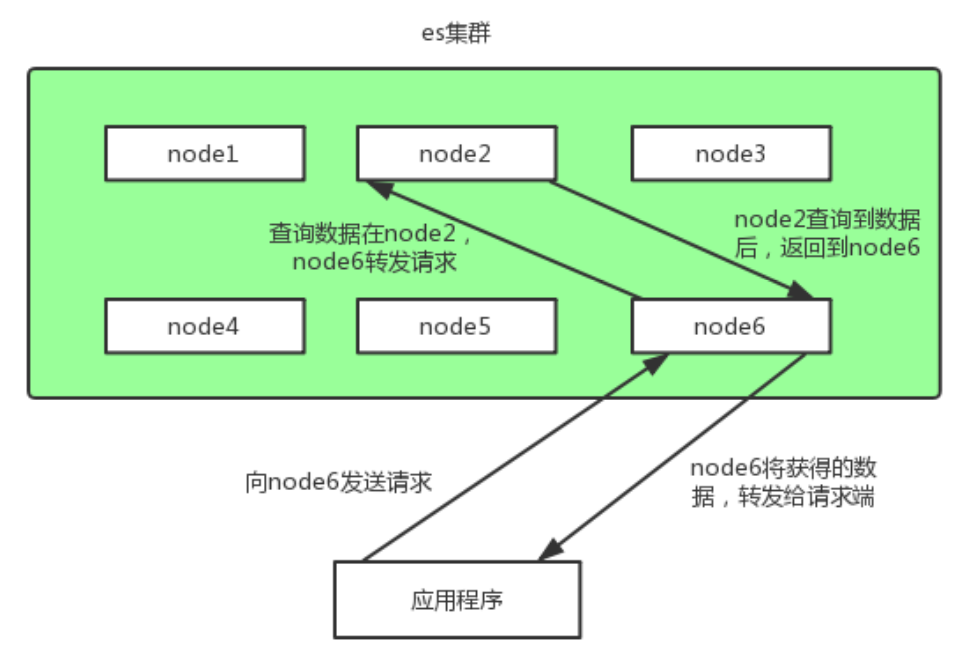
集群环境搭建
elasticsearch.yml ,相关配置
| 配置项 | 作用 |
|---|---|
| cluster.name | 集群名称,相同名称为一个集群 |
| node.name | 节点名称,集群模式下每个节点名称唯一 |
| node.master | 当前节点是否可以被选举为master节点,是:true、否:false |
| node.data | 当前节点是否用于存储数据,是:true、否:false |
| path.data | 索引数据存放的位置 |
| path.logs | 日志文件存放的位置 |
| bootstrap.memory_lock | 需求锁住物理内存,是:true、否:false |
| network.host | 监听地址,用于访问该es |
| http.port | es对外提供的http端口,默认 9200 |
| transport.port | 节点选举的通信端口 默认是9300 |
| discovery.seed_hosts | es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服 务后可以被选为主节点 |
| cluster.initial_master_nodes | es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选 举master |
| http.cors.enabled | 是否支持跨域,是:true,在使用head插件时需要此配置 |
| http.cors.allow-origin "*" | 表示支持所有域名 |
搭建过程略
集群规划
我们需要多大规模的集群
需要从以下两个方面考虑:
- 当前的数据量有多大?数据增长情况如何?
- 你的机器配置如何?cpu、多大内存、多大硬盘容量?
推算的依据:
- Elasticsearch JVM heap 最大可以设置 32G 。
- 30G heap 大概能处理的数据量 10T 。如果内存很大如 128G,可在一台机器上运行多个 ES 节点实例。
备注:集群规划满足当前数据规模+适量增长规模即可,后续可按需扩展。
两类应用场景:
- 用于构建业务搜索功能模块,且多是垂直领域的搜索。数据量级几千万到数十亿级别。一般 2-4 台机器的规模。
- 用于大规模数据的实时 OLAP (联机处理分析),经典的如 ELK Stack ,数据规模可能达到千亿或更多。几十到上百节点的规模。
集群中的节点角色如何分配
节点角色:
-
Master
node.master: true:节点可以作为主节点 -
DataNode
node.data: true:默认是数据节点 -
Coordinate node
协调节点,一个节点只作为接收请求、转发请求到其他节点、汇总各个节点返回数据等功能的节点,就叫协调节点,如果仅担任协调节点,将上两个配置设为
false。
说明:一个节点可以充当一个或多个角色,默认三个角色都有
节点角色如何分配:
- 小规模集群,不需严格区分。
- 中大规模集群(十个以上节点),应考虑单独的角色充当。特别并发查询量大,查询的合并量大,可以增加独立的协调节点。角色分开的好处是分工分开,不互影响。如不会因协调角色负载过高而影响数据节点的能力。
如何避免脑裂问题 脑裂问题
一个集群中只有一个 A 主节点, A 主节点因为需要处理的东西太多或者网络过于繁忙,从而导致其他从节点 ping 不通 A 主节点,这样其他从节点就会认为 A 主节点不可用了,就会重新选出一个新的主节点 B 。过了一会 A 主节点恢复正常了,这样就出现了两个主节点,导致一部分数据来源于 A 主节点,另外一部分数据来源于 B 主节点,出现数据不一致问题,这就是 脑裂 。
6.x 和之前版本尽量避免脑裂,需要添加最小数量的主节点配置:discovery.zen.minimum_master_nodes: (有master资格节点数/2) + 1
这个参数控制的是,选举主节点时需要看到最少多少个具有 master 资格的活节点,才能进行选举。官方
的推荐值是 (N/2)+1 ,其中N是具有 master 资格的节点的数量。
在新版 7.X 的 ES 中,对 es 的集群发现系统做了调整,不再有 discovery.zen.minimum_master_nodes 这个控制集群脑裂的配置,转而由集群自主控制,并且新版在启动一个新的集群的时候需要有 cluster.initial_master_nodes 初始化集群列表。
在 ES 7 中,discovery.zen.* 开头的参数,有些已经失效:
| Old name | New name |
|---|---|
| discovery.zen.ping.unicast.hosts | discovery.seed_hosts |
| discovery.zen.hosts_provider | discovery.seed_providers |
| discovery.zen.no_master_block | cluster.no_master_block |
常用做法(中大规模集群):
- Master 和 dataNode 角色分开,配置奇数个 Master ,如 3
- 单播发现机制,配置 Master 资格节点( 5.0 之前):
discovery.zen.ping.multicast.enabled: false—— 关闭多播发现机制,默认是关闭的 - 延长 ping Master 的等待时长
discovery.zen.ping_timeout: 30(默认值是 3 秒)—— 其他节点 ping 主节点多久时间没有响应就认为主节点不可用了。ES 7 中换成了 discovery.request_peers_timeout
索引应该设置多少个分片
分片数指定后不可变,除非重建索引。
分片设置的可参考原则:
- Elasticsearch 推荐的最大 JVM 堆空间是 30~32G , 所以把你的分片最大容量限制为 30GB , 然后再对分片数量做合理估算 . 例如, 你认为你的数据能达到 200GB , 推荐你最多分配 7 到 8 个分片。
- 在开始阶段, 一个好的方案是根据你的节点数量按照 1.5~3 倍的原则来创建分片 . 例如,如果你有 3 个节点,则推荐你创建的分片数最多不超过 9 ( 3x3 )个。当性能下降时,增加节点, ES 会平衡分片的放置。
- 对于基于日期的索引需求, 并且对索引数据的搜索场景非常少 . 也许这些索引量将达到成百上千, 但每个索引的数据量只有 1GB 甚至更小。对于这种类似场景, 建议只需要为索引分配 1 个分片。如日志管理就是一个日期的索引需求,日期索引会很多,但每个索引存放的日志数据量就很少。
分片应该设置几个副本
副本设置基本原则:为保证高可用,副本数设置为 2 即可。要求集群至少要有 3 个节点,来分开存放主分片、副本。如发现并发量大时,查询性能会下降,可增加副本数,来提升并发查询能力。
注意:新增副本时主节点会自动协调,然后拷贝数据到新增的副本节点,副本数是可以随时调整的!
PUT /my_temp_index/_settings
{
"number_of_replicas": 1
}
分布式集群调优策略
拉勾网是一家专注于互联网垂直招聘的互联网公司,我们在生产环境的多个场景下都使用到了 Elasticsearch ,比如针对 C 端个人用户的职位搜索、针对 B 端企业用户的简历搜索,另外也在后台日志分析平台( ELK )中应用到,所部署的 Elasticsearch 版本上覆盖了 2.x 、 5.x 、 6.x 和 7.x 多个版本。在拉勾网数据总量达百亿级 documents ,日增量近 1T (近 1 百万 document )的高并发海量数据场景下,研发和运维团队积累了丰富的 Elasticsearch 调优经验。
拉勾网生产环境 Elasticsearch 集群有多套,但节点数并没有很多,针对 C 端个人用户的职位搜索只有 7 个实例节点, ELK 日志平台中 Elasticsearch 实例节点数也仅仅只有 4 个,考虑到资金投入、当前及未来一定时间内数据的增量情况等,研发和运维团队在竭尽所能的通过调优方式保证 Elasticsearch 正常高效运转。
接下来,我们从 Index (写)和 Search (读)两个方面给大家分享调优经验
Index (写)调优
拉勾网的职位数据和简历数据,首先都是进入 MySQL 集群的,我们从 MySQL 的原始表里面抽取并存储到 ES 的 Index ,而 MySQL 的原始数据也是经常在变化的,所以快速写入 Elasticsearch 、以保持 Elasticsearch 和 MySQL 的数据及时同步也是很重要的。
拉勾网的工程师主要是下面几个方面优化来提高写入的速度:
副本数置 0
如果是集群首次灌入数据,可以将副本数设置为 0 ,写入完毕再调整回去,这样副本分片只需要拷贝,节省了索引过程。
PUT /my_temp_index/_settings
{
"number_of_replicas": 0
}
自动生成 doc ID
通过 Elasticsearch 写入流程可以看出,如果写入 doc 时如果外部指定了 id ,则 Elasticsearch 会先尝试读取原来 doc 的版本号,以判断是否需要更新。这会涉及一次读取磁盘的操作,通过自动生成 doc ID 可以避免这个环节。
合理设置 mappings
- 将不需要建立索引的字段
index属性设置为not_analyzed或no。对字段不分词,或者不索引,可以减少很多运算操作,降低 CPU 占用。 尤其是binary类型,默认情况下占用 CPU 非常高,而这种类型进行分词通常没有什么意义。 - 减少字段内容长度,如果原始数据的大段内容无须全部建立索引,则可以尽量减少不必要的内容。
- 使用不同的分析器(analyzer),不同的分析器在索引过程中运算复杂度也有较大的差异。
调整 _source字段
_source 字段用于存储 doc 原始数据,对于部分不需要存储的字段,可以通过 includes、excludes 过滤,或者将 _source 禁用,一般用于索引和数据分离,这样可以降低 I/O 的压力,不过实际场景中大多不会禁用 _source 。
对 analyzed 的字段禁用 norms
norms 用于在搜索时计算 doc 的评分,如果不需要评分,则可以将其禁用:
"title": {
"type": "string",
"norms": {
"enabled": false
}
}
调整索引的刷新间隔
该参数缺省是 1s ,强制 ES 每秒创建一个新 segment ,从而保证新写入的数据近实时的可见、可被搜索到。比如该参数被调整为 30s ,降低了刷新的次数,把刷新操作消耗的系统资源释放出来给 index 操作使用。
PUT /my_index/_settings
{
"index": {
"refresh_interval": "30s"
}
}
这种方案以牺牲可见性的方式,提高了 index 操作的性能。
批处理
批处理把多个 index 操作请求合并到一个 batch 中去处理,和 MySQL 的 jdbc 的 bacth 有类似之处。
比如每批 1000 个 documents 是一个性能比较好的 size 。每批中多少 document 条数合适,受很多因素影响而不同,如单个 document 的大小等。 ES 官网建议通过在单个 node 、单个 shard 做性能基准测试来确定这个参数的最优值。
Document 的路由处理
当对一批中的 documents 进行 index 操作时,该批 index 操作所需的线程的个数由要写入的目的 shard 的个数决定。
假设有 2 批 documents 写入 ES , 每批都需要写入 4 个 shard ,所以总共需要 8 个线程。如果能减少 shard 的个数,那么耗费的线程个数也会减少。如果两批中每批的 shard 个数都只有 2 个,总共线程消耗个数 4 个,减少一半。
默认的 routing 就是 id ,也可以在发送请求的时候,手动指定一个 routing value ,比如说 PUT /index/doc/id?routing=user_id
值得注意的是线程数虽然降低了,但是单批的处理耗时可能增加了。和提高刷新间隔方法类似,这有可能会延长数据不见的时间。
Search (读)调优
在存储的 Document 条数超过 10 亿条后,我们如何进行搜索调优。
数据分组
很多人拿 ES 用来存储日志,日志的索引管理方式一般基于日期的,基于天、周、月、年建索引。如果基于天建索引,当搜索单天的数据,只需要查询一个索引的 shards 就可以。当需要查询多天的数据时,需要查询多个索引的 shards 。这种方案其实和数据库的分表、分库、分区查询方案相比,思路类似,小数据范围查询而不是大海捞针。
开始的方案是建一个 index ,当数据量增大的时候,就扩容增加 index 的 shard 的个数。当 shards 增大时,要搜索的 shards 个数也随之显著上升。基于数据分组的思路,可以基于 client 进行数据分组,每一个 client 只需依赖自己的 index 的数据 shards 进行搜索,而不是所有的数据 shards ,大大提高了搜索的性能
使用 Filter 替代 Query
在搜索时候使用 Query ,需要为 Document 的相关度打分。使用 Filter ,没有打分环节处理,做的事情更少,而且 Filter 理论上更快一些。
如果搜索不需要打分,可以直接使用 Filter 查询。如果部分搜索需要打分,建议使用 bool 查询。这种方式可以把打分的查询和不打分的查询组合在一起使用,如:
GET /_search
{
"query": {
"bool": {
"must": {
"term": {
"user": "kimchy"
}
},
"filter": {
"term": {
"tag": "tech"
}
}
}
}
}
ID 字段定义为 keyword
一般情况,如果 ID 字段不会被用作 Range 类型搜索字段,都可以定义成 keyword 类型。这是因为 keyword 会被优化,以便进行 terms 查询。 integers 等数字类的 mapping 类型,会被优化来进行 range 类型搜索。
将 integers 改成 keyword 类型之后,搜索性能大约能提升 30% 。
别让用户的无约束的输入拖累了 ES 集群的性能
拉勾工程师通过监控发现所有 node 的 CPU 使用及其负载突然异常飙高。通过对 Slow Logs 分析发现,用户查询输入的条件中夹带了很多 OR 语句以及通配符 * 开头的字符串
为了不让用户无约束的查询语句拖累 ES 集群的查询性能,可以限制用户用来查询的 keywords 。对于可以用来查询的 keywords ,也可以写成文档来帮助用户更正确的使用。

