
20200311 2. RabbitMQ
RabbitMQ
RabbitMQ 架构与实战
RabbitMQ 介绍、概念、基本架构
RabbitMQ 介绍
RabbitMQ,俗称 兔子MQ (可见其轻巧,敏捷),是目前非常热门的一款开源消息中间件,不管是互联网行业还是传统行业都广泛使用(最早是为了解决电信行业系统之间的可靠通信而设计)。
- 高可靠性、易扩展、高可用、功能丰富等
- 支持大多数(甚至冷门)的编程语言客户端
- RabbitMQ 遵循 AMQP 协议,自身采用 Erlang (一种由爱立信开发的通用面向并发编程的语言)编写
- RabbitMQ 也支持 MQTT 等其他协议
RabbitMQ具有很强大的插件扩展能力,官方和社区提供了非常丰富的插件可供选择:Community Plugins
RabbitMQ 整体逻辑架构
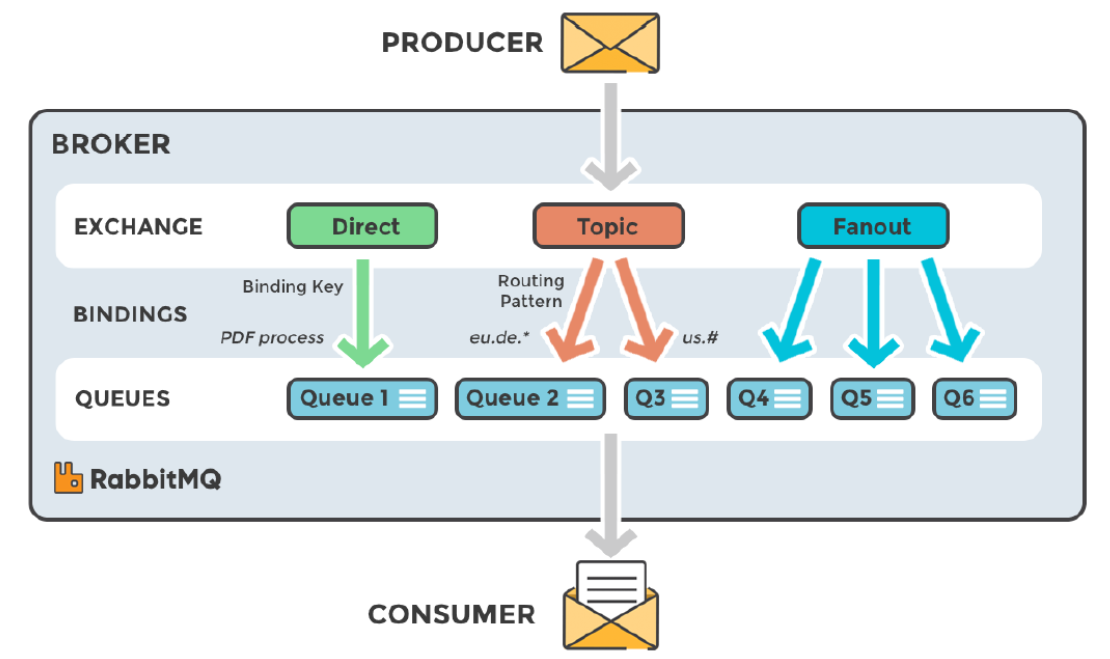
RabbitMQ Exchange 类型
RabbitMQ 常用的交换器类型有: fanout 、 direct 、 topic 、 headers 四种。
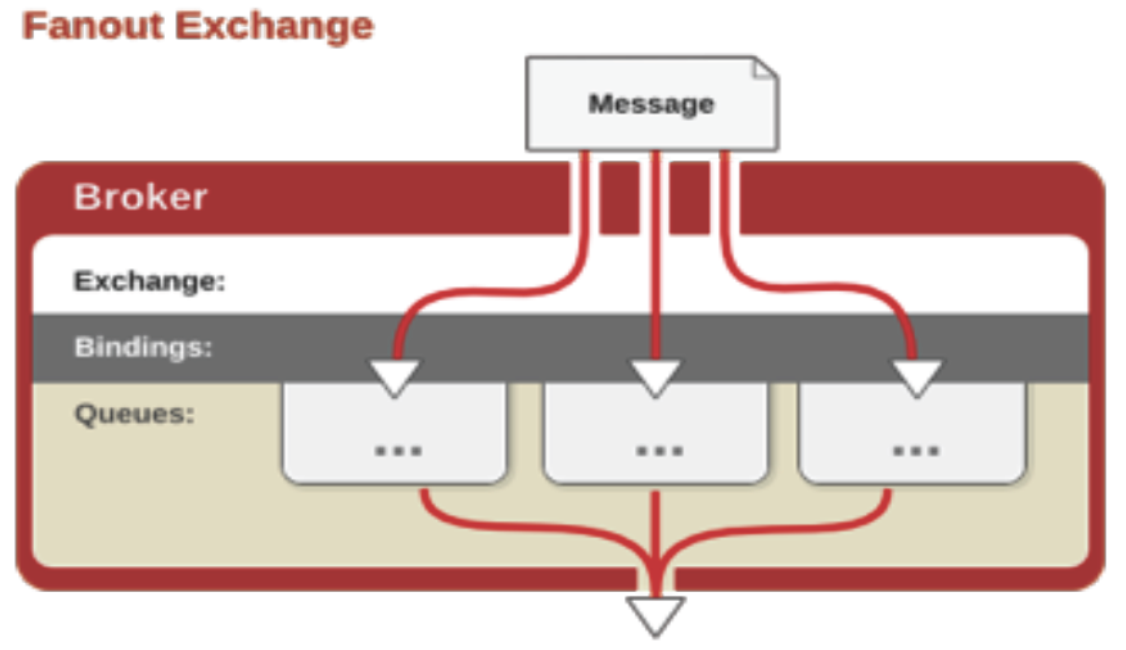
Fanout
会把所有发送到该交换器的消息路由到所有与该交换器绑定的队列中,如图:
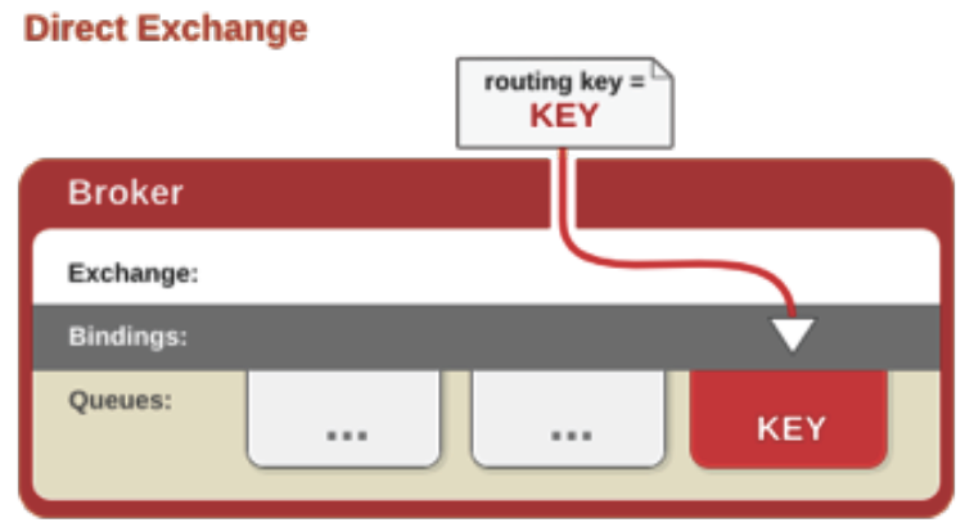
Direct
direct 类型的交换器路由规则很简单,它 会把消息路由到那些 BindingKey 和 RoutingKey 完全匹配的队列中,如下图:
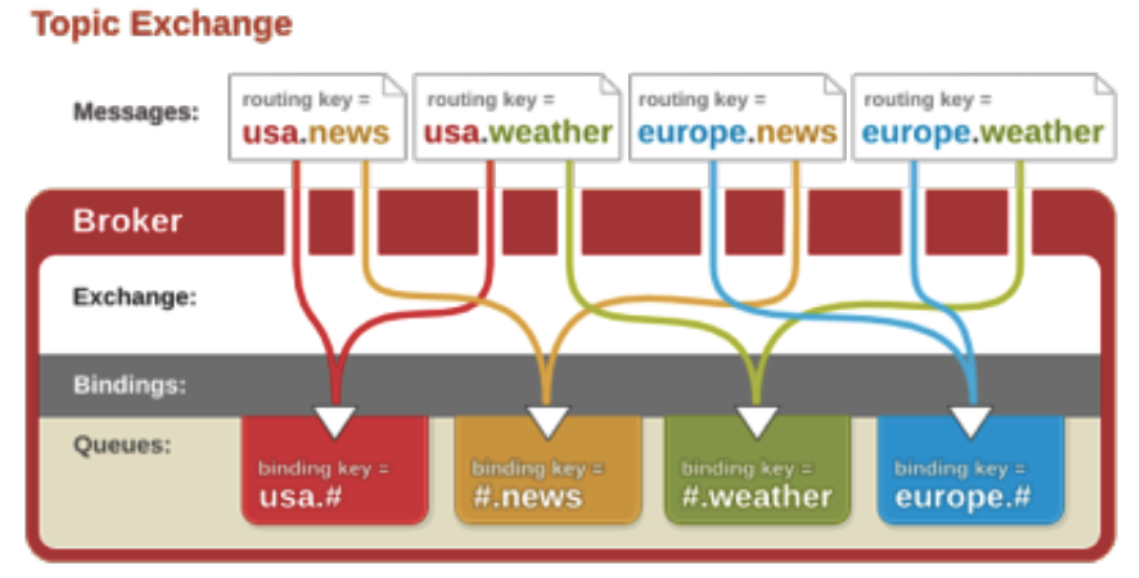
Topic
topic 类型的交换器在 direct 匹配规则上进行了扩展,也是 将消息路由到 BindingKey 和 RoutingKey 相匹配的队列中,这里的匹配规则稍微不同,它约定:
BindingKey 和 RoutingKey 一样都是由 . 分隔的字符串; BindingKey 中可以存在两种特殊字符 * 和 # ,用于模糊匹配,其中 * 用于匹配一个单词, # 用于匹配多个单词( 可以是 0 个 )。
Headers
headers 类型的交换器不依赖于路由键的匹配规则来路由信息,而是根据发送的消息内容中的 headers 属性进行匹配。在绑定队列和交换器时指定一组键值对,当发送的消息到交换器时, RabbitMQ 会获取到该消息的 headers ,对比其中的键值对是否完全匹配队列和交换器绑定时指定的键值对,如果匹配,消息就会路由到该队列。
headers 类型的交换器性能很差,不实用。
RabbitMQ 数据存储
存储机制
RabbitMQ 消息有两种类型:持久化消息和非持久化消息,这两种消息都会被写入磁盘。
- 持久化消息在到达队列时写入磁盘,同时会内存中保存一份备份,当内存吃紧时,消息从内存中清除。这会提高一定的性能。
- 非持久化消息一般只存于内存中,当内存压力大时数据刷盘处理,以节省内存空间。
RabbitMQ 存储层包含两个部分:队列索引和消息存储。
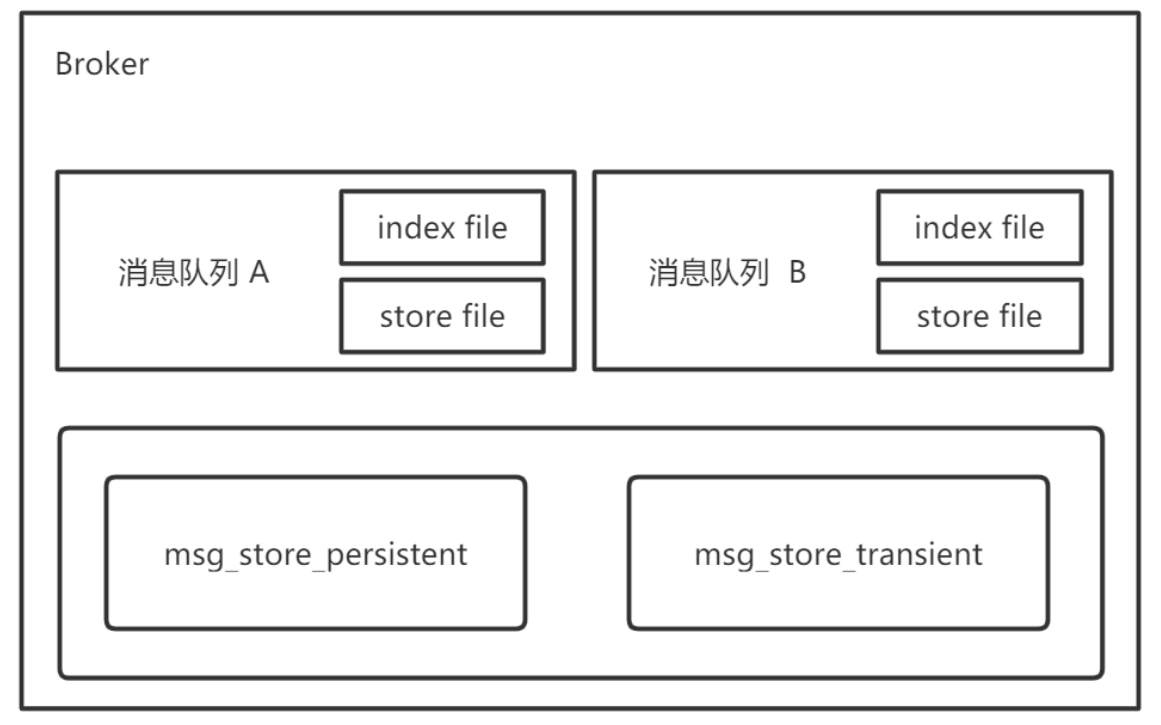
队列索引:rabbit_queue_index
索引维护队列的落盘消息的信息,如存储地点、是否已被给消费者接收、是否已被消费者 ack 等。
每个队列都有相对应的索引。
索引使用顺序的段文件来存储,后缀为 .idx ,文件名从 0 开始累加,每个段文件中包含固定的 segment_entry_count 条记录,默认值是 16384 。每个 index 从磁盘中读取消息的时候,至少要在内存中维护一个段文件,所以设置 queue_index_embed_msgs_below 值得时候要 格外谨慎,一点点增大也可能会引起内存爆炸式增长。
消息(包括消息体、属性和 headers )可以直接存储在 rabbit_queue_index 中,也可以被保存在 rabbit_msg_store 中。最佳的配备是较小的消息存储在 rabbit_queue_index 中而较大的消息存储在 rabbit_msg_store 中。这个消息大小的界定可以通过 queue_index_embed_msgs_below 来配置,默认大小为 4096B 。这里的大小是指消息体、属性及 headers 整体的大小。
消息存储:rabbit_msg_store
消息以键值对的形式存储到文件中,一个虚拟主机上的所有队列使用同一块存储,每个节点只有一个。存储分为持久化存储( msg_store_persistent )和短暂存储( msg_store_transient )。持久化存储的内容在 Broker 重启后不会丢失,短暂存储的内容在 Broker 重启后丢失。
store 使用文件来存储,后缀为 .rdq ,经过 store 处理的所有消息都会以追加的方式写入到该文件中,当该文件的大小超过指定的限制( file_size_limit )后,将会关闭该文件并创建一个新的文件以供新的消息写入。文件名从 0 开始进行累加。在进行消息的存储时,RabbitMQ 会在 ETS ( Erlang TermStorage )表中记录消息在文件中的位置映射和文件的相关信息。
消息(包括消息头、消息体、属性)可以直接存储在 index 中,也可以存储在 store 中。最佳的方式是较小的消息存在 index 中,而较大的消息存在 store 中。这个消息大小的界定可以通过 queue_index_embed_msgs_below 来配置,默认值为 4096B 。当一个消息小于设定的大小阈值时,就可以存储在 index 中,这样性能上可以得到优化。一个完整的消息大小小于这个值,就放到索引中,否则放到持久化消息文件中。
rabbitmq.conf 中的配置信息:
## Size in bytes below which to embed messages in the queue index.
## Related doc guide: https://rabbitmq.com/persistence-conf.html
##
# queue_index_embed_msgs_below = 4096
## You can also set this size in memory units
##
# queue_index_embed_msgs_below = 4kb
如果消息小于这个值,就在索引中存储,如果消息大于这个值就在 store 中存储
- 大于这个值的消息存储于
msg_store_persistent目录中的<num>.rdq文件中 - 小于这个值的消息存储于
<num>.idx索引文件中
读取消息时,先根据消息的 ID ( msg_id )找到对应存储的文件,如果文件存在并且未被锁住,则直接打开文件,从指定位置读取消息内容。如果文件不存在或者被锁住了,则发送请求由 store 进行处理。
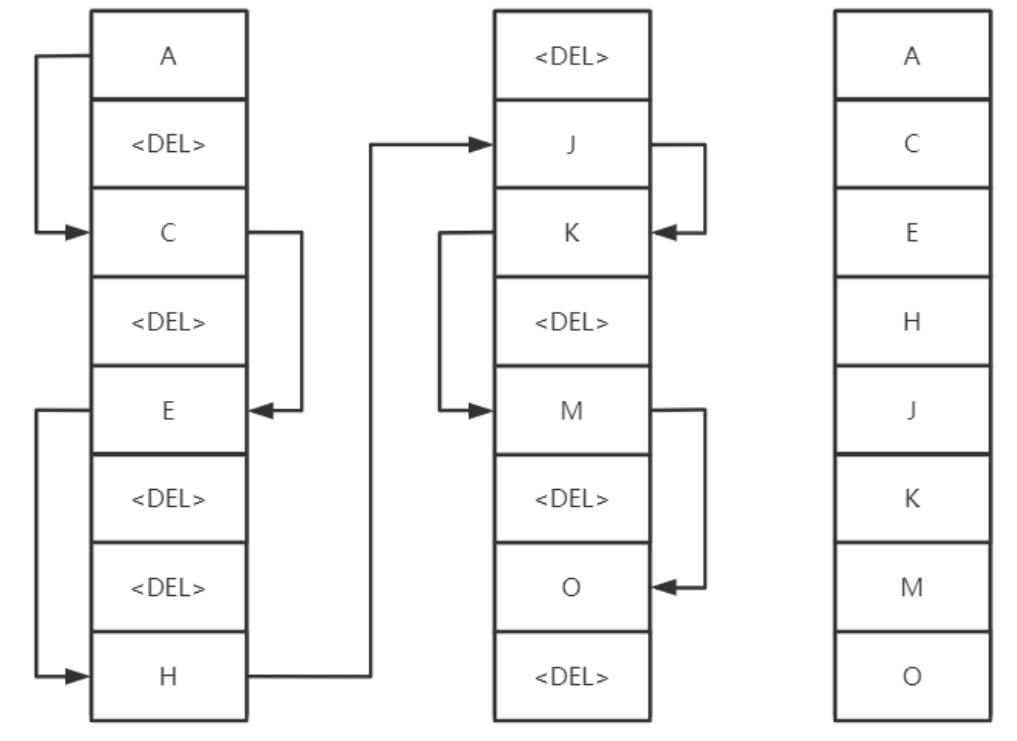
删除消息时,只是从 ETS 表删除指定消息的相关信息,同时更新消息对应的存储文件和相关信息。在执行消息删除操作时,并不立即对文件中的消息进行删除,也就是说消息依然在文件中,仅仅是标记为垃圾数据而已。当一个文件中都是垃圾数据时可以将这个文件删除。当检测到前后两个文件中的有效数据可以合并成一个文件,并且所有的垃圾数据的大小和所有文件(至少有 3 个文件存在的情况下)的数据大小的比值超过设置的阈值 garbage_fraction (默认值 0.5 )时,才会触发垃圾回收,将这两个文件合并,执行合并的两个文件一定是逻辑上相邻的两个文件。
合并逻辑:
- 锁定这两个文件
- 先整理前面的文件的有效数据,再整理后面的文件的有效数据
- 将后面文件的有效数据写入到前面的文件中
- 更新消息在 ETS 表中的记录
- 删除后面文件
队列结构
通常队列由 rabbit_amqqueue_process 和 backing_queue 这两部分组成, rabbit_amqqueue_process 负责协议相关的消息处理,即接收生产者发布的消息、向消费者交付消息、处理消息的确认( 包括生产端的 confirm 和消费端的 ACK )等。 backing_queue 是消息存储的具体形式和引擎,并向 rabbit_amqqueue_process 提供相关的接口以供调用。
如果消息投递的目的队列是空的,并且有消费者订阅了这个队列,那么该消息会直接发送给消费者,不会经过队列这一步。当消息无法直接投递给消费者时,需要暂时将消息存入队列,以便重新投递。
rabbit_variable_queue.erl 源码中定义了 RabbitMQ 队列的 4 种状态:
alpha:消息索引和消息内容都存内存,最耗内存,很少消耗 CPUbeta:消息索引存内存,消息内容存磁盘gama:消息索引内存和磁盘都有,消息内容存磁盘delta:消息索引和内容都存磁盘,基本不消耗内存,消耗更多 CPU 和 I/O 操作
消息存入队列后,不是固定不变的,它会随着系统的负载在队列中不断流动,消息的状态会不断发生变化。
持久化的消息,索引和内容都必须先保存在磁盘上,才会处于上述状态中的一种。
gama 状态是只有持久化消息才会有的状态。
在运行时, RabbitMQ 会根据消息传递的速度定期计算一个当前内存中能够保存的最大消息数量( target_ram_count ),如果 alpha 状态的消息数量大于此值,则会引起消息的状态转换,多余的消息可能会转换到 beta 、 gama 或者 delta 状态。区分这 4 种状态的主要作用是满足不同的内存和 CPU 需求。
对于普通没有设置优先级和镜像的队列来说, backing_queue 的默认实现是 rabbit_variable_queue ,其内部通过 5 个子队列 Q1 、 Q2 、 delta 、 Q3 、 Q4 来体现消息的各个状态。
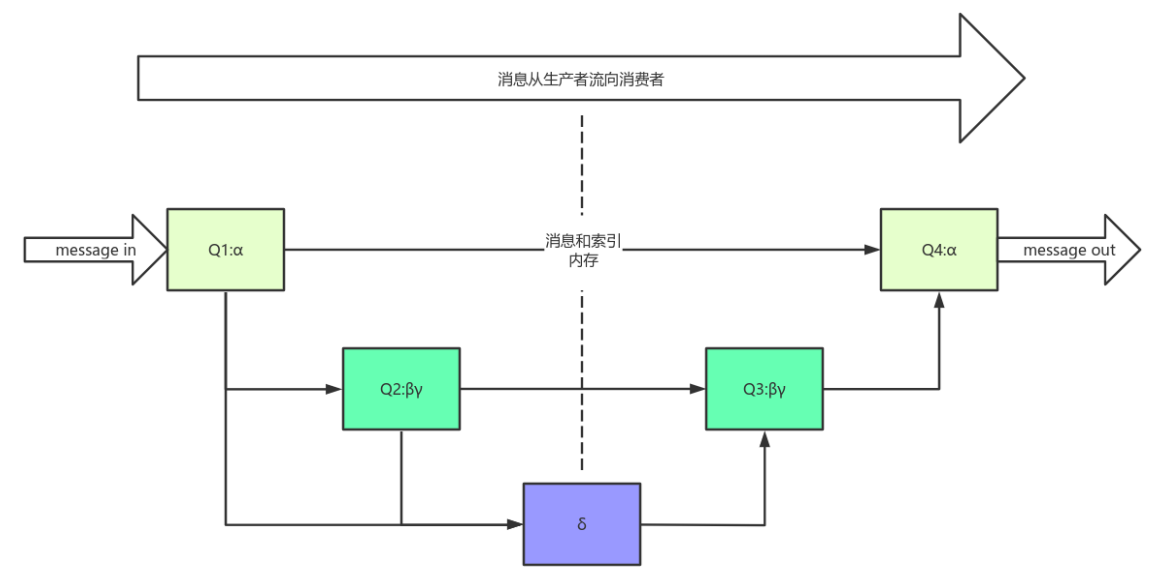
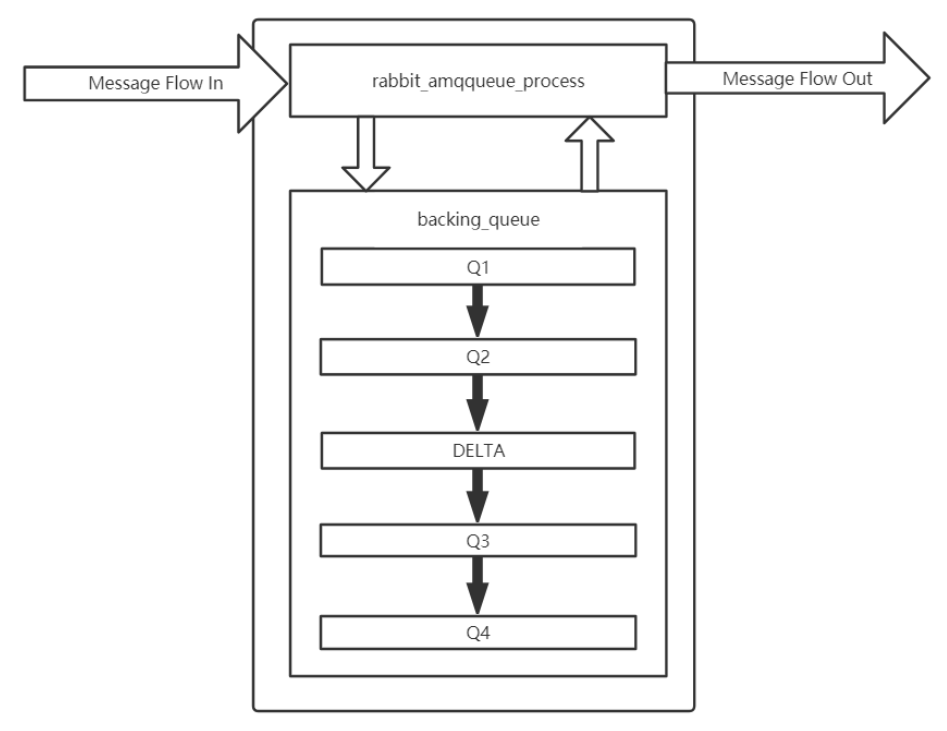
消费者获取消息也会引起消息的状态转换。
当消费者获取消息时:
- 首先会从 Q4 中获取消息,如果获取成功则返回
- 如果 Q4 为空,则尝试从 Q3 中获取消息,系统首先会判断 Q3 是否为空,如果为空则返回队列为空,即此时队列中无消息。
- 如果 Q3 不为空,则取出 Q3 中的消息;进而再判断此时 Q3 和 Delta 中的长度,如果都为空,则可以认为 Q2 、 Delta 、 Q3 、 Q4 全部为空,此时将 Q1 中的消息直接转移至 Q4 ,下次直接从 Q4 中获取消息。
- 如果 Q3 为空, Delta 不为空,则将 Delta 的消息转移至 Q3 中,下次可以直接从 Q3 中获取消息。在将消息从 Delta 转移到 Q3 的过程中,是按照索引分段读取的,首先读取某一段,然后判断读取的消息的个数与 Delta 中消息的个数是否相等,如果相等,则可以判定此时 Delta 中己无消息,则直接将 Q2 和刚读取到的消息一并放入到 Q3 中,如果不相等,仅将此次读取到的消息转移到 Q3 。
这里就有两处疑问,第一个疑问是:为什么 Q3 为空则可以认定整个队列为空?
- 试想一下,如果 Q3 为空, Delta 不为空,那么在 Q3 取出最后一条消息的时候, Delta 上的消息就会被转移到 Q3 ,这样与 Q3 为空矛盾;
- 如果 Delta 为空且 Q2 不为空,则在 Q3 取出最后一条消息时会将 Q2 的消息并入到 Q3 中,这样也与 Q3 为空矛盾;
- 在 Q3 取出最后一条消息之后,如果 Q2 、 Delta 、 Q3 都为空,且 Q1 不为空时,则 Q1 的消息会被转移到 Q4 ,这与 Q4 为空矛盾。
其实这一番论述也解释了另一个问题:为什么 Q3 和 Delta 都为空时,则可以认为 Q2 、 Delta 、 Q3 、 Q4 全部为空?
通常在负载正常时,如果消费速度大于生产速度,对于不需要保证可靠不丢失的消息来说,极有可能只会处于 alpha 状态。
对于持久化消息,它一定会进入 gamma 状态,在开启 publisher confirm 机制时,只有到了 gamma 状态时才会确认该消息己被接收,若消息消费速度足够快、内存也充足,这些消息也不会继续走到下一个状态。
为什么消息的堆积导致性能下降?
在系统负载较高时,消息若不能很快被消费掉,这些消息就会进入到很深的队列中去,这样会增加处理每个消息的平均开销。因为要花更多的时间和资源处理“堆积”的消息,如此用来处理新流入的消息的能力就会降低,使得后流入的消息又被积压到很深的队列中,继续增大处理每个消息的平均开销,继而情况变得越来越恶化,使得系统的处理能力大大降低。
应对这一问题一般有 3 种措施:
- 增加
prefetch_count的值,即一次发送多条消息给消费者,加快消息被消费的速度 - 采用 multiple ack,降低处理 ack 带来的开销
- 流量控制
安装和配置 RabbitMQ
略
RabbitMQ 常用操作命令
# 前台启动Erlang VM和RabbitMQ
rabbitmq-server
# 后台启动
rabbitmq-server -detached
# 停止RabbitMQ和Erlang VM
rabbitmqctl stop
# 查看所有队列
rabbitmqctl list_queues
# 查看所有虚拟主机
rabbitmqctl list_vhosts
# 在Erlang VM运行的情况下启动、停止RabbitMQ应用
rabbitmqctl start_app
rabbitmqctl stop_app
# 查看节点状态
rabbitmqctl status
# 查看所有可用的插件
rabbitmq-plugins list
# 启用插件
rabbitmq-plugins enable <plugin-name>
# 停用插件
rabbitmq-plugins disable <plugin-name>
# 添加用户
rabbitmqctl add_user username password
# 列出所有用户:
rabbitmqctl list_users
# 删除用户:
rabbitmqctl delete_user username
# 清除用户权限:
rabbitmqctl clear_permissions -p vhostpath username
# 列出用户权限:
rabbitmqctl list_user_permissions username
# 修改密码:
rabbitmqctl change_password username newpassword
# 设置用户权限:
rabbitmqctl set_permissions -p vhostpath username ".*" ".*" ".*"
# 创建虚拟主机:
rabbitmqctl add_vhost vhostpath
# 列出所以虚拟主机:
rabbitmqctl list_vhosts
# 列出虚拟主机上的所有权限:
rabbitmqctl list_permissions -p vhostpath
# 删除虚拟主机:
rabbitmqctl delete_vhost vhost vhostpath
# 移除所有数据,要在 rabbitmqctl stop_app 之后使用:
rabbitmqctl reset
RabbitMQ 工作流程详解
生产者发送消息的流程
- 生产者连接 RabbitMQ ,建立 TCP 连接( Connection ),开启信道( Channel )
- 生产者声明一个 Exchange (交换器),并设置相关属性,比如交换器类型、是否持久化等
- 生产者声明一个队列井设置相关属性,比如是否排他、是否持久化、是否自动删除等
- 生产者通过 bindingKey (绑定Key)将交换器和队列绑定( binding )起来
- 生产者发送消息至 RabbitMQ Broker,其中包含 routingKey (路由键)、交换器等信息
- 相应的交换器根据接收到的 routingKey 查找相匹配的队列
- 如果找到,则将从生产者发送过来的消息存入相应的队列中
- 如果没有找到,则根据生产者配置的属性选择丢弃还是回退给生产者
- 关闭信道
- 关闭连接
消费者接收消息的过程
- 消费者连接到 RabbitMQ Broker ,建立一个连接( Connection ) ,开启一个信道( Channel )
- 消费者向 RabbitMQ Broker 请求消费相应队列中的消息,可能会设置相应的回调函数, 以及做一些准备工作
- 等待 RabbitMQ Broker 回应并投递相应队列中的消息, 消费者接收消息
- 消费者确认( ACK ) 接收到的消息
- RabbitMQ 从队列中删除相应己经被确认的消息
- 关闭信道
- 关闭连接
案例
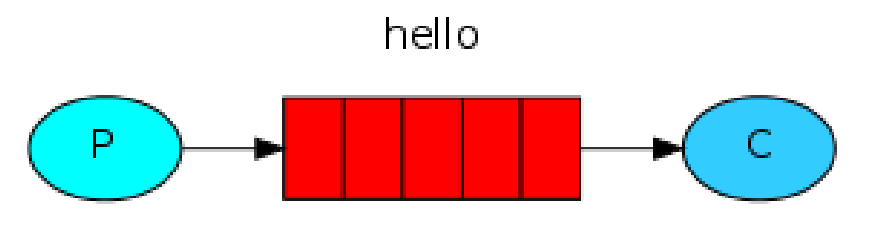
Hello World 一对一的简单模式。生产者直接发送消息给 RabbitMQ ,另一端消费。未定义和指定 Exchange 的情况下,使用的是 AMQP default 这个内置的 Exchange 。
-
pom.xml
<dependency> <groupId>com.rabbitmq</groupId> <artifactId>amqp-client</artifactId> <version>5.9.0</version> </dependency> -
生产者
/** * Rabbitmq是一个消息 Broker:接收消息,传递给下游应用 * <p> * 术语: * Producing就是指发送消息,发送消息的程序是Producer * Queue指的是RabbitMQ内部的一个组件,消息存储于queue中。queue使用主机的内存和磁盘存 * 储,收到内存和磁盘空间的限制 * 可以想象为一个大的消息缓冲。很多Producer可以向同一个queue发送消息,很多消费者 * 可以从同一个queue消费消息。 * Consuming就是接收消息。一个等待消费消息的应用程序称为Consumer * <p> * 生产者、消费者、队列不必在同一台主机,一般都是在不同的主机上的应用。一个应用可以同时是 * 生产者和消费者。 */ public class HelloWorldSender { private static String QUEUE_NAME = "hello"; public static void main(String[] args) { ConnectionFactory factory = new ConnectionFactory(); factory.setHost("192.168.181.133"); factory.setVirtualHost("/"); factory.setUsername("root"); factory.setPassword("123456"); factory.setPort(5672); try (Connection conn = factory.newConnection(); Channel channel = conn.createChannel()) { channel.queueDeclare(QUEUE_NAME, false, false, true, null); String message = "Hello World!"; channel.basicPublish("", QUEUE_NAME, null, message.getBytes()); System.out.println(" [x] Sent '" + message + "'"); } catch (Exception e) { e.printStackTrace(); } } } -
消费者
@Slf4j public class HelloWorldReceiver { private final static String QUEUE_NAME = "hello"; public static void main(String[] argv) throws Exception { log.info("main"); // 连接工厂 ConnectionFactory factory = new ConnectionFactory(); // 设置服务器主机名或IP地址 factory.setHost("192.168.181.133"); // 设置Erlang的虚拟主机名称 factory.setVirtualHost("/"); // 设置用户名 factory.setUsername("root"); // 设置密码 factory.setPassword("123456"); // 设置客户端与服务器的通信端口,默认值为5672 factory.setPort(5672); // 获取连接 Connection connection = factory.newConnection(); // 从连接获取通道 Channel channel = connection.createChannel(); // 声明一个队列 // 第一个参数是队列名称 // 第二个参数false表示在rabbitmq-server重启后就没有了 // 第三个参数表示该队列不是一个排外队列,否则一旦客户端断开,队列就删除了 // 第四个参数表示该队列是否自动删除,true表示一旦不使用了,系统删除该队列 // 第五个参数表示该队列的参数,该参数是Map集合,用于指定队列的属性 // channel.queueDeclare(QUEUE_NAME, false, false, true, null); channel.queueDeclare(QUEUE_NAME, false, false, true, null); System.out.println(" [*] Waiting for messages. To exit press CTRL+C"); /* 使用服务器生成的consumerTag启动本地,非排他的使用者。 启动一个 仅提供了basic.deliver和basic.cancel AMQP方法(对大多数情形够用了) 参数: 第一个参数:队列名称 autoAck – true 只要服务器发送了消息就表示消息已经被消费者确认; false服务 端等待客户端显式地发送确认消息 deliverCallback – 服务端推送过来的消息回调函数 cancelCallback – 客户端忽略该消息的回调方法 返回: 服务端生成的consumerTag */ channel.basicConsume(QUEUE_NAME, true, (consumerTag, delivery) -> { log.info("deliverCallback"); String message = new String(delivery.getBody(), "UTF-8"); System.out.println(" [x] Received '" + message + "'"); }, consumerTag -> { log.info("cancelCallback"); }); } }
Connection 和 Channel 关系
生产者和消费者,需要与 RabbitMQ Broker 建立 TCP 连接,也就是 Connection 。一旦 TCP 连接建立起来,客户端紧接着创建一个 AMQP 信道( Channel ),每个信道都会被指派一个唯一的 ID 。信道是建立在 Connection 之上的虚拟连接, RabbitMQ 处理的每条 AMQP 指令都是通过信道完成的。
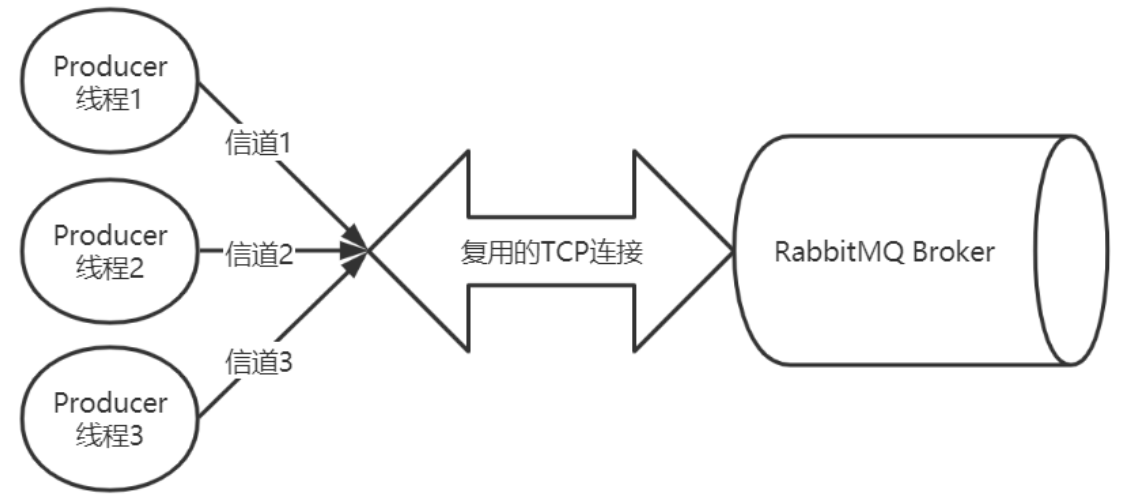
为什么不直接使用 TCP 连接,而是使用信道?
- RabbitMQ 采用类似 NIO 的做法,复用 TCP 连接,减少性能开销,便于管理
- 当每个信道的流量不是很大时,复用单一的
Connection可以在产生性能瓶颈的情况下有效地节省 TCP 连接资源 - 当信道本身的流量很大时,一个
Connection就会产生性能瓶颈,流量被限制。需要建立多个Connection,分摊信道。具体的调优看业务需要。 - 信道在 AMQP 中是一个很重要的概念,大多数操作都是在信道这个层面进行的。
- RabbitMQ 相关的 API 与 AMQP 紧密相连,比如
channel.basicPublish对应 AMQP 的Basic.Publish命令。
channel.exchangeDeclare
channel.queueDeclare
channel.basicPublish
channel.basicConsume
// ...
RabbitMQ 工作模式详解
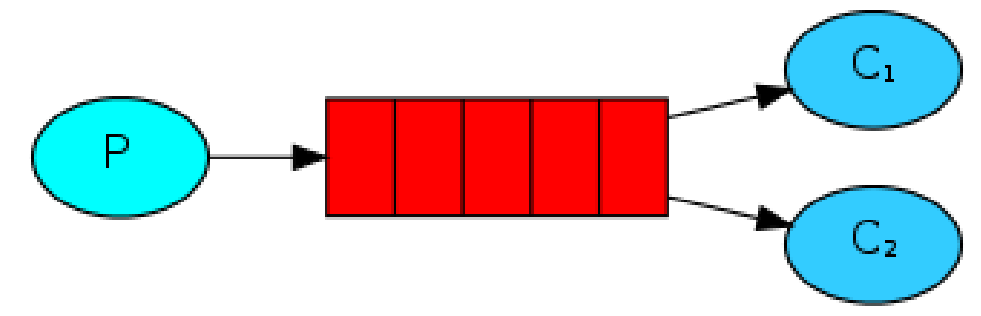
Work Queue
生产者发消息,启动多个消费者实例来消费消息,每个消费者仅消费部分信息,可达到负载均衡的效果。
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
public class NewTask {
private static final String QUEUE_NAME = "";
private static final String[] works = {"hello.", "hello..", "hello...", "hello....", "hello.....", "hello......", "hello.......", "hello........", "hello.........", "hello.........."};
public static void main(String[] args) {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.181.133");
factory.setVirtualHost("/");
factory.setUsername("root");
factory.setPassword("123456");
factory.setPort(5672);
try (Connection conn = factory.newConnection(); Channel channel = conn.createChannel()) {
channel.queueDeclare("taskQueue", false, false, false, null);
for (String work : works) {
// BuiltinExchangeType.DIRECT
// BuiltinExchangeType.FANOUT
// BuiltinExchangeType.HEADERS
// BuiltinExchangeType.TOPIC
// channel.exchangeDeclare("ex1", BuiltinExchangeType.DIRECT);
// 将消息路由到taskQueue队列
channel.basicPublish("", "taskQueue", null, work.getBytes("UTF-8"));
// channel.basicPublish("", "hello", MessageProperties.PERSISTENT_TEXT_PLAIN, work.getBytes());
System.out.println(" [x] Sent '" + work + "'");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
public class Worker {
private static final String TASK_QUEUE_NAME = "taskQueue";
public static void main(String[] args) throws IOException, TimeoutException {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.181.133");
factory.setVirtualHost("/");
factory.setUsername("root");
factory.setPassword("123456");
factory.setPort(5672);
// true表示不需要手动确认消息,false表示需要手动确认消息: channel.basicAck(xxx, yyy);
boolean autoAck = true;
Connection conn = factory.newConnection();
Channel channel = conn.createChannel();
// 预取指定个数的消息。此处每次获取一个消息
// channel.basicQos(1);
channel.queueDeclare(TASK_QUEUE_NAME, false, false, false, null);
channel.basicConsume(TASK_QUEUE_NAME, autoAck, (consumerTag, delivery) -> {
String task = new String(delivery.getBody(), "UTF-8");
System.out.println(" [x] Received '" + task + "'");
try {
doWork(task);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
System.out.println(" [x] Done");
// 手动确认消息
// channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
}
}, consumerTag -> {
});
}
private static void doWork(String task) throws InterruptedException {
System.out.println("task = " + task);
for (char ch : task.toCharArray()) {
if (ch == '.') {
Thread.sleep(1000);
}
}
}
}
发布订阅模式
使用 fanout 类型交换器, routingKey 忽略。每个消费者定义生成一个队列并绑定到同一个 Exchange ,每个消费者都可以消费到完整的消息。
消息广播给所有订阅该消息的消费者。
在RabbitMQ中,生产者不是将消息直接发送给消息队列,实际上生产者根本不知道一个消息被发送到哪个队列。
生产者将消息发送给交换器。交换器非常简单,从生产者接收消息,将消息推送给消息队列。交换器必须清楚地知道要怎么处理接收到的消息。应该是追加到一个指定的队列,还是追加到多个队列,还是丢弃。规则就是交换器类型。
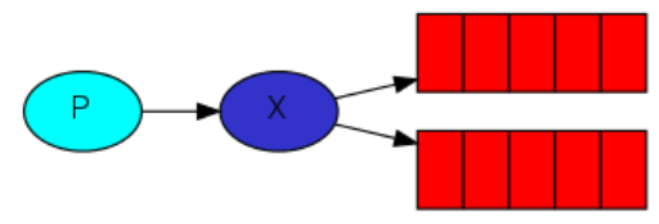
交换器的类型前面已经介绍过了: direct 、 topic 、 headers 和 fanout 四种类型。发布订阅使
用 fanout。
创建交换器,名字叫 logs :
channel.exchangeDeclare("logs", "fanout");
fanout 交换器很简单,从名字就可以看出来(用风扇吹出去),将所有收到的消息发送给它知道的所有的队列。
rabbitmqctl list_exchanges --formatter pretty_table
列出 RabbitMQ 的交换器,包括了 amq.* 的和默认的(未命名)的交换器。
未命名交换器:在前面的那里中我们没有指定交换器,但是依然可以向队列发送消息。这是因为我们使用了默认的交换器。
channel.basicPublish("", "hello", null, message.getBytes());
第一个参数就是交换器名称,为空字符串。直接使用 routingKey 向队列发送消息,如果该 routingKey 指定的队列存在的话。
现在,向指定的交换器发布消息:
channel.basicPublish("logs", "", null, message.getBytes());
临时队列
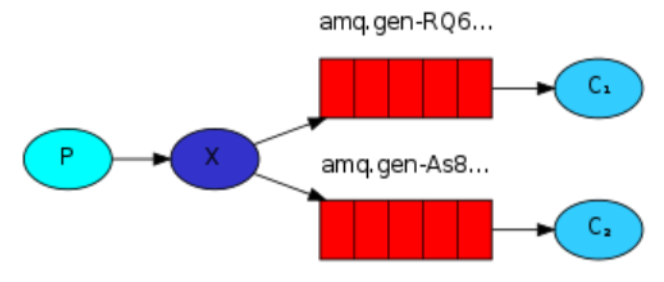
前面我们使用队列的名称,生产者和消费者都是用该名称来发送和接收该队列中的消息。
首先,我们无论何时连接 RabbitMQ 的时候,都需要一个新的,空的队列。我们可以使用随机的名字创建队列,也可以让服务器帮我们生成随机的消息队列名字。
其次,一旦我们断开到消费者的连接,该队列应该自动删除。
String queueName = channel.queueDeclare().getQueue();
上述代码我们声明了一个非持久化的、排他的、自动删除的队列,并且名字是服务器随机生成的。
queueName 一般的格式类似: amq.gen-JzTY20BRgKO-HjmUJj0wLg 。
绑定
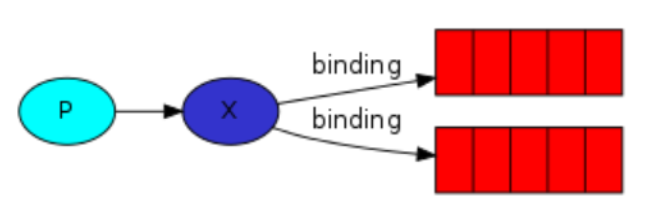
在创建了消息队列和 fanout 类型的交换器之后,我们需要将两者进行 绑定,让交换器将消息发送给该队列。
channel.queueBind(queueName, "logs", "");
此时, logs 交换器会将接收到的消息追加到我们的队列中。
可以使用下述命令列出 RabbitMQ 中交换器的绑定关系:
rabbitmqctl list_bindings --formatter pretty_table
发布订阅模式的整体代码如下:
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
public class EmitLog {
private static final String EXCHANGE_NAME = "logs";
public static void main(String[] argv) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.181.133");
factory.setVirtualHost("/");
factory.setUsername("root");
factory.setPassword("123456");
factory.setPort(5672);
try (Connection connection = factory.newConnection(); Channel channel = connection.createChannel()) {
channel.exchangeDeclare(EXCHANGE_NAME, "fanout");
String message = argv.length < 1 ? "info: Hello World!" : String.join(" ", argv);
channel.basicPublish(EXCHANGE_NAME, "", null, message.getBytes("UTF-8"));
System.out.println(" [x] Sent '" + message + "'");
}
}
}
public class ReceiveLogs {
private static final String EXCHANGE_NAME = "logs";
public static void main(String[] argv) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.181.133");
factory.setVirtualHost("/");
factory.setUsername("root");
factory.setPassword("123456");
factory.setPort(5672);
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare(EXCHANGE_NAME, "fanout");
String queueName = channel.queueDeclare().getQueue();
channel.queueBind(queueName, EXCHANGE_NAME, "");
System.out.println(" [*] Waiting for messages. To exit press CTRL+C");
channel.basicConsume(queueName, true, (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
System.out.println(" [x] Received '" + message + "'");
}, consumerTag -> {
});
}
}
当消费者启动起来之后,命令 rabbitmqctl list_bindings 列出绑定关系:
消息的推拉:实现 RabbitMQ 的消费者有两种模式,推模式( Push )和拉模式( Pull )。 实现推模式推荐的方式是继承 DefaultConsumer 基类,也可以使用 Spring AMQP 的 SimpleMessageListenerContainer 。 推模式是最常用的,但是有些情况下推模式并不适用的,比如说: 由于某些限制,消费者在某个条件成立时才能消费消息,需要批量拉取消息进行处理,实现拉模式,RabbitMQ 的 Channel 提供了 basicGet 方法用于拉取消息。
路由模式
使用 direct 类型的 Exchange ,发 N 条消费并使用不同的 routingKey ,消费者定义队列并将队列、 routingKey 、 Exchange 绑定。此时使用 direct 模式 Exchagne 必须要 routingKey 完全匹配的情况下消息才会转发到对应的队列中被消费。
上一个模式中,可以将消息广播到很多接收者。
现在我们想让接收者只接收部分消息,如,我们通过直接模式的交换器将关键的错误信息记录到 log 文件,同时在控制台正常打印所有的日志信息。
绑定
上一模式中,交换器的使用方式:
channel.queueBind(queueName, EXCHANGE_NAME, "");
绑定语句中还有第三个参数: routingKey :
channel.queueBind(queueName, EXCHANGE_NAME, "black");
bindingKey 的作用与具体使用的交换器类型有关。对于 fanout 类型的交换器,此参数设置无效,系统直接忽略。
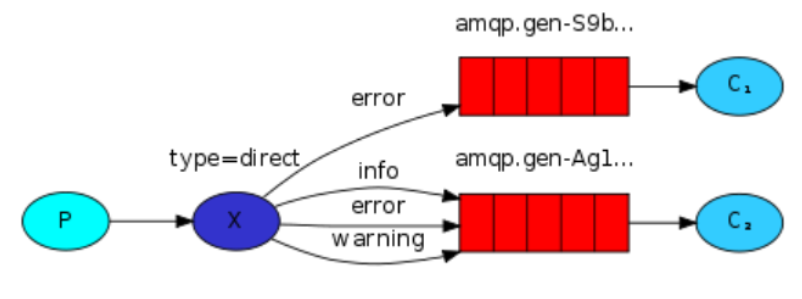
direct 交换器
分布式系统中有很多应用,这些应用需要运维平台的监控,其中一个重要的信息就是服务器的日志记录。
我们需要将不同日志级别的日志记录交给不同的应用处理。
如何解决?使用direct交换器
如果要对不同的消息做不同的处理,此时不能使用 fanout 类型的交换器,因为它只会盲目的广播消息。
我们需要使用 direct 类型的交换器。 direct 交换器的路由算法很简单:只要消息的 routingKey 和队列的 bindingKey 对应,消息就可以推送给该队列。
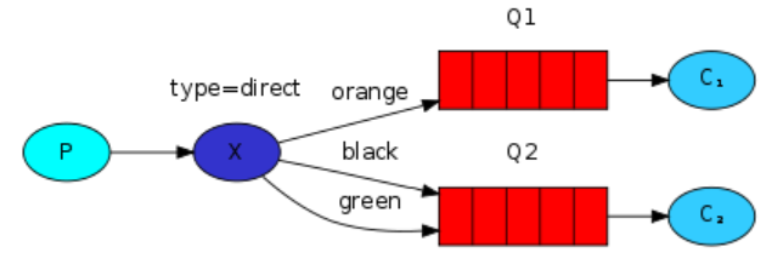
上图中的交换器 X 是 direct 类型的交换器,绑定的两个队列中,一个队列的 bindingKey 是 orange ,另一个队列的 bindingKey 是 black 和 green 。
如此,则 routingKey 是 orange 的消息发送给队列 Q1 , routingKey 是 black 和 green 的消息发送给 Q2 队列,其他消息丢弃。
多重绑定
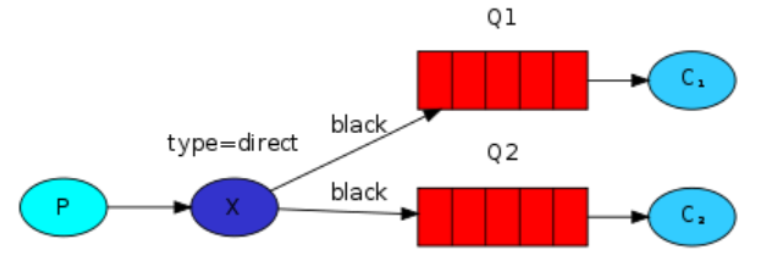
上图中,我们使用 direct 类型的交换器 X ,建立了两个绑定:队列 Q1 根据 bindingKey 的值 black 绑定到交换器 X ,队列 Q2 根据 bindingKey 的值 black 绑定到交换器 X ;交换器 X 会将消息发送给队列 Q1 和队列 Q2 。交换器的行为跟 fanout 的行为类似,也是广播。
在案例中,我们将日志级别作为 routingKey 。
// 消息生产者
public class EmitLogsDirect {
public static void main(String[] args) throws IOException, TimeoutException {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("node1");
factory.setVirtualHost("/");
factory.setUsername("root");
factory.setPassword("123456");
factory.setPort(5672);
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
String servrity = null;
// 声明direct类型的交换器logs
channel.exchangeDeclare("direct_logs", BuiltinExchangeType.DIRECT);
for (int i = 0; i < 100; i++) {
switch (i % 3) {
case 0:
servrity = "info";
break;
case 1:
servrity = "warn";
break;
case 2:
servrity = "error";
break;
default:
System.err.println("log错误,程序退出");
System.exit(-1);
}
String logStr = "这是 【" + servrity + "】 的消息 :: " + i;
channel.basicPublish("direct_logs", servrity, null, logStr.getBytes("UTF-8"));
}
}
}
// 消息消费者,消费 error 级别的日志
public class ReceiveErrorLogsDirect {
public static void main(String[] args) throws IOException, TimeoutException {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("node1");
factory.setVirtualHost("/");
factory.setUsername("root");
factory.setPassword("123456");
factory.setPort(5672);
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare("direct_logs", BuiltinExchangeType.DIRECT);
String queueName = channel.queueDeclare().getQueue();
System.out.println("queueName :: " + queueName);
// 将logs交换器和queueName队列通过bindingKey:error绑定
channel.queueBind(queueName, "direct_logs", "error");
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
System.out.println(" [x] Received '" + delivery.getEnvelope().getRoutingKey() + "':'" + message + "'");
};
channel.basicConsume(queueName, deliverCallback, consumerTag -> {
});
}
}
// 消息消费者,消费 warn 和 info 级别的日志
public class ReceiveWarnInfoLogsDirect {
public static void main(String[] args) throws IOException, TimeoutException {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("node1");
factory.setVirtualHost("/");
factory.setUsername("root");
factory.setPassword("123456");
factory.setPort(5672);
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare("direct_logs", BuiltinExchangeType.DIRECT);
String queueName = channel.queueDeclare().getQueue();
// 将logs交换器和queueName队列通过bindingKey:warn绑定
channel.queueBind(queueName, "direct_logs", "warn");
// 将logs交换器和queueName队列通过bindingKey:info绑定
channel.queueBind(queueName, "direct_logs", "info");
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
System.out.println(" [x] Received '" + delivery.getEnvelope().getRoutingKey() + "':'" + message + "'");
};
channel.basicConsume(queueName, deliverCallback, consumerTag -> {
});
}
}
主题模式
使用 topic 类型的交换器,队列绑定到交换器、 bindingKey 时使用通配符,交换器将消息路由转
发到具体队列时会根据消息 routingKey 模糊匹配,比较灵活。
上个模式中,我们通过 direct 类型的交换器做到了根据日志级别的不同,将消息发送给了不同队
列的。
这里有一个限制,假如现在我不仅想根据日志级别划分日志消息,还想根据日志来源划分日志,怎
么做?
比如,我想监听 cron 服务发送的 error 消息,又想监听从 kern 服务发送的所有消息。
此时可以使用 RabbitMQ 的主题模式( Topic )。
要想 topic 类型的交换器, routingKey 就不能随便写了,它必须得是点分单词。单词可以随便写,生产中一般使用消息的特征。如:“stock.usd.nyse”,“nyse.vmw”,“quick.orange.rabbit” 等。该点分单词字符串最长 255 字节。
bindingKey 也必须是这种形式。 topic 类型的交换器背后原理跟 direct 类型的类似:只要队列的 bindingKey 的值与消息的 routingKey 匹配,队列就可以收到该消息。有两个不同:
*匹配一个单词#匹配 0 到多个单词
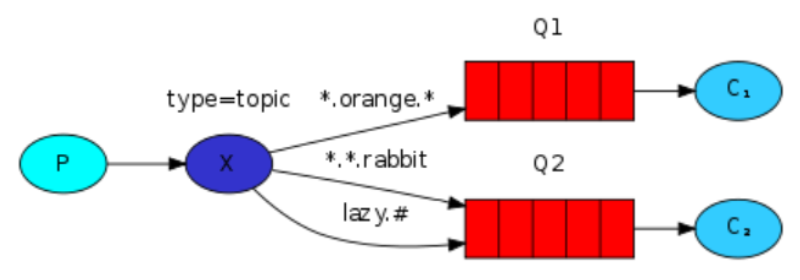
上图中,我们发送描述动物的消息。消息发送的时候指定的 routingKey 包含了三个词,两个点。第一个单词表示动物的速度,第二个是颜色,第三个是物种:<speed>.<color>.<species>。
创建三个绑定:Q1 绑定到 *.orange.* ,Q2 绑定到 *.*.rabbit 和 lazy.# :
- Q1 关注 orange 颜色动物的消息
- Q2 关注兔子的消息,以及所有懒的动物消息
如果不能匹配,就丢弃消息。
如果发送的消息 routingKey 是 lazy.orange.male.rabbit ,则会匹配最后一个绑定。
如果在 topic 类型的交换器中 bindingKey 使用 # ,则就是 fanout 类型交换器的行为。
如果在 topic 类型的交换器中 bindingKey 中不使用 * 和 # ,则就是 direct 类型交换器的行为。
// 生产者:随即生产 routingKey 和 message
public class EmitLogTopic {
private static final String EXCHANGE_NAME = "topic_logs";
private static final String[] SPEED = {"lazy", "quick", "normal"};
private static final String[] COLOR = {"black", "orange", "red", "yellow", "blue", "white", "pink"};
private static final String[] SPECIES = {"dog", "rabbit", "chicken", "horse", "bear", "cat"};
private static final Random RANDOM = new Random();
public static void main(String[] args) throws IOException, TimeoutException {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("node1");
factory.setVirtualHost("/");
factory.setUsername("root");
factory.setPassword("123456");
factory.setPort(5672);
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.TOPIC);
String message = null;
String routingKey = null;
String speed = null;
String color = null;
String species = null;
for (int i = 0; i < 10; i++) {
speed = SPEED[RANDOM.nextInt(SPEED.length)];
color = COLOR[RANDOM.nextInt(COLOR.length)];
species = SPECIES[RANDOM.nextInt(SPECIES.length)];
message = speed + "-" + color + "-" + species;
routingKey = speed + "." + color + "." + species;
System.out.println("routingKey :: " + routingKey + " , message :: " + message);
channel.basicPublish(EXCHANGE_NAME, routingKey, null, message.getBytes());
}
}
}
// 生产者,生成 routingKey 为 lazy.xx.xx 的 message
public class EmitLogTopic1 {
private static final String EXCHANGE_NAME = "topic_logs";
private static final String[] SPECIES = {"dog", "rabbit", "chicken", "horse", "bear", "cat"};
private static final Random RANDOM = new Random();
public static void main(String[] args) throws IOException, TimeoutException {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("node1");
factory.setVirtualHost("/");
factory.setUsername("root");
factory.setPassword("123456");
factory.setPort(5672);
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.TOPIC);
String message = null;
String routingKey = null;
String speed = null;
String species = null;
for (int i = 0; i < 10; i++) {
speed = "lazy";
species = SPECIES[RANDOM.nextInt(SPECIES.length)];
message = speed + "-" + species;
routingKey = speed + "." + species;
System.out.println("routingKey :: " + routingKey + " , message :: " + message);
channel.basicPublish(EXCHANGE_NAME, routingKey, null, message.getBytes());
}
}
}
// 消费者,消费 routingKey 为 *.*.rabbit 的 message
public class ReceiveLogsTopic {
private static final String EXCHANGE_NAME = "topic_logs";
public static void main(String[] args) throws IOException, TimeoutException {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("node1");
factory.setVirtualHost("/");
factory.setUsername("root");
factory.setPassword("123456");
factory.setPort(5672);
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.TOPIC);
String queueName = channel.queueDeclare().getQueue();
String routingKey = "*.*.rabbit";
channel.queueBind(queueName, EXCHANGE_NAME, routingKey);
DeliverCallback callback = (consumerTag, message) -> {
System.out.println(routingKey + " 匹配到的消息:" + new String(message.getBody(), "UTF-8"));
};
channel.basicConsume(queueName, true, callback, consumerTag -> {
});
}
}
// 消费者,消费 routingKey 为 *.*.rabbit 的 message
public class ReceiveLogsTopic1 {
private static final String EXCHANGE_NAME = "topic_logs";
public static void main(String[] args) throws IOException, TimeoutException {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("node1");
factory.setVirtualHost("/");
factory.setUsername("root");
factory.setPassword("123456");
factory.setPort(5672);
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.TOPIC);
String queueName = channel.queueDeclare().getQueue();
String routingKey = "*.orange.*";
channel.queueBind(queueName, EXCHANGE_NAME, routingKey);
DeliverCallback callback = (consumerTag, message) -> {
System.out.println(routingKey + " 匹配到的消息:" + new String(message.getBody(), "UTF-8"));
};
channel.basicConsume(queueName, true, callback, consumerTag -> {
});
}
}
// 消费者,消费 routingKey 为 *.*.rabbit 的 message
public class ReceiveLogsTopic2 {
private static final String EXCHANGE_NAME = "topic_logs";
public static void main(String[] args) throws IOException, TimeoutException {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("node1");
factory.setVirtualHost("/");
factory.setUsername("root");
factory.setPassword("123456");
factory.setPort(5672);
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.TOPIC);
String queueName = channel.queueDeclare().getQueue();
String routingKey = "lazy.*.*";
channel.queueBind(queueName, EXCHANGE_NAME, routingKey);
DeliverCallback callback = (consumerTag, message) -> {
System.out.println(routingKey + " 匹配到的消息:" + new String(message.getBody(), "UTF-8"));
};
channel.basicConsume(queueName, true, callback, consumerTag -> {
});
}
}
// 消费者,消费 routingKey 为 *.*.rabbit 的 message
public class ReceiveLogsTopic3 {
private static final String EXCHANGE_NAME = "topic_logs";
public static void main(String[] args) throws IOException, TimeoutException {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("node1");
factory.setVirtualHost("/");
factory.setUsername("root");
factory.setPassword("123456");
factory.setPort(5672);
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.TOPIC);
String queueName = channel.queueDeclare().getQueue();
String routingKey = "lazy.#";
channel.queueBind(queueName, EXCHANGE_NAME, routingKey);
DeliverCallback callback = (consumerTag, message) -> {
System.out.println(routingKey + " 匹配到的消息:" + new String(message.getBody(), "UTF-8"));
};
channel.basicConsume(queueName, true, callback, consumerTag -> {
});
}
}
Spring 整合 RabbitMQ
spring-amqp 是对 AMQP 的一些概念的一些抽象, spring-rabbit 是对 RabbitMQ 操作的封装实现。
主要有几个核心类 RabbitAdmin 、 RabbitTemplate 、 SimpleMessageListenerContainer 等
RabbitAdmin类完成对Exchange,Queue,Binding的操作,在容器中管理了RabbitAdmin类的时候,可以对Exchange,Queue,Binding进行自动声明。RabbitTemplate类是发送和接收消息的工具类。SimpleMessageListenerContainer是消费消息的容器。
目前比较新的一些项目都会选择基于注解方式,而比较老的一些项目可能还是基于配置文件的。
基于配置文件的整合
-
pom.xml
<dependency> <groupId>org.springframework.amqp</groupId> <artifactId>spring-rabbit</artifactId> <version>2.2.7.RELEASE</version> </dependency> -
rabbit-context.xml
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:rabbit="http://www.springframework.org/schema/rabbit" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/rabbit http://www.springframework.org/schema/rabbit/spring-rabbit.xsd"> <rabbit:connection-factory id="connectionFactory" host="node1" virtual-host="/" username="root" password="123456" port="5672"/> <!--创建一个 rabbit的 template对象 (org.springframework.amqp.rabbit.core.RabbitTemplate), 以便于访问 Broker--> <rabbit:template id="amqpTemplate" connection-factory="connectionFactory"/> <!-- 自动查找类型是Queue、Exchange、Binding 的 bean,并为用户向 RabbitMQ声明 --> <!-- 因此,我们不需要显式地在 java中声明 --> <rabbit:admin id="rabbitAdmin" connection-factory="connectionFactory"/> <!-- 为消费者创建一个队列,如果broker中存在,则使用同名存在的队列,否则创建一个新的。 --> <!-- 如果要发送消息,得使用交换器 --> <!-- 这里使用的是默认的交换器 --> <rabbit:queue name="myqueue" durable="true"/> <rabbit:direct-exchange name="direct.biz.ex" auto-declare="true" auto-delete="false" durable="true"> <rabbit:bindings> <!--exchange:其他绑定到该交换器的交换器名称--> <!--queue:绑定到该交换器的queue的bean名称--> <!--key:显式声明的路由key--> <rabbit:binding queue="myqueue" key="dir.ex"></rabbit:binding> </rabbit:bindings> </rabbit:direct-exchange> </beans> -
Java
public class App { public static void main(String[] args) throws IOException { AbstractApplicationContext context = new ClassPathXmlApplicationContext("classpath:rabbit-context.xml"); AmqpTemplate template = context.getBean(AmqpTemplate.class); for (int i = 0; i < 10; i++) { // 第一个参数是路由key,第二个参数是消息 template.convertAndSend("direct.biz.ex","dir.ex", "fooxml" + i); } //主动从队列拉取消息 String foo = (String) template.receiveAndConvert("myqueue"); System.out.println(foo); context.close(); } }
基于注解的整合
-
pom.xml
<dependency> <groupId>org.springframework.amqp</groupId> <artifactId>spring-rabbit</artifactId> <version>2.2.7.RELEASE</version> </dependency> -
Java
// 配置类 @Configuration public class RabbitConfiguration { @Bean public com.rabbitmq.client.ConnectionFactory rabbitFactory() { com.rabbitmq.client.ConnectionFactory rabbitFactory = new com.rabbitmq.client.ConnectionFactory(); rabbitFactory.setHost("node1"); rabbitFactory.setVirtualHost("/"); rabbitFactory.setUsername("root"); rabbitFactory.setPassword("123456"); rabbitFactory.setPort(5672); return rabbitFactory; } @Bean public ConnectionFactory connectionFactory(com.rabbitmq.client.ConnectionFactory rabbitFactory) { ConnectionFactory connectionFactory = new CachingConnectionFactory(rabbitFactory); return connectionFactory; } @Bean public AmqpAdmin amqpAdmin(ConnectionFactory factory) { AmqpAdmin amqpAdmin = new RabbitAdmin(factory); return amqpAdmin; } @Bean public RabbitTemplate rabbitTemplate(ConnectionFactory factory) { RabbitTemplate rabbitTemplate = new RabbitTemplate(factory); return rabbitTemplate; } @Bean public Queue queue() { Queue myqueue = new Queue("myqueue"); return myqueue; } }// 主启动类 public class App { public static void main(String[] args) { AbstractApplicationContext context = new AnnotationConfigApplicationContext(RabbitConfiguration.class); AmqpTemplate template = context.getBean(AmqpTemplate.class); template.convertAndSend("myqueue", "foo"); for (int i = 0; i < 1000; i++) { // 第一个参数是路由key,第二个参数是消息 template.convertAndSend("dir.ex", "foo" + i); } String foo = (String) template.receiveAndConvert("myqueue"); System.out.println(foo); context.close(); } }
SpringBoot 整合 RabbitMQ
-
pom.xml
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> </dependency> -
application.properties
spring.application.name=springboot_rabbitmq spring.rabbitmq.host=node1 spring.rabbitmq.virtual-host=/ spring.rabbitmq.username=root spring.rabbitmq.password=123456 spring.rabbitmq.port=5672 -
Java
// 配置类 @Configuration public class RabbitConfig { @Bean public Queue myQueue() { return new Queue("myqueue"); } @Bean public Exchange myExchange() { // new Exchange() // return new TopicExchange("topic.biz.ex", false, false, null); // return new DirectExchange("direct.biz.ex", false, false, null); // return new FanoutExchange("fanout.biz.ex", false, false, null); // return new HeadersExchange("header.biz.ex", false, false, null); // 交换器名称,交换器类型(),是否是持久化的,是否自动删除,交换器属性 Map 集合 // return new CustomExchange("custom.biz.ex", ExchangeTypes.DIRECT, false, false, null); return new DirectExchange("myex", false, false, null); } @Bean public Binding myBinding() { // 绑定的目的地,绑定的类型:到交换器还是到队列,交换器名称,路由key,绑定的属性 // new Binding("", Binding.DestinationType.EXCHANGE, "", "", null); // 绑定的目的地,绑定的类型:到交换器还是到队列,交换器名称,路由key, 绑定的属性 // new Binding("", Binding.DestinationType.QUEUE, "", "", null); // 绑定了交换器direct.biz.ex到队列myqueue,路由key是 direct.biz.ex return new Binding("myqueue", Binding.DestinationType.QUEUE, "myex", "direct.biz.ex", null); } }// web 接口,用于发送消息 @RestController public class HelloController { @Autowired private AmqpTemplate rabbitTemplate; @RequestMapping("/send/{message}") public String sendMessage(@PathVariable String message) { rabbitTemplate.convertAndSend("myex", "direct.biz.ex", message); return "ok"; } }// 消费者 @Component public class HelloConsumer { @RabbitListener(queues = "myqueue") public void service(String message) { System.out.println("消息队列推送来的消息:" + message); } }
RabbitMQ 高级特性解析
消息可靠性
你用支付宝给商家支付,如果是个仔细的人,会考虑我转账的话,会不会把我的钱扣了,商家没有收到我的钱?
一般我们使用支付宝或微信转账支付的时候,都是扫码,支付,然后立刻得到结果,说你支付了多少钱,如果你绑定的是银行卡,可能这个时候你并没有收到支付的确认消息。往往是在一段时间之后,你会收到银行卡发来的短信,告诉你支付的信息。
支付平台如何保证这笔帐不出问题?
支付平台必须保证数据正确性,保证数据并发安全性,保证数据最终一致性。
支付平台通过如下几种方式保证数据一致性:
-
分布式锁
这个比较容易理解,就是在操作某条数据时先锁定,可以用 Redis 或 ZooKeeper 等常用框架来实现。 比如我们在修改账单时,先锁定该账单,如果该账单有并发操作,后面的操作只能等待上一个操作的锁释放后再依次执行。
优点:能够保证数据强一致性。
缺点:高并发场景下可能有性能问题。
-
消息队列
消息队列是为了保证最终一致性,我们需要确保消息队列有 ACK 机制,客户端收到消息并消费处理完成后,客户端发送 ACK 消息给消息中间件,如果消息中间件超过指定时间还没收到 ACK 消息,则定时去重发消息。
比如我们在用户充值完成后,会发送充值消息给账户系统,账户系统再去更改账户余额。
优点:异步、高并发
缺点:有一定延时、数据弱一致性,并且必须能够确保该业务操作肯定能够成功完成,不可能失败。
我们可以从以下几方面来保证消息的可靠性:
- 客户端代码中的异常捕获,包括生产者和消费者
- AMQP/RabbitMQ 的事务机制
- 发送端确认机制
- 消息持久化机制
- Broker 端的高可用集群
- 消费者确认机制
- 消费端限流
- 消息幂等性
异常捕获机制
先执行行业务操作,业务操作成功后执行行消息发送,消息发送过程通过 try catch 方式捕获异常,在异常处理理的代码块中执行行回滚业务操作或者执行行重发操作等。这是一种最大努力确保的方式,并无法保证 100% 绝对可靠,因为这里没有异常并不代表消息就一定投递成功。
另外,可以通过 spring.rabbitmq.template.retry.enabled=true 配置开启发送端的重试
AMQP/RabbitMQ 的事务机制
没有捕获到异常并不能代表消息就一定投递成功了。
一直到事务提交后都没有异常,确实就说明消息是投递成功了。但是,这种方式在性能方面的开销比较大,一般也不推荐使用。
发送端确认机制
RabbitMQ 后来引入了一种轻量量级的方式,叫发送方确认( publisher confirm )机制。生产者将信道设置成 confirm (确认)模式,一旦信道进入 confirm 模式,所有在该信道上面面发布的消息都会被指派一个唯一的 ID (从 1 开始),一旦消息被投递到所有匹配的队列之后(如果消息和队列是持久化的,那么确认消息会在消息持久化后发出), RabbitMQ 就会发送一个确认( Basic.Ack )给生产者(包含消息的唯一 ID ),这样生产者就知道消息已经正确送达了。
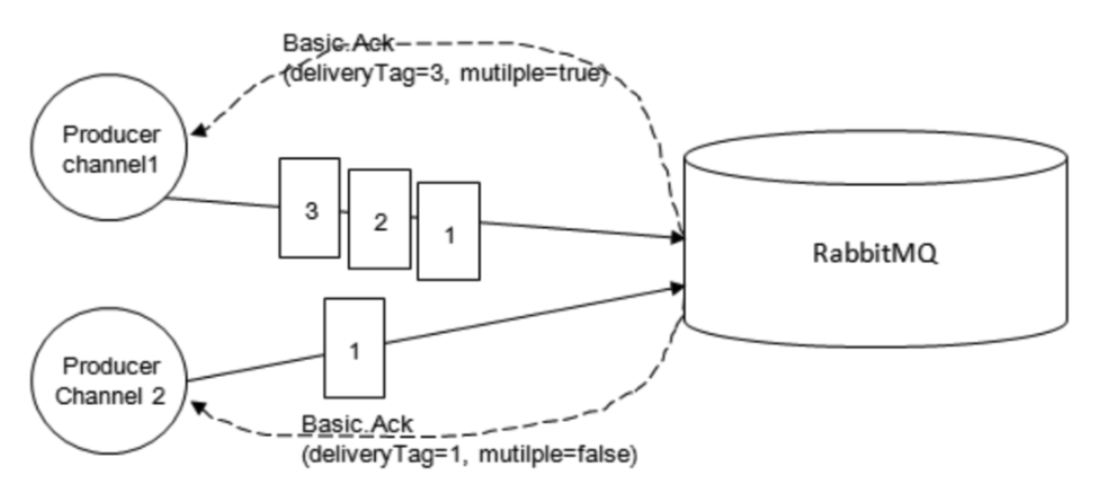
RabbitMQ 回传给生产者的确认消息中的 deliveryTag 字段包含了确认消息的序号,另外,通过设置 channel.basicAck 方法中的 multiple 参数,表示到这个序号之前的所有消息是否都已经得到了处理了。生产者投递消息后并不需要一直阻塞着,可以继续投递下一条消息并通过回调方式处理 ACK 响应。如果 RabbitMQ 因为自身内部错误导致消息丢失等异常情况发生,就会响应一条 nack( Basic.Nack )命令,生产者应用程序同样可以在回调方法中处理该 nack 命令。
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
// Publisher Confirms
channel.confirmSelect();
channel.exchangeDeclare(EX_PUBLISHER_CONFIRMS, BuiltinExchangeType.DIRECT);
channel.queueDeclare(QUEUE_PUBLISHER_CONFIRMS, false, false, false, null);
channel.queueBind(QUEUE_PUBLISHER_CONFIRMS, EX_PUBLISHER_CONFIRMS,QUEUE_PUBLISHER_CONFIRMS);
String message = "hello";
channel.basicPublish(EX_PUBLISHER_CONFIRMS, QUEUE_PUBLISHER_CONFIRMS, null, message.getBytes());
try {
channel.waitForConfirmsOrDie(5_000);
System.out.println("消息被确认:message = " + message);
} catch (IOException e) {
e.printStackTrace();
System.err.println("消息被拒绝! message = " + message);
} catch (InterruptedException e) {
e.printStackTrace();
System.err.println("在不是Publisher Confirms的通道上使用该方法");
} catch (TimeoutException e) {
e.printStackTrace();
System.err.println("等待消息确认超时! message = " + message);
}
waitForConfirm 方法有个重载的,可以自定义 timeout 超时时间,超时后会抛 TimeoutException 。类似的有几个 waitForConfirmsOrDie 方法, Broker 端在返回 nack ( Basic.Nack )之后该方法会抛出 java.io.IOException 。需要根据异常类型来做区别处理理, TimeoutException 超时是属于第三状态(无法确定成功还是失败),而返回 Basic.Nack 抛出 IOException 这种是明确的失败。上面的代码主要只是演示 confirm 机制,实际上还是同步阻塞模式的,性能并不不是太好。
实际上,我们也可以通过 批处理 的方式来改善整体的性能(即批量量发送消息后仅调用一次 waitForConfirms 方法)。正常情况下这种批量处理的方式效率会高很多,但是如果发生了超时或者 nack (失败)后那就需要批量重发消息或者通知上游业务批量回滚(因为我们只知道这个批次中有消息没投递成功,而并不知道具体是那条消息投递失败了,所以很难针对性处理),如此看来,批量重发消息肯定会造成部分消息重复。另外,我们可以通过异步回调的方式来处理 Broker 的响应。 addConfirmListener 方法可以添加 ConfirmListener 这个回调接口,这个 ConfirmListener 接口包含两个方法: handleAck 和 handleNack ,分别用来处理 RabbitMQ 回传的 Basic.Ack 和 Basic.Nack 。
SpringBoot 案例
-
pom.xml
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> </dependency> -
application.properties
spring.application.name=publisherconfirm spring.rabbitmq.host=node1 spring.rabbitmq.virtual-host=/ spring.rabbitmq.username=root spring.rabbitmq.password=123456 spring.rabbitmq.port=5672 spring.rabbitmq.publisher-confirm-type=correlated spring.rabbitmq.publisher-returns=true -
Java
// 配置类 @Configuration public class RabbitConfig { @Bean public Queue queue() { Queue queue = new Queue("q.biz", false, false, false, null); return queue; } @Bean public Exchange exchange() { Exchange exchange = new DirectExchange("ex.biz", false, false, null); return exchange; } @Bean public Binding binding() { return BindingBuilder.bind(queue()).to(exchange()).with("biz").noargs(); } }// web 接口 @RestController public class BizController { private RabbitTemplate rabbitTemplate; @Autowired public void setRabbitTemplate(RabbitTemplate rabbitTemplate) { this.rabbitTemplate = rabbitTemplate; this.rabbitTemplate.setConfirmCallback((correlationData, flag, cause) -> { if (flag) { try { System.out.println("消息确认:" + correlationData.getId() + " " + new String(correlationData.getReturned().getMessage().getBody(), "utf-8")); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } } else { System.out.println(cause); } }); } @RequestMapping("/biz") public String doBiz() throws UnsupportedEncodingException { MessageProperties props = new MessageProperties(); props.setCorrelationId("1234"); props.setConsumerTag("msg1"); props.setContentType(MessageProperties.CONTENT_TYPE_TEXT_PLAIN); props.setContentEncoding("utf-8"); // props.setDeliveryMode(MessageDeliveryMode.NON_PERSISTENT); // 1 // props.setDeliveryMode(MessageDeliveryMode.PERSISTENT); // 2 CorrelationData cd = new CorrelationData(); cd.setId("msg1"); cd.setReturnedMessage(new Message("这是msg1的响应".getBytes("utf-8"), null)); Message message = new Message("这是等待确认的消息".getBytes("utf-8"), props); rabbitTemplate.convertAndSend("ex.biz", "biz", message, cd); return "ok"; } @RequestMapping("/bizfalse") public String doBizFalse() throws UnsupportedEncodingException { MessageProperties props = new MessageProperties(); props.setCorrelationId("1234"); props.setConsumerTag("msg1"); props.setContentType(MessageProperties.CONTENT_TYPE_TEXT_PLAIN); props.setContentEncoding("utf-8"); Message message = new Message("这是等待确认的消息".getBytes("utf-8"), props); rabbitTemplate.convertAndSend("ex.bizFalse", "biz", message); return "ok"; } }
持久化存储机制
持久化是提高 RabbitMQ 可靠性的基础,否则当 RabbitMQ 遇到异常时(如:重启、断电、停机等)数据将会丢失。主要从以下几个方面来保障消息的持久性:
Exchange的持久化。通过定义时设置durable参数为ture来保证Exchange相关的元数据不不丢失Queue的持久化。也是通过定义时设置durable参数为ture来保证Queue相关的元数据不不丢失- 消息的持久化。通过将消息的投递模式 (
BasicProperties中的deliveryMode属性)设置为2即可实现消息的持久化,保证消息自身不丢失
RabbitMQ 中的持久化消息都需要写入磁盘(当系统内存不不足时,非持久化的消息也会被刷盘处理理),这些处理理动作都是在“持久层”中完成的。持久层是一个逻辑上的概念,实际包含两个部分:
- 队列索引(
rabbit_queue_index),rabbit_queue_index负责维护Queue中消息的信息,包括消息的存储位置、是否已交给消费者、是否已被消费及 ACK 确认等,每个Queue都有与之对应的rabbit_queue_index - 消息存储(
rabbit_msg_store),rabbit_msg_store以键值对的形式存储消息,它被所有队列列共享,在每个节点中有且只有一个
/var/lib/rabbitmq/mnesia/rabbit@HOSTNAME/msg_stores/vhosts/$VHostId
这个路路径下包含 queues、msg_store_persistent、msg_store_transient 这 3 个目录,这是实际存储消息的位置。其中 queues 目录中保存着 rabbit_queue_index 相关的数据,而 msg_store_persistent 保存着持久化消息数据, msg_store_transient 保存着非持久化相关的数据。
另外, RabbitMQ 通过配置 queue_index_embed_msgs_below 可以根据消息大小决定存储位置,默认 queue_index_embed_msgs_below 是 4096 字节(包含消息体、属性及 headers ),小于该值的消息存在 rabbit_queue_index 中。
Consumer ACK
如何保证消息被消费者成功消费?
前面我们讲了生产者发送确认机制和消息的持久化存储机制,然而这依然无法完全保证整个过程的可靠性,因为如果消息被消费过程中业务处理失败了但是消息却已经出列了(被标记为已消费了),我们又没有任何重试,那结果跟消息丢失没什么分别。
RabbitMQ 在消费端会有 ACK 机制,即消费端消费消息后需要发送 ACK 确认报文给 Broker 端,告知自己是否已消费完成,否则可能会一直重发消息直到消息过期( AUTO 模式)。
这也是我们之前一直在讲的“最终一致性”、“可恢复性” 的基础。
一般而言,我们有如下处理手段:
- 采用
NONE模式,消费的过程中自行捕获异常,引发异常后直接记录日志并落到异常恢复表,再通过后台定时任务扫描异常恢复表尝试做重试动作。如果业务不自行处理则有丢失数据的风险 - 采用
AUTO(自动 ACK )模式,不主动捕获异常,当消费过程中出现异常时会将消息放回Queue中,然后消息会被重新分配到其他消费者节点(如果没有则还是选择当前节点)重新被消费,默认会一直重发消息并直到消费完成返回 ACK 或者一直到过期 - 采用
MANUAL(手动 ACK )模式,消费者自行控制流程并手动调用channel相关的方法返回 ACK
/**
* NONE模式,则只要收到消息后就立即确认(消息出列,标记已消费),有丢失数据的风险
* AUTO模式,看情况确认,如果此时消费者抛出异常则消息会返回到队列中
* MANUAL模式,需要显式的调用当前channel的basicAck方法
*
* @param channel
* @param deliveryTag
* @param message
*/
@RabbitListener(queues = "q.biz", ackMode = "AUTO")
public void handleMessageTopic(Channel channel, @Header(AmqpHeaders.DELIVERY_TAG) long deliveryTag, @Payload String message) {
System.out.println("RabbitListener 消费消息,消息内容:" + new String((message)));
try {
// 手动ack,deliveryTag表示消息的唯一标志,multiple表示是否是批量确认
channel.basicAck(deliveryTag, false);
// 手动nack,告诉broker消费者处理失败,最后一个参数表示是否需要将消息重新入列
// channel.basicNack(deliveryTag, false, true);
// 手动拒绝消息。第二个参数表示是否重新入列
// channel.basicReject(deliveryTag, true);
} catch (IOException e) {
e.printStackTrace();
}
}
上面是通过在消费端直接配置指定 ackMode ,在一些比较老的 Spring 项目中一般是通过 XML 方式去定义、声明和配置的,不管是 XML 还是注解,相关配置、属性这些其实都是大同小异,触类旁通。然后需要注意的是 channel.basicACK 这几个手工 ACK 确认的方法。
SpringBoot 项目中支持如下的一些配置:
#最大重试次数
spring.rabbitmq.listener.simple.retry.max-attempts=5
#是否开启消费者重试(为false时关闭消费者重试,意思不是“不重试”,而是一直收到消息直到jack确认或者一直到超时)
spring.rabbitmq.listener.simple.retry.enabled=true
#重试间隔时间(单位毫秒)
spring.rabbitmq.listener.simple.retry.initial-interval=5000
# 重试超过最大次数后是否拒绝
spring.rabbitmq.listener.simple.default-requeue-rejected=false
#ack模式
spring.rabbitmq.listener.simple.acknowledge-mode=manual
本小节的内容总结起来就如图所示,本质上就是“请求/应答”确认模式
消费端限流
在电商的秒杀活动中,活动一开始会有大量并发写请求到达服务端,需要对消息进行削峰处理,如何削峰?
当消息投递速度远快于消费速度时,随着时间积累就会出现 消息积压 。消息中间件本身是具备一定的缓冲能力的,但这个能力是 有容量限制 的,如果长期运行并没有任何处理,最终会导致Broker崩溃,而分布式系统的故障往往会发生上下游传递,连锁反应那就会很悲剧...
下面我将从多个角度介绍 QoS 与限流,防止上面的悲剧发生:
-
RabbitMQ 可以对内存和磁盘使用量设置阈值,当达到阈值后,生产者将被阻塞( block ),直到对应项指标恢复正常。全局上可以防止超大流量、消息积压等导致的 Broker 被压垮。当内存受限或磁盘可用空间受限的时候,服务器都会暂时阻止连接,服务器将暂停从发布消息的已连接客户端的套接字读取数据。连接心跳监视也将被禁用。所有网络连接将在
rabbitmqctl和管理插件中显示为“已阻止”,这意味着它们尚未尝试发布,因此可以继续或被阻止,这意味着它们已发布,现在已暂停。兼容的客户端被阻止时将收到通知。在
/etc/rabbitmq/rabbitmq.conf中可以配置磁盘可用空间大小:disk_free_limit.absolute = 2GB -
RabbitMQ 还默认提供了一种基于 credit flow 的 流控机制,面向每一个连接进行流控。当单个队列达到最大流速时,或者多个队列达到总流速时,都会触发流控。触发单个链接的流控可能是因为
Connection、Channel、Queue的某一个过程处于 flow 状态,这些状态都可以从监控平台看到 -
RabbitMQ 中有一种 QoS 保证机制,可以 限制
Channel上接收到的未被 ACK 的消息数量,如果超过这个数量限制 RabbitMQ 将不会再往消费端推送消息。这是一种流控手段,可以防止大量消息瞬时从 Broker 送达消费端造成消费端巨大压力(甚至压垮消费端)。比较值得注意的是 QoS 机制仅对于消费端推模式有效,对拉模式无效。而且不支持 NONE ACK 模式。执行channel.basicConsume方法之前通过channel.basicQoS方法可以设置该数量。消息的发送是异步的,消息的确认也是异步的。在消费者消费慢的时候,可以设置 QoS 的prefetchCount,它表示 Broker 在向消费者发送消息的时候,一旦发送了prefetchCount个消息而没有一个消息确认的时候,就停止发送。消费者确认一个, Broker 就发送一个,确认两个就发送两个。换句话说,消费者确认多少, Broker 就发送多少,消费者等待处理的个数永远限制在prefetchCount个如果对于每个消息都发送确认,增加了网络流量,此时可以批量确认消息。如果设置了
multiple为true,消费者在确认的时候,比如说 id 是 8 的消息确认了,则在 8 之前的所有消息都确认了
生产者往往是希望自己产生的消息能快速投递出去,而当消息投递太快且超过了下游的消费速度时就容易出现消息积压/堆积,所以,从上游来讲我们应该在生产端应用程序中也可以加入限流、应急开关等控制手段,避免超过 Broker 端的极限承载能力或者压垮下游消费者。
再看看下游,我们期望下游消费端能尽快消费完消息,而且还要防止瞬时大量消息压垮消费端(推模式),我们期望消费端处理速度是最快、最稳定而且还相对均匀(比较理想化)。提升下游应用的吞吐量和缩短消费过程的耗时,优化主要以下几种方式:
- 优化应用程序的性能,缩短响应时间(需要时间)
- 增加消费者节点实例(成本增加,而且底层数据库操作这些也可能是瓶颈)
- 调整并发消费的线程数(线程数并非越大越好,需要大量压测调优至合理值)
@Bean
public RabbitListenerContainerFactory rabbitListenerContainerFactory(ConnectionFactory connectionFactory) {
// SimpleRabbitListenerContainerFactory发现消息中有content_type有text就会默认将其转换为String类型的,没有content_type都按byte[]类型
SimpleRabbitListenerContainerFactory factory = new
SimpleRabbitListenerContainerFactory();
factory.setConnectionFactory(connectionFactory);
// 设置并发线程数
factory.setConcurrentConsumers(10);
// 设置最大并发线程数
factory.setMaxConcurrentConsumers(20);
return factory;
}
消息可靠性保障
在讲高级特性的时候几乎已经都涉及到了,这里简单回顾总结下:
- 消息传输保障
- 各种限流、应急手段
- 业务层面的一些容错、补偿、异常重试等手段
消息可靠传输 一般是业务系统接入消息中间件时 首要考虑的问题 ,一般消息中间件的消息传输保障分为三个层级:
- At most once:最多一次。消息可能会丢失,但绝不会重复传输
- At least once:最少一次。消息绝不会丢失,但可能会重复传输
- Exactly once:恰好一次。每条消息肯定会被传输一次且仅传输一次
RabbitMQ 支持其中的 最多一次 和 最少一次 。
其中 最少一次 投递实现需要考虑以下这个几个方面的内容:
- 消息生产者需要开启事务机制或者 publisher confirm 机制,以确保消息可以可靠地传输到 RabbitMQ 中
- 消息生产者需要配合使用 mandatory 参数或者备份交换器来确保消息能够从交换器路由到队列中,进而能够保存下来而不会被丢弃
- 消息和队列都需要进行持久化处理,以确保 RabbitMQ 服务器在遇到异常情况时不会造成消息丢失
- 消费者在消费消息的同时需要将
autoAck设置为false,然后通过手动确认的方式去确认已经正确消费的消息,以避免在消费端引起不必要的消息丢失
最多一次 的方式就无须考虑以上那些方面,生产者随意发送,消费者随意消费,不过这样很难确保消息不会丢失。(估计有不少公司的业务系统都是这样的,想想都觉得可怕)
恰好一次 是 RabbitMQ 目前无法保障的。
考虑这样一种情况,消费者在消费完一条消息之后向 RabbitMQ 发送确认 Basic.Ack 命令,此时由于网络断开或者其他原因造成 RabbitMQ 并没有收到这个确认命令,那么 RabbitMQ 不会将此条消息标记删除。在重新建立连接之后,消费者还是会消费到这一条消息,这就造成了 重复消费 。
再考虑一种情况,生产者在使用 publisher confirm 机制的时候,发送完一条消息等待 RabbitMQ 返回确认通知,此时网络断开,生产者捕获到异常情况,为了确保消息可靠性选择重新发送,这样 RabbitMQ 中就有两条同样的消息,在消费的时候消费者就会重复消费。
消息幂等性处理
刚刚我们讲到,追求高性能就无法保证消息的顺序,而追求可靠性那么就可能产生重复消息,从而导致重复消费。真是应证了那句老话:做架构就是权衡取舍。
RabbitMQ层面有实现 去重机制 来保证 恰好一次 吗?答案是并 没有 。而且这个在目前主流的消息中间件都没有实现。
借用淘宝沈洵的一句话:最好的解决办法就是不去解决。当为了在基础的分布式中间件中实现某种相对不太通用的功能,需要牺牲到性能、可靠性、扩展性时,并且会额外增加很多复杂度,最简单的办法就是 交给业务自己去处理 。事实证明,很多业务场景下是可以容忍重复消息的。例如:操作日志收集,而对一些金融类的业务则要求比较严苛。
一般解决重复消息的办法是,在消费端让我们消费消息的操作具备幂等性。
幂等性问题并不是消息系统独有,而是(分布式)系统中普遍存在的问题。例如: RPC 框架调用超后会重试, HTTP 请求会重复发起(用户手抖多点了几下按钮)
幂等(Idempotence)是一个数学上的概念,它是这样定义的:如果一个函数 f(x) 满足:f(f(x)) = f(x) ,则函数 f(x) 满足幂等性。这个概念被拓展到计算机领域,被用来描述一个操作、方法或者服务。
一个幂等操作的特点是,其任意多次执行所产生的影响均与一次执行的影响相同。一个幂等的方法,使用同样的参数,对它进行多次调用和一次调用,对系统产生的影响是一样的。
对于幂等的方法,不用担心重复执行会对系统造成任何改变。
举个简单的例子(在不考虑并发问题的情况下):
select * from xx where id=1
delete from xx where id=1
这两条 sql 语句就是天然幂等的,它本身的重复执行并不会引起什么改变。而 update 就要看情况的:
update xxx set amount = 100 where id =1
这条语句执行 1 次和 100 次都是一样的结果(最终余额都还是 100 ),所以它是满足幂等性的。而下面这条 sql 它就不满足幂等性的:
update xxx set amount = amount + 100 where id =1
业界对于幂等性的一些常见做法:
- 借助 数据库唯一索引,重复插入直接报错,事务回滚。还是举经典的转账的例子,为了保证不重复扣款或者重复加钱,我们这边维护一张“资金变动流水表”,里面至少需要交易单号、变动账户、变动金额等 3 个字段。我们选择交易单号和变动账户做联合唯一索引(单号是上游生成的可保证唯一性),这样如果同一笔交易发生重复请求时就会直接报索引冲突,事务直接回滚。现实中,数据库唯一索引的方式通常做为兜底保证;
- 前置检查机制 。这个很容易理解,并且有几种实现办法。还是引用上面转账的例子,当我在执行更改账户余额这个动作之前,我得先检查下资金变动流水表(或者 Tair 中)中是否已经存在这笔交易相关的记录了,
select * from xxx where accountNumber=xxx and orderId=yyy,如果已经存在,那么直接返回,否则执行正常的更新余额的动作。为了防止并发问题,我们通常需要借助 排他锁 来完成。在支付宝有一条铁律叫:一锁、二判、三操作。当然,我们 也可以使用乐观锁或 CAS 机制 ,乐观锁一般会使用扩展一个版本号字段做判断条件 - 唯一 ID 机制 ,比较通用的方式。对于每条消息我们都可以生成唯一 ID ,消费前判断 Tair 中是否存在( MsgId 做 Tair 排他锁的 key ),消费成功后将状态写入 Tair 中,这样就可以防止重复消费了。
对于接口请求类的幂等性保证要相对更复杂,我们通常要求上游请求时传递一个类 GUID 的请求号( 或 TOKEN ),如果我们发现已经存在了并且上一次请求处理结果是成功状态的(有时候上游的重试请求是正常诉求,我们不能将上一次异常/失败的处理结果返回或者直接提示“请求异常”,如果这样重试就变得没意义了)则不继续往下执行,直接返回“重复请求”的提示和上次的处理结果(上游通常是由于请求超时等未知情况才发起重试的,所以直接返回上次请求的处理结果就好了)。如果请求 ID 都不存在或者上次处理结果是失败/异常的,那就继续处理流程,并最终记录最终的处理结果。这个请求序号由上游自己生成,上游通用需要根据请求参数、时间间隔等因子来生成请求 ID 。同样也需要利用这个请求 ID 做分布式锁的 KEY 实现排他。
可靠性分析
在使用任何消息中间件的过程中,难免会出现消息丢失等异常情况,这个时候就需要有一个良好的机制来跟踪记录消息的过程(轨迹溯源),帮助我们排查问题。
在 RabbitMQ 中可以使用 Firehose 功能来实现消息追踪, Firehose 可以记录每一次发送或者消费消息的记录,方便 RabbitMQ 的使用者进行调试、排错等。
Firehose 的原理是将生产者投递给 RabbitMQ 的消息,或者 RabbitMQ 投递给消费者的消息按照指定的格式发送到默认的交换器上。这个默认的交换器的名称为 amq.rabbitmq.trace ,它是一个 topic 类型的交换器。发送到这个交换器上的消息的路由键为 publish.{exchangename} 和 delive.{queuename} 。其中 exchangename 和 queuename 为交换器和队列的名称,分别对应生产者投递到交换器的消息和消费者从队列中获取的消息。
开启 Firehose 命令:
rabbitmqctl trace_on [-p vhost]
其中 [-p vhost] 是可选参数,用来指定虚拟主机 vhost 。
对应的关闭命令为:
rabbitmqctl trace_off [-p vhost]
Firehose 默认情况下处于 关闭状态 ,并且 Firehose 的状态是 非持久化 的,会在 RabbitMQ 服务重启的时候还原成默认的状态。Firehose 开启之后多少 会影响 RabbitMQ 整体服务性能,因为它会引起额外的消息生成、路由和存储。
rabbitmq_tracing 插件相当于 Firehose 的 GUI 版本,它同样能跟踪 RabbitMQ 中消息的流入流出情况。rabbitmq_tracing 插件同样会对流入流出的消息进行封装,然后 将封装后的消息日志存入相应的 trace 文件中。
可以使用命令来启动 rabbitmq_tracing 插件:
rabbitmq-plugins enable rabbitmq_tracing
使用命令关闭该插件:
rabbitmq-plugins disable rabbitmq_tracing
TTL 机制
在京东下单,订单创建成功,等待支付,一般会给 30 分钟的时间,开始倒计时。如果在这段时间内用户没有支付,则默认订单取消。该如何实现?
-
定期轮询(数据库等)
- 用户下单成功,将订单信息放入数据库,同时将支付状态放入数据库,用户付款更改数据库状态。定期轮询数据库支付状态,如果超过 30 分钟就将该订单取消
- 优点:设计实现简单
- 缺点:需要对数据库进行大量的IO操作,效率低下。
-
TimerSimpleDateFormat simpleDateFormat = new SimpleDateFormat("HH:mm:ss"); Timer timer = new Timer(); TimerTask timerTask = new TimerTask() { @Override public void run() { System.out.println("用户没有付款,交易取消:" + simpleDateFormat.format(new Date(System.currentTimeMillis()))); timer.cancel(); } }; System.out.println("等待用户付款:" + simpleDateFormat.format(new Date(System.currentTimeMillis()))); // 10秒后执行timerTask timer.schedule(timerTask, 10 * 1000); -
缺点:
Timer没有持久化机制.Timer不灵活 (只可以设置开始时间和重复间隔,对等待支付貌似够用)Timer不能利用线程池,一个Timer一个线程Timer没有真正的管理计划
-
ScheduledExecutorServiceSimpleDateFormat format = new SimpleDateFormat("HH:mm:ss"); // 线程工厂 ThreadFactory factory = Executors.defaultThreadFactory(); // 使用线程池 ScheduledExecutorService service = new ScheduledThreadPoolExecutor(10, factory); System.out.println("开始等待用户付款10秒:" + format.format(new Date())); service.schedule(new Runnable() { @Override public void run() { System.out.println("用户未付款,交易取消:" + format.format(new Date())); }// 等待10s 单位秒 }, 10, TimeUnit.SECONDS);- 优点:可以多线程执行,一定程度上避免任务间互相影响,单个任务异常不影响其它任务
- 在高并发的情况下,不建议使用定时任务去做,因为太浪费服务器性能,不建议
-
RabbitMQ
- 使用 TTL
-
Quartz
-
Redis Zset
-
JCronTab
-
SchedulerX
-
。。。
TTL ,Time to Live 的简称,即过期时间。
RabbitMQ 可以 对消息和队列两个维度来设置 TTL 。
任何消息中间件的容量和堆积能力都是有限的,如果有一些消息总是不被消费掉,那么需要有一种过期的机制来做兜底。
目前有两种方法可以设置消息的 TTL :
- 通过
Queue属性设置,队列中所有消息都有相同的过期时间 - 对消息自身进行单独设置,每条消息的TTL 可以不同
如果两种方法一起使用,则消息的 TTL 以两者之间 较小数值为准 。通常来讲,消息在队列中的生存时间一旦超过设置的 TTL 值时,就会变成 死信 ( Dead Message ),消费者默认就无法再收到该消息。当然,“死信”也是可以被取出来消费的。
原生 API 案例:
try (Connection connection = factory.newConnection(); Channel channel = connection.createChannel()) {
// 创建队列(实际上使用的是AMQP default这个direct类型的交换器)
// 设置队列属性
Map<String, Object> arguments = new HashMap<>();
// 设置队列的TTL
arguments.put("x-message-ttl", 30000);
// 设置队列的空闲存活时间(如该队列根本没有消费者,一直没有使用,队列可以存活多久)
arguments.put("x-expires", 10000);
channel.queueDeclare(QUEUE_NAME, false, false, false, arguments);
for (int i = 0; i < 1000000; i++) {
String message = "Hello World!" + i;
channel.basicPublish("", QUEUE_NAME, new AMQP.BasicProperties().builder().expiration("30000").build(), message.getBytes());
System.out.println(" [X] Sent '" + message + "'");
}
} catch (TimeoutException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
此外,还可以通过命令行方式设置全局 TTL ,执行如下命令:
rabbitmqctl set_policy TTL ".*" '{"message-ttl":30000}' --apply-to queues
还可以通过 restful api 方式设置,这里不做过多介绍。
默认规则:
- 如果不设置 TTL ,则表示此消息不会过期;
- 如果 TTL 设置为 0 ,则表示除非此时可以直接将消息投递到消费者,否则该消息会被立即丢弃;
注意理解 message-ttl 、 x-expires 这两个参数的区别,有不同的含义。但是这两个参数属性都遵循上面的默认规则。一般 TTL 相关的参数单位都是 毫秒(ms)
死信队列
用户下单,调用订单服务,然后订单服务调用派单系统通知外卖人员送单,这时候订单系统与派单系统 采用 MQ 异步通讯。
在定义业务队列时可以考虑指定一个 死信交换机,并绑定一个死信队列。当消息变成死信时,该消息就会被发送到该死信队列上,这样方便我们查看消息失败的原因。
DLX ,全称为Dead-Letter-Exchange,死信交换器。消息在一个队列中变成死信(Dead Letter)之后,被重新发送到一个特殊的交换器(DLX)中,同时,绑定DLX的队列就称为 死信队列 。
以下几种情况导致消息变为死信:
- 消息被拒绝(
Basic.Reject/Basic.Nack),并且设置requeue参数为false - 消息过期
- 队列达到最大长度
对于 RabbitMQ 来说, DLX 是一个非常有用的特性。它可以处理异常情况下,消息不能够被消费者正确消费(消费者调用了 Basic.Nack 或者 Basic.Reject )而被置入死信队列中的情况,后续分析程序可以通过消费这个死信队列中的内容来分析当时所遇到的异常情况,进而可以改善和优化系统。
原生 API 案例
try (Connection connection = factory.newConnection(); Channel channel = connection.createChannel()) {
// 定义一个死信交换器(也是一个普通的交换器)
channel.exchangeDeclare("exchange.dlx", "direct", true);
// 定义一个正常业务的交换器
channel.exchangeDeclare("exchange.biz", "fanout", true);
Map<String, Object> arguments = new HashMap<>();
// 设置队列TTL
arguments.put("x-message-ttl", 10000);
// 设置该队列所关联的死信交换器(当队列消息TTL到期后依然没有消费,则加入死信队列)
arguments.put("x-dead-letter-exchange", "exchange.dlx");
// 设置该队列所关联的死信交换器的routingKey,如果没有特殊指定,使用原队列的 routingKey
arguments.put("x-dead-letter-routing-key", "routing.key.dlx.test");
channel.queueDeclare("queue.biz", true, false, false, arguments);
channel.queueBind("queue.biz", "exchange.biz", "");
channel.queueDeclare("queue.dlx", true, false, false, null);
// 死信队列和死信交换器
channel.queueBind("queue.dlx", "exchange.dlx", "routing.key.dlx.test");
channel.basicPublish("exchange.biz", "", MessageProperties.PERSISTENT_TEXT_PLAIN, "dlx.test".getBytes());
} catch (Exception e) {
e.printStackTrace();
}
延迟队列
延迟消息是指的消息发送出去后并不想立即就被消费,而是需要等(指定的)一段时间后才触发消费。
例如下面的业务场景:在支付宝上面买电影票,锁定了一个座位后系统默认会帮你保留 15 分钟时间,如果 15 分钟后还没付款那么不好意思系统会自动把座位释放掉。怎么实现类似的功能呢?
- 可以用定时任务每分钟扫一次,发现有占座超过 15 分钟还没付款的就释放掉。但是这样做很低效,很多时候做的都是些无用功;
- 可以用分布式锁、分布式缓存的被动过期时间, 15 分钟过期后锁也释放了,缓存 key 也不存在了;
- 还可以用延迟队列,锁座成功后会发送 1 条延迟消息,这条消息 15 分钟后才会被消费,消费的过程就是检查这个座位是否已经是“已付款”状态;
你在公司的协同办公系统上面预约了一个会议,邀请汪产品和陈序员今晚 22 点准时参加会有。系统还比较智能,除了默认发会议邀请的邮件告知参会者以外,到了今晚 21:45 分的时候(提前15分钟)就会通知提醒参会人员做好参会准备,会议马上开始...
同样的,这也可以通过轮询“会议预定表”来实现,比如我每分钟跑一次定时任务看看当前有哪些会议即将开始了。当然也可以通过延迟消息来实现,预定会议以后系统投递一条延迟消息,而这条消息比较特殊不会立马被消费,而是延迟到指定时间后再触发消费动作(发通知提醒参会人准备)。不过遗憾的是,在 AMQP 协议和 RabbitMQ 中都没有相关的规定和实现。不过,我们似乎可以借助上一小节介绍的“死信队列”来变相的实现。
可以使用 rabbitmq_delayed_message_exchange 插件实现。
这里和 TTL 方式有个很大的不同就是 TTL 存放消息在死信队列( delayqueue )里,二基于插件存放消息在延时交换机里( x-delayed-message exchange )。

- 生产者将消息( msg )和路由键( routekey )发送指定的延时交换机( exchange )上
- 延时交换机( exchange )存储消息等待消息到期根据路由键( routekey )找到绑定自己的队列( queue )并把消息给它
- 队列( queue )再把消息发送给监听它的消费者( customer )
RabbitMQ 集群与运维
集群方案原理
对于无状态应用(如普通的微服务)很容易实现负载均衡、高可用集群。而对于有状态的系统(如数据库等)就比较复杂。
-
业界实践:
- 主备模式:单活,容量对等,可以实现故障转移。使用独立存储时需要借助复制、镜像同步等技术,数据会有延迟、不一致等问题(CAP定律),使用共享存储时就不会有状态同步这个问题。
- 主从模式:一定程度的双活,容量对等,最常见的是读写分离。通常也需要借助复制技术,或者要求上游实现双写来保证节点数据一致。
- 主主模式:两边都可以读写,互为主备。如果两边同时写入很容易冲突,所以通常实现的都是“伪主主模式”,或者说就是主从模式的升级版,只是新增了主从节点的选举和切换。
- 分片集群:不同节点保存不同的数据,上游应用或者代理节点做路由,突破存储容量限制,分摊读写负载;典型的如 MongoDB 的分片、 MySQL 的分库分表、 Redis 集群。
- 异地多活:“两地三中心”是金融行业经典的容灾模式(有资源闲置的问题),“异地多活”才是王道。
-
常用负载均衡算法:
- 随机
- 轮询
- 加权轮询
- 最少活跃连接
- 原地址/目标地址 hash(一致性 hash)
-
集群中的经典问题:
脑裂(可以通过协调器选举算法、仲裁节点等方式来解决)
网络分区、一致性、可用性(CAP)
相关经典的技术和工具:LVS、HAProxy、Nginx、KeepAlived、Heartbeat、DRBD、Corosync、Pacemaker、MMM/MHA、Galera、MGR等
现在太多公司选择直接购买公有云服务,基本不用太关心很多基础设施和中间件的部署、运维细节。但是这些技术以及背后的原理是非常重要的。
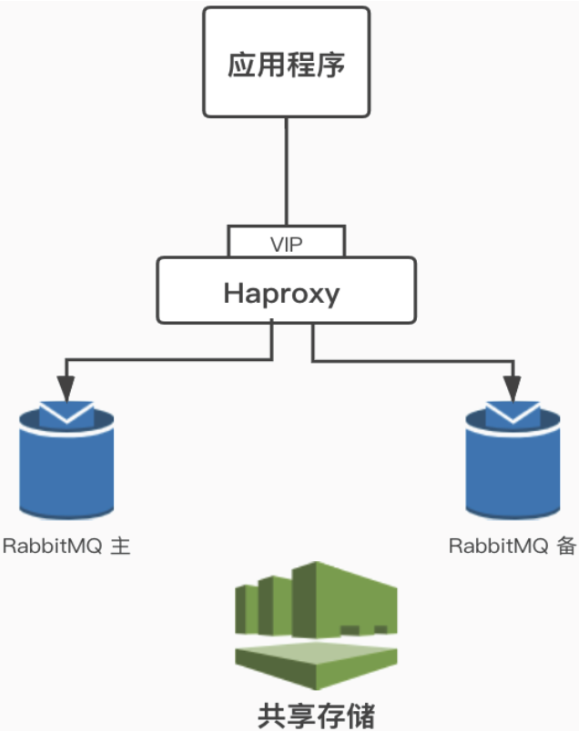
主备模式
也叫 Warren(兔子窝)模式,同一时刻只有一个节点在工作(备份节点不能读写),当主节点发生故障后会将请求切换到备份节点上(主恢复后成为备份节点)。需要借助 HAProxy 之类的( VIP 模式 )负载均衡器来做健康检查和主备切换,底层需要借助共享存储(如 SAN 设备)。
这不是 RabbitMQ 官方或者开源社区推荐方案,适用于访问压力不是特别大但是又有高可用架构需求(故障切换)的中小规模的系统来使用。首先有一个节点闲置,本身就是资源浪费,其次共享存储往往需要借助硬件存储,或者分布式文件系统。
Shovel 铲子模式
Shovel 是一个插件,用于实现跨机房数据复制,或者数据迁移,故障转移与恢复等。
如下图,用户下单的消费先是投递在 Goleta Broker 实例中,当 Goleta 实例达到触发条件后(例如:消息堆积数达到阈值)会将消息放到 Goleta 实例的 backup_orders 备份队列中,并通过 Shovel 插件从 Goleta 的 backup_orders 队列中将消息拉取到 Carpinteria 实例存储。
使用 Shovel 插件后,模型变成了近端同步确认,远端异步确认的方式。
此模式支持 WAN 传输,并且 Broker 实例的 RabbitMQ 、 Erlang 版本不要求完全一致。
Shovel 的配置分静态模式(修改 RabbitMQ 配置)和动态模式(在控制台直接部署,重启后失效)
RabbitMQ 集群
RabbitMQ 集群允许消费者和生产者在 RabbitMQ 单个节点崩溃的情况下继续运行,并可以通过添加更多的节点来线性扩展消息通信的吞吐量。当失去一个 RabbitMQ 节点时,客户端能够重新连接到集群中的任何其他节点并继续生产和消费。
RabbitMQ 集群中的所有节点都会备份所有的元数据信息,包括:
- 队列元数据:队列的名称及属性;
- 交换器:交换器的名称及属性;
- 绑定关系元数据:交换器与队列或者交换器与交换器之间的绑定关系;
- vhost 元数据:为 vhost 内的队列、交换器和绑定提供命名空间及安全属性。
基于存储空间和性能的考虑, RabbitMQ 集群中的各节点存储的消息是不同的(有点儿类似分片集群,各节点数据并不是全量对等的),各节点之间同步备份的仅仅是上述元数据以及 QueueOwner (队列所有者,就是实际创建 Queue 并保存消息数据的节点)的指针。当集群中某个节点崩溃后,该节点的队列进程和关联的绑定都会消失,关联的消费者也会丢失订阅信息,节点恢复后(前提是消息有持久化)消息可以重新被消费。虽然消息本身也会持久化,但如果节点磁盘存储设备发生故障那同样会导致消息丢失。
总的来说,该集群模式只能保证集群中的某个 Node 挂掉后应用程序还可以切换到其他 Node 上继续地发送和消费消息,但并无法保证原有的消息不丢失,所以并不是一个真正意义的高可用集群。
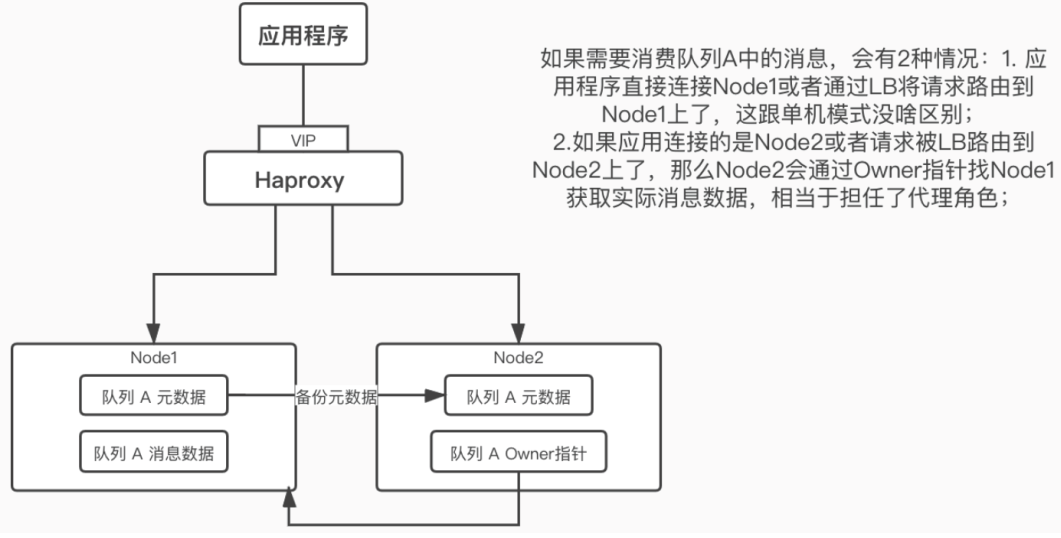
这是 RabbitMQ 内置的集群模式, Erlang 语言天生具备分布式特性,所以不需要借助类似 ZooKeeper 之类的组件来实现集群(集群节点间使用 Cookie 来进行通信验证,所有节点都必须使用相同的 .erlang.Cookie 文件内容),不同节点的 Erlang 、 RabbitMQ 版本必须一致。
镜像队列模式
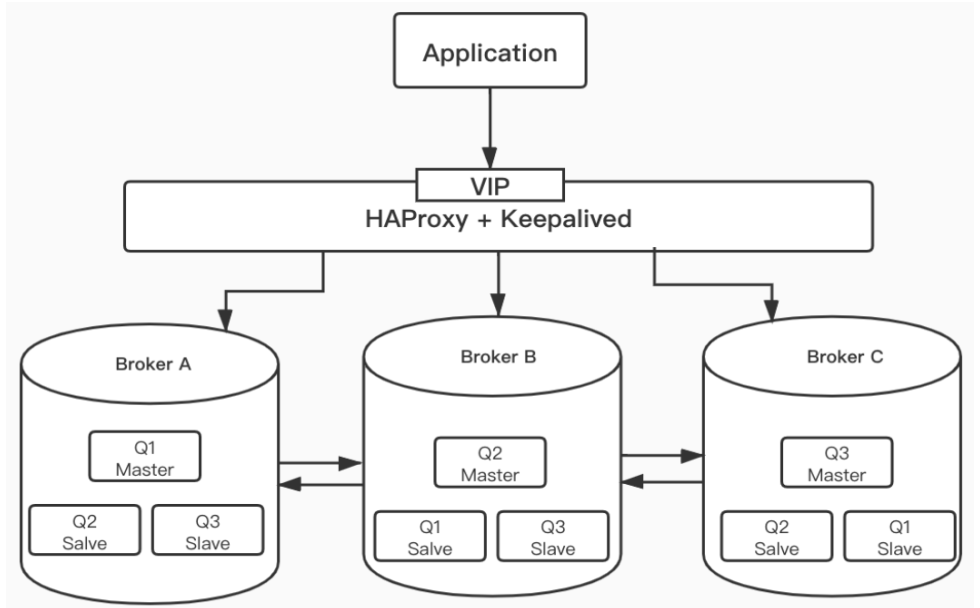
前面我们讲了, RabbitMQ 内置的集群模式有丢失消息的风险,“镜像队列”可以看成是对内置默认集群模式的一种高可用架构的补充。可以将队列镜像(同步)到集群中的其他 Broker 上,相当于是多副本冗余。如果集群中的一个节点失效,队列能自动地切换到集群中的另一个镜像节点上以保证服务的可用性,而且消息不丢失。
在 RabbitMQ 镜像队列中所谓的 Master 和 Slave 都仅仅是针对某个 Queue 而言的,而不是 Node 。一个 Queue 第一次创建所在的节点是它的 Master 节点,其他节点为 Slave 节点。如果 Master 由于某种原因失效,最先加入的 Slave 会被提升为新的 Master 。
无论客户端请求到达 Master 还是 Slave ,最终数据都是从 Master 节点获取。当请求到达 Master 节点时, Master 节点直接将消息返回给 Client ,同时 Master 节点会通过 GM ( Guaranteed Multicast )协议将 Queue 的最新状态广播到 Slave 节点。 GM 保证了广播消息的原子性,即要么都更新要么都不更新。当请求到达 Slave 节点时, Slave 节点需要将请求先重定向到 Master 节点, Master 节点将消息返回给 Client ,同时 Master 节点会通过 GM 协议将 Queue 的最新状态广播到 Slave 节点。
很多同学可能就会疑惑,这样设计太傻叉了, Slave 完全是闲置的啊!干嘛不学习 MySQL 主从复制,起码可以搞个读写分离啊!其实业界很多 HA 架构实践中冗余资源都是闲置的。前面我们讲了 RabbitMQ 镜像队列中的 Master 、 Slave 是 Queue 维度而并非 Node 维度,所以我们可以交叉减少资源限制,如下图所示:
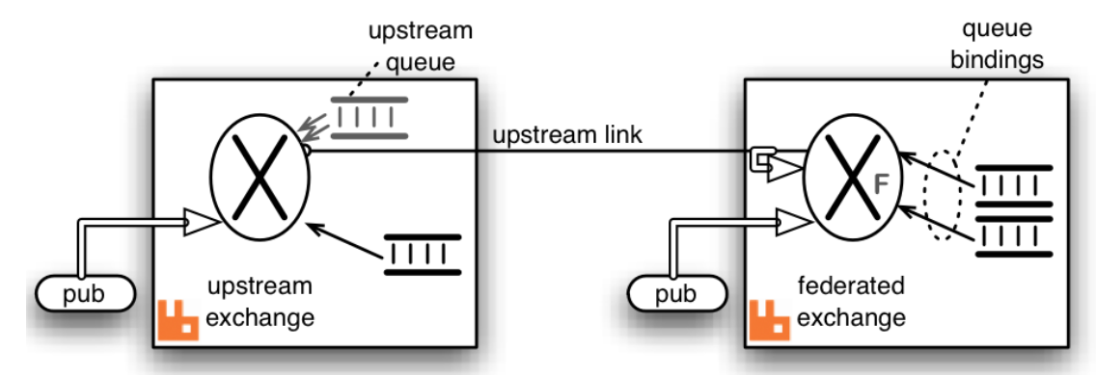
Federation 联邦模式
Federation 和 Shovel 类似,也是一个实现跨集群、节点消息同步的插件。支持联邦交换器、联邦队列(作用在不同级别)。
Federation 插件允许你配置一个 exchanges federation 或者 queues federation 。
一个 exchange/queues federation 允许你从一个或者多个 upstream 接收信息,就是远程的 exchange/queues 。
无论是 Federation 还是 Shovel 都只是解决消息数据传输的问题(当然插件自身可能会一些应用层的优化),跨机房跨城市的这种网络延迟问题是客观存在的,不是简单的通过什么插件可以解决的,一般需要借助昂贵的专线。
很多书籍和文章中存在误导大家的,可能会说 Federation/Shovel 可以解决延迟的问题,可以实现异地多活等等,其实这都是错误的。而且我可以负责人的告诉大家,他们所谓的“异地多活”并非大厂最佳实践。
例如:使用 Shovel 构建集群, RabbitMQ 和应用程序都选择双机房部署时,当杭州机房发生了消息积压后超出阈值部分的消息就会被转发到上海机房中,此时上海机房的应用程序直接消费掉上海机房 RabbitMQ 的消息,这样看起来上海机房是可以分摊负载,而且一定程度上实现“双机房多活”的。但是数据库呢?选择两边都部署还是仅部署在某个机房呢?两边同时写入是很容易造成冲突的,如果数据库仅仅部署在杭州机房,那么数据库也可能成为瓶颈导致消费速度依然上不去,只不过是多了上海机房中的消费者实例节点而已。
而使用 Federation 模式呢?如果要真正要实现“双机房多活”那么应用程序也是多机房的,那某些 Exchange/Queue 中的消息会在两边机房都有,两边机房的应用程序都会同时消息,那必然会造成重复消息!
异地多活架构
| 方 案 | 容量 | 容灾 | 成本 |
|---|---|---|---|
| 异 地 多 活 | [优]基于逻辑机房,容量 可伸缩的云微架构 [优]容量可异地伸缩 |
[优]日常运行,容灾时可用 性高。 [劣]受城际网络故障影响, 影响度取决于横向依赖程 度 |
[优]IDC、应用等成本在日常 得到有效利用 |
| 两 地 三 中 心 | [劣]仅可部署在一个城 市,容量伸缩有城市级 瓶颈 | [劣]灾备设施冷备等待,容 灾时可用性低。 | [劣]容灾设施等成本仅在容 灾时才使用,且受限于可用 性 |
单机多实例部署
单机版安装前面介绍过了,不再介绍。
此处在单机版基础上 ,也就是一台 Linux 虚拟机上启动多个 RabbitMQ 实例,部署集群。
在单个 Linux 虚拟机上运行多个 RabbitMQ 实例
- 多个 RabbitMQ 使用的端口号不能冲突
- 多个 RabbitMQ 使用的磁盘存储路径不能冲突
- 多个 RabbitMQ 的配置文件也不能冲突
在单个 Linux 虚拟机上运行多个 RabbitMQ 实例,涉及到 RabbitMQ 虚拟主机的名称不能重复,每个 RabbitMQ 使用的端口不能重复。
RABBITMQ_NODE_PORT 用于设置 RabbitMQ 的服务发现,对外发布的其他端口在这个端口基础上计算得来。
| 端口号 | 说明 |
|---|---|
| 4369 | epmd , RabbitMQ 节点和 CLI 工具使用的对等发现服务 |
| 5672、 5671 | 分别为不带 TLS 和带 TLS 的 AMQP 0-9-1 和 1.0 客户端使用 |
| 25672 | 用于节点间和 CLI 工具通信( Erlang 分发服务器端口),并从动态范围分配(默认情 况下限制为单个端口,计算为 AMQP 端口 + 20000 )。一般这些端口不应暴露出去 |
| 35672- 35682 | 由 CLI 工具( Erlang 分发客户端端口)用于与节点进行通信,并从动态范围(计算为 服务器分发端口 + 10000 通过服务器分发端口 + 10010 )分配 |
| 15672 | HTTP API 客户端,管理 UI 和 Rabbitmqadmin (仅在启用了管理插件的情况下) |
| 61613、 61614 | 不带 TLS 和带 TLS 的 STOMP 客户端(仅在启用 STOMP 插件的情况下) |
| 1883、 8883 | 如果启用了 MQTT 插件,则不带 TLS 和具有 TLS 的 MQTT 客户端 |
| 15674 | STOMP-over-WebSockets 客户端(仅在启用了 Web STOMP 插件的情况下) |
| 15675 | MQTT-over-WebSockets 客户端(仅在启用 Web MQTT 插件的情况下) |
| 15692 | Prometheus 指标(仅在启用 Prometheus 插件的情况下) |
RABBITMQ_NODENAME 用于设置 RabbitMQ 节点名称, @ 前缀是用户名, @ 后缀是 RabbitMQ 所在的 Linux 主机的 hostname ,例如:/var/lib/rabbitmq/mnesia/rabbit@hwjlinux
RabbitMQ 使用的环境变量:
| 环境变量 | 描述 |
|---|---|
| RABBITMQ_NODE_IP_ADDRESS | 将 RabbitMQ 绑定到一个网络接口。 如果要绑定多个网络接口,可以在配置文件中配置。 空字符串。表示绑定到所有的网络接口。 |
| RABBITMQ_NODE_PORT | 默认值:5672 |
| RABBITMQ_DIST_PORT | RabbitMQ 节点之间通信以及节点和CLI工具通信用到的端口。 如果在配置文件中配置了 kernel.inet_dist_listen_min 或者 kernel.inet_dist_listen_max ,则忽略该配置。 默认值: $RABBITMQ_NODE_PORT + 20000 |
| ERL_EPMD_ADDRESS | epmd 使用的网络接口, epmd 用于节点之间以及节点和 CLI 之间的通信。 默认值:所有网络接口 |
| ERL_EPMD_PORT | epmd 使用的端口。 默认值:4369 |
| RABBITMQ_DISTRIBUTION_BUFFER_SIZE | 节点之间通信连接使用的发送数据缓冲区大小限制, 单位是 KB 。推荐使用小于 64MB 的值。 默认值: 128000 |
| RABBITMQ_IO_THREAD_POOL_SIZE | Erlang运行时的 I/O 用到的线程数。不推荐小于32的值。 默认值:128(Linux),64(Windows) |
| RABBITMQ_NODENAME | RabbitMQ 的节点名称。对于 Erlang 节点和机器,此名称应该唯一。 通过设置此值,可以在一台机器多个 RabbitMQ 节点。 默认值:rabbit@$HOSTNAME(Unix-like),rabbit@%COMPUTERNAME% (Windows) |
| RABBITMQ_CONFIG_FILE | RabbitMQ 主要配置文件的路径。例如 /etc/rabbitmq/rabbitmq.conf 或者 /data/configuration/rabbitmq.conf 是新格式的配置文件。 如果是老格式的配置文件,扩展名 是 .config 或者不写。 默认值: 对于Unix: $RABBITMQ_HOME/etc/rabbitmq/rabbitmq Debian: /etc/rabbitmq/rabbitmq RPM: /etc/rabbitmq/rabbitmq MacOS(Homebrew): ${install_prefix}/etc/rabbitmq/rabbitmq , Homebrew的前缀通常是: /usr/local/ %APPDATA%\RabbitMQ\rabbitmq |
方式一:
export RABBITMQ_NODE_PORT=5672
export RABBITMQ_NODENAME=rabbit2
rabbitmq-server
export RABBITMQ_NODE_PORT=5673
export RABBITMQ_NODENAME=rabbit3
rabbitmq-server
export RABBITMQ_NODE_PORT=5674
export RABBITMQ_NODENAME=rabbit4
rabbitmq-server
方式二:
RABBITMQ_NODE_PORT=5672 RABBITMQ_NODENAME=rabbit2 rabbitmq-server
RABBITMQ_NODE_PORT=5673 RABBITMQ_NODENAME=rabbit3 rabbitmq-server
RABBITMQ_NODE_PORT=5674 RABBITMQ_NODENAME=rabbit4 rabbitmq-server
以上命令的运行主要考虑到环境变量的可见性问题。
启动 web 控制台的管理插件
rabbitmq-plugins enable rabbitmq_management
RabbitMQ 从 3.3.0 开始禁止使用 guest/guest 权限通过除 localhost 外的访问。如果想使用 guest/guest 通过远程机器访问,需要在 RabbitMQ 配置文件中设置 loopback_users 为 [] ,当然也可以按我之前讲的命令自己创建用户。
需要注意的是,如果要使用自定义位置的配置文件,需要目录属于 rabbitmq 组。
默认配置文件的位置:/etc/rabbitmq/rabbitmq.conf
我们在/opt/rabbitconf中创建三个配置文件:rabbit1.conf,rabbit2.conf,rabbit3.conf,其中注明三个 RabbitMQ 实例使用的
rabbitmq_management 插件使用的端口号,以及开通 guest 远程登录系统的权限:
| 文件路径 | 内容 |
|---|---|
| /opt/rabbitmqconf/rabbit1.conf | loopback_users.guest=false management.tcp.port=6001 |
| /opt/rabbitmqconf/rabbit2.conf | loopback_users.guest=false management.tcp.port=6002 |
| /opt/rabbitmqconf/rabbit3.conf | loopback_users.guest=false management.tcp.port=6003 |
启动命令:
| 节点名 称 | 命令 |
|---|---|
| rabbit1 | RABBITMQ_NODENAME=rabbit1 RABBITMQ_NODE_PORT=5001 RABBITMQ_CONFIG_FILE=/opt/rabbitconf/rabbit1.conf rabbitmq-server |
| rabbit2 | RABBITMQ_NODENAME=rabbit1 RABBITMQ_NODE_PORT=5001 RABBITMQ_CONFIG_FILE=/opt/rabbitconf/rabbit1.conf rabbitmq-server |
| rabbit3 | RABBITMQ_NODENAME=rabbit1 RABBITMQ_NODE_PORT=5001 RABBITMQ_CONFIG_FILE=/opt/rabbitconf/rabbit1.conf rabbitmq-server |
停止命令:
| 节点名称 | 命令 |
|---|---|
| rabbit1 | rabbitmqctl -n rabbit1 stop |
| rabbit2 | rabbitmqctl -n rabbit2 stop |
| rabbit3 | rabbitmqctl -n rabbit3 stop |
集群管理
前面我们讲了几种 RabbitMQ 分布式 / 集群架构的模式,下面我们结合 Rabbit 集群 + 镜像队列,并借助 HAProxy 实现负载均衡的集群。
-
在 node2 、 node3 、 node4 三台 Linux 虚拟机中安装 RabbitMQ
-
从 node2 拷贝
.erlang.cookie到 node3 、 node4 的相应目录如果没有该文件,手动创建
/var/lib/rabbitmq/.erlang.cookie,生成 Cookie 字符串,或者启动一次 RabbitMQ 自动生成该文件。生产中推荐使用第三方工具生成。我们首先在 node2 上启动单机版 RabbitMQ ,以生成 Cookie 文件:
systemctl start rabbitmq-server开始准备同步
.erlang.cookie文件。 RabbitMQ 的集群依赖 Erlang 的分布式特性,需要保持 Erlang Cookie 一致才能实现集群节点的认证和通信,我们直接使用scp命令从 node1 远程传输:scp /var/lib/rabbitmq/.erlang.cookie root@node3:/var/lib/rabbitmq/ scp /var/lib/rabbitmq/.erlang.cookie root@node4:/var/lib/rabbitmq/修改 node3 和 node4 上该文件的所有者为
rabbitmq:rabbitmq:chown rabbitmq:rabbitmq /var/lib/rabbitmq/.erlang.cookie注意
.erlang.cookie文件权限为400 -
使用下述命令启动 node3 和 node4 上的 RabbitMQ :
systemctl start rabbitmq-server -
将 node3 和 node4 这两个节点加入到集群中
# 停止Erlang VM上运行的RabbitMQ应用,保持Erlang VM的运行 rabbitmqctl stop_app # 移除当前RabbitMQ虚拟主机中的所有数据:重置 rabbitmqctl reset # 将当前RabbitMQ的主机加入到rabbit@node2这个虚拟主机的集群中。一个节点也是集群。 rabbitmqctl join_cluster rabbit@node2 # 启动当前Erlang VM上的RabbitMQ应用 rabbitmqctl start_apprabbit@node2表示 RabbitMQ 节点名称,默认前缀就是rabbit,@之后是当前虚拟主机所在的物理主机 hostname- 注意检查下 hostname 要可以相互 ping 通
- join_cluster 默认是使用 disk 模式,后面可以加入参数
--ram启用内存模式
移出集群节点使用:
# 将虚拟主机(RabbitMQ的节点)rabbit@node3从集群中移除,但是rabbit@node3还保留集群信息 # 还是会尝试加入集群,但是会被拒绝。可以重置rabbit@node3节点。 rabbitmqctl forget_cluster_node rabbit@node3 #修改集群名称(任意节点执行都可以) rabbitmqctl set_cluster_name #查看集群状态(任意节点执行都可以) rabbitmqctl cluster_status
在三个 RabbitMQ 节点上的任意一个添加用户,设置用户权限,设置用户标签,即可
rabbitmqctl add_user root 123456
rabbitmqctl set_permissions --vhost "/" root ".*" ".*" ".*"
rabbitmqctl set_user_tags --vhost "/" root administrator
可以到 web 控制台查看集群信息,如果要看到所有 RabbitMQ 节点上的运行情况,都需要启用 rabbitmq_management 插件。
RabbitMQ 镜像集群配置
RabbitMQ 中队列的内容是保存在单个节点本地的(声明队列的节点)。跟交换器和绑定不同,它们是对于集群中所有节点的。如此,则队列内容存在单点故障,解决方式之一就是使用镜像队列。在多个节点上拷贝队列的副本。
每个镜像队列包含一个 Master ,若干个镜像。
Master 存在于称为 Master 的节点上。
所有的操作都是首先对 Master 执行,之后广播到镜像。
这涉及排队发布,向消费者传递消息,跟踪来自消费者的确认等。
镜像意味着集群,不应该 WAN 使用。
发布到队列的消息会拷贝到该队列所有的镜像。消费者连接到 Master ,当消费者对消息确认之后,镜像删除 Master 确认的消息。
队列的镜像提供了高可用,但是没有负载均衡。
HTTP API 和 CLI 工具中队列对象的字段原来使用的是 Slave 代表 secondaries ,现在该字段的存在仅是为了向后兼容,后续版本会移除。
可以使用策略随时更改队列的类型,可以首先创建一个非镜像队列,然后使用策略将其配置为镜像队列或者反过来。非镜像队列没有额外的基础设施,因此可以提供更高的吞吐率。
Master 选举策略:
- 最长的运行镜像升级为主镜像,前提是假定它与主镜像完全同步。如果没有与主服务器同步的镜像,则仅存在于主服务器上的消息将丢失。
- 镜像认为所有以前的消费者都已突然断开连接。它重新排队已传递给客户端但正在等待确认的所有消息。这包括客户端已为其发出确认的消息,例如,确认是在到达节点托管队列主节点之前在线路上丢失了,还是在从主节点广播到镜像时丢失了。在这两种情况下,新的主服务器都
别无选择,只能重新排队它尚未收到确认的所有消息。 - 队列故障转移时请求通知的消费者将收到取消通知。当镜像队列发生了 Master 的故障转移,系统就不知道向哪些消费者发送了哪些消息。已经发送的等待确认的消息会重新排队
- 重新排队的结果是,从队列重新使用的客户端必须意识到,他们很可能随后会收到已经收到的消息
- 当所选镜像成为主镜像时,在此期间发布到镜像队列的消息将不会丢失(除非在提升的节点上发生后续故障)。发布到承载队列镜像的节点的消息将路由到队列主服务器,然后复制到所有镜像。如果主服务器发生故障,则消息将继续发送到镜像,并在完成向主服务器的镜像升级后
将其添加到队列中 - 即使主服务器(或任何镜像)在正在发布的消息与发布者收到的确认之间失败,由客户端使用发布者确认发布的消息仍将得到确认。从发布者的角度来看,发布到镜像队列与发布到非镜像队列没有什么不同
给队列添加镜像要慎重。
| ha-mode | ha-params | 结果 |
|---|---|---|
| exactly | count | 设置集群中队列副本的个数(镜像+master)。1表示一个副本;也就 是master。如果master不可用,行为依赖于队列的持久化机制。2表示 1个master和1个镜像。如果master不可用,则根据镜像推举策略从镜 像中选出一个做master。如果节点数量比镜像副本个数少,则镜像覆盖 到所有节点。如果count个数少于集群节点个数,则在一个镜像宕机 后,会在其他节点创建出来一个镜像。将“exactly”模式与“ha-promote on-shutdown”: “ always”一起使用可能很危险,因为队列可以在整个集 群中迁移并在关闭时变得不同步。 |
| all | (none) | 镜像覆盖到集群中的所有节点。当添加一个新的节点,队列就会复制过 去。这个配置很保守。一般推荐N/2+1个节点。在集群所有节点拷贝镜 像会给集群所有节点施加额外的负载,包括网络IO,磁盘IO和磁盘空间 使用。 |
| nodes | node names | 在指定node name的节点上复制镜像。node name就是在rabbitmqctl cluster_status命令输出中的node name。如果有不属于集群的节点名 称,它不报错。如果指定的节点都不在线,则仅在客户端连接到的声明 镜像的节点上创建镜像。 |
接下来,启用镜像队列:
# 对/节点配置镜像队列,使用全局复制
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
# 配置过半(N/2 + 1)复制镜像队列
rabbitmqctl set_policy ha-halfmore "queueA" '{"ha-mode":"exactly", "haparams":2}'
# 指定优先级,数字越大,优先级越高
rabbitmqctl set_policy --priority 1 ha-all "^" '{"ha-mode":"all"}'
在任意一个节点上面执行即可。默认是将所有的队列都设置为镜像队列,在消息会在不同节点之间复制,各节点的状态保持一致。
其他细节可以查看 官方文档
负载均衡 - HAProxy
将客户端的连接和操作的压力分散到集群中的不同节点,防止单个或几台服务器压力过大成为访问的瓶颈,甚至宕机。
HAProxy 是一款开源免费,并提供高可用性、负载均衡以及基于 TCP 和 HTTP 协议的代理软件,可以支持四层、七层负载均衡,经过测试单节点可以支持 10W 左右并发连接。
LVS 是工作在内核模式( IPVS ),支持四层负载均衡,实测可以支撑百万并发连接。
Nginx 支持七层的负载均衡(后期的版本也支持四层了),是一款高性能的反向代理软件和 Web 服务器,可以支持单机 3W 以上的并发连接。
这里我们使用 HAProxy 来做 RabbitMQ 的负载均衡,通过暴露 VIP 给上游的应用程序直接连接,上游应用程序不感知底层的 RabbitMQ 的实例节点信息。
yum install gcc -y
tar -zxf haproxy-2.1.0.tar.gz
cd haproxy-2.1.0
make TARGET=linux-glibc
make install
mkdir /etc/haproxy
#赋权
groupadd -r -g 149 haproxy
# 添加用户
useradd -g haproxy -r -s /sbin/nologin -u 149 haproxy
#创建haproxy配置文件
touch /etc/haproxy/haproxy.cfg
如果觉得编译安装很麻烦,也可以简单的:
yum -y install haproxy
如果使用 yum 安装的,那么 haproxy 默认在 /usr/sbin/haproxy,且会自动创建配置文件 /etc/haproxy/haproxy.cfg
监控
RabbitMQ 自带的( Management 插件)管理控制台功能比较丰富,不仅提供了 Web UI 界面,还暴露了很多 HTTP API 的能力。其中也具备基本的监控能力。此外,自带的命令行工具(例如: rabbitmqctl )也比较强大。
不过这些工具都不具备告警的能力。在实际的生产环境中,我们需要知道负载情况和运行监控状态(例如:系统资源、消息积压情况、节点健康状态等),而且当发生问题后需要触发告警。像传统的监控平台 Nagios 、 Zabbix 等均提供了 RabbitMQ 相关的插件支持。
另外,当前云原生时代最热门的 Prometheus 监控平台也提供了 rabbitmq_exporter ,结合 Grafana 漂亮美观的 dashboard (可以自定义,也可以在仓库选择一些现有的),我们目前公司就是使用 Prometheus + Grafana 来监控 RabbitMQ 的,并实现了水位告警通知。

