

20210207. MongoDB - 拉勾教育
环境信息
- 视频版本:
4.1.3 - 笔记版本:
4.1.3 - 最新版本:
4.4.3-2021年2月3日
MongoDB 体系结构
MongoDB 是一款高性能的 NoSQL ( Not Only SQL 不仅仅 SQL )数据库
NoSQL 和 MongoDB
- NoSQL = Not Only SQL ,支持类似 SQL 的功能, 与 Relational Database 相辅相成。其性能较高,不使用 SQL 意味着没有结构化的存储要求( SQL 为结构化的查询语句),没有约束之后架构更加灵活。
- NoSQL 数据库四大家族 列存储 HBase ,键值( Key-Value )存储 Redis ,图像存储 Neo4j ,文档存储 MongoDB
- MongoDB 是一个基于分布式文件存储的数据库,由 C++ 编写,可以为 WEB 应用提供可扩展、高性能、易部署的数据存储解决方案。
- MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库中功能最丰富、最像关系数据库的。在高负载的情况下,通过添加更多的节点,可以保证服务器性能。
MongoDB 体系结构
MongoDB 和 RDBMS (关系型数据库)对比
| RDBMS | MongoDB |
|---|---|
| database (数据库) | database(数据库) |
| table(表) | collection(集合) |
| row(行) | document(BSON 文档) |
| column(列) | field(字段) |
| index(唯一索引、主键索引) | index(支持地理位置索引、全文索引 、哈希索引) |
| join(主外键关联) | embedded Document(嵌套文档) |
| primary key(指定 1 至 N 个列做主键) | primary key(指定 _id field 做为主键) |
什么是 BSON
BSON 是一种类 JSON 的一种 二进制形式 的存储格式,简称 Binary JSON ,它和 JSON 一样,支持内嵌的文档对象和数组对象,但是 BSON 有 JSON 没有的一些数据类型,如 Date 和 Binary Data 类型。 BSON 可以做为网络数据交换的一种存储形式,是一种 schema-less 的存储形式,它的优点是灵活性高,但它的缺点是空间利用率不是很理想。
{key:value,key2:value2}
这是一个 BSON 的例子,其中 key 是字符串类型,后面的 value 值,它的类型一般是字符串、double、Array、ISODate 等类型。
BSON 有三个特点:轻量性、可遍历性、高效性
BSON 在 MongoDB 中的使用
MongoDB 使用了 BSON 这种结构来存储数据和网络数据交换。把这种格式转化成文档这个概念(Document),这里的一个 Document 也可以理解成关系数据库中的一条记录( Record ),只是这里的 Document 的变化更丰富一些,如 Document 可以嵌套。
MongoDB 中 Document 中可以出现的数据类型:
| 数据类型 | 说明 | 解释说明 | Document 举例 |
|---|---|---|---|
String |
字符串 | UTF-8 编码的字符串才是 合法的。 | {key:"cba"} |
Integer |
整型数值 | 根据你所采用的服务器, 可分为 32 位或 64 位。 | {key:1} |
Boolean |
布尔值 | 用于存储布尔值(真/ 假)。 | {key:true} |
Double |
双精度浮点值 | 用于存储浮点值 | {key:3.14} |
ObjectId |
对象ID | 用于创建文档的 ID | {_id:new ObjectId()} |
Array |
数组 | 用于将数组或列表或多个 值存储为一个键 | {arr:["a","b"]} |
Timestamp |
时间戳 | 从开始纪元开始的毫秒数 | { ts: new Timestamp() } |
Object |
内嵌文档 | 文档可以作为文档中某个 key 的 value | {o:{foo:"bar"}} |
Null |
空值 | 表示空值或者未定义的对 象 | {key:null} |
Date 或者 ISODate |
格林尼治时间 | 日期时间,用 Unix 日期格 式来存储当前日期或时间。 | {birth:new Date()} |
Code |
代码 | 可以包含 JS 代码 | {x:function(){}} |
File |
文件 | 1. 二进制转码(Base64)后 存储 (<16M) 2. GridFS(>16M) |
GridFS 用两个集合来存储一个文件:fs.files 与 fs.chunks 真正存储需要使用 mongofiles -d gridfs put song.mp3 |
MongoDB 在 Linux 的安装
-
下载社区版 MongoDB 4.1.3
去官网下载对应的 MongoDB 然后上传到 Linux 虚拟机
-
将压缩包解压即可
tar -zxvf MongoDB-linux-x86_64-4.1.3.tgz -
启动
# 默认配置启动 ./bin/mongod # 指定配置文件 ./bin/mongod -f mongo.conf -
连接
# 启动 mongo shell ./bin/mongo # 指定主机和端口的方式启动 ./bin/mongo --host=主机IP --port=端口
配置文件样例:
dbpath=/data/mongo/
port=27017
bind_ip=0.0.0.0
fork=true
logpath=/data/mongo/MongoDB.log
logappend=true
auth=false
MongoDB 启动和参数说明
| 参数 | 说明 |
|---|---|
dbpath |
数据库目录,默认 /data/db |
port |
监听的端口,默认 27017 |
bind_ip |
监听IP地址,默认全部可以访问 |
fork |
是否以后台启动的方式登录 |
logpath |
日志路径 |
logappend |
是否追加日志 |
auth |
是开启用户密码登陆 |
config |
指定配置文件 |
MongoDB GUI 工具
- MongoDB Compass Community(官方提供)
- NoSQLBooster(MongoBooster)
- Navicat
MongoDB 命令
MongoDB 的基本操作
# 查看数据库
show dbs;
# 切换数据库 如果没有对应的数据库则创建
use 数据库名;
# 创建集合
db.createCollection("集合名")
# 查看集合
show tables;
show collections;
# 删除集合,会删除集合上的索引
db.集合名.drop();
# 删除当前数据库
db.dropDatabase();
MongoDB 集合数据操作(CURD)
数据添加
-
文档的数据结构和 JSON 基本一样。
-
所有存储在集合中的数据都是 BSON 格式。
-
BSON 是一种类 JSON 的一种二进制形式的存储格式,简称 Binary JSON 。
-
插入时没有指定
_id这个字段,系统会自动生成,当然我们也可以指定_id -
_id类型是ObjectId类型,是一个 12 字节 BSON 类型数据,有以下格式: -
前4个字节表示时间戳,可以通过
ObjectId("对象Id字符串").getTimestamp()来获取 -
接下来的 3 个字节是机器标识码
-
紧接的两个字节由进程 id 组成(PID)
-
最后三个字节是随机数。
-
语法:
# 插入单条数据 db.集合名.insert(文档) # 插入多条数据 db.集合名.insert([文档,文档]) ## 示例 db.lg_resume_preview.insert({name:"张三",birthday:new ISODate("2000-07-01"),expectSalary:3000,gender:1,city:"bj"}); db.lg_resume_preview.insert({name:"李四",birthday:new ISODate("2000-07-01"),expectSalary:4000,gender:0,city:"bj"}); db.lg_resume_preview.insert({name:"王五",birthday:new ISODate("2000-07-01"),expectSalary:5000,gender:0,city:"sh"});
数据查询
比较条件查询
db.集合名.find(条件)
| 操作 | 条件格式 | 例子 | RDBMS 中的条件 |
|---|---|---|---|
| 等于 | {key:value} |
db.collection.find({字段名:值}).pretty() |
where 字段名=值 |
| 大于 | {key:{$gt:value}} | db.collection.find({字段名:{$gt:值}}).pretty() |
where 字段名>值 |
|
| 小于 | {key:{$lt:value}} | db.collection.find({字段名:{$lt:值}}).pretty() |
where 字段名<值 |
|
| 大于等于 | {key:{$gte:value}} | db.collection.find({字段名:{$gte:值}}).pretty() |
where 字段名>= 值 |
|
| 小于等于 | {key:{$lte:value}} | db.collection.find({字段名:{$lte:值}}).pretty() |
where 字段名<=值 |
|
| 不等于 | {key:{$ne:value}} | db.collection.find({字段名:{$ne:值}}).pretty() |
where 字段名!=值 |
db.lg_resume_preview.find({gender:0});
db.lg_resume_preview.find({expectSalary:{$gt:100000}});
逻辑条件查询
MongoDB 的 find() 方法可以传入多个键( key ),每个键( key )以逗号隔开,即常规 SQL 的 AND 条件
| 逻辑条件 | 语法 |
|---|---|
| and | db.collection.find({key1:value1, key2:value2}).pretty() |
| or | db.collection.find({$or:[{key1:value1}, {key2:value2}]}).pretty() |
| not | db.collection.find({key:{$not:{$操作符:value}}).pretty() |
db.lg_resume_preview.find({gender:0, city: 'bj'});
db.lg_resume_preview.find({$and:[{gender:0}, {city: 'bj'}]});
db.lg_resume_preview.find({$or:[{gender:0}, {city: 'sh'}]});
db.lg_resume_preview.find({city:{$not:{$ne:'bj'}}});
分页查询
db.集合名.find({条件}).sort({排序字段:排序方式})).skip(跳过的行数).limit(一页显示多少数据)
db.lg_resume_preview.find({gender:0}).sort({expectSalary:-1}).skip(1).limit(1);
数据更新,调用 update
$set :设置字段值
$unset :删除指定字段
$inc:对修改的值进行自增
db.集合名.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
db.集合名.update({条件},{$set:{字段名:值}},{multi:true})
| 参数 | 说明 |
|---|---|
query |
update 的查询条件,类似 sql update 查询内 where 后面的 |
update |
update 的对象和一些更新的操作符(如 $set,$inc ...)等,也可以理解为 sql update中 set 后面的 |
upsert |
可选,这个参数的意思是,如果不存在 update 的记录,是否插入 objNew,true 为插入,默认是 false,不插入。 |
multi |
可选,MongoDB 默认是 false,只更新找到的第一条记录,如果这个参数为 true,就把按条件查出来多条记录全部更新。 |
writeConcern |
可选,用来指定 mongod 对写操作的回执行为,比如写的行为是否需要确认。 |
writeConcern 包括以下字段:
{ w: <value>, j: <boolean>, wtimeout: <number> }
-
w:指定写操作传播到的成员数量w=1(默认):则要求得到写操作已经传播到独立的 Mongod 实例或副本集的 primary 成员的确认w=0:则不要求确认写操作,可能会返回 socket exceptions 和 networking errorsw="majority":要求得到写操作已经传播到大多数具有存储数据具有投票的(data-bearing voting)成员(也就是members[n].votes值大于 0 的成员)的确认
-
j:要求得到 MongoDB 的写操作已经写到硬盘日志的确认j=true:要求得到 MongoDB ( w 指定的实例个数)的写操作已经写到硬盘日志的确认。j=true本身并不保证因为副本集故障而不会回滚。
-
wtimeout:指定 write concern 的时间限制,只适用于w>1的情况wtimeout在超过指定时间后写操作会返回 error ,即使写操作最后执行成功,当这些写操作返回时, MongoDB 不会撤消在wtimeout时间限制之前执行成功的数据修改。- 如果未指定
wtimeout选项且未指定 write concern 级别,则写入操作将无限期阻止。 指定wtimeout值为 0 等同于没有wtimeout选项。
db.lg_resume_preview.update({name:'张三'},{$set:{expectSalary:2000}});
db.lg_resume_preview.update({name:'张三'},{$unset:{'expectSalary':null}});
db.lg_resume_preview.update({name:'张三'},{$set:{'expectSalary':3234}}, {upsert:true});
数据删除
db.collection.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
| 参数 | 说明 |
|---|---|
query |
(可选)删除的文档的条件 |
justOne |
(可选)如果设为 true 或 1,则只删除一个文档,如果不设置该参数,或使用默认值 false,则删除所有匹配条件的文档。 |
writeConcern |
(可选)用来指定 mongod 对写操作的回执行为。 |
db.lg_resume_preview.remove({name:'张三'});
MongoDB 聚合操作
聚合操作简介
聚合是 MongoDB 的高级查询语言,它允许我们通过转化合并由多个文档的数据来生成新的在单个文档里不存在的文档信息。一般都是将记录按条件分组之后进行一系列求最大值,最小值,平均值的简单操作,也可以对记录进行复杂数据统计,数据挖掘的操作。聚合操作的输入是集中的文档,输出可以是一个文档也可以是多个文档。
MongoDB 聚合操作分类
- 单目的聚合操作( Single Purpose Aggregation Operation )
- 聚合管道( Aggregation Pipeline )
- MapReduce 编程模型
单目的聚合操作
单目的聚合命令常用的有:count() 和 distinct()
db.lg_resume_preview.count();
db.lg_resume_preview.distinct('city').length;
聚合管道( Aggregation Pipeline )
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
db.lg_resume_preview.aggregate([{$group:{_id:"$city",city_count:{$sum:1}}}])
MongoDB 中聚合( aggregate )主要用于统计数据(诸如统计平均值,求和等),并返回计算后的数据结果。
表达式:处理输入文档并输出。表达式只能用于计算当前聚合管道的文档,不能处理其它的文档。
| 表达式 | 描述 |
|---|---|
$sum |
计算总和 |
$avg |
计算平均值 |
$min |
获取集合中所有文档对应值得最小值 |
$max |
获取集合中所有文档对应值得最大值 |
$push |
在结果文档中插入值到一个数组中 |
$addToSet |
在结果文档中插入值到一个数组中,但数据不重复 |
$first |
根据资源文档的排序获取第一个文档数据 |
$last |
根据资源文档的排序获取最后一个文档数据 |
MongoDB 中使用 db.COLLECTION_NAME.aggregate([{},...]) 方法来构建和使用聚合管道,每个文档通过一个由一个或者多个阶段(stage)组成的管道,经过一系列的处理,输出相应的结果。
MongoDB 的聚合管道将 MongoDB 文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
这里我们介绍一下聚合框架中常用的几个操作:
| 聚合管道 | 描述 |
|---|---|
$group |
将集合中的文档分组,可用于统计结果 |
$project |
修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档 |
$match | 用于过滤数据,只输出符合条件的文档。$match 使用 MongoDB 的标准查询操作 |
|
$limit |
用来限制 MongoDB 聚合管道返回的文档数 |
$skip |
在聚合管道中跳过指定数量的文档,并返回余下的文档 |
$sort |
将输入文档排序后输出 |
$geoNear |
输出接近某一地理位置的有序文档 |
// 统计每个城市的平均期望工资
db.lg_resume_preview.aggregate([
{$group : {_id: "$city", avgSal:{$avg:"$expectSalary"}}},
{$project : {city: "$city", salary : "$avgSal"}}
]);
// 统计简历数大于 1 的城市
db.lg_resume_preview.aggregate([
{$group:{_id: "$city",count:{$sum : 1}}},
{$match:{count:{$gt:1}}}
]);
MapReduce 编程模型
Pipeline 查询速度快于 MapReduce ,但是 MapReduce 的强大之处在于能够在多台 Server 上并行执行复杂的聚合逻辑。
MongoDB 不允许 Pipeline 的单个聚合操作占用过多的系统内存,如果一个聚合操作消耗 20% 以上的内存,那么 MongoDB 直接停止操作,并向客户端输出错误消息。
MapReduce 是一种计算模型,简单的说就是将大批量的工作(数据)分解( MAP )执行,然后再将结果合并成最终结果( REDUCE )。
db.collection.mapReduce(
function() {emit(key,value);}, // map 函数
function(key,values) {return reduceFunction}, // reduce 函数
{
out: collection,
query: document,
sort: document,
limit: number,
finalize: <function>,
verbose: <boolean>
}
)
使用 MapReduce 要实现两个函数 Map 函数和 Reduce 函数, Map 函数调用 emit(key, value), 遍历 collection 中所有的记录, 将 key 与 value 传递给 Reduce 函数进行处理。
| 参数 | 描述 |
|---|---|
| map | 是 JavaScript 函数,负责将每一个输入文档转换为零或多个文档,生成键值对序列,作为 reduce 函数参数 |
| reduce | 是 JavaScript 函数,对 map 操作的输出做合并的化简的操作(将 key-value 变成 key-values ,也就是把 values 数组变成一个单一的值 value ) |
| out | 统计结果存放集合 |
| query | 一个筛选条件,只有满足条件的文档才会调用 map 函数 |
| sort | 和 limit 结合的 sort 排序参数(也是在发往 map 函数前给文档排序),可以优化分组机制 |
| limit | 发往 map 函数的文档数量的上限(要是没有 limit ,单独使用 sort 的用处不大) |
| finalize | 可以对 reduce 输出结果再一次修改 |
| verbose | 是否包括结果信息中的时间信息,默认为 false |
db.lg_resume_preview.mapReduce(
function() { emit(this.city,this.expectSalary); },
function(key, value) {return Array.sum(value)},
{
query:{expectSalary:{$gt: 1500}},
out:"cityAvgSal"
}
);
// Navicat 无法看到结果
MongoDB 索引 Index
什么是索引
索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识的数据页的逻辑指针清单。
索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
索引目标是提高数据库的查询效率,没有索引的话,查询会进行全表扫描( scan every document in a collection ),数据量大时严重降低了查询效率。
默认情况下 MongoDB 在一个集合( collection )创建时,自动地对集合的 _id 创建了唯一索引。
索引类型
单键索引(Single Field)
MongoDB 支持所有数据类型中的单个字段索引,并且可以在文档的任何字段上定义。
对于单个字段索引,索引键的排序顺序无关紧要,因为 MongoDB 可以在任一方向读取索引。
单个例上创建索引:
db.集合名.createIndex({"字段名":排序方式})
db.lg_resume_preview.createIndex({"name":1})
特殊的单键索引 - 过期索引 TTL ( Time To Live)
TTL 索引是 MongoDB 中一种特殊的索引, 可以支持文档在一定时间之后自动过期删除,目前 TTL 索引只能在单字段上建立,并且字段类型必须是日期类型。
db.集合名.createIndex({"日期字段":排序方式}, {expireAfterSeconds: 秒数})
// 5s 后删除文档,不删除后持续生效,之后插入的数据,也会在 5s 后删除
db.lg_resume_preview.createIndex({"birthday":1}, {expireAfterSeconds: 5})
复合索引(Compound Index)
通常我们需要在多个字段的基础上搜索表/集合,这是非常频繁的。 如果是这种情况,我们可能会考虑在 MongoDB 中制作复合索引。 复合索引支持基于多个字段的索引,这扩展了索引的概念并将它们扩展到索引中的更大域。
制作复合索引时要注意的重要事项包括:字段顺序与索引方向。
db.集合名.createIndex( { "字段名1" : 排序方式, "字段名2" : 排序方式 } )
db.lg_resume_preview.createIndex( { "name" : 1, "city" : -1 } );
多键索引(Multikey indexes)
针对属性包含数组数据的情况, MongoDB 支持针对数组中每一个 element 创建索引, Multikey indexes 支持 strings , numbers 和 nested documents
地理空间索引(Geospatial Index)
针对地理空间坐标数据创建索引
2dsphere 索引,用于存储和查找球面上的点
2d 索引,用于存储和查找平面上的点
db.company.insert({
loc : { type: "Point", coordinates: [ 116.482451, 39.914176 ] },
name: "大望路地铁",
category : "Parks"
})
// 参数不是 1 或 -1 ,是 2dsphere 或者 2d。还可以建立组合索引。
db.company.ensureIndex( { loc : "2dsphere" } )
// 查询在地点附近的位置
db.company.find({
"loc" : {
"$geoWithin" : {
"$center":[[116.482451,39.914176],0.05]
}
}
})
全文索引
MongoDB 提供了针对 string 内容的文本查询, Text Index 支持任意属性值为 string 或 string 数组元素的索引查询。
注意:一个集合仅支持最多一个 Text Index ,中文分词不理想,推荐 ES 。
db.集合.createIndex({"字段": "text"})
db.集合.find({"$text": {"$search": "coffee"}})
db.lg_resume_preview.createIndex({"city": "text"});
db.lg_resume_preview.find({"$text": {"$search": "张三"}});
哈希索引 Hashed Index
针对属性的哈希值进行索引查询,当要使用 Hashed index 时, MongoDB 能够自动的计算 hash 值,无需程序计算 hash 值。
Hashed index 仅支持等于查询,不支持范围查询。
db.集合.createIndex({"字段": "hashed"})
db.lg_resume_preview.createIndex({"name": "hashed"});
索引和 explain 分析
索引管理
创建索引并在后台运行:
db.COLLECTION_NAME.createIndex({"字段":排序方式}, {background: true});
db.lg_resume_preview.createIndex({"expectSalary": "hashed"}, {background: true});
获取针对某个集合的索引:
db.COLLECTION_NAME.getIndexes()
db.lg_resume_preview.getIndexes();
索引的大小:
db.COLLECTION_NAME.totalIndexSize()
db.lg_resume_preview.totalIndexSize();
索引的重建:
db.COLLECTION_NAME.reIndex()
db.lg_resume_preview.reIndex();
索引的删除:
db.COLLECTION_NAME.dropIndex("INDEX-NAME")
db.COLLECTION_NAME.dropIndexes()
// 注意: _id 对应的索引是删除不了的
db.lg_resume_preview.dropIndex("birthday_1")
explain 分析
使用 js 循环插入100万条数据,不使用索引字段查询,查看执行计划 ,然后给某个字段建立索引,使用索引字段作为查询条件,再查看执行计划进行分析
for (var i = 0; i < 1000000; i++) {
db.lg_resume_preview.insert({name:"张三"+i,birthday:new ISODate("2000-07-01"),expectSalary:i,gender:i%2,city:"bj"});
}
db.lg_resume_preview.explain().find();
db.lg_resume_preview.explain("executionStats").find();
db.lg_resume_preview.explain("allPlansExecution").find();
explain() 也接收不同的参数,通过设置不同参数我们可以查看更详细的查询计划:
| 参数 | 描述 |
|---|---|
queryPlanner |
默认参数 |
executionStats |
会返回执行计划的一些统计信息(有些版本中和 allPlansExecution 等同) |
allPlansExecution |
用来获取所有执行计划,结果参数基本与上文相同 |
queryPlanner 默认参数
| 参数 | 含义 |
|---|---|
plannerVersion |
查询计划版本 |
namespace |
要查询的集合(该值返回的是该 query 所查询的表)数据库.集合 |
indexFilterSet |
针对该 query 是否有 indexFilter |
parsedQuery |
查询条件 |
winningPlan |
被选中的执行计划 |
winningPlan.stage |
被选中执行计划的 stage(查询方式),常见的有: COLLSCAN/全表 扫描:(应该知道就是 CollectionScan,就是所谓的“集合扫描”, 和 MySQL 中 table scan/heap scan 类似,这个就是所谓的性能最烂 最无奈的由来) IXSCAN/索引扫描:(是 IndexScan,这就说明我们已经命中索引了) FETCH/根据索引去检索文档 SHARD_MERGE/合并分片结果 IDHACK/针对_id进行查询 |
winningPlan.inputStage |
用来描述子 stage,并且为其父 stage 提供文档和索引关键字。 |
winningPlan.stage的child stage |
如果此处是 IXSCAN,表示进行的是 index scanning。 |
winningPlan.keyPattern |
所扫描的 index 内容 |
winningPlan.indexName |
winning plan 所选用的 index。 |
winningPlan.isMultiKey |
是否是 Multikey,此处返回是 false,如果索引建立在 array 上,此处将是true。 |
winningPlan.direction |
此 query 的查询顺序,此处是 forward,如果用了 .sort({字段:-1}) 将显示 backward。 |
filter |
过滤条件 |
winningPlan.indexBounds |
winningplan 所扫描的索引范围,如果没有制定范围就是 [MaxKey, MinKey],这主要是直接定位到 MongoDB 的 chunck 中去查找数据,加快数据读取。 |
rejectedPlans |
被拒绝的执行计划的详细返回,其中具体信息与 winningPlan 的返回中意义相同,故不在此赘述) |
serverInfo |
MongoDB 服务器信息 |
executionStats 参数
| 参数 | 含义 |
|---|---|
executionSuccess |
是否执行成功 |
nReturned |
返回的文档数 |
executionTimeMillis |
执行耗时 |
totalKeysExamined |
索引扫描次数 |
totalDocsExamined |
文档扫描次数 |
executionStages |
这个分类下描述执行的状态 |
stage |
扫描方式,具体可选值与上文的相同 |
nReturned |
查询结果数量 |
executionTimeMillisEstimate |
检索 document 获得数据的时间 |
inputStage.executionTimeMillisEstimate |
该查询扫描文档 index 所用时间 |
works |
工作单元数,一个查询会分解成小的工作单元 |
advanced |
优先返回的结果数 |
docsExamined |
文档检查数目,与 totalDocsExamined 一致。检查了总共的document 个数,而从返回上面的 nReturned 数量 |
executionStats 返回逐层分析
第一层
executionTimeMillis 最为直观,explain 返回值是 executionTimeMillis 值,指的是这条语句的执行时间,这个值当然是希望越少越好。
其中有 3 个 executionTimeMillis,分别是:
executionStats.executionTimeMillis:该 query 的整体查询时间。executionStats.executionStages.executionTimeMillisEstimate:该查询检索 document 获得数据的时间。executionStats.executionStages.inputStage.executionTimeMillisEstimate:该查询扫描文档 index 所用时间。
第二层
index 与 document 扫描数与查询返回条目数
这个主要讨论 3 个返回项 nReturned、totalKeysExamined、totalDocsExamined,分别代表该条查询返回的条目、索引扫描条目、文档扫描条目。 这些都是直观地影响到 executionTimeMillis,我们需要扫描的越少速度越快。 对于一个查询,我们最理想的状态是:nReturned=totalKeysExamined=totalDocsExamined
第三层
stage 状态分析
那么又是什么影响到了 totalKeysExamined 和 totalDocsExamined ?是 stage 的类型。
类型列举如下:
| 类型 | 描述 |
|---|---|
COLLSCAN |
全表扫描 |
IXSCAN |
索引扫描 |
FETCH |
根据索引去检索指定 document |
SHARD_MERGE |
将各个分片返回数据进行 merge |
SORT |
表明在内存中进行了排序 |
LIMIT |
使用 limit 限制返回数 |
SKIP |
使用 skip 进行跳过 |
IDHACK |
针对 _id 进行查询 |
SHARDING_FILTER |
通过 mongos 对分片数据进行查询 |
COUNT |
利用 db.coll.explain().count() 之类进行 count 运算 |
TEXT |
使用全文索引进行查询时候的stage返回 |
PROJECTION |
限定返回字段时候stage的返回 |
对于普通查询,我希望看到 stage 的组合(查询的时候尽可能用上索引):
Fetch+IDHACKFetch+IXSCANLimit+ (Fetch+IXSCAN)PROJECTION+IXSCANSHARDING_FITER+IXSCAN
不希望看到包含如下的stage:
COLLSCAN(全表扫描)SORT(使用 sort 但是无 index )COUNT(不使用 index 进行 count )
allPlansExecution 参数
queryPlanner 参数和 executionStats 的拼接
慢查询分析
-
开启内置的查询分析器,记录读写操作效率
db.setProfilingLevel(n,m),n 的取值可选 0、1、2- 0 表示不记录
- 1 表示记录慢速操作,如果值为 1,m 必须赋值,单位为 ms ,用于定义慢速查询时间的阈值
- 2 表示记录所有的读写操作
-
查询监控结果
db.system.profile.find().sort({millis:-1}).limit(3) -
分析慢速查询
应用程序设计不合理、不正确的数据模型、硬件配置问题,缺少索引等
-
解读 explain 结果,确定是否缺少索引
MongoDB 索引底层实现原理分析
MongoDB 是文档型的数据库,它使用 BSON 格式保存数据,比关系型数据库存储更方便。
比如之前关系型数据库中处理用户、订单等数据要建立对应的表,还要建立它们之间的关联关系。但是 BSON 就不一样了,我们可以把一条数据和这条数据对应的数据都存入一个 BSON 对象中,这种形式更简单,通俗易懂。
MySQL 是关系型数据库,数据的关联性是非常强的,区间访问是常见的一种情况,底层索引组织数据使用 B+ 树, B+ 树由于数据全部存储在叶子节点,并且通过指针串在一起,这样就很容易的进行区间遍历甚至全部遍历。
MongoDB 使用 B-树,所有节点都有 Data 域,只要找到指定索引就可以进行访问,单次查询从结构上来看要快于 MySQL 。
MongoDB 应用实战
MongoDB 的适用场景
- 网站数据:MongoDB 非常适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。
- 缓存:由于性能很高,MongoDB 也适合作为信息基础设施的缓存层。在系统重启之后,由 MongoDB 搭建的持久化缓存层可以避免下层的数据源过载。
- 大尺寸、低价值的数据:使用传统的关系型数据库存储一些大尺寸低价值数据时会比较浪费,在此之前,很多时候程序员往往会选择传统的文件进行存储。
- 高伸缩性的场景:MongoDB 非常适合由数十或数百台服务器组成的数据库,MongoDB 的路线图中已经包含对 MapReduce 引擎的内置支持以及集群高可用的解决方案。
- 用于对象及 JSON 数据的存储:MongoDB 的 BSON 数据格式非常适合文档化格式的存储及查询。
MongoDB 的行业具体应用场景
- 游戏场景,使用 MongoDB 存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储,方便查询、更新。
- 物流场景,使用 MongoDB 存储订单信息,订单状态在运送过程中会不断更新,以 MongoDB 内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来。
- 社交场景,使用 MongoDB 存储存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能。
- 物联网场景,使用 MongoDB 存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析。
- 直播,使用 MongoDB 存储用户信息、礼物信息等。
如何抉择是否使用 MongoDB
| 应用特征 | Yes / No |
|---|---|
| 应用不需要事务及复杂 join 支持 | 必须 Yes |
| 新应用,需求会变,数据模型无法确定,想快速迭代开发 | ? |
| 应用需要 2000-3000 以上的读写 QPS(更高也可以) | ? |
| 应用需要 TB 甚至 PB 级别数据存储 | ? |
| 应用发展迅速,需要能快速水平扩展 | ? |
| 应用要求存储的数据不丢失 | ? |
| 应用需要 99.999% 高可用 | ? |
| 应用需要大量的地理位置查询、文本查询 | ? |
满足一个特征就推荐使用了
Java 访问 MongoDB
-
pom.xml
<dependency> <groupId>org.mongodb</groupId> <artifactId>mongo-java-driver</artifactId> <version>3.10.1</version> </dependency> -
Java
// com.lagou.test.DocumentTest /* use lagou; db.lg_resume_preview.insert({name:"张三",birthday:new ISODate("2000-07-01"),expectSalary:3000,gender:1,city:"bj"}); db.lg_resume_preview.insert({name:"李四",birthday:new ISODate("2000-07-01"),expectSalary:4000,gender:0,city:"bj"}); db.lg_resume_preview.insert({name:"王五",birthday:new ISODate("2000-07-01"),expectSalary:5000,gender:0,city:"sh"}); */ public class DocumentTest { private MongoClient mongoClient; private MongoDatabase mongoDatabase; private MongoCollection<Document> collection; @Before public void before() { mongoClient = new MongoClient("127.0.0.1", 27017); // 获取数据库对象 mongoDatabase = mongoClient.getDatabase("lagou"); // 获取集合对象 collection = mongoDatabase.getCollection("lg_resume_preview"); } @After public void after() { mongoClient.close(); } @Test public void testFind() { // 要根据expectSalary 降序排列 Document sortDocument = new Document(); // 1 - 升序;-1 - 降序 sortDocument.append("gender", 1); FindIterable<Document> findIterable = collection.find().sort(sortDocument); for (Document document : findIterable) { System.out.println(document); } } @Test public void testFindFilter() { // 要根据expectSalary 降序排列 Document sortDocument = new Document(); sortDocument.append("expectSalary", -1); // FindIterable<Document> findIterable = collection.find(Document.parse("{expectSalary:{$gt:21000}}")).sort(sortDocument); FindIterable<Document> findIterable = collection.find(Filters.gt("expectSalary", 3000)).sort(sortDocument); for (Document document : findIterable) { System.out.println(document); } } @Test public void testInsert() { // 构建Document 对象 并插入到集合中 Document document = Document.parse("{name:'lisi',city:'北京',birth_day:new ISODate('2001-08-01'),expectSalary:18000}"); collection.insertOne(document); } }
Spring 访问 MongoDB
-
pom.xml
<dependency> <groupId>org.springframework.data</groupId> <artifactId>spring-data-mongodb</artifactId> <version>2.0.9.RELEASE</version> </dependency> -
applicationContext.xml
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:mongo="http://www.springframework.org/schema/data/mongo" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/data/mongo http://www.springframework.org/schema/data/mongo/spring-mongo.xsd"> <mongo:db-factory id="mongoDbFactory" client-uri="mongodb://localhost:27017/lagou"></mongo:db-factory> <bean id="mongoTemplate" class="org.springframework.data.mongodb.core.MongoTemplate"> <constructor-arg index="0" ref="mongoDbFactory"></constructor-arg> </bean> <context:component-scan base-package="com.lagou"></context:component-scan> </beans> -
Java
// com.lagou.bean.Resume @Data public class Resume { private String id; private String name; private String city; private Date birthday; private double expectSalary; }// com.lagou.dao.ResumeDAO public interface ResumeDAO { void insertResume(Resume resume); /** * 根据name 获取Resume 对象 */ Resume findByName(String name); List<Resume> findList(String name); /** * 根据name 和 expectSalary 查询 */ List<Resume> findListByNameAndExpectSalary(String name, double expectSalary); }// com.lagou.dao.impl.ResumeDAOImpl @Repository("resumeDao") public class ResumeDAOImpl implements ResumeDAO { @Autowired private MongoTemplate mongoTemplate; @Override public void insertResume(Resume resume) { //mongoTemplate.insert(resume); mongoTemplate.insert(resume, "lg_resume_datas"); } @Override public Resume findByName(String name) { Query query = new Query(); query.addCriteria(Criteria.where("name").is(name)); List<Resume> datas = mongoTemplate.find(query, Resume.class, "lg_resume_datas"); return datas.isEmpty() ? null : datas.get(0); } @Override public List<Resume> findList(String name) { Query query = new Query(); query.addCriteria(Criteria.where("name").is(name)); List<Resume> datas = mongoTemplate.find(query, Resume.class, "lg_resume_datas"); return datas; } @Override public List<Resume> findListByNameAndExpectSalary(String name, double expectSalary) { Query query = new Query(); //query.addCriteria(Criteria.where("name").is(name).andOperator(Criteria.where("expectSalary").is(expectSalary))); query.addCriteria(Criteria.where("name").is(name).andOperator(Criteria.where("expectSalary").is(expectSalary))); return mongoTemplate.find(query, Resume.class, "lg_resume_datas"); } }// com.lagou.MongoTemplateMain public class MongoTemplateMain { public static void main(String[] args) { ClassPathXmlApplicationContext applicationContext = new ClassPathXmlApplicationContext("applicationContext.xml"); ResumeDAO resumeDao = applicationContext.getBean("resumeDao", ResumeDAO.class); // 插入数据 Resume resume = new Resume(); resume.setName("lisi"); resume.setCity("北京"); resume.setBirthday(new Date()); resume.setExpectSalary(28000); resumeDao.insertResume(resume); // 查询数据 resume = resumeDao.findByName("lisi"); System.out.println(resume); List<Resume> datas = resumeDao.findList("zhangsan"); System.out.println(datas); List<Resume> datas2 = resumeDao.findListByNameAndExpectSalary("zhangsan", 25000); System.out.println(datas2); } }
Spring Boot 访问 MongoDB
MongoTemplate 的方式
-
pom.xml
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-mongodb</artifactId> <version>2.2.2.RELEASE</version> </dependency> -
application.properties
spring.data.mongodb.host=localhost spring.data.mongodb.port=27017 spring.data.mongodb.database=lagou -
Java
// com.lagou.bean.Resume // com.lagou.dao.ResumeDAO // com.lagou.dao.impl.ResumeDAOImpl // 三个 Java 文件同上// com.lagou.MongoTemplateMain @SpringBootApplication public class MongoTemplateMain { public static void main(String[] args) { ApplicationContext applicationContext = SpringApplication.run(MongoTemplateMain.class, args); ResumeDAO resumeDao = applicationContext.getBean("resumeDao", ResumeDAO.class); Resume resume = new Resume(); resume.setName("zhangsan"); resume.setCity("北京"); resume.setBirthday(new Date()); resume.setExpectSalary(25000); resumeDao.insertResume(resume); System.out.println("resume=" + resume); Resume resume2 = resumeDao.findByName("lisi"); System.out.println(resume2); List<Resume> datas = resumeDao.findList("zhangsan"); System.out.println(datas); List<Resume> datas2 = resumeDao.findListByNameAndExpectSalary("zhangsan", 25000); System.out.println(datas2); } }
MongoRepository 的方式
-
pom.xml 同上
-
application.properties 同上
-
Java
// com.lagou.bean.Resume @Data @Document("lg_resume_datas") public class Resume { private String id; private String name; private String city; private Date birthday; private double expectSalary; }// com.lagou.repository.ResumeRepository public interface ResumeRepository extends MongoRepository<Resume, String> { List<Resume> findByNameEquals(String name); List<Resume> findByNameAndExpectSalary(String name, double expectSalary); }// com.lagou.MongoRepositoryMain @SpringBootApplication public class MongoRepositoryMain { public static void main(String[] args) { ApplicationContext applicationContext = SpringApplication.run(MongoRepositoryMain.class, args); ResumeRepository resumeRepository = applicationContext.getBean(ResumeRepository.class); System.out.println(resumeRepository.findAll()); System.out.println(resumeRepository.findByNameEquals("zhangsan")); System.out.println(resumeRepository.findByNameAndExpectSalary("zhangsan", 25000)); Resume resume = new Resume(); resume.setName("hwj"); resume.setExpectSalary(1); resume.setCity("bj"); resumeRepository.save(resume); } }
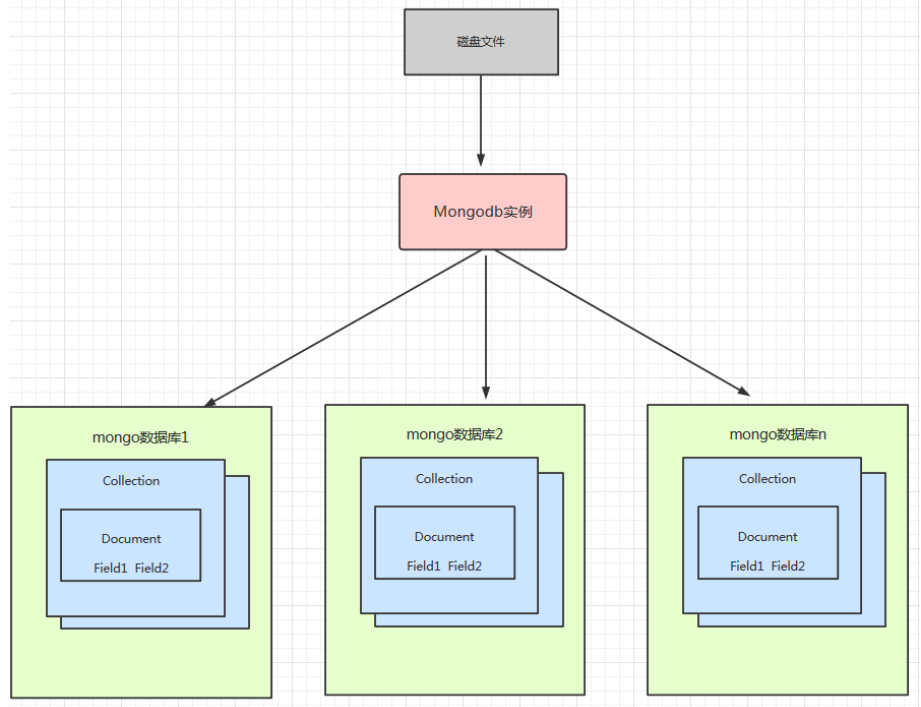
MongoDB 架构
MongoDB 逻辑结构

MongoDB 与 MySQL 中的架构相差不多,底层都使用了可插拔的存储引擎以满足用户的不同需要。用户可以根据程序的数据特征选择不同的存储引擎,在最新版本的 MongoDB 中使用了 WiredTiger 作为默认的存储引擎,WiredTiger 提供了不同粒度的并发控制和压缩机制,能够为不同种类的应用提供了最好的性能和存储率。
在存储引擎上层的就是 MongoDB 的数据模型和查询语言了,由于 MongoDB 对数据的存储与 RDBMS 有较大的差异,所以它创建了一套不同的数据模型和查询语言
MongoDB 的数据模型
描述数据模型
-
内嵌
内嵌的方式指的是把相关联的数据保存在同一个文档结构之中。MongoDB 的文档结构允许一个字段或者一个数组内的值作为一个嵌套的文档。
-
引用
引用方式通过存储数据引用信息来实现两个不同文档之间的关联,应用程序可以通过解析这些数据引用来访问相关数据。
如何选择数据模型
- 选择内嵌:
- 数据对象之间有包含关系,一般是数据对象之间有一对多或者一对一的关系 。
- 需要经常一起读取的数据。
- 有 map-reduce/aggregation 需求的数据放在一起,这些操作都只能操作单个 collection。
- 选择引用:
- 当内嵌数据会导致很多数据的重复,并且读性能的优势又不足于覆盖数据重复的弊端 。
- 需要表达比较复杂的多对多关系的时候 。
- 大型层次结果数据集,嵌套不要太深。
MongoDB 存储引擎
存储引擎概述
- 存储引擎是 MongoDB 的核心组件,负责管理数据如何存储在硬盘和内存上。
- MongoDB 支持的存储引擎有 MMAPv1 , WiredTiger 和 InMemory 。
- InMemory 存储引擎用于将数据只存储在内存中,只将少量的元数据( meta-data )和诊断日志( Diagnostic )存储到硬盘文件中,由于不需要 Disk 的 IO 操作,就能获取所需的数据, InMemory 存储引擎大幅度降低了数据查询的延迟( Latency )。
- 从 MongoDB 3.2 开始默认的存储引擎是 WiredTiger , 3.2 版本之前的默认存储引擎是 MMAPv1 , MongoDB 4.x 版本不再支持 MMAPv1 存储引擎。
storage:
journal:
enabled: true
dbPath: /data/mongo/
##是否一个库一个文件夹
directoryPerDB: true
##数据引擎
engine: wiredTiger
##WT引擎配置
WiredTiger:
engineConfig:
##WT最大使用cache(根据服务器实际情况调节)
cacheSizeGB: 2
##是否将索引也按数据库名单独存储
directoryForIndexes: true
# (默认snappy)
journalCompressor: none
##表压缩配置
collectionConfig:
# (默认snappy,还可选none、zlib)
blockCompressor: zlib
##索引配置
indexConfig:
prefixCompression: true
WiredTiger 存储引擎优势
-
文档空间分配方式
WiredTiger使用的是 BTree 存储,MMAPV1 是线性存储,需要 Padding
-
并发级别
WiredTiger 文档级别锁 MMAPV1 引擎使用表级锁
-
数据压缩
snappy (默认) 和 zlib,相比 MMAPV1(无压缩) 空间节省数倍。
-
内存使用
WiredTiger 可以指定内存的使用大小。
-
Cache 使用
WT 引擎使用了二阶缓存 WiredTiger Cache ,File System Cache 来保证 Disk 上的数据的最终一致性。
而 MMAPv1 只有 journal 日志。
WiredTiger 引擎包含的文件和作用
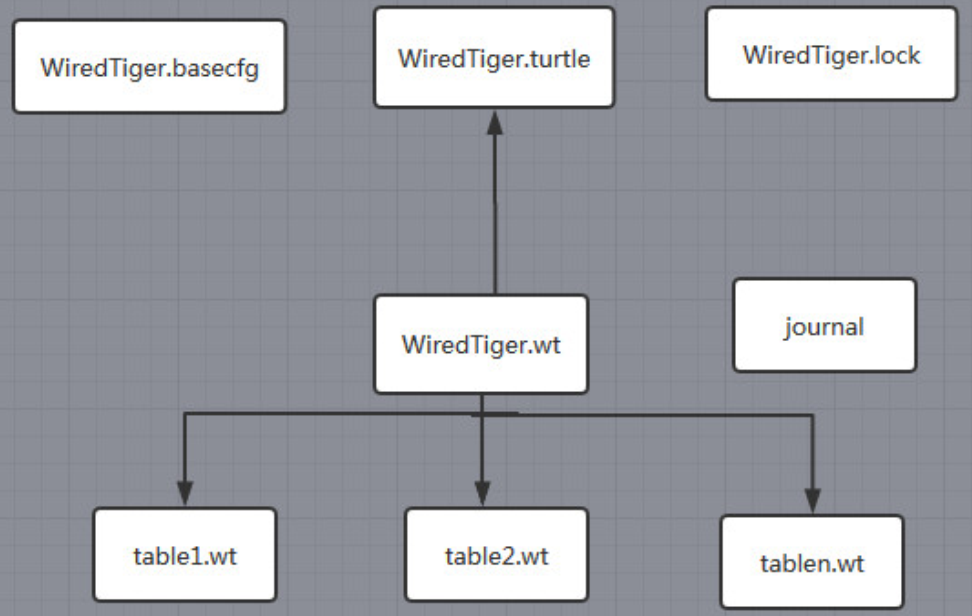
WiredTiger.basecfg: 存储基本配置信息,与 ConfigServer 有关系WiredTiger.lock:定义锁操作table*.wt:存储各张表的数据WiredTiger.wt:存储table*的元数据WiredTiger.turtle:存储WiredTiger.wt的元数据journal:存储 WAL(Write Ahead Log)
WiredTiger存储引擎实现原理
写请求
WiredTiger 的写操作会默认写入 Cache ,并持久化到 WAL ( Write Ahead Log ),每 60s 或 Log 文件达到 2G 做一次 checkpoint (当然我们也可以通过在写入时传入 j: true 的参数强制 journal 文件的同步 ,writeConcern({ w: , j: , wtimeout: }) 产生快照文件。WiredTiger 初始化时,恢复至最新的快照状态,然后再根据 WAL 恢复数据,保证数据的完整性。
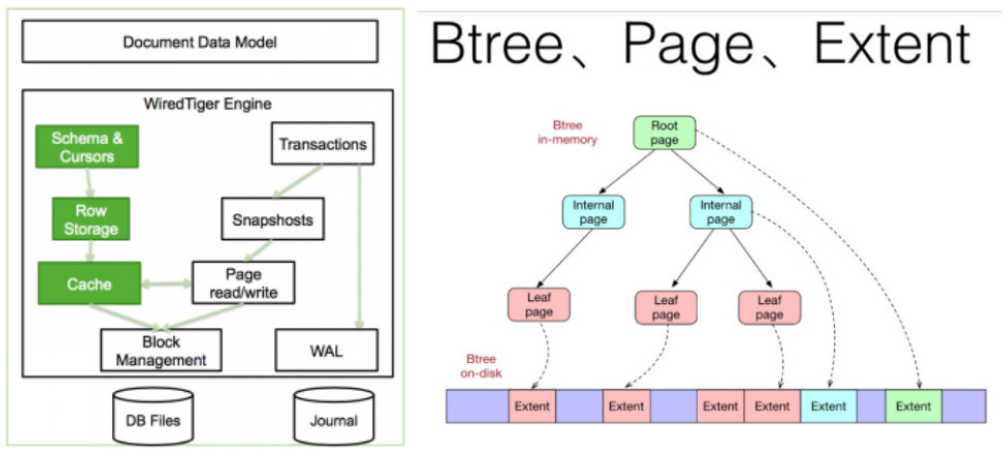
Cache 是基于 BTree 的,节点是一个 page , root page 是根节点, internal page 是中间索引节点, leaf page 真正存储数据,数据以 page 为单位读写。
WiredTiger 采用 Copy on write 的方式管理写操作( insert 、 update 、 delete ),写操作会先缓存在 cache 里,持久化时,写操作不会在原来的 leaf page 上进行,而是写入新分配的 page ,每次 checkpoint 都会产生一个新的 root page 。
checkpoint 流程
- 对所有的 table 进行一次 checkpoint ,每个 table 的 checkpoint 的元数据更新至
WiredTiger.wt - 对
WiredTiger.wt进行 checkpoint ,将该 table checkpoint 的元数据更新至临时文件WiredTiger.turtle.set - 将
WiredTiger.turtle.set重命名为WiredTiger.turtle - 上述过程如果中间失败, WiredTiger 在下次连接初始化时,首先将数据恢复至最新的快照状态,然后根据 WAL 恢复数据,以保证存储可靠性。
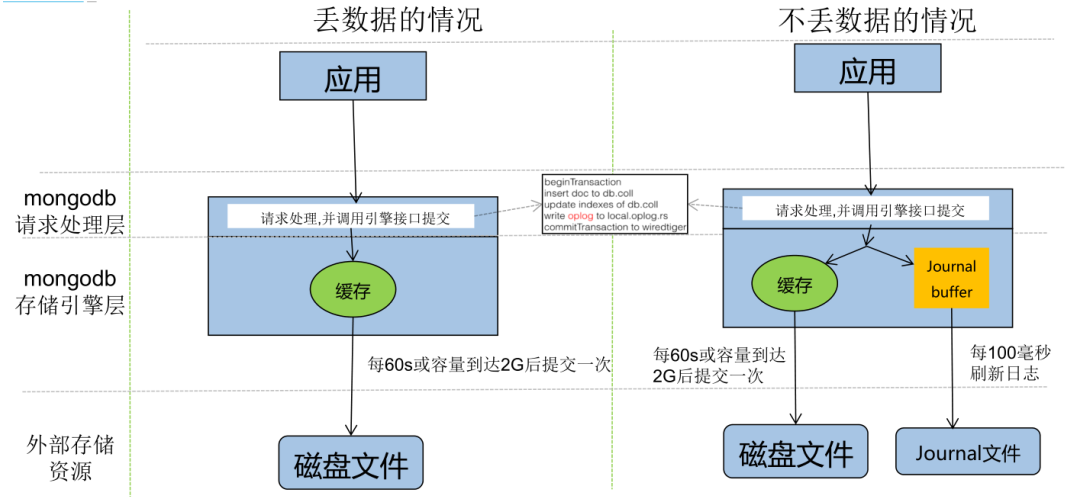
Journaling
在数据库宕机时 , 为保证 MongoDB 中数据的持久性, MongoDB 使用了 Write Ahead Logging 向磁盘上的 journal 文件预先进行写入。除了 journal 日志, MongoDB 还使用检查点( checkpoint )来保证数据的一致性,当数据库发生宕机时,我们就需要 checkpoint 和 journal 文件协作完成数据的恢复工作。
- 在数据文件中查找上一个检查点的标识符
- 在 journal 文件中查找标识符对应的记录
- 重做对应记录之后的全部操作
MongoDB集群高可用
MongoDB 主从复制架构原理和缺陷
master-slave 架构中 master 节点负责数据的读写,slave 没有写入权限只负责读取数据。
在主从结构中,主节点的操作记录成为 oplog ( operation log )。 oplog 存储在系统数据库 local 的 oplog.$main 集合中,这个集合的每个文档都代表主节点上执行的一个操作。从服务器会定期从主服务器中获取 oplog 记录,然后在本机上执行!对于存储 oplog 的集合, MongoDB 采用的是固定集合,也就是说随着操作过多,新的操作会覆盖旧的操作!
主从结构没有自动故障转移功能,需要指定 master 和 slave 端,不推荐在生产中使用。
MongoDB 4.0 后不再支持主从复制!
[main] Master/slave replication is no longer supported
复制集 replica sets
什么是复制集
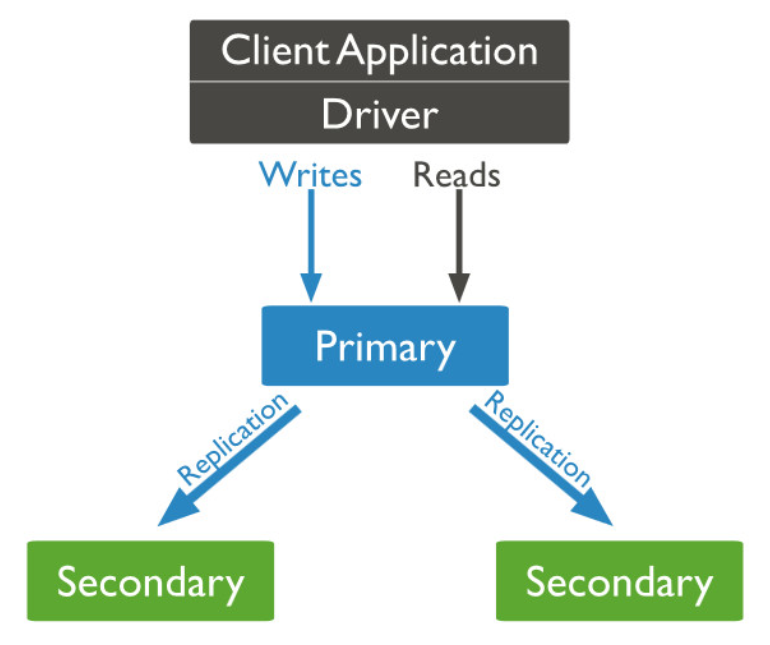
复制集是由一组拥有相同数据集的 mongod 实例做组成的集群。
复制集是一个集群,它是2台及2台以上的服务器组成,以及复制集成员包括Primary主节点,secondary从节点
和投票节点。
复制集提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性,保证数据的安全
性。
为什么要使用复制集
-
高可用
防止设备(服务器、网络)故障。
提供自动 failover 功能。
技术来保证高可用
-
灾难恢复
当发生故障时,可以从其他节点恢复 用于备份。
-
功能隔离
我们可以在备节点上执行读操作,减少主节点的压力
比如:用于分析、报表,数据挖掘,系统任务等。
复制集集群架构原理
一个复制集中 Primary 节点上能够完成读写操作, Secondary 节点仅能用于读操作。 Primary 节点需要记录所有改变数据库状态的操作,这些记录保存在 oplog 中,这个文件存储在 local 数据库,各个 Secondary 节点通过此 oplog 来复制数据并应用于本地,保持本地的数据与主节点的一致。 oplog 具有幂等性,即无论执行几次其结果一致,这个比 MySQL 的二进制日志更好用。
oplog 的组成结构:
{
"ts" : Timestamp(1446011584, 2),
"h" : NumberLong("1687359108795812092"),
"v" : 2,
"op" : "i",
"ns" : "test.nosql",
"o" : {
"_id" : ObjectId("563062c0b085733f34ab4129"),
"name" : "mongodb",
"score" : "10"
}
}
ts:操作时间,当前 timestamp + 计数器,计数器每秒都被重置h:操作的全局唯一标识v:oplog 版本信息op:操作类型i:插入操作u:更新操作d:删除操作c:执行命令(如createDatabase,dropDatabase)
n:空操作,特殊用途ns:操作针对的集合o:操作内容o2:更新查询条件,仅 update 操作包含该字段
复制集数据同步分为初始化同步和 keep 复制同步。初始化同步指全量从主节点同步数据,如果 Primary 节点数据量比较大同步时间会比较长。
而 keep 复制指初始化同步过后,节点之间的实时同步一般是增量同步。
初始化同步有以下两种情况会触发:
- Secondary 第一次加入
- Secondary 落后的数据量超过了 oplog 的大小,这样也会被全量复制
MongoDB 的 Primary 节点选举基于心跳触发。一个复制集 N 个节点中的任意两个节点维持心跳,每个节点维护其他 N-1 个节点的状态。
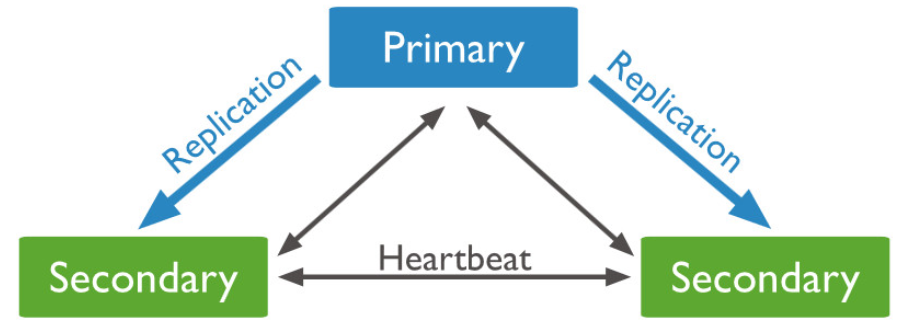
心跳检测:整个集群需要保持一定的通信才能知道哪些节点活着哪些节点挂掉。 MongoDB 节点会向副本集中的其他节点每 2 秒就会发送一次 pings 包,如果其他节点在 10 秒钟之内没有返回就标示为不能访问。每个节点内部都会维护一个状态映射表,表明当前每个节点是什么角色、日志时间戳等关键信息。如果主节点发现自己无法与大部分节点通讯则把自己降级为 Secondary 只读节点。
主节点选举触发的时机:
- 第一次初始化一个复制集
- Secondary 节点权重比 Primary 节点高时,发起替换选举
- Secondary 节点发现集群中没有 Primary 时,发起选举
- Primary 节点不能访问到大部分(Majority)成员时主动降级
当触发选举时, Secondary 节点尝试将自身选举为 Primary 。主节点选举是一个二阶段过程 + 多数派协议。
-
第一阶段:
检测自身是否有被选举的资格,如果符合资格会向其它节点发起本节点是否有选举资格的 FreshnessCheck,进行同僚仲裁
-
第二阶段:
发起者向集群中存活节点发送 Elect (选举)请求,仲裁者收到请求的节点会执行一系列合法性检查,如果检查通过,则仲裁者(一个复制集中最多 50 个节点 其中只有 7 个具有投票权)给发起者投一票。
pv0 通过 30 秒选举锁防止一次选举中两次投票。
pv1 使用了 terms (一个单调递增的选举计数器)来防止在一次选举中投两次票的情况。
多数派协议:
发起者如果获得超过半数的投票,则选举通过,自身成为 Primary 节点。获得低于半数选票的原因,除了常见的网络问题外,相同优先级的节点同时通过第一阶段的同僚仲裁并进入第二阶段也是一个原因。因此,当选票不足时,会 sleep[0, 1] 秒内的随机时间,之后再次尝试选举。
复制集搭建时,成员的配置参数
| 参数字段 | 类型说明 | 取值 | 说明 |
|---|---|---|---|
_id |
整数 | _id:0 | 复制集中的标示 |
host |
字符串 | host:"主机:端口" | 节点主机名 |
arbiterOnly |
布尔值 | arbiterOnly:true | 是否为仲裁(裁判)节点 |
priority |
整数 | priority=0|1 | 权重,默认1,是否有资格变成主节点,取值范围0-1000,0永远不 会变成主节点 |
hidden |
布尔值 | hidden=true|false,0|1 | 隐藏,权重必须为0,才可以设置 |
votes |
整数 | votes= 0|1 | 投票,是否为投票节点,0 不投票,1投票 |
slaveDelay |
整数 | slaveDelay=3600 | 从库的延迟多少秒 |
buildIndexes |
布尔值 | buildIndexes=true|false,0|1 | 主库的索引,从库也创建,_id索引无效 |
有仲裁节点复制集搭建
// 增加节点
rs.addArb("IP:端口");
// 增加仲裁节点
rs.addArb("192.168.211.133:37020");
分片集群 Shard Cluster
什么是分片
分片( sharding )是 MongoDB 用来将大型集合水平分割到不同服务器(或者复制集)上所采用的方法。不需要功能强大的大型计算机就可以存储更多的数据,处理更大的负载。
为什么要分片
- 存储容量需求超出单机磁盘容量。
- 活跃的数据集超出单机内存容量,导致很多请求都要从磁盘读取数据,影响性能。
- IOPS 超出单个 MongoDB 节点的服务能力,随着数据的增长,单机实例的瓶颈会越来越明显。
- 副本集具有节点数量限制。
垂直扩展:增加更多的CPU和存储资源来扩展容量。
水平扩展:将数据集分布在多个服务器上。水平扩展即分片。
分片的工作原理
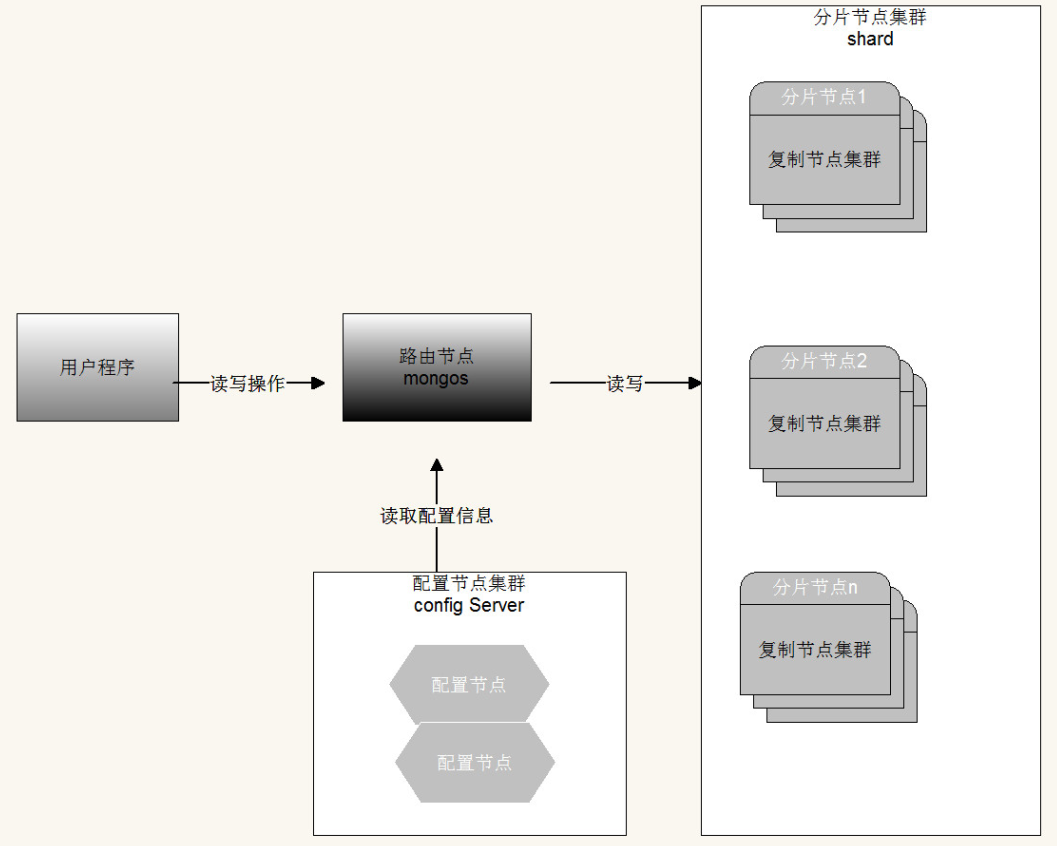
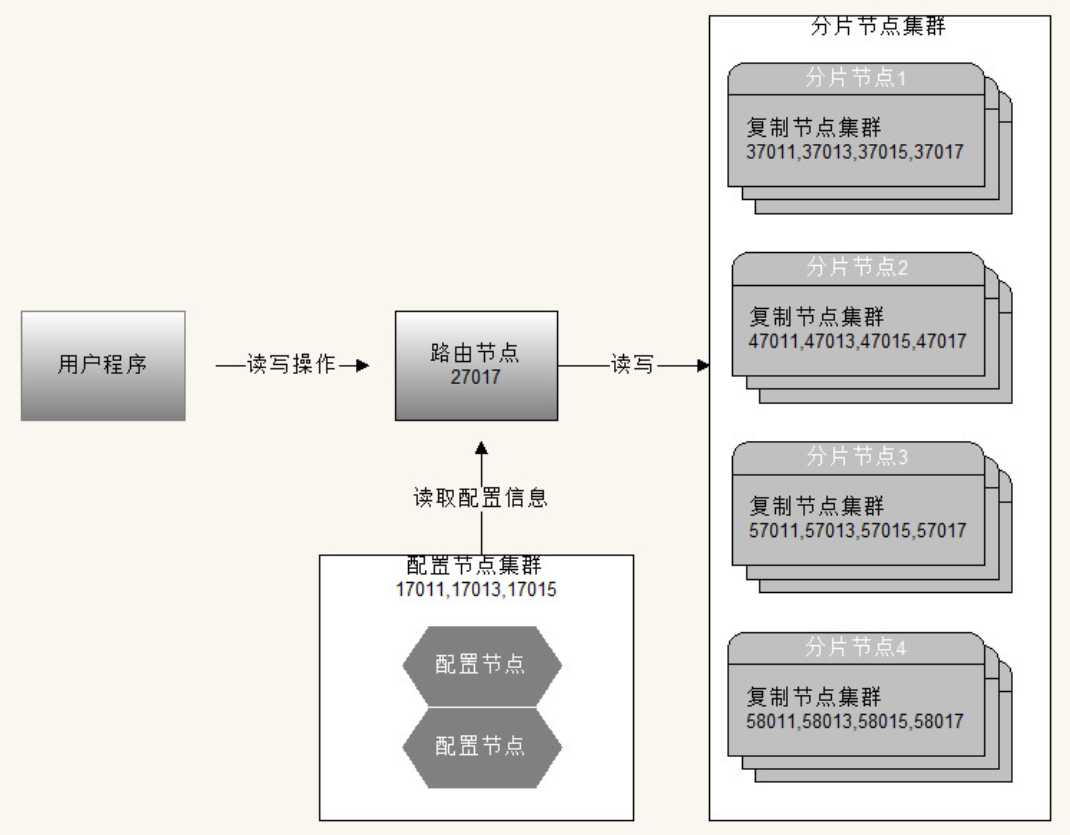
分片集群由以下 3 个服务组成:
- Shards Server : 每个 shard 由一个或多个 mongod 进程组成,用于存储数据。
- Router Server : 数据库集群的请求入口,所有请求都通过 Router ( mongos )进行协调,不需要在应用程序添加一个路由选择器, Router ( mongos )就是一个请求分发中心它负责把应用程序的请求转发到对应的 Shard 服务器上。
- Config Server : 配置服务器。存储所有数据库元信息(路由、分片)的配置。
片键(shard key)
为了在数据集合中分配文档,MongoDB 使用分片主键分割集合。
区块(chunk)
在一个 shard server 内部, MongoDB 还是会把数据分为 chunks ,每个 chunk 代表这个 shard server 内部一部分数据。 MongoDB 分割分片数据到区块,每一个区块包含基于分片主键的左闭右开的区间范围。
分片策略
-
范围分片(Range based sharding)
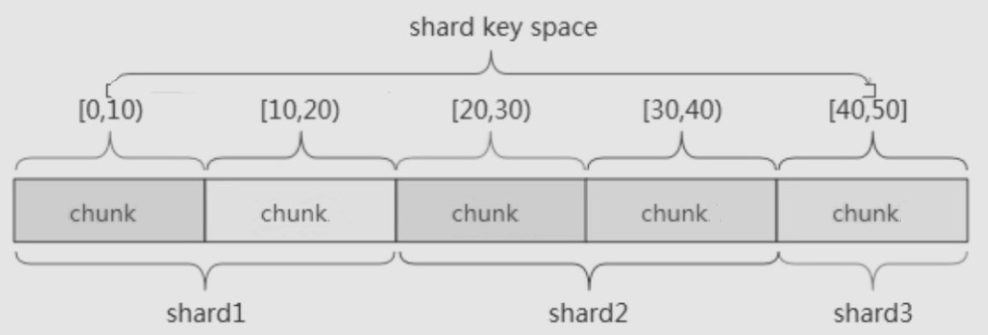
- 范围分片是基于分片主键的值切分数据,每一个区块将会分配到一个范围。
- 范围分片适合满足在一定范围内的查找,例如查找 X 的值在 [20, 30) 之间的数据, mongo 路由根据 Config server 中存储的元数据,可以直接定位到指定的 shard 的 Chunk 中。
- 缺点: 如果 shard key 有明显递增(或者递减)趋势,则新插入的文档多会分布到同一个 chunk ,无法扩展写的能力。
-
hash 分片(Hash based sharding)
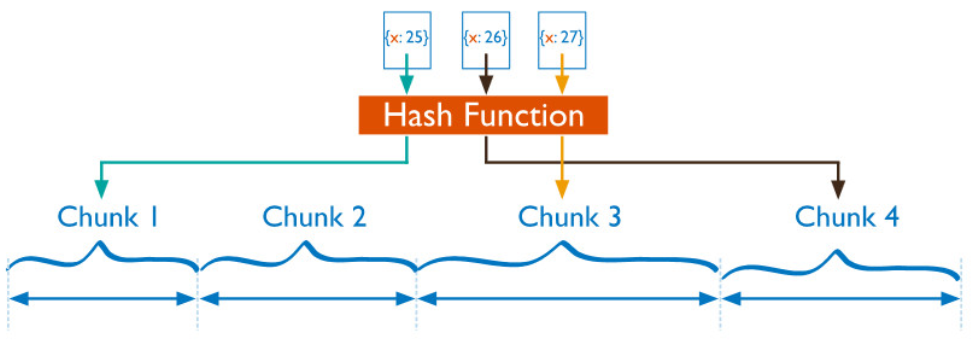
- Hash 分片是计算一个分片主键的 hash 值,每一个区块将分配一个范围的 hash 值。
- Hash 分片与范围分片互补,能将文档随机的分散到各个 chunk ,充分的扩展写能力,弥补了范围分片的不足,缺点是不能高效的服务范围查询,所有的范围查询要分发到后端所有的 Shard 才能找出满足条件的文档。
-
组合片键 A + B (散列思想 不能是直接 hash )
数据库中没有比较合适的片键供选择,或者是打算使用的片键基数太小(即变化少如星期只有 7 天可变化),可以选另一个字段使用组合片键,甚至可以添加冗余字段来组合。一般是粗粒度 + 细粒度进行组合。
合理的选择 shard key
无非从两个方面考虑,数据的查询和写入,最好的效果就是数据查询时能命中更少的分片,数据写入时能够随机的写入每个分片,关键在于如何权衡性能和负载。
分片集群的搭建过程
环境信息
- MongoDB 版本:
4.1.3
集群配置
主机 IP:192.168.181.134
尾数为 7 的分片节点是仲裁节点
- 分片节点
- shard1:37011,37013,37015,37017
- shard2:47011,47013,47015,47017
- shard3:57011,57013,57015,57017
- shard4:58011,58013,58015,58017
- 配置节点
- config:17011,17013,17015
- 路由节点
- route:27017
目录结构
/mongodb
|- bin
|- conf
|----|- shard1 ... shard4
|----|----|- server_37011.conf ...
|----|- config
|----|----|- config_17011.conf ...
|----|- route
|----|----|- route_27017.conf ...
|- data
|----|- shard1 ... shard4
|----|----|- server_37011 ...
|----|- config
|----|----|- config_17011 ...
|- logs
|----|- shard1 ... shard4
|----|----|- server_37011.log ...
|----|- config
|----|----|- config_17011.log ...
|----|- route
|----|----|- route_27017.log ...
节点配置
分片节点
dbpath=/mongodb/data/shard1/server_37011
bind_ip=0.0.0.0
port=37011
fork=true
logpath=/mongodb/logs/shard1/server_37011.log
replSet=shard1
shardsvr=true
配置节点
dbpath=/mongodb/data/config/config_17011
logpath=/mongodb/logs/config/config_17011.log
logappend=true
fork = true
bind_ip=0.0.0.0
port = 17011
configsvr=true
replSet=configsvr
路由节点
port=27017
bind_ip=0.0.0.0
fork=true
logpath=/mongodb/logs/route/route_27017.log
configdb=configsvr/192.168.181.134:17011,192.168.181.134:17013,192.168.181.134:17015
启动集群
启动顺序:
- 配置节点
- 分片节点
- 路由节点
配置节点
启动:
# 启动配置节点
/mongodb/bin/mongod -f /mongodb/conf/config/config_17011.conf
/mongodb/bin/mongod -f /mongodb/conf/config/config_17013.conf
/mongodb/bin/mongod -f /mongodb/conf/config/config_17015.conf
/mongodb/bin/mongo --host=192.168.181.134 --port=17011
配置:
use admin;
var cfg ={
"_id":"configsvr",
"members":[
{"_id":1,"host":"192.168.181.134:17011"},
{"_id":2,"host":"192.168.181.134:17013"},
{"_id":3,"host":"192.168.181.134:17015"}
]
};
rs.initiate(cfg)
分片节点
启动:
# 启动分片节点
/mongodb/bin/mongod -f /mongodb/conf/shard1/server_37011.conf
/mongodb/bin/mongod -f /mongodb/conf/shard1/server_37013.conf
/mongodb/bin/mongod -f /mongodb/conf/shard1/server_37015.conf
/mongodb/bin/mongod -f /mongodb/conf/shard1/server_37017.conf
/mongodb/bin/mongod -f /mongodb/conf/shard2/server_47011.conf
/mongodb/bin/mongod -f /mongodb/conf/shard2/server_47013.conf
/mongodb/bin/mongod -f /mongodb/conf/shard2/server_47015.conf
/mongodb/bin/mongod -f /mongodb/conf/shard2/server_47017.conf
/mongodb/bin/mongod -f /mongodb/conf/shard3/server_57011.conf
/mongodb/bin/mongod -f /mongodb/conf/shard3/server_57013.conf
/mongodb/bin/mongod -f /mongodb/conf/shard3/server_57015.conf
/mongodb/bin/mongod -f /mongodb/conf/shard3/server_57017.conf
/mongodb/bin/mongod -f /mongodb/conf/shard4/server_58011.conf
/mongodb/bin/mongod -f /mongodb/conf/shard4/server_58013.conf
/mongodb/bin/mongod -f /mongodb/conf/shard4/server_58015.conf
/mongodb/bin/mongod -f /mongodb/conf/shard4/server_58017.conf
# 批量终止进程
# ps aux|grep mongo|grep -v grep|awk '{print $2}'|xargs kill -9
配置:
# shard1
/mongodb/bin/mongo --host=192.168.181.134 --port=37011
var cfg ={
"_id":"shard1",
"protocolVersion" : 1,
"members":[
{"_id":1,"host":"192.168.181.134:37011","priority":10},
{"_id":2,"host":"192.168.181.134:37013","priority":5},
{"_id":3,"host":"192.168.181.134:37015","priority":5},
{"_id":4,"host":"192.168.181.134:37017","arbiterOnly":true}
]
};
rs.initiate(cfg);
rs.status();
## 分片字段需要有索引
use lg_resume;
# db.lg_resume_datas.getIndexes();
db.lg_resume_datas.createIndex({"name":1});
# shard2
/mongodb/bin/mongo --host=192.168.181.134 --port=47011
var cfg ={
"_id":"shard2",
"protocolVersion" : 1,
"members":[
{"_id":1,"host":"192.168.181.134:47011","priority":10},
{"_id":2,"host":"192.168.181.134:47013","priority":5},
{"_id":3,"host":"192.168.181.134:47015","priority":5},
{"_id":4,"host":"192.168.181.134:47017","arbiterOnly":true}
]
};
rs.initiate(cfg);
rs.status();
## 分片字段需要有索引
use lg_resume;
db.lg_resume_datas.createIndex({"name":1});
# shard3
/mongodb/bin/mongo --host=192.168.181.134 --port=57011
var cfg ={
"_id":"shard3",
"protocolVersion" : 1,
"members":[
{"_id":1,"host":"192.168.181.134:57011","priority":10},
{"_id":2,"host":"192.168.181.134:57013","priority":5},
{"_id":3,"host":"192.168.181.134:57015","priority":5},
{"_id":4,"host":"192.168.181.134:57017","arbiterOnly":true}
]
};
rs.initiate(cfg);
rs.status();
## 分片字段需要有索引
use lg_resume;
db.lg_resume_datas.createIndex({"name":1});
# shard4
/mongodb/bin/mongo --host=192.168.181.134 --port=58011
var cfg ={
"_id":"shard4",
"protocolVersion" : 1,
"members":[
{"_id":1,"host":"192.168.181.134:58011","priority":10},
{"_id":2,"host":"192.168.181.134:58013","priority":5},
{"_id":3,"host":"192.168.181.134:58015","priority":5},
{"_id":4,"host":"192.168.181.134:58017","arbiterOnly":true}
]
};
rs.initiate(cfg);
rs.status();
## 分片字段需要有索引
use lg_resume;
db.lg_resume_datas.createIndex({"name":1});
验证:
# 进入主节点 ----- 插入数据 ------ 进入从节点验证
# 主节点插入
use lagou;
db.lg_clusters.insert({port:37017});
# 从节点验证
rs.slaveOk();
use lagou;
db.lg_clusters.find();
路由节点
启动:
/mongodb/bin/mongos -f /mongodb/conf/route/route_27017.conf
/mongodb/bin/mongo --host=192.168.181.134 --port=27017
配置:
# 添加分片节点
sh.status();
sh.addShard("shard1/192.168.181.134:37011,192.168.181.134:37013,192.168.181.134:37015,192.168.181.134:37017");
sh.addShard("shard2/192.168.181.134:47011,192.168.181.134:47013,192.168.181.134:47015,192.168.181.134:47017");
sh.addShard("shard3/192.168.181.134:57011,192.168.181.134:57013,192.168.181.134:57015,192.168.181.134:57017");
sh.addShard("shard4/192.168.181.134:58011,192.168.181.134:58013,192.168.181.134:58015,192.168.181.134:58017");
sh.status();
# 开启数据库和集合分片(指定片键)
## 为数据库开启分片功能
sh.enableSharding("lg_resume");
## 为指定集合开启分片功能
sh.shardCollection("lg_resume.lg_resume_datas",{"name":"hashed"});
验证:
/mongodb/bin/mongo --host=192.168.181.134 --port=27017
# 插入测试数据
use lg_resume;
## 清库后,需要重新制定分片功能
## db.lg_resume_datas.drop();
## sh.shardCollection("lg_resume.lg_resume_datas",{"name":"hashed"});
for(var i=1;i<= 1000;i++){
db.lg_resume_datas.insert({"name":"test"+i, salary: (Math.random()*20000).toFixed(2)});
}
# 分别进入 shard1 和 shard2 中的数据库 进行验证
/mongodb/bin/mongo --host=192.168.181.134 --port=37011
use lg_resume;
db.lg_resume_datas.count();
db.lg_resume_datas.find();
权限控制
/mongodb/bin/mongo --host=192.168.181.134 --port=27017
use lg_resume;
db.createUser(
{
user:"lagou_gx",
pwd:"abc321",
roles:[{role:"readWrite",db:"lg_resume"}]
}
)
use lg_resume;
db.auth("lagou_gx","abc321");
# db.dropUser("lagou_gx");
Spring Boot 连接
验证:
use lg_resume;
db.lg_resume_datas.find({name:'hwj'});
MongoDB 安全认证
安全认证概述
- MongoDB 默认是没有账号的,可以直接连接,无须身份验证。
- 实际项目中肯定是要权限验证的,否则后果不堪设想。从 2016 年开始 发生了多起 MongoDB 黑客赎金事件,大部分 MongoDB 安全问题 暴露出了安全问题的短板其实是用户,首先用户对于数据库的安全不重视,其次用户在使用过程中可能没有养成定期备份的好习惯,最后是企业可能缺乏有经验和技术的专业人员。所以对 MongoDB 进行安全认证是必须要做的。
用户相关操作
切换到 admin 数据库对用户的添加
use admin;
db.createUser(userDocument):用于创建 MongoDB 登录用户以及分配权限的方法
db.createUser({
user: "账号",
pwd: "密码",
roles: [
{ role: "角色", db: "安全认证的数据库" },
{ role: "角色", db: "安全认证的数据库" }
]
})
user:创建的用户名称,如 admin、root 、lagoupwd:用户登录的密码roles:为用户分配的角色,不同的角色拥有不同的权限,参数是数组,可以同时设置多个role:角色,MongoDB 已经约定好的角色,不同的角色对应不同的权限db:数据库实例名称,如 MongoDB 4.0.2 默认自带的有 admin、local、config、test 等,即为哪个数据库实例设置用户
db.createUser({
user:"root",
pwd:"123321",
roles:[
{role:"root", db:"admin"}
]
})
其他操作
// 修改密码
db.changeUserPassword( 'root' , 'rootNew' );
// 用户添加角色
db.grantRolesToUser( '用户名' , [{ role: '角色名' , db: '数据库名'}])
// 以 auth 方向启动 mongod,(也可以在mongo.conf 中添加auth=true 参数)
./bin/mongod -f conf/mongo.conf --auth
// 验证用户
db.auth("账号","密码");
// 删除用户
db.dropUser("用户名")
角色
数据库内置的角色
| 角色 | 描述 |
|---|---|
read |
允许用户读取指定数据库 |
readWrite |
允许用户读写指定数据库 |
dbAdmin |
允许用户在指定数据库中执行管理函数,如索引创建、删除,查看统计或访问 system.profile |
userAdmin |
允许用户向 system.users 集合写入,可以找指定数据库里创建、删除和管理用户 |
clusterAdmin |
只在 admin 数据库中可用,赋予用户所有分片和复制集相关函数的管理权限 |
readAnyDatabase |
只在 admin 数据库中可用,赋予用户所有数据库的读权限 |
readWriteAnyDatabase |
只在 admin 数据库中可用,赋予用户所有数据库的读写权限 |
userAdminAnyDatabase |
只在 admin 数据库中可用,赋予用户所有数据库的 userAdmin 权限 |
dbAdminAnyDatabase |
只在 admin 数据库中可用,赋予用户所有数据库的 dbAdmin 权限 |
root |
只在 admin 数据库中可用。超级账号,超级权限 |
dbOwner |
库拥有者权限,即 readWrite、dbAdmin、userAdmin 角色的合体 |
各个类型用户对应的角色
- 数据库用户角色:
read、readWrite - 数据库管理角色:
dbAdmin、dbOwner、userAdmin - 集群管理角色:
clusterAdmin、clusterManager、clusterMonitor、hostManager - 备份恢复角色:
backup、restore - 所有数据库角色:
readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、dbAdminAnyDatabase - 超级用户角色:
root - 这里还有几个角色间接或直接提供了系统超级用户的访问(
dbOwner、userAdmin、userAdminAnyDatabase)
单机安全认证实现流程
创建 mydb1 数据库并创建了两个用户,zhangsan 拥有读写权限,lisi 拥有只读权限测试这两个账户的
权限。
以超级管理员登录测试权限。
创建管理员
MongoDB 服务端开启安全检查之前,至少需要有一个管理员账号,admin 数据库中的用户都被视为管理员
如果 admin 库没有任何用户的话,即使在其他数据库中创建了用户,启用身份验证,默认的连接方式依然会有超级权限,即仍然可以不验证账号密码照样能进行 CRUD,安全认证相当于无效。
use admin;
db;
db.createUser({
user:"root",
pwd:"123456",
roles:[{role:"root",db:"admin"}]
});
创建普通用户
如下所示 mydb1 是自己新建的数据库,没安全认证之前可以随意 CRUD ,其余的都是 MongoDB 4.0.2 自带的数据库:
show dbs;
use mydb1;
db.c1.insert({name:"testdb1"});
show tables;
db.c1.find();
use mydb1;
db;
db.createUser({
user:"zhangsan",
pwd:"123456",
roles:[
{role:"readWrite",db:"mydb1"}
]
})
db.createUser({
user:"lisi",
pwd:"123456",
roles:[
{role:"read",db:"mydb1"}
]
})
// 关闭服务端,重启
db.shutdownServer()
MongoDB 安全认证方式启动
mongod --dbpath=数据库路径 --port=端口 --auth
也可以在配置文件中 加入 auth=true
以普通用户登录验证权限
普通用户现在仍然像以前一样进行登录,如下所示直接登录进入 mydb1 数据库中,登录是成功的,只是登录后日志少了很多东西,而且执行 show dbs 命令,以及 show tables 等命令都是失败的,即使没有被安全认证的数据库,用户同样操作不了,这都是因为权限不足,一句话:用户只能在自己权限范围内的数据库中进行操作
db.auth("zhangsan","123456");
分片集群安全认证
-
开启安全认证之前,进入路由创建管理员和普通用户
-
关闭所有的配置节点、分片节点 和 路由节点
-
生成密钥文件,并修改权限
openssl rand -base64 756 > data/mongodb/testKeyFile.file chmod 600 data/mongodb/keyfile/testKeyFile.file -
配置节点集群和分片节点集群开启安全认证和指定密钥文件
auth=true keyFile=data/mongodb/testKeyFile.file -
在路由配置文件中设置密钥文件
keyFile=data/mongodb/testKeyFile.file -
启动所有的配置节点、分片节点 和 路由节点,使用路由进行权限验证
-
Spring Boot 连接安全认证的分片集群
spring.data.mongodb.username=账号 spring.data.mongodb.password=密码 #spring.data.mongodb.uri=mongodb://账号:密码@IP:端口/数据库名


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异