

20201217 Cluster模式潜在问题及解决方案、Web服务综合解决方案 - 拉勾教育
一致性 Hash 算法
- Hash 算法较多的应用在数据存储和查找领域
- 解决 Hash 冲突的方法
- 开放寻址法
- 拉链法
Hash 算法应用场景:
- 请求的负载均衡
- Nginx 的 ip_hash 策略
- 分布式存储
- Redis 集群,分区
普通 Hash 算法存在的问题:扩容或缩容导致服务数变化后,需要重新计算,全部重新分配,导致服务器会话丢失。
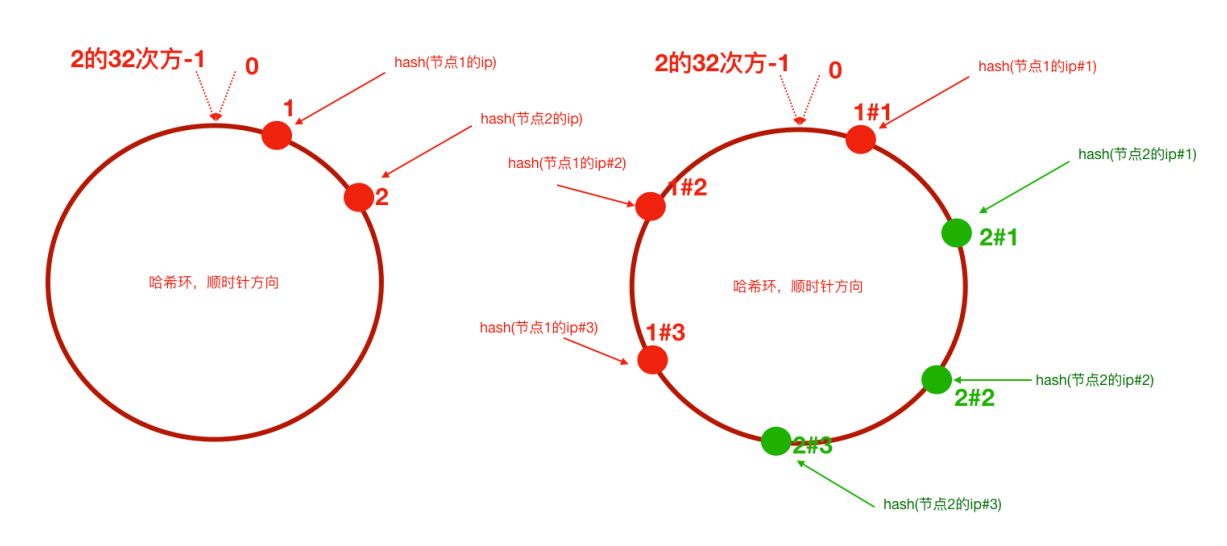
public class ConsistentHashWithVirtual {
public static void main(String[] args) {
//step1 初始化:把服务器节点IP的哈希值对应到哈希环上
// 定义服务器ip
String[] tomcatServers = new String[]{"123.111.0.0", "123.101.3.1", "111.20.35.2", "123.98.26.3"};
SortedMap<Integer, String> hashServerMap = new TreeMap<>();
// 定义针对每个真实服务器虚拟出来几个节点
int virtaulCount = 3;
for (String tomcatServer : tomcatServers) {
// 求出每一个ip的hash值,对应到hash环上,存储hash值与ip的对应关系
int serverHash = Math.abs(tomcatServer.hashCode());
// 存储hash值与ip的对应关系
hashServerMap.put(serverHash, tomcatServer);
// 处理虚拟节点
for (int i = 0; i < virtaulCount; i++) {
int virtualHash = Math.abs((tomcatServer + "#" + i).hashCode());
hashServerMap.put(virtualHash, "----由虚拟节点" + i + "映射过来的请求:" + tomcatServer);
}
}
//step2 针对客户端IP求出hash值
// 定义客户端IP
String[] clients = new String[]{"10.78.12.3", "113.25.63.1", "126.12.3.8"};
for (String client : clients) {
int clientHash = Math.abs(client.hashCode());
//step3 针对客户端,找到能够处理当前客户端请求的服务器(哈希环上顺时针最近)
// 根据客户端ip的哈希值去找出哪一个服务器节点能够处理()
SortedMap<Integer, String> integerStringSortedMap = hashServerMap.tailMap(clientHash);
if (integerStringSortedMap.isEmpty()) {
// 取哈希环上的顺时针第一台服务器
Integer firstKey = hashServerMap.firstKey();
System.out.println("==========>>>>客户端:" + client + " 被路由到服务器:" + hashServerMap.get(firstKey));
} else {
Integer firstKey = integerStringSortedMap.firstKey();
System.out.println("==========>>>>客户端:" + client + " 被路由到服务器:" + hashServerMap.get(firstKey));
}
}
}
}
Nginx 配置一致性 Hash 负载均衡策略
使用 Nginx 第三方模块 ngx_http_upstream_consistent_hash
-
安装模块
./configure --add-module=/root/ngx_http_consistent_hash-master make make install -
修改配置
upstream lagouServer { consistent_hash $request_uri; server localhost:8080; server localhost:8090; } -
Nginx reload
集群时钟同步问题
- 不同服务器可能存在时钟不一致的问题,如果集群中的服务器使用的不是相同时间,会导致严重问题
集群时钟同步思路:
-
分布式集群中各个服务器节点都可以连接互联网
# 使用 ntpdate 网络时间同步命令 ## 从⼀个时间服务器同步时间 ntpdate -u ntp.api.bz -
分布式集群中某一个服务器节点可以访问互联网或者所有节点都不能够访问互联网
-
选取集群中的一个服务器节点 A ( 172.17.0.17 )作为时间服务器(整个集群时间从这台服务器同步,如果这台服务器能够访问互联网,可以让这台服务器和网络时间保持同步,如果不能就手动设置一个时间)
-
首先设置好 A 的时间
-
把 A 配置为时间服务器(修改
/etc/ntp.conf文件)1、如果有 restrict default ignore ,注释掉它 2、添加如下几行内容 # 放开局域网同步功能, 172.17.0.0 是你的局域网网段 restrict 172.17.0.0 mask 255.255.255.0 nomodify notrap # local clock server 127.127.1.0 fudge 127.127.1.0 stratum 10 3、重启生效并配置 ntpd 服务开机自启动 service ntpd restart chkconfig ntpd on -
集群中其他节点就可以从A服务器同步时间了
ntpdate 172.17.0.17
-
-
分布式 ID 解决方案
分布式集群环境下的全局唯一 ID :
- UUID (可以用)
- 通用唯一识别码(Universally Unique Identifier)
- 产生重复 UUID 并造成错误的情况非常低
- 独立数据库的自增 ID
- SnowFlake 雪花算法(推荐)
- 借助 Redis 的 Incr 命令获取全局唯一 ID (推荐)
雪花算法
雪花算法是一个算法,基于这个算法可以生成 ID ,生成的 ID 是一个 long 型,那么在 Java 中一个 long 型是 8 个字节,算下来是 64 bit ,如下是使用雪花算法生成的一个 ID 的二进制形式示意:
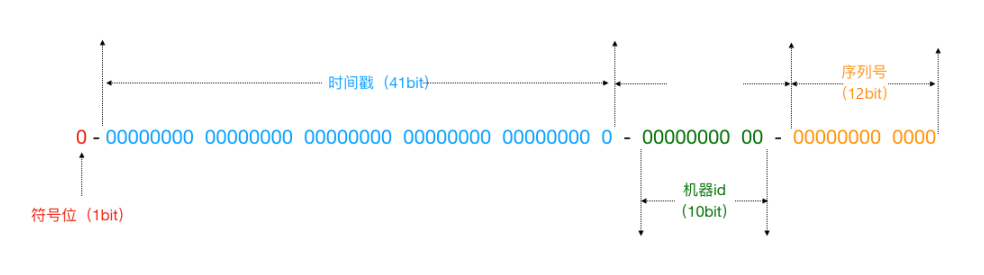
- 符号位:固定为 0 ,二进制表示最高位是符号位, 0 代表正数, 1 代表负数。
- 时间戳: 41 个二进制数用来记录时间戳,表示某一个毫秒(毫秒级)
- 机器 id :代表当前算法运行机器的 id
- 序列号: 12 位,用来记录某个机器同一个毫秒内产生的不同序列号,代表同一个机器同一个毫秒可以产生的 ID 序号。
- 雪花算法是 Twitter 推出的一个用于生成分布式 ID 的策略
- 一些互联网公司也基于上述的方案封装了一些分布式 ID 生成器
- 滴滴的 tinyid (基于数据库实现)
- 百度的 uidgenerator (基于 SnowFlake )
- 美团的 leaf (基于数据库和 SnowFlake )
分布式调度问题
参考:
使用定时任务的场景:
- 每隔⼀定时间执行
- 特定某⼀时刻执行
分布式任务调度有两层含义:
- 运行在分布式集群环境下的调度任务(同一个定时任务程序部署多份,只应该有一个定时任务在执行)
- 分布式调度 → 定时任务的分布式 → 定时任务的拆分(即为把一个大的作业任务拆分为多个小的作业任务,同时执行)
定时任务与消息队列的异同:
- 相同点:
- 异步处理
- 应用解耦
- 流量削峰
- 不同点:
- 定时任务作业是时间驱动,而 MQ 是事件驱动;
- 定时任务作业更倾向于批处理, MQ 倾向于逐条处理;
分布式调度框架 Elastic-Job
- Elastic-Job 是当当网开源的一个分布式调度解决方案,基于 Quartz 二次开发的,由两个相互独立的子项目 Elastic-Job-Lite 和 Elastic-Job-Cloud 组成。
- 我们要学习的是 Elastic-Job-Lite ,它定位为轻量级无中心化解决方案,使用 Jar 包的形式提供分布式任务的协调服务。
- Elastic-Job-Cloud 子项目需要结合 Mesos 以及 Docker 在云环境下使用。
- 已成为 Apache ShardingSphere 子项目,重新开始更新
- Github 地址
- TODO 3.x 版本变化巨大,等正式版发布后再进行学习
Elastic-Job 2 主要功能:
- 分布式调度协调
- 在分布式环境中,任务能够按指定的调度策略执行,并且能够避免同一任务多实例重复执行
- 丰富的调度策略
- 基于成熟的定时任务作业框架 Quartz cron 表达式执行定时任务
- 弹性扩容缩容
- 当集群中增加某一个实例,它应当也能够被选举并执行任务;当集群减少一个实例时,它所执行的任务能被转移到别的实例来执行。
- 失效转移
- 某实例在任务执行失败后,会被转移到其他实例执行
- 错过执行作业重触发
- 若因某种原因导致作业错过执行,自动记录错过执行的作业,并在上次作业完成后自动触发。
- 支持并行调度
- 支持任务分片,任务分片是指将一个任务分为多个小任务项在多个实例同时执行。
- 作业分片一致性
- 当任务被分片后,保证同一分片在分布式环境中仅一个执行实例。
Session 共享问题
- Session 在集群环境里不能保持一致性
- 从根本上来说是因为 Http 协议是无状态的协议。客户端和服务端在某次会话中产生的数据不会被保留下来,所以第二次请求服务端无法认识到你曾经来过
- 早期都是静态页面无所谓有无状态,后来有动态的内容更丰富,就需要有状态,出现了两种用于保持 Http 状态的技术,那就是 Cookie 和 Session
解决 Session 一致性的方案:
- Nginx 的 IP_Hash 策略(可以使用)
- Session 复制(不推荐)
- Session 共享, Session 集中存储(推荐)
- Spring Session 使得基于 Redis 的 Session 共享应用起来非常之简单
Spring Session
-
POM
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <dependency> <groupId>org.springframework.session</groupId> <artifactId>spring-session-data-redis</artifactId> </dependency> -
增加注解
@EnableCaching @EnableRedisHttpSession
源码参考:
org.springframework.session.data.redis.config.annotation.web.http.EnableRedisHttpSessionorg.springframework.session.data.redis.config.annotation.web.http.RedisHttpSessionConfigurationorg.springframework.session.config.annotation.web.http.SpringHttpSessionConfiguration#springSessionRepositoryFilterorg.springframework.session.web.http.SessionRepositoryFilter#doFilterInternal


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异