MapReduce的完整逻辑
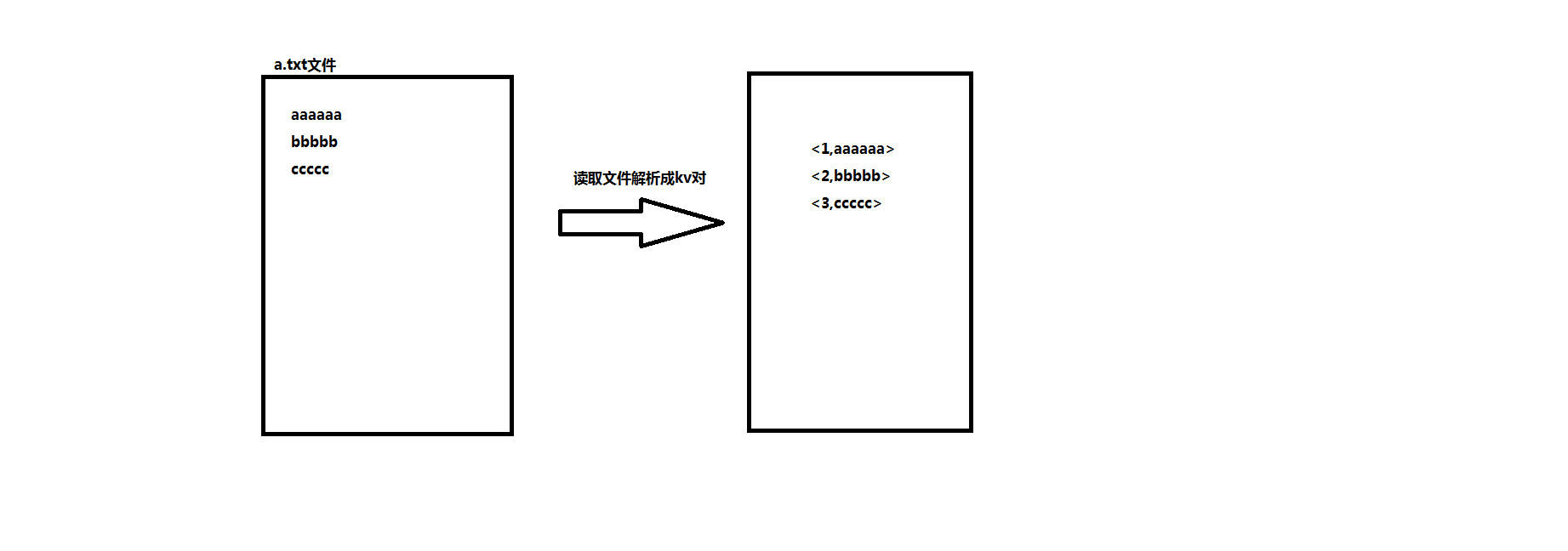
1、读取文件,将文件解析成一个<k1,v1>对
这里面的k1主要指的是行数,v1指的是该该行数据
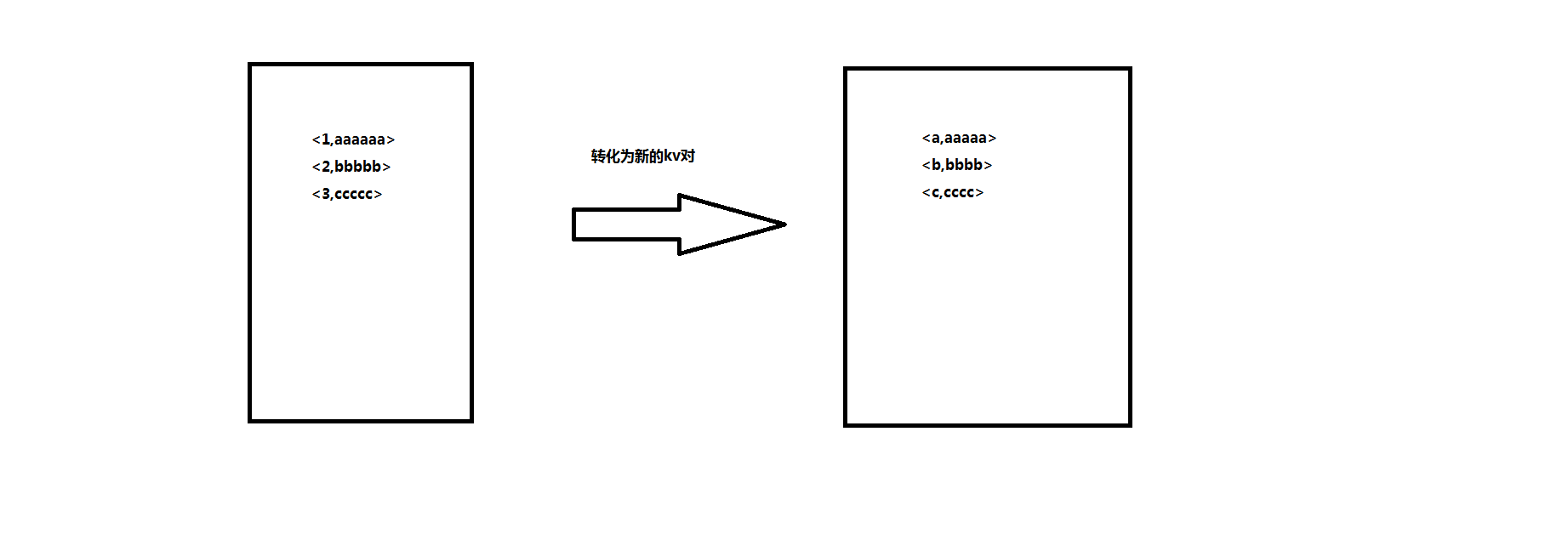
2、通过mapTask任务将<k1,v1>转化为我们需要的<key,value>对
主要是对v1进行拆分
3、分区和分组,将<key,value>对进行哈希编码,主要对key进行hashcode计算
1、然后按照自定义的算法给每个<key,value>对一个partition index,方便分区
4、排序
1、按照分区规则进行分区,主要对key的hashcode进行比较
2、分完了区之后,再对区内的key进行排序(这个是字典排序)
5、combiner。对数据进行map阶段的合并
对之前分好区,拍好序的数据进行合并
6、将分区后的小文件写入磁盘中
这个过程内存会给mr一个100M的环形缓冲区域,一旦达到80%的占有率就让它溢写到本地磁盘小文件中
7、使用归并排序,对本地磁盘溢写小文件进行归并排序
8、等待reduceTask启动线程来进行拉取数据
9、reduceTask启动线程,从各map task拉取属于自己分区的数据
10、从mapTask拉取回来的数据继续进行归并排序
11、进行groupingComparator分组操作
12、调用reduce的逻辑,写出数据




