


【实体统一】大数据环境下一种基于模式匹配的实体统一方法
大数据环境下一种基于模式匹配的实体统一方法
1、要解决什么问题?
1、传统实体统一主要针对小数据集,以前数据量小传统方法还可以,但是现在数据量大了,传统方法解决起来太慢了
2、数据量这么庞大,如何从大量数据中获取到值得我们关注的问题
2、实体统一相关解决思路
(1)、穷尽式的实体统一
解释:
说白了,就是一一进行比较,看两个实体是否为同一个实体
好处和坏处:
好处就是精度高
坏处就是这样比较太慢了
(2)、分块的实体统一
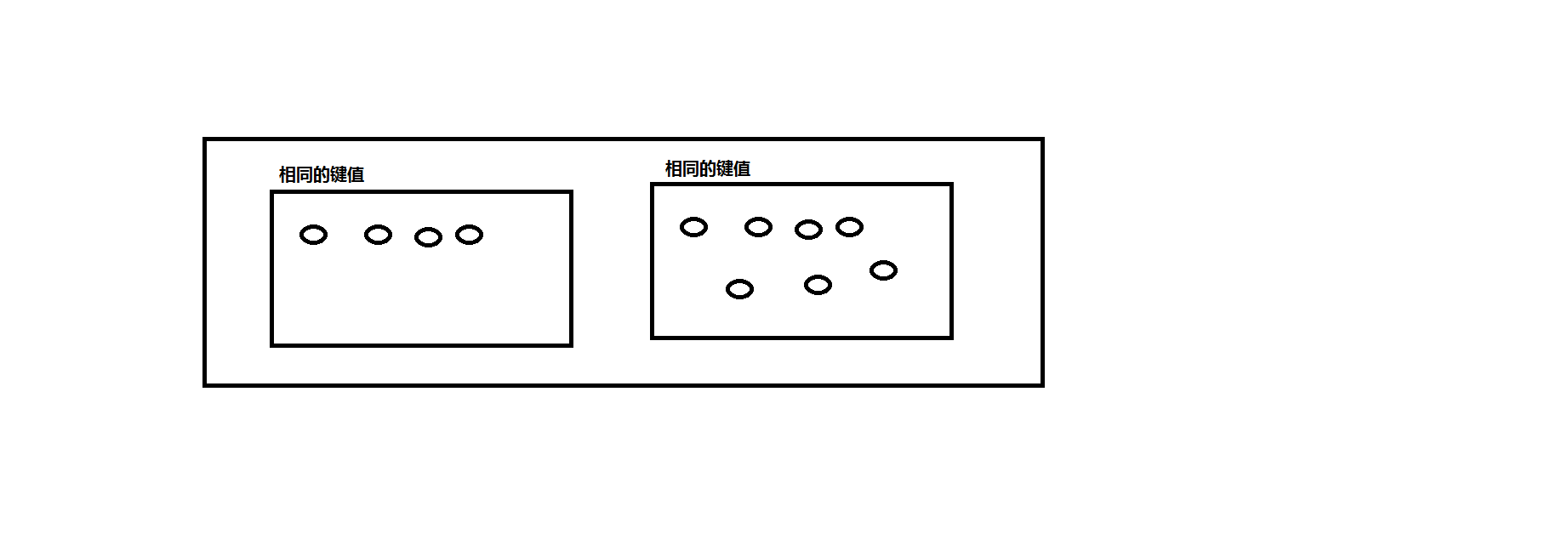
解释:
把那种相似的实体,放到一个块中,他们拥有同一个键值。
好处和坏处
好处就是速度快
坏处就是精度低
(3)、分布式架构的实体统一
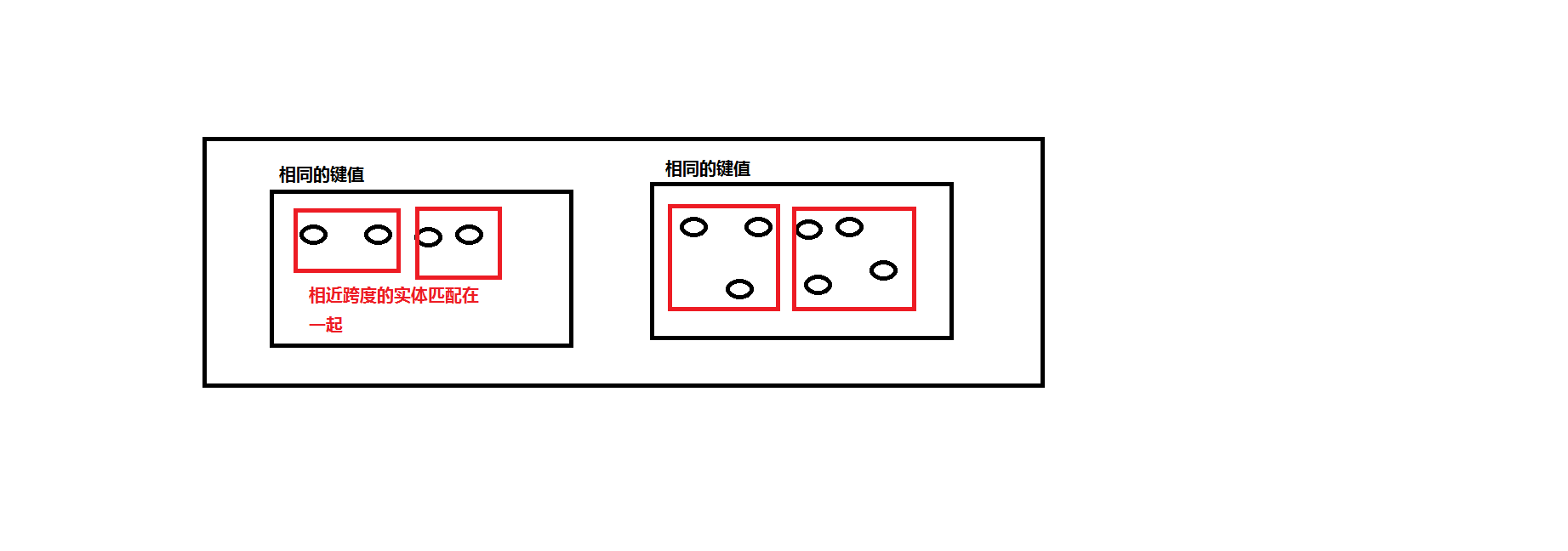
解释:
在之前的分块实体统一的基础之上,进行二次匹配,这次只是块内进行匹配,通过设定跨度距离来控制匹配的实体数量,并且块之间是分布式进行计算,极大提高计算机效率。
好处和坏处
好处就是速度快(但是和距离设置有关)
坏处就是精度较低
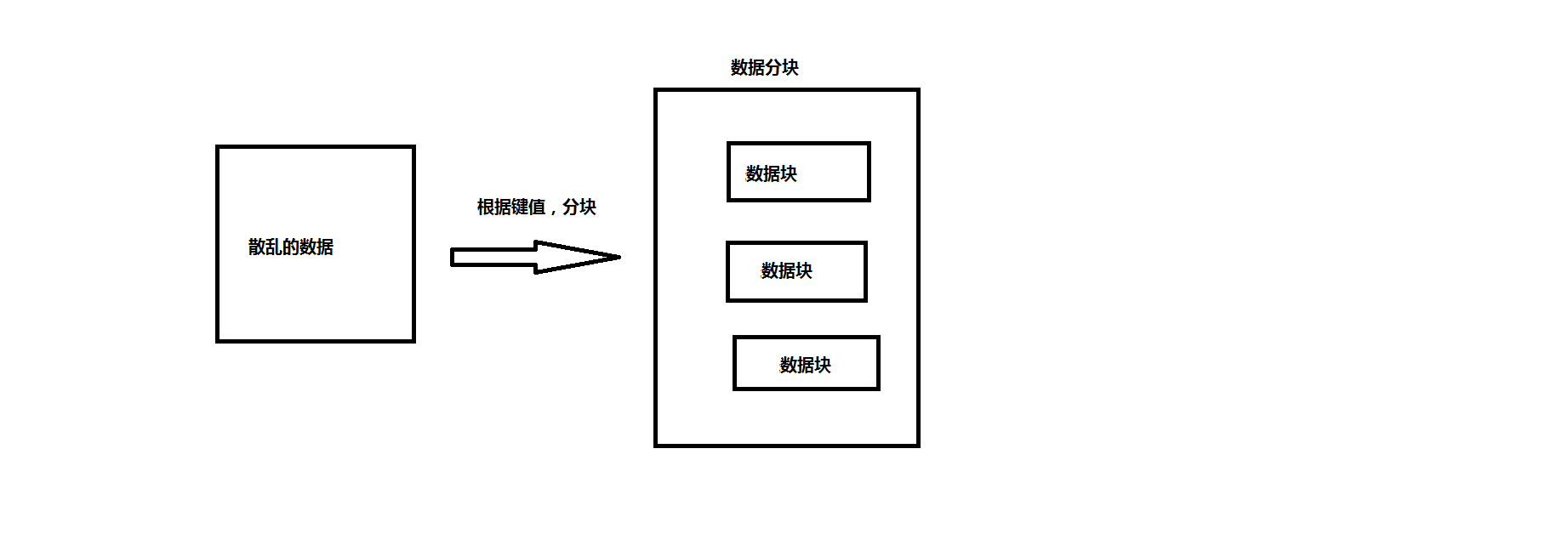
3、算法模型
分为3块数据分块模块、模式匹配和抽取模块、模式合并模块
(1)、数据分块模块
(2)、模式匹配和抽取模块
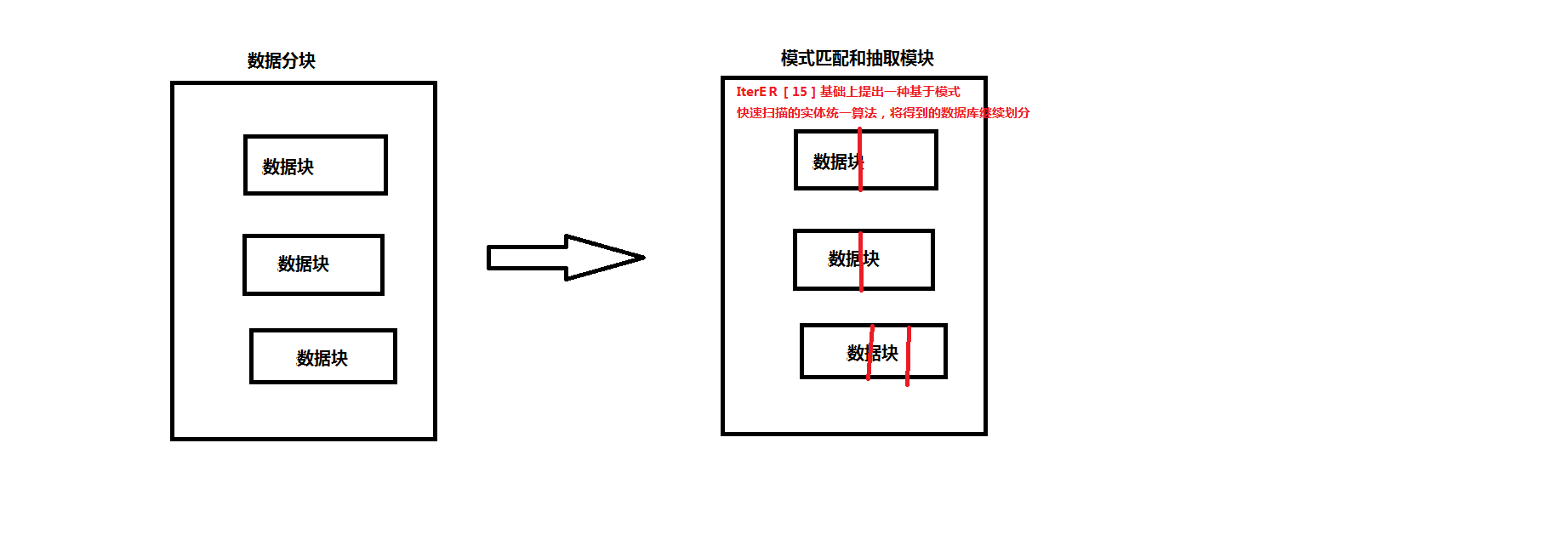
(3)、模式合并模块
经过前面的这个方式筛选,过滤和匹配之后,得到一个新的集合,这个新的集合是由多个相似块进行合并和拆分出来的结果集。
4、用到的算法
(1)、相似度计算
目的:
做模式之间的相似度计算,主要是为了后续模式之间的合并做了一个依据,相似度在我们规定的范围内就可以进行合并。
假如有实体:R{halloworde, helloworld}
1、先得到单个实体对应的模式公式,如下操作,进行比较
halloworde
helloworld
只有2位置和最后两个位置不一样,所以我们可以将他们归类为一种模式M:h{a,e}llowor{d,l}{e,d}
2、根据每个实体对应得到的模式 {R1,R2,R3.....} ——> {M1,M2,M3.....},然后我们对它的模式进行相似度计算
即我们比较 {M1,M2,M3.....}他们的相似度,为了将他们进一步合并。
(2)、模式快速扫描算法( PRSA)
1、根据第一步算出来的相似度,我们可以对他们进行比较。
2、把他们共同的地方标记出来,把不同的索引标记出来,记录下来(相同模式地方,不同模式处,不同模式处的索引)
(3)、模式抽取算法( PEA)
直接将上一步扫描的结果进行模式抽取,把他们的模式进行合并。
5、总结
实体统一算法的时间效率的要求越来越来,我们要尽量保证有效性的同时,重点关注如何更迅速地从大数据集中得到我们需要的数据实体。

