


查词系统的设计
假如你现在正在做一款词典软件,你手头拥有的资源只有从一个大数据库里面导出来的词条,你需要怎样组织这些词条,才能做到你所设计的查词软件即能够内置词库,又能够扩展词库,用户每次输入时都需要有下拉提示,并且在数据量很大的情况下查询速度不能太慢呢?
一个比较笨拙的方法当然就是,把所有词条放到一个数据库里面,每次用户查词的时候,使用”select * from wordtable where word like ?”查询,当数据量很小的时候是能够满足需求的,但是当数据量大到一定程度以后,查询的速度会越来越慢,这种方法的时间复杂度是为O(n)的。
当时我做第一版的时候,就是用如上的方法做的,作为新手,也不管那么多,第一想法就是让产品赶紧上线。上线后根据用户的反馈,以及后来产品需求的变更,上面的方法已经不适合了,然后只好自己研究,最后采用了下面将要讲到的文件索引方法。、
文件索引方法的思路就是,将所有的词条事先排好序,然后以指定的格式写到相应的索引文件以及相应的解释文件中,每个索引文件的单词量N自定义(接下来会讲N的设定对时间复杂度以及空间复杂度的影响),然后再提取每个索引文件中指定位置的一个词写入到配置文件中,这样,我们在查找的时候,我们只需要根据用户输入,然后与配置文件中的单词进行比较,就可以快速定位到用户输入的词应该在哪一个索引文件中。
好了,从上面的思路,我们可以知道完成这个任务需要两步。
第一步就是用从数据库导出来的词条生成相应的索引文件以及配置文件。配置文件除了记录每个索引文件中指定位置的单词外,还会记录一些词库信息(如版本,词库名等等)。为了方便,我们事先生成好了一个配置文件的头部,头部即词库信息,这样一来我们写入对应的单词时从文件末尾追加即可。例如我们要做一个英汉互译的词库,大致的配置信息如下表所示,
| [配置描述信息](106Bytes) | [汉语索引个数]cnIdxCount (4Bytes)int型 |
[英语索引个数]enIdxCount (4Bytes)int型 |
| cnIdxCount个单词信息(每个索引文件中取一个单词)格式如右:{[单词对应的字节数组长度(1Byte)][单词对应的字节数组]} | ||
| enIdxCount个单词信息(每个索引文件中取一个单词)格式如右:{[单词对应的字节数组长度(1Byte)][单词对应的字节数组]} |
先是关于词库的基本信息,然后是汉语索引个数,英语索引个数,紧跟在英文索引个数后面的数据将是用一个字节记录单词对应字节数组的长度,紧接着记录该单词对应的字节数组,如此循环记录cnIdxCount个单词索引,紧接着enIdxCount个单词索引。
第二步的工作就是根据用户输入的字符串,从索引文件中返回含有该字符串作为前缀的单词列表信息,大致的流程图如下所示:
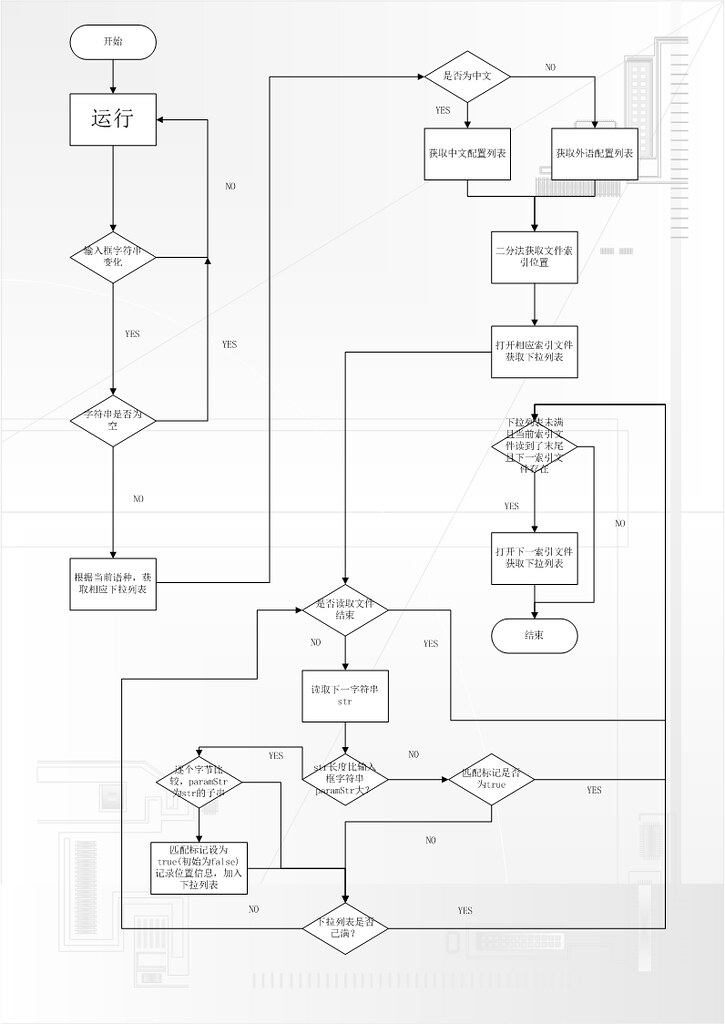
上面我们说到了用数据库查询的话,时间复杂度为O(n)。现在来分析一下用文件索引方法查询的时间复杂度:假设总词数n, 每个索引文件里面的单词个数为N,则索引文件个数为idxCount=(n/N), 二分法比较的次数最大为log(idxCount), 获取下拉列表需要比较的次数最大为N, 则整个的算法复杂度为O(log(idxCount)+N) = O(log(n/N)+N) = O(logn-logN+N),当N=n时,跟数据库查询的时间复杂度一样为O(n)。当N远小于n时,时间复杂度为O(logn)。
Android工程里面assets目录下面的文件大小不能超过1MB,故内置词库采用零散的索引文件。但是当做成外部扩展词库的时候,我们就不能使用零散文件了,因为用户下载之后再解压成零散文件,或者用户卸载扩展词库时删除零散文件,都是一件很费劲的事。所以做成外部词库时采用的是把如上内置词库生成的所有的索引文件以及解释文件合成到一个大的文件里,在配置文件里面增加一个字段记录每个索引文件的偏移量,在合成文件里面增加一个字段记录索引文件长度一边获取释义的时候可以直接跳过索引文件。假如设置一个扩展词库,文件的配置文件结构如下所示:
|
[词典名字对应的字节数组长度] (1Byte) |
[词典名字对应的字节数组] |
[语种类型](1Byte) |
[总词数]WordCount (4Bytes) |
[索引文件个数]idxCount (2Bytes) |
| idxCount个索引信息格式如右:{[(单词对应的字节数组长度+4) (1Byte)][对应的索引文件在合成文件里的偏移量 |
扩展词库文件的组织结构如下所示:
|
[配置文件] |
[第一个索引文件长度](4Bytes) |
[第一个索引文件] |
[第一个解释文件] |
|
[第二个索引文件长度](4Bytes) |
[第二个索引文件] |
[第二个索引文件] |
… |
整个的词库设计都是依据字节的偏移量来查询单词的,故对数据的准确性要求较高,所以从外部下载扩展词库的时候应该进行下文件完整性校验,否则出错了排查起来将是十分的困难。
posted on 2013-03-18 02:22 PeterHuang 阅读(433) 评论(0) 编辑 收藏 举报
