


关于分库分表大体思路,做法
起因:公司项目的数据量过大,已经超过20T,单张表数据+索引近5T,单表及单库性能都面临巨大的挑战。为了保证用户体验,提升效率,数据库方面需要优化。
项目:分布式项目,单系统已做集群,日均查询量2000W左右,交易量800W左右
特点:数据量大,并发量大
***(由于本身所在的项目属于核心系统部分与数据库交互,其他系统调用核心系统接口,所以不做阐述,仅记录本系统做法)
数据库:Oracle+Mysql
语言:Java
技术:zookeeper+dubbo+spring+mybatis+内部框架
分库分表:mycat+内部中间件
===========================================分割线================================================
在阐述之前,要先说明一下:
1,项目在线上稳定运行,要保证用户的服务,不能停止项目的运行
2,版本的切换要迅速,以最少的时间完成
3,代码的改造要兼容旧系统以及其他系统
4,不能影响业务
5,平滑过渡
等等......
===========================================分割线================================================
数据库部分
旧版本:原有的系统是采用单个oracle数据库,所有的业务都指向同一个数据库
新版本:将单个数据库,依据业务的组成,拆分成为几部分,如下图
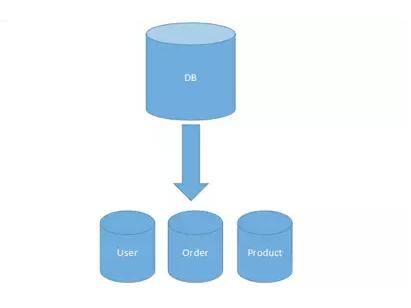
比如原先的一个系统,所有的业务都指向同一个数据库
如
旧系统业务=(订单+产品+用户+....)DB (一个DB)
新系统业务=订单DB+产品DB+用户DB+.... (多个DB)
实际做法:我们的实际做法是依据业务,将所有的表划分到不同的归属域中,并不是一个业务一个库,另外增加分库分表的路由表,分区属性,分库属性。
原因:根据业务,将不同的表划分到不同的归属域,要考虑到原系统的实际情况和新方案之间的一些过渡,兼容,可行性问题。
比如原代码的改造,重构的工作量的大小;是否会影响到上游系统;旧表和新表之间的数据问题等等。
另外不同域代表的不仅是业务归属,还代表数据库归属和表归属,为什么这么说呢?
因为原先一个库根据业务的归属域,拆分成多个库,用分区键路由,看你去哪一个归属域;在一个归属域中,一个库又拆成多个库,存储不同数据,用分库键路由,看你去哪一个数据库,其实库中的表结构都一样,只是存放的数据不同。
以上是数据库的拆分思路,要弄清楚一件事情,就是原本是所有的表都在一个库里面,现在是把不同的表依据归属域,放到不同的库里面,同一个归属域的数据库,比如说有100个库,那么100个库里的表是一样的,不同的库的表虽然相同,但是数据是不同的。
===========================================分割线================================================
相关问题部分:
有人会说,原先的代码,SQL指向的是同一个数据源,那么做了拆分之后,指向多个不同的数据源,那么会出问题
比如:
1,已经稳定运行的庞大系统,老代码,新代码,怎么知道哪些sql会在分库分表的时候出现问题?
2,多表查询的时候,不是同一个数据源怎么多表查询?
3,多数据源之间怎么切换,保持事务?
4,原有业务代码逻辑怎么改?
5,并发和防重怎么解决?
6,分库分表的实施,肯定会改变原表的结构导致数据问题,怎么办?
首先,要做前期的准备工作
===========================================分割线================================================
前期准备工作
1,已经稳定运行的庞大系统,老代码,新代码,怎么知道哪些sql会在分库分表的时候出现问题,怎么知道需要修改哪些SQL?
方案:监控系统
思路:简单的监控系统是由过滤器或者拦截器构成,而且本身mybatis可以配置打印sql
实际做法:其实我们的做法是新增监控系统(当然会复杂一些),采取为期一段时间(需要评估)的监控,每天搜集日志,整理,归纳,可以用python脚本。
把项目当中使用的sql整理出来,并且同时项目依据业务逻辑拆分成几大块,分配给不同的开发人员整理,归纳,与监控系统的结果做对比,把相关SQL整理出来。
2,多表查询的时候,不是同一个数据源怎么多表查询?
方案:SQL拆分+接口改造
思路:跨数据源的SQL拆分成多个SQL,业务代码重新整理
实际做法:
a,根据业务的拆分, 分配给不同的开发人员整理,归纳业务接口
b,依据不同的接口,根据接口中的业务和SQL,对比整理出的正在使用的SQL
c,依据分库逻辑,把跨数据源的多表关联的SQL拆分成单个SQL,如果不跨数据源,依旧可以多表查询
这里其实还涉及到接口的改造,因为在拆分SQL的时候,接口代码也会有相应的改动,这就要分配任务了......总之很难受
3,多数据源之间怎么切换,保持事务?
方案:单数据源单事务
思路:跨数据源的SQL已经拆分为前提,多个单数据源的SQL分别为各自的事务
实际做法:由于有内部框架,我们自己封装了jar包,手动开启,提交,回滚事务
举个例子:
旧系统:不管多少业务,不管什么业务,都是1个库,库里有A,B,C,D,E五张表,那么你查询一下就直接关联5张表就好了,需要update就直接update就好了,随便怎么搞
新系统:分别是5个库,5个业务,公共区域(品牌)+订单+用户+交易+积分一共5个业务,不同库里的表不同(理一下之间的关系)
a,公共区域库:品牌表A
b,订单库:订单表B
c,用户库:用户表C
d,交易库:交易表D
e,积分库:积分表E
比如一个业务:需要查询某个品牌的某个时间段的订单记录和这些订单的用户信息
<1>,先把需要查询的品牌先从表A中查询出来
<2>,依据<1>中的结果,当做参数传递到订单表中去查询,并且带上时间参数,获取订单信息
<3>,把<2>中的结果当做参数传递到用户表中去查询,获取用户信息
<4>,组装需要的结果
再比如:用户下单购买多件商品,根据用户订单的金额给用户加积分
<1>,用户下单,订单表增加数据
<2>,交易表记录流水
<3>,查询这个用户这比订单总金额
<4>,把<3>的结果当做参数传递到积分表算积分
不同的库,都分别开启和提交各自的事务,通过程序来控制各个小事务
关于产生脏数据的问题如下:
比如有A,B,C,D4个库,A中有1表,B中有2表,C中有3表,D中有4表,有一个业务需要做如下操作:
1,在A的1表中做select
2,把1的结果当做参数给B中2表,做insert
3,把1的结果当做参数给C中3表,做update
4,最后再把3的返回值,当做条件和参数,去D中4表做update
那么当3步骤出错的话,我们肯定是会catch的,但是2步骤的事务是提交了的,那么怎么办?
答案是:
1,3步骤出现错误,3步骤是可以回滚的,没有问题
2,2步骤的话,数据需要删除
那么又会问如果又出错了怎么办?
当然也确实有这个问题,我们的做法是有一个监控系统和补偿机制。
比如制定规则之后,每隔半个小时去扫描一些表,看哪些数据是有问题的,依据补偿的机制去补偿。
因为其实在实际操作过程中会增加很多表来完成这些操作。
比如最常见的补偿就是冲正了。
举个例子(自行百度)
即一笔交易在终端已经置为成功标志,但是发送到主机的帐务交易包没有得到响应,即终端交易超时,所以不确定该笔交易是否在主机端也成功完成,为了确保用户的利益,终端重新向主机发送请求,请求取消该笔交易的流水,如果主机端已经交易成功,则回滚交易,否则不处理,然后将处理结果返回给终端。
4,分库分表的实施,肯定会改变原表的结构导致数据问题,怎么办?
方案:数据清洗。
思路:依据分库分表的方案,确定新库的表结构,确定增加或者删除哪些字段,重新建立新表。在原表的基础上,新增字段,去除脏数据。
实际作法:
1,会先清除一批脏数据,这些脏数据是由于业务原因所导致的一些历史遗留问题,不会影响到现有的使用,比如说临时账户之类,临时数据之类。
2,保留可用数据,在现有表的基础上增加分库分表必要的字段
3,拆分原有表,比如说字段太多,可拆(看情况)
4,新增分库分表必须表,比如说路由表
5,去除冗余,无效字段
===========================================分割线================================================
4,原有业务代码逻辑怎么改
一般分库分表,如果会拆表或者废除一些表,那么就需要看代码,把废除的表的代码和拆表的代码重构,
原则上是需要多人协作仔细看代码来做这件事情的,分工合作
5,关于并发和防重问题
其实网上有很多解决方法
我们采取的做法是
1,乐观锁
2,悲观锁
3,幂等性校验
4,少量java代码的锁比如synchronized和lock锁(一般采用前三个,这个耗性能)
===========================================分割线================================================
在完成切换的过程之前,其实是有一个过渡期的,什么叫过渡期?
1,代码是一点一点写的,不是一下能完成的
2,多个团队协作,不是你的版本上线了,人家就要上线的
3,不同的团队负责的东西不同
现实:
1,在数据库的实际分库分表部分是由DBA负责的
2,在和数据库交互的过程中,是由中间件团队负责的
3,核心系统部分其实只是修改自己的业务代码和SQL语句来配合
举个例子比如说,我们要把一个库拆分成5个区域,每个区域都有10个库,那么一共50个库,怎么过度呢?
<1>,首先核心系统需要切换配置,首先要先配置好50个库的文件,但是路径指向的是同一个库,这是在过渡
<2>,到了和中间件团队约定的时间,由中间件团队的中间件去路由各个库
<3>,实际的切换不是同时切换到50个库,而是一个一个的切,每个大约在5分钟左右,在切库的过程中,只允许查询功能出现,停止一切写入库的操作
===========================================分割线================================================
关于路由问题:
虽然和数据库的交互是由中间件的团队来负责,但是我们也需要告诉中间件,到底哪一个连接是连哪一个数据库的,不然中间件也不能识别到底哪一个请求是连A库,哪一个请求去连B库。
方案:增加分区键,分库键
思路:请求参数中新增分区属性,分库属性参数,通过此参数告诉中间件
实际做法:我们的实际做法是依据业务,将所有的表划分到不同的归属域中,并不是一个业务一个库,另外增加分库分表的路由表,分区属性,分库属性。
原因:根据业务,将不同的表划分到不同的归属域,要考虑到原系统的实际情况和新方案之间的一些过渡,兼容,可行性问题。
比如原代码的改造,重构的工作量的大小;是否会影响到上游系统;旧表和新表之间的数据问题等等。
另外不同域代表的不仅是业务归属,还代表数据库归属和表归属,为什么这么说呢?
因为原先一个库根据业务的归属域,拆分成多个库,用分区键路由,看你去哪一个归属域;在一个归属域中,一个库又拆成多个库,存储不同数据,用分库键路由,看你去哪一个数据库,其实库中的表结构都一样,只是存放的数据不同。
===========================================分割线================================================
关于SQL拆分问题
1,在大部分的时候,查询的需求会多一些,所以需要查询的速度很快,那么在优化的时候肯定有加索引这一条,但是我们在使用mybatis的时候经常会写一些判断语句,如下:
<if test="fwbdh != null and fwbdh == 'BAK'">
fwbdh=#{fwbdh}
<if>
这种语句呢其实会很尴尬,为什么呢?因为DBA在加索引的时候,他不知道你的SQL中的where条件里到底这个字段要不要加索引,因为这个字段可能查询的时候不会用到。
所以,优化中的一条就是尽量不要写这种SQL,能判断的条件就在java代码里判断掉,或者把复杂SQL拆成简单SQL,用很多简单SQL来代替这些复杂SQL,说白了就是JAVA代码里多写if判断。但是呢,if判断多了也很耗性能,这也是很尴尬的,所以就权衡利弊了,不过一般来说,数据量超级大的时候,数据库查询的速度会比JAVA代码的运行速度慢很多。
2,一条复杂SQL和多条简单SQL执行一个业务
其实这个要分场景的,需要评估
3,千万不要写子查询,尤其是嵌套子查询
4,千万不要写select * from
5,常见优化方案百度
===========================================分割线================================================
关于中间件
我们分库分表采用的是mycat,数据库是mysql+oracle
其实这里采用的mycat已经不是开源的mycat了,中间件团队已经修改了mycat的源码
关于连接数据库的问题
Mysql:大家都知道mysql是开源的,所以,中间件团队选择以协议的方式来连接mysql
Oracle:因为oracle不是开源的,所以中间件团队选择以jdbc的方式连接oracle
另外连接数据库的连接池选用的是duird,因为duird连接池是开源的,所以中间件团队也是修改了durid的源码
在路由数据库之前,我们已经和中间件团队商讨过路由策略,决定以业务表中的某个字段的数据作为标志,另外会把这个数据塞到线程中去,最后由中间件团队来识别并处理。
===========================================分割线================================================
以上的方案实际上还在优化的过程中,但是已经是按照这个方向在走了,这个工程浩大,是以年来计算的,并不是一两个月能完成的,走到某一步,下一步可能都需要优化,改进。

