


Mastering the game of Go with deep neural networks and tree search浅析
Silver, David, et al. "Mastering the game of Go with deep neural networks and tree search." Nature 529.7587 (2016): 484-489.
推荐PPT:https://wenku.baidu.com/view/3cbb606f49649b6648d747fb.html?from=search
Alphago的论文,主要使用了RL的技术,不知道之前有没有用RL做围棋的。RL之外的工作应该是围棋或者下棋这个研究领域都有的工作,包括蒙特卡洛搜索树(MCTS)和有监督训练。
所以主要贡献是提出了两个网络,一个是策略网络,一个是价值网络。均是通过自我对战实现。
策略网络:
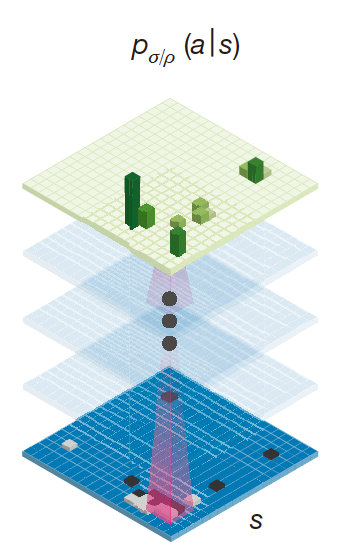
策略网络就是给定当前棋盘和历史信息,给出下一步每个位置的概率。以前的人似乎是用棋手下的棋做有监督训练,这里用RL代替,似乎效果比有监督训练要好。策略网络的参数初始化是用有监督训练网络的参数。
价值网络:
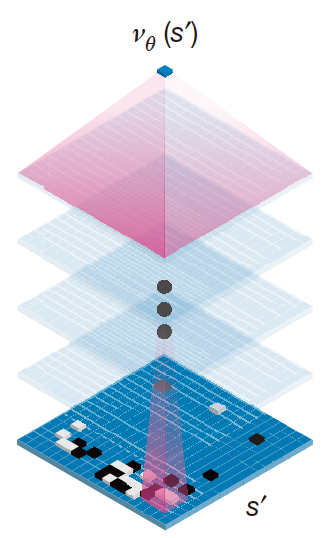
价值网络就是给定当前棋盘和历史信息,给出对己方的优势概率。本来是用来代替蒙特卡洛的随机模拟估计的,但是发现把价值网络和随机模拟估计结合起来效果比较好。个人觉得要是价值网络如果训练得足够好,说不定也就不需要模拟估计了。当然这里的模拟也不是完全随机,好像是用的一个有监督训练出来的浅层网络进行模拟下棋。
策略网络可以降低蒙特卡洛搜索树的宽度,价值网络减小其深度。
该论文第一次打败了人类职业选手(五段的Fan Hui)
另外,该方法有分布式版本和单机版,官方给单机版的判断是和Fan Hui一个水平,分布式版本的可以达到职业5段以上水平。分布式版本用了40个搜索线程, 1,202 个CPU以及176个GPU。单机版是40个搜索线程,48个CPU和8个GPU。按照这个配置,应该10年之内,单台笔记本电脑能跑个职业3段以上的围棋程序,这对围棋学习者是个很好的消息。
Alphgo让RL火了,让围棋火了,让柯洁火了,威力还是巨大的。围棋比较容易形式化,规则也比较简单,只是搜索空间有点大,但现实中还有很多问题规则复杂,信息不完全,状态空间大,决策空间大,需要联合决策等。Alphago还在不断发展,后续应该还有论文。
另外论文的用色和图表做得真是好。
实用指数:4颗星
理论指数:1颗星
创新指数:5颗星


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧