


《算法设计》一、引言:某些典型的问题
男女匹配算法:


![]()
![]()
一种最坏的情况就是,所有男人和女人对对方的排序都是样的,而且算法选择的时候是从男士排名最差到最好进行进行。这时候算法要运行n^2次。
问题1:对任意情况,是否都存在一种自由男士的选取顺序,使得不会有新的自由男士出现(已配对男士变成自由男士)?
问题2:是否存在一种情况,在这种情况里,所有人都不能和自己最喜欢的人在一起?

稳定匹配的方案不只有一个,可能存在多个。男士求婚和女士求婚的匹配结果可以不一样。有些匹配方案甚至不能只通过男士求婚或女士求婚求出来。
问题3:运用上述算法,匹配结果是否和男士选取顺序有关。
回答:匹配结果和男士选取顺序无关
证明:

定理1.7的证明:首先,S*为什么就一定是稳定匹配?当然我们不用证明S*是稳定匹配,因为我们只要证明算法的执行结果是S*就可以了。因为我们已经知道算法的结果是稳定匹配。如何证明算法结果一定是S*呢?那么需要用到反证法。那么我们假设算法结果里面至少有一个男人没有和最佳有效伴侣组合,这些男人叫做倒霉男,其中有个倒霉男在算法的执行过程当中会是所有被有效伴侣拒绝的倒霉男中第一次被有效伴侣拒绝的人,记为m,其最佳伴侣为w,在算法结果中w和m'在一起。另外存在某个稳定匹配S',包含(m,w)和(m',w'),我们可以很容易证明w更喜欢m'(w拒绝了m而选择了m'),m'更喜欢w(m是第一次被有效伴侣拒绝的人),所以在S'中(m',w')的组合是不稳定的,这和S'是一个稳定匹配矛盾。
有了这个定理,那么问题2将会和下面这个问题等价。
问题4:S*集合中,是否一定存在一个男士选上了自己最喜欢的女性。

五个经典问题:
1.区间调度问题
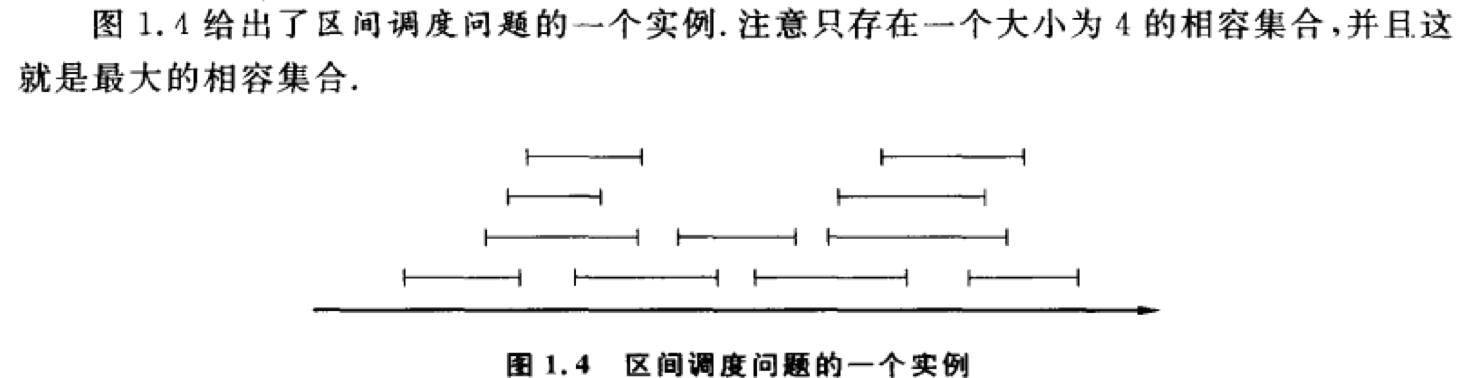
解法:贪心,按照结束时间进行排序,结束时间相同的,按照起始时间进行排序,每次选取第一个可以用的,选取可用的后排除无法使用的。

const int MAX_N=100000; //输入 int N,S[MAX_N],T[MAX_N]; //用于对工作排序的pair数组 pair<int,int> itv[MAX_N]; void solve() { //对pair进行的是字典序比较,为了让结束时间早的工作排在前面,把T存入first,//把S存入second for(int i=0;i<N;i++) { itv[i].first=T[i]; itv[i].second=S[i]; } sort(itv,itv+N); //t是最后所选工作的结束时间 int ans=0,t=0; for(int i=0;i<N;i++) { if(t<itv[i].second)//判断区间是否重叠 { ans++; t=itv[i].first; } } printf(“%d\n”,ans); }
时间复杂度:排序 O(nlogn) +扫描O(n) =O(nlogn)
如果我们不用贪心算法,考虑最简单的暴力枚举。对于每个区间,我们有选择与不选择两种方式,那么n个区间就一共有2^n种组合方式,对于每种组合方式,判断区间是否重叠需要O(n^2)的时间复杂度,所以暴力枚举的整体复杂度为O(2^n * n^2),可以看出复杂度极高。
我们比较是否重叠的算法复杂太高了,如果对结束时间进行排序,那么我们就用第一个和第二个进行判断,如果重叠则算法结束,如果不重叠则继续比较第二个和第三个是否重叠,以此类推。这样重叠检测就变成了O(n),原来算法复杂度降为了O(2^n * n)。
那我们是否一定需要遍历所有n^2种情况呢?定理:按(结束时间,起始时间)字典排序后的第一个区间肯定属于最优解。证明:假设一个最优解,我们通过分析可以知道排序后的第一个区间一定可以加入这个最优解或者替换掉最优解里面的第一个区间(如果最优解中结束时间最小的区间不是所有区间中结束时间最小的区间
,我们看看能否进行替换。
和
肯定是重叠的,否则就可以将
添加到最优解中获得更好的最优解。能否将
替换成
呢?
和
满足
,
和
满足
(两个区间不重叠),所以有
,从而
和
不重叠。所以我们可以用
来替换
。这就得出一个结论:在按照结束时间排序的情况下,第一个区间必定属于最优解。按照这个思路继续推导剩下的区间我们就会发现:每次选结束时间最早的区间就可以获得最优解。)。
有了上述定理,我们首先进行排序,然后选出第一个,然后排除所有其他冲突的区间。这样操作后不会改变剩下区间的顺序而且剩下的区间构成了一个和原始问题一样的子问题,这样问题就迎刃而解了。
很多最优化深搜问题都可以巧妙地转化成动态规划问题,可以转化的根本原因在于存在重复子问题,我们看图四就会发现最多区间调度问题也存在重复子问题,所以可以利用动态规划来解决。假设区间已经排序,可以尝试这样设计递归式:前i个区间的最多不重叠区间个数为dp[i]。dp[i]等于啥呢?我们需要根据第i个区间是否选择这两种情况来考虑。如果我们选择第i个区间,它可能和前面的区间重叠,我们需要找到不重叠的位置k,然后计算最多不重叠区间个数dp[k]+1(如果区间按照开始时间排序,则前i+1个区间没有明确的分界线,我们必须按照结束时间排序);如果我们不选择第i个区间,我们需要从前i-1个结果中选择一个最大的dp[j];最后选择dp[k]+1和dp[j]中较大的。伪代码如下:
void solve() { //1. 对所有的区间进行排序 sort_all_intervals(); //2. 按照动态规划求最优解 dp[0]=1; for (int i = 1; i < intervals.size(); i++) {
//1. 不选择第i个区间
maxBefore = -1;
int j = 0;
for (int p = 0 ; p < i ; p++){
if (maxBefore < dp[p]){
maxBefore = dp[p];
j = p;
}
}
//2. 选择第i个区间
k=find_nonoverlap_pos();
if(k>=0) dp[i]=dp[k]+1;
dp[i]=max{dp[i],dp[j]};
}
}
时间复杂度为O(n^2)
可以分析得出一个性质:dp数组的值应该是非递减的。因为对于第i个区间,我们可以完全不选择它,使得它和前面的dp[i-1]一样大。只是我们希望选择第i个区间后能够增加它的值。有了这个性质,我们的maxBefore就可以直接等于dp[i-1]了。
下面对find_nonoverlap_pos()函数进行优化。只要我们开个数组record[]记录每个dp指对应的起始位置,那么再把maxbefore传给find_nonoverlap_pos(),把record[maxBefore]返回的位置和区间i的位置比较看看是否重叠,如果不重叠则可以选取这个位置。
有了上述两步优化,那么每次查找的时间复杂度为O(1),整体复杂度(不算排序)为O(n)。这时候这个动态规划就变成了贪心算法一样了。
再把这个问题进行变化,变成求解最大区间问题,这时不是要求区间个数最多,而是要求区间的长度加起来最长。(上面的贪心法不能保证长度最长,甚至不能保证是个数最多里面的长度最长,那么一个新问题就是:如何设计一个的高效算法,使得保证区间个数最多情况下长度总和最长?)为什么不能用贪心?从前面的分析可以知道,排序后的第一个元素和最优解的第一个元素具有可替换性,而新问题下不具有这种性质。再从动规的角度分析,首先dp数组递增是一样的,但是find_nonoverlap_pos()函数却不能通过直接传入maxBefore进行得到。因为如果区间的长度是浮点数,那么不可能开个数组record进行记录。即便区间长度是离散值,如果长度不定且很长,那么需要开的数组空间就很大,算法空间和时间复杂度和区间长度成倍数增长,不具有推广性。所以只有把find_nonoverlap_pos()改成二分查找才能更通用地解决各种相似的问题。代码如下:
public int getMaxWorkingTime(List<Interval> intervals) { /* * 1 check the parameter validity */ /* * 2 sort the jobs(intervals) based on the end time */ Collections.sort(intervals, new EndTimeComparator()); /* * 3 calculate dp[i] using dp */ int[] dp = new int[intervals.size()]; dp[0] = intervals.get(0).getIntervalMinute(); for (int i = 1; i < intervals.size(); i++) { int max; //select the ith interval int nonOverlap = below_lower_bound(intervals, intervals.get(i).getBeginMinuteUnit()); if (nonOverlap >= 0) max = dp[nonOverlap] + intervals.get(i).getIntervalMinute(); else max = intervals.get(i).getIntervalMinute(); //do not select the ith interval dp[i] = Math.max(max, dp[i-1]); } return dp[intervals.size() - 1]; } public int below_lower_bound(List<Interval> intervals, int startTime) { int lb = -1, ub = intervals.size(); while (ub - lb > 1) { int mid = (ub + lb) >> 1; if (intervals.get(mid).getEndMinuteUnit() >= startTime) ub = mid; else lb = mid; } return lb; }
C++:
const int MAX_N=100000; //输入 int N,S[MAX_N],T[MAX_N]; //用于对工作排序的pair数组 pair<int,int> itv[MAX_N]; void solve() { //对pair进行的是字典序比较,为了让结束时间早的工作排在前面,把T存入first,//把S存入second for(int i=0;i<N;i++) { itv[i].first=T[i]; itv[i].second=S[i]; } sort(itv,itv+N); dp[0] = itv[0].first-itv[0].second; for (int i = 1; i < N; i++) { int max; //select the ith interval int nonOverlap = lower_bound(itv, itv[i].second)-1; if (nonOverlap >= 0) max = dp[nonOverlap] + (itv[i].first-itv[i].second); else max = itv[i].first-itv[i].second; //do not select the ith interval dp[i] = max>dp[i-1]?max:dp[i-1]; } printf(“%d\n”,dp[N-1]); }
可以看出,区间最多问题是区间最长问题的特例,即所有区间长度为1。区间最长问题的时间复杂度为O(nlogn) ,即排序和二分查找。
2.带权的区间调度
对区间最长问题进行扩展,我们可以得到带权区间最长问题,但是原来的动态规划的解法依然适用,一样的排序,一样的二分查找,只是区间长度不再是简单的结束时间减去开始时间,而是要在此基础上乘以权重。
现在回过来取解决那个在最多区间中寻找最长区间也很容易。主要再多开一个数组,记录每种dp值得总和长度的最大值就可以了。
3.二分匹配
二分图的另一个判别方式:不含有「含奇数条边的环」的图。
4.独立集
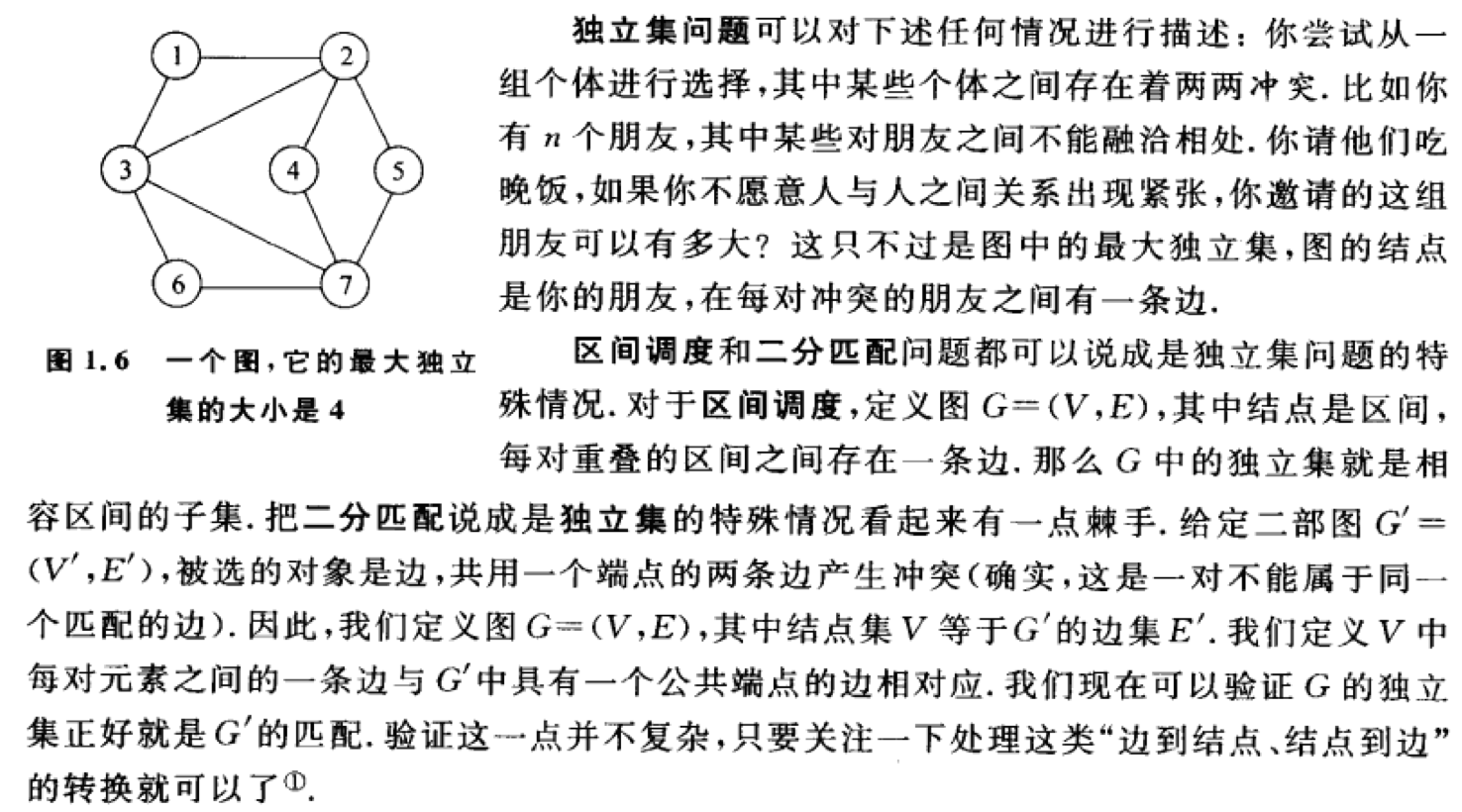
要求一个图的最大独立集就是求其补图的最大团。最大团就是在一个无向图中找出一个点数最多的完全图。
5.竞争的便利店选址问题







【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧