

Bayesian RL and PGMRL
简介:
PGMRL: PGMRL就是把RL问题建模成一个概率图模型,如下图所示:
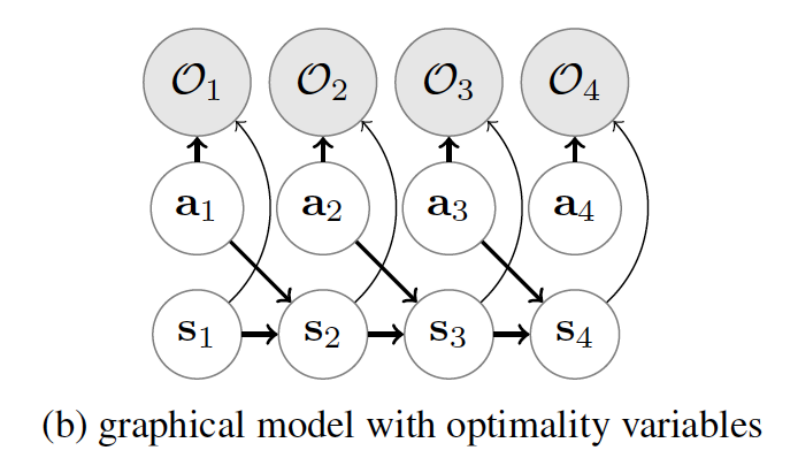
然后通过variational inference的方法进行学习:

PGMRL给RL问题的表示给了一个范例,对解决很多RL新问题提供了一种思路和工具。
Bayesian RL: 主要是对RL的reward function, transation function引入uncertainty, 引入prior和更新posterior来建模,从而更好地进行探索。
思考:为什么PGMRL推导过程中没有Beyesian RL的exploration-exploitation trade-off的问题。
简单的PGMRL建模的reward和transation是确定的,没有超参数的。在某种程度下,比如问题是凸的情况下,是不需要进行exploration的。而Beyesian RL的问题设定是假设这些东西是一种概率分布,而不是确定性的。而BeyesionRL对这种不确定性的处理恰巧克服了RL问题不是凸的情况local optimal的减弱。
thinking: what things does the Beyesian RL not consider?
Beyesian RL关注的点主要还是在uncertainty上,对policy学习过程的建模能力较弱,更适合用来处理RL中的uncertainty的问题,比如对sparse reward的问题处理能力较弱。
relationship between PGMRL and Bayesian RL:
我觉得Bayesian RL应该归为PGMRL中的一部分,PGMRL更具有整体性,对问题描述更全面,而Bayesian RL更像是处理某一特殊问题的方式。Bayesian RL需要在通过数据更新后验,然后也是model学习和policy学习相互交替的过程,但是由于没有很好的描述,我们不清楚这里面那些东西是missing variables,而且表面上看上去似乎reward和transation是missing的,但在PGMRL框架下,我们可以很清晰的看到其实optimal policy才是missing variable(PGMRL中把optimal policy转换成了variable)。这种迭代学习的过程,和EM算法的迭代类似,就是一边做inference一边做learning。这里inference就是对opitmal policy的学习过程,learning就是对MDP参数学习的过程。而在对optimal policy学习的时候,是这一种变分推断的过程,而这个变分推断过程又结合了MCMC采样的东西,MCMC采样有个冷启动的过程,所以前期不能只根据policy的最优结果来进行采样,需要加一些扰动。各种inference技术的结合加上简化形成了目前的基于deep learning的RL policy学习方法。
对于无先验的东西,我觉得还是用maximum entropy和variational infercence的方式去处理,简单的Bayesian RL中如果使用简单的共轭先验,对问题的处理局限性也较大,不具有普适性。所以,对于无先验的东西,直接采用maximum entropy更具有普适性。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】凌霞软件回馈社区,携手博客园推出1Panel与Halo联合会员
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· C#高性能开发之类型系统:从 C# 7.0 到 C# 14 的类型系统演进全景
· 从零实现富文本编辑器#3-基于Delta的线性数据结构模型
· 记一次 .NET某旅行社酒店管理系统 卡死分析
· 长文讲解 MCP 和案例实战
· Hangfire Redis 实现秒级定时任务,使用 CQRS 实现动态执行代码
· C#高性能开发之类型系统:从 C# 7.0 到 C# 14 的类型系统演进全景
· 管理100个小程序-很难吗
· 基于Blazor实现的运输信息管理系统
· 如何统计不同电话号码的个数?—位图法
· 聊聊四种实时通信技术:长轮询、短轮询、WebSocket 和 SSE
2018-04-04 Linux之查看切换Shell
2017-04-04 NIPS(Conference and Workshop on Neural Information Processing Systems)
2017-04-04 CVPR(IEEE Conference on Computer Vision and Pattern Recognition)