

神经网络手写数字识别
初始化Network对象,sizes包含各层神经元的数量,假设创建一个三层神经网络,第一层2个神经元,第二层3个神经元,第三层4个神经元。
初始化代码如下:

输出biases,weights情况如下:
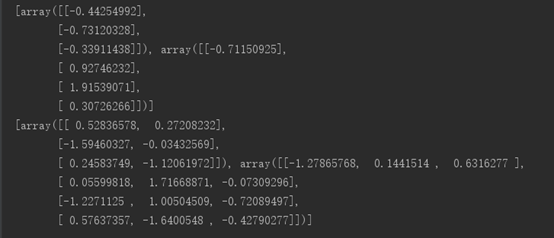
随机抽样
numpy.random.rand(d0,d1,...,dn)随机样本位于[0,1)中
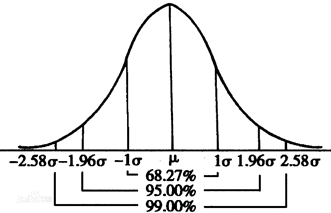
numpy.random.randn(d0,d1,...,dn)从标准正态分布中返回样本值,均值=0,标准差=1,记为N(0,1),样本基本上取值主要在-1.96~+1.96之间,在其他范围的概率较小。
Sigmoid函数:

Sigmoid函数的导数:

前向传播:

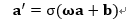
numpy.dot(a, b, out=None)
计算两个数组的乘积。对于二维数组来说,dot()计算的结果就相当于矩阵乘法。对于一维数组,它计算的是两个向量的点积。 对于N维数组,它是a的最后一维和b的倒数第二维和的积:dot(a, b)[i,j,k,m] = sum(a[i,j,:] * b[k,:,m])
*和dot()区别:
*来说只能是shape一样的才能相乘,与其他shape的矩阵相乘都会报错, 结果是对应元素相乘作为当前位置的结果,结果矩阵的形状保持不变
随机梯度下降:(训练数据,迭代次数,小样本数量,学习速率,是否有测试集)

对每个mini_batch都更新一次,重复完整个training_data:
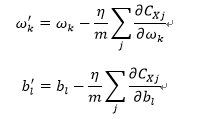
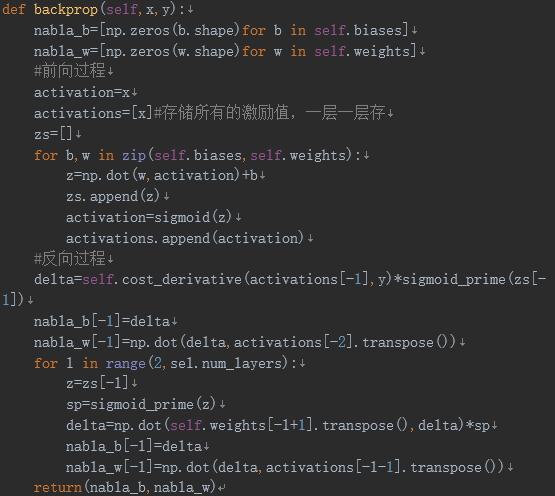
反向传播:

输出层cost函数对于a的导数

评价函数

完整代码如下:
import numpy as np
import random
import os,struct
from array import
array as pyarray
from numpy import
append,array,int8,uint8,zeros
class Network(object):
def __init__(self, sizes):#列表sizes包含各层神经元的数量
self.num_layers
= len(sizes)
self.sizes
= sizes
self.biases
= [np.random.randn(y, 1) for y in sizes[1:]]
self.weights
= [np.random.randn(y, x)
for x, y in zip(sizes[:-1], sizes[1:])]
# numpy.random随机抽样randn(d0,d1,...,dn)返回一个样本,具有标准正态分布
def feedforward(self, a):
for b, w in zip(self.biases, self.weights):
a = sigmoid(np.dot(w, a)+b)#np.dot()返回的是两个数组的点积
return a
def SGD(self, training_data, epochs, mini_batch_size, eta,
test_data=None):
if test_data:
n_test = len(test_data)
n = len(training_data)
for j in range(epochs):
random.shuffle(training_data)#将序列的所有元素随机排序
mini_batches = [
training_data[k:k+mini_batch_size]
for k in range(0, n, mini_batch_size)]
for mini_batch
in mini_batches:
self.update_mini_batch(mini_batch, eta)
if test_data:
print("Epoch {0}: {1} / {2}".format(j, self.evaluate(test_data), n_test))#str.format()格式化字符串
else:
print("Epoch {0} complete".format(j))
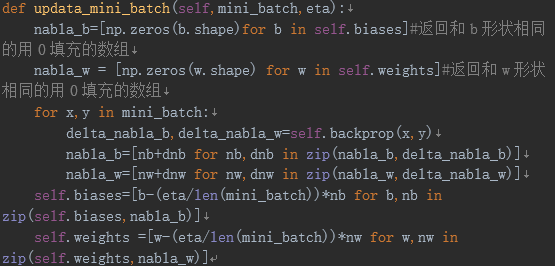
def update_mini_batch(self, mini_batch, eta):
nabla_b = [np.zeros(b.shape) for b in self.biases]#返回和b形状相同的用0填充的数组
nabla_w = [np.zeros(w.shape) for w in self.weights]#返回和w形状相同的用0填充的数组
for x, y in mini_batch:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
self.weights
= [w-(eta/len(mini_batch))*nw
for w, nw in zip(self.weights, nabla_w)]
self.biases
= [b-(eta/len