











正则表达式性能优化的探究
一.背景
前文的String字符串性能优化的探究中的第3点讲述了Split() 方法使用了正则表达式实现了其强大的分割功能,而正则表达式的性能是非常不稳定的,使用不恰当会引起回溯问题。那么今天详细探讨下正则表达式。
正则表达式是计算机科学的一个概念,很多语言都实现了它。正则表达式使用一些特定的元字符来检索、匹配以及替换符合规定的字符串。
构造正则表达式语法的元字符,由普通字符、标准字符、限定字符(量词)、定位符(边界字符)组成,详情如下图: 
二.正则表达式引擎
正则表达式是一个用正则符号写出的公式,程序对这个公式进行语法分析,建立一个语法分析树,再根据这个分析树结合正则表达式的引擎生成执行程序(这个执行程序我们把它称作状态机,也叫状态自动机),用于字符匹配。
而这里的正则表达式引擎就是一套核心算法,用于建立状态机。
目前实现正则表达式引擎的方式有两种:DFA自动机(Deterministic Final Automata 确定有限状态自动机)和 NFA(Non deterministic Finite Automaton 非确定有限状态自动机)。
对比来看,构造 DFA 自动机的代价远大于 NFA 自动机,但 DFA 自动机的执行效率高于 NFA 自动机。
假设一个字符串的长度是 n,如果用 DFA 自动机作为正则表达式引擎,则匹配的时间复杂度为 O(n);如果用 NFA 自动机作为正则表达式引擎,由于 NFA 自动机在匹配过程中存在大量的分支和回溯,假设 NFA 的状态数为 s,则该匹配算法的时间复杂度为 O(ns)。
NFA 自动机的优势是支持更多功能。例如:捕获 group、环视、占有优先量词等高级功能。这些功能都是基于子表达式独立进行匹配,因此在编程语言里,使用的正则表达式库都是基于 NFA 实现的。
那么 NFA 自动机到底是怎么进行匹配的呢?接下来以下面的例子来进行说明:
text = "aabcab"
regex = "bc"
NFA 自动机会读取正则表达式的每一个字符,拿去和目标字符串匹配,匹配成功就换正则表达式的下一个字符,反之就继续和目标字符串的下一个字符进行匹配。
分解一下过程:
1)读取正则表达式的第一个匹配符和字符串的第一个字符进行比较,b 对 a,不匹配;继续换字符串的下一个字符,也就是 a,不匹配;继续换下一个,是 b,匹配;
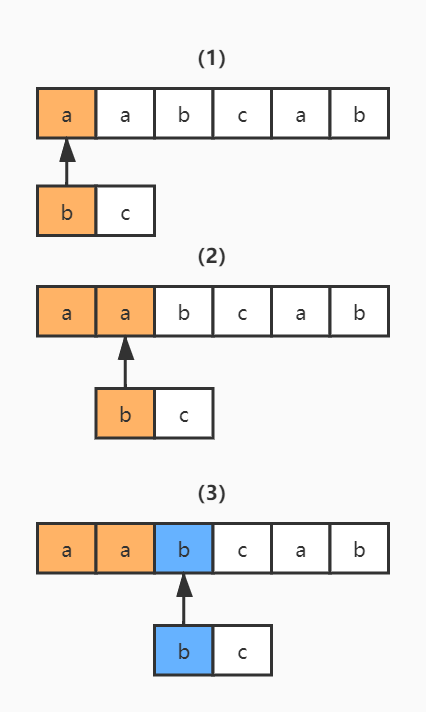
2)同理,读取正则表达式的第二个匹配符和字符串的第四个字符进行比较,c 对 c,匹配;继续读取正则表达式的下一个字符,然而后面已经没有可匹配的字符了,结束。
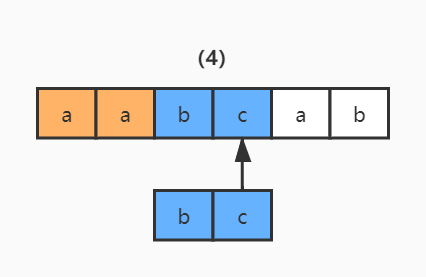
这就是 NFA 自动机的匹配过程,虽然在实际应用中,碰到的正则表达式都要比这复杂,但匹配方法是一样的。
三.NFA自动机的回溯
用 NFA 自动机实现的比较复杂的正则表达式,在匹配过程中经常会引起回溯问题。大量的回溯会长时间地占用 CPU,从而带来系统性能开销。如下面例子:
text = "abbc"
regex = "ab{1,3}c"
上面例子,匹配目的比较简单。匹配以 a 开头,以 c 结尾,中间有 1-3 个 b 字符的字符串。NFA 自动机对其解析的过程是这样的:
1)读取正则表达式第一个匹配符 a 和字符串第一个字符 a 进行比较,a 对 a,匹配;
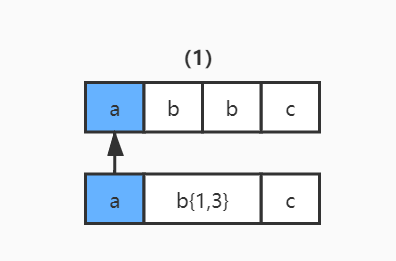
2)读取正则表达式第一个匹配符 b{1,3} 和字符串的第二个字符 b 进行比较,匹配。但因为 b{1,3} 表示 1-3 个 b 字符串,NFA 自动机又具有贪婪特性,所以此时不会继续读取正则表达式的下一个匹配符,而是依旧使用 b{1,3} 和字符串的第三个字符 b 进行比较,结果还是匹配。

3)继续使用 b{1,3} 和字符串的第四个字符 c 进行比较,发现不匹配了,此时就会发生回溯,已经读取的字符串第四个字符 c 将被吐出去,指针回到第三个字符 b 的位置。
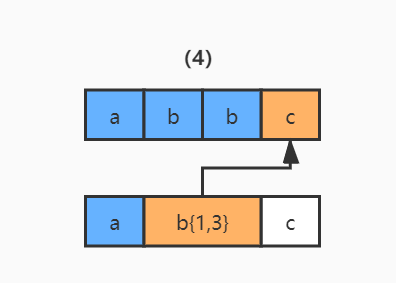
4)那么发生回溯以后,匹配过程怎么继续呢?程序会读取正则表达式的下一个匹配符 c,和字符串中的第四个字符 c 进行比较,结果匹配,结束。

四.如何避免回溯问题?
既然回溯会给系统带来性能开销,那我们如何应对呢?如果你有仔细看上面那个案例的话,你会发现 NFA 自动机的贪婪特性就是导火索,这和正则表达式的匹配模式息息相关。
1.贪婪模式(Greedy)
顾名思义,就是在数量匹配中,如果单独使用 +、?、*或(min,max)等量词,正则表达式会匹配尽可能多的内容。
例如,上面那个例子:
text = "abbc"
regex = "ab{1,3}c"
就是在贪婪模式下,NFA自动机读取了最大的匹配范围,即匹配 3 个 b 字符。匹配发生了一次失败,就引起了一次回溯。如果匹配结果是“abbbc”,就会匹配成功。
text = "abbbc"
regex = "ab{1,3}c"
2.懒惰模式(Reluctant)
在该模式下,正则表达式会尽可能少地重复匹配字符,如果匹配成功,它会继续匹配剩余的字符串。
例如,上面的例子的字符后面加一个“?”,就可以开启懒惰模式。
text = "abc"
regex = "ab{1,3}?c"
匹配结果是“abc”,该模式下 NFA 自动机首先选择最小的匹配范围,即匹配 1 个 b 字符,因此就避免了回溯问题。
3.独占模式(Possessive)
同贪婪模式一样,独占模式一样会最大限度地匹配更多内容;不同的是,在独占模式下,匹配失败就会结束匹配,不会发生回溯问题。
还是上面的例子,在字符后面加一个“+”,就可以开启独占模式。
text = "abbc"
regex = "ab{1,3}+c"
结果是不匹配,结束匹配,不会发生回溯问题。
所以综上所述,避免回溯的方法就是:使用懒惰模式或独占模式。
前面讲述了“Split() 方法使用了正则表达式实现了其强大的分割功能,而正则表达式的性能是非常不稳定的,使用不恰当会引起回溯问题。”,比如使用了 split 方法提取域名,并检查请求参数是否符合规定。split 在匹配分组时遇到特殊字符产生了大量回溯,解决办法就是在正则表达式后加一个需要匹配的字符和“+”解决了回溯问题:
\\?(([A-Za-z0-9-~_=%]++\\&{0,1})+)
五.正则表达式的优化
1.少用贪婪模式:多用贪婪模式会引起回溯问题,可以使用独占模式来避免回溯。
2.减少分支选择:分支选择类型 “(X|Y|Z)” 的正则表达式会降低性能,在开发的时候要尽量减少使用。如果一定要用,可以通过以下几种方式来优化:
1)考虑选择的顺序,将比较常用的选择项放在前面,使他们可以较快地被匹配;
2)可以尝试提取共用模式,例如,将 “(abcd|abef)” 替换为 “ab(cd|ef)” ,后者匹配速度较快,因为 NFA 自动机会尝试匹配 ab,如果没有找到,就不会再尝试任何选项;
3)如果是简单的分支选择类型,可以用三次 index 代替 “(X|Y|Z)” ,如果测试话,你就会发现三次 index 的效率要比 “(X|Y|Z)” 高一些。
3.减少捕获嵌套 :
捕获组是指把正则表达式中,子表达式匹配的内容保存到以数字编号或显式命名的数组中,方便后面引用。一般一个()就是一个捕获组,捕获组可以进行嵌套。
非捕获组则是指参与匹配却不进行分组编号的捕获组,其表达式一般由(?:exp)组成。
在正则表达式中,每个捕获组都有一个编号,编号 0 代表整个匹配到的内容。可以看看下面的例子:
public static void main(String[] args) { String text = "<input high=\"20\" weight=\"70\">test</input>"; String reg = "(<input.*?>)(.*?)(</input>)"; Pattern p = Pattern.compile(reg); Matcher m = p.matcher(text); while (m.find()){ System.out.println(m.group(0));//整个匹配到的内容 System.out.println(m.group(1));//<input.*?> System.out.println(m.group(2));//(.*?) System.out.println(m.group(3));//(</input>) } } =====运行结果===== <input high="20" weight="70">test</input> <input high="20" weight="70"> test </input>
如果你并不需要获取某一个分组内的文本,那么就使用非捕获组,例如,使用 “(?:x)” 代替 “(X)” ,例如下面的例子:
public static void main(String[] args) { String text = "<input high=\"20\" weight=\"70\">test</input>"; String reg = "(?:<input.*?>)(.*?)(?:</input>)"; Pattern p = Pattern.compile(reg); Matcher m = p.matcher(text); while (m.find()) { System.out.println(m.group(0));//整个匹配到的内容 System.out.println(m.group(1));//(.*?) } } =====运行结果===== <input high="20" weight="70">test</input> test
如果,您希望更容易地发现我的新博客,不妨点击一下左下角的【关注我】。
如果,您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是【码猿手】。

