
聊聊RPC原理二
之前写了一篇关于RPC的文章,浏览量十分感人:),但是感觉文章写得有些粗,觉得很多细节没有讲出来,这次把里边的细节再次补充和说明。
这次主要说的内容分为:
1. RPC的主要结构图。
2.分析结构图的中的细节和步骤。
关于RPC,大家都不陌生,其简写和介绍什么的我就不过多介绍了,可以从我上篇文章中看到,下面直接上我画的图,简单粗暴:
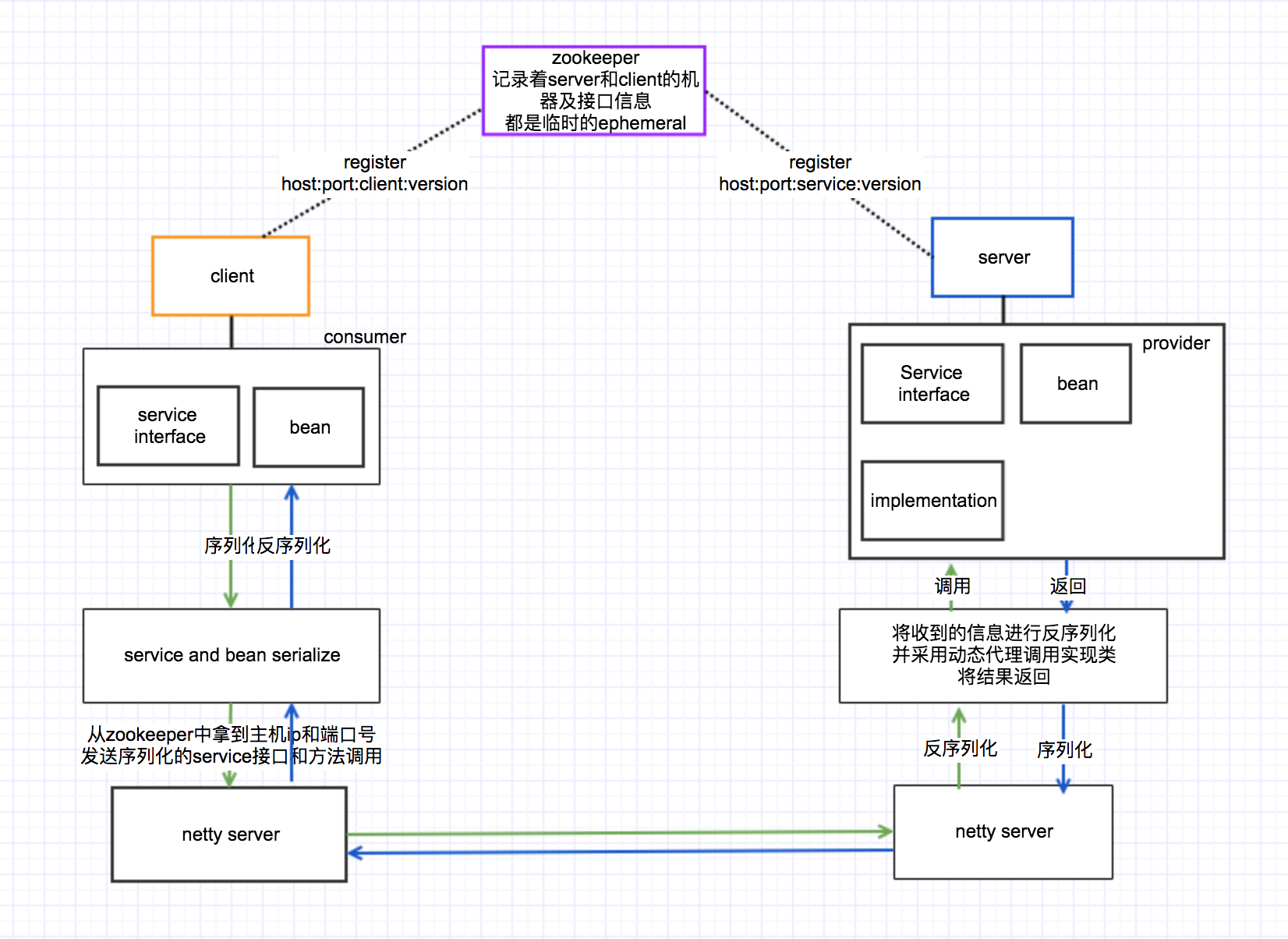
RPC的主要目的是将一个庞大的系统分离成不同的子系统,按照不同的功能,比如读库功能,记录日志等可以单独出来的功能单独出来,这样的好处是,不会像以前那样庞大的系统部署的时候每次都要整个系统进行重启,可以修改单独的模块,并且自己独立部署,这样大大提升效率。但是如果拆分的过细的话,可能需要维护很多的小项目,代码工程由一个大工程,拆分成很多小工程,而且启动功能并且进行测试的话一般至少启动两个服务,一个server和一个client,同时相应的zookeeper也要启动。
下面来说一下上图中每个模块的功能。
先来说一下zookeeper, 可能有些同学已经很熟悉zookeeper使用了,当然我也在博客中写过zookeepr实现的锁文章,它非常强大,但是这里不过多解释它强大之处,这次说它的作用。在RPC中zookeeper承担着服务的注册,心跳检测,记录client的相关信息,最关键的是要记录server的IP和端口号以及它提供service信息,版本号等信息。每个client在调用之前都要从zookeeper那里获取存活server的相关信息及提供服务的版本。这样client拿到这些信息后可以直接和server进行通信了。
里边有一个细节就是client和server在zookeeper中注册的znode是临时的ephemral的,这样的目的是在心跳检测的时候发现client或者server已经down了,需要从zk中剔除,这样client连接server失败的情况下重新从zookeeper中获取有效的server及service信息。
接下来就是server,在一些大型系统中,其实server是由很多台机器构成的,这里我为了简化就画了一台机器,当server和其中部署的service启动之后需要到zookeeper中进行注册,这样client就可以发现新部署的service了,通过zookeeper实现了动态的service上线和下线,是不是很厉害。在server中,由service声明和implementation实现,同时还有在使用过程中对应的bean对象。当然在server中还部署着netty服务,这个一会儿咱们就说。
继续看client,client在这里边充当着的是consumer,就是消费service所produce的服务。client应该也是多台的。client其实就相对比较简单,因为是调用方,所以只需要声明对应的service接口和相应的bean对象就行了。
然后就是netty服务了,这次咱们不说netty的详细内容,大家知道它是用来进行通信的,拥有高吞吐量,高并发,多协议实现,并且支持NIO,AIO的工具。有兴趣的同学可以读一些关于netty的文章。netty在这里扮演的角色就是通信,将调用的service以及相关的bean对象和参数进行序列化,找到从zookeeper获取的service所在的主机、IP、端口号、服务及版本等信息后进行TCP连接,发送给server后,在server中也有一个netty在对应的端口进行接口,接收后进行反序列化,然后通过动态代理实现接口调用,关于动态代理的实现可以参考我之前写过的文章。调用之后获取到执行结果后再以相反的顺序返回去。这就是netty实现的功能了。
这块基本就是RPC的主要核心实现细节,当然里边可能还会有一些细节我没有提到,因为RPC的功能也在不断完善中,所以还有一些新增的一些功能没有提及,比如server机器的比重等,这些在用到的工程中一看应该就会明白。
好了,希望你们能从这篇文章中获得收获。
欢迎转载,但转载请署名黄青石,谢谢。

