
爬取今日头条财经版块新闻
使用jupyter编辑, etree爬取
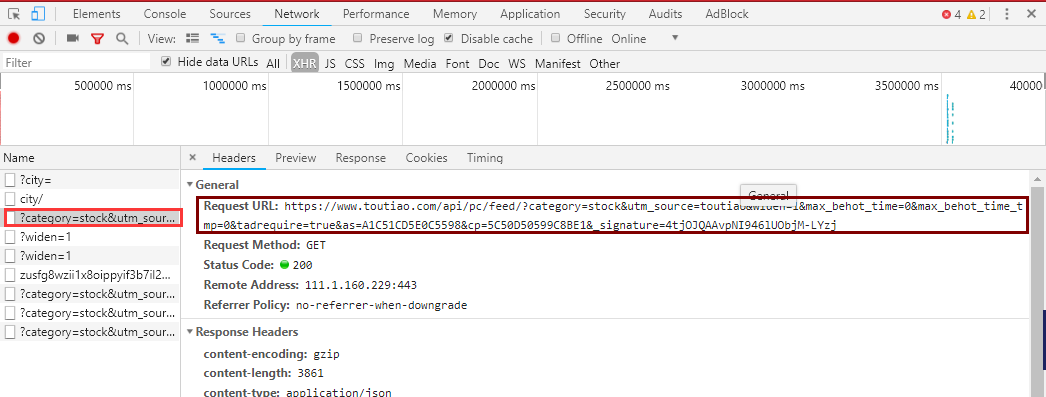
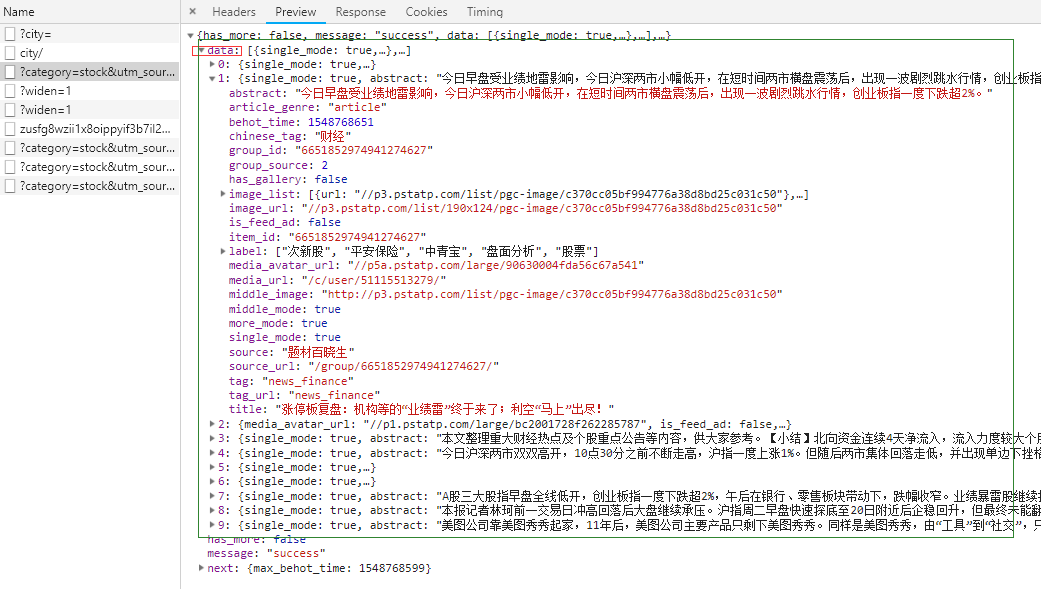
进入头条财经新闻网页,无法获取原网页内容,在查看各个请求中发现一个url里包含新闻信息.信息都在data里
import requests from lxml import etree import json
url = "https://www.toutiao.com/api/pc/feed/?category=stock&utm_source=toutiao&widen=1&max_behot_time=0&max_behot_time_tmp=0&tadrequire=true&as=A1C51CD5E0C5598&cp=5C50D50599C8BE1&_signature=4tjOJQAAvpNI946lUObjM-LYzj" headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3610.2 Safari/537.36", "Connection": "close" } response = requests.get(url=url,headers=headers) response.encoding = "utf-8" page_text = json.loads(response.text) # 获取页面内容 # print(page_text) data = page_text['data'] # 获取data # print(data) news_dict = {} # 存放每条新闻信息的字典 news_list = [] # 存放所有新闻信息的列表 for news in data: news_dict['描述'] = news['abstract'] news_dict['标题'] = news['title'] news_dict['来源'] = news['source'] news_dict['关键字'] = news['label'] news_list.append(news_dict) news_dict={} print(news_list)
无限的我,现在才开始绽放,从东边的第一缕阳光到西边的尽头

