

论文爬取 pdf文件爬取(二)
pdf文件爬取
首先分析此论文网站的网站结构
我选取的是2018年的ECCV论文
首先进入后
是所有的一个论文总览

然后为了实现一个自动爬取
需要首先截取到他的一个链接
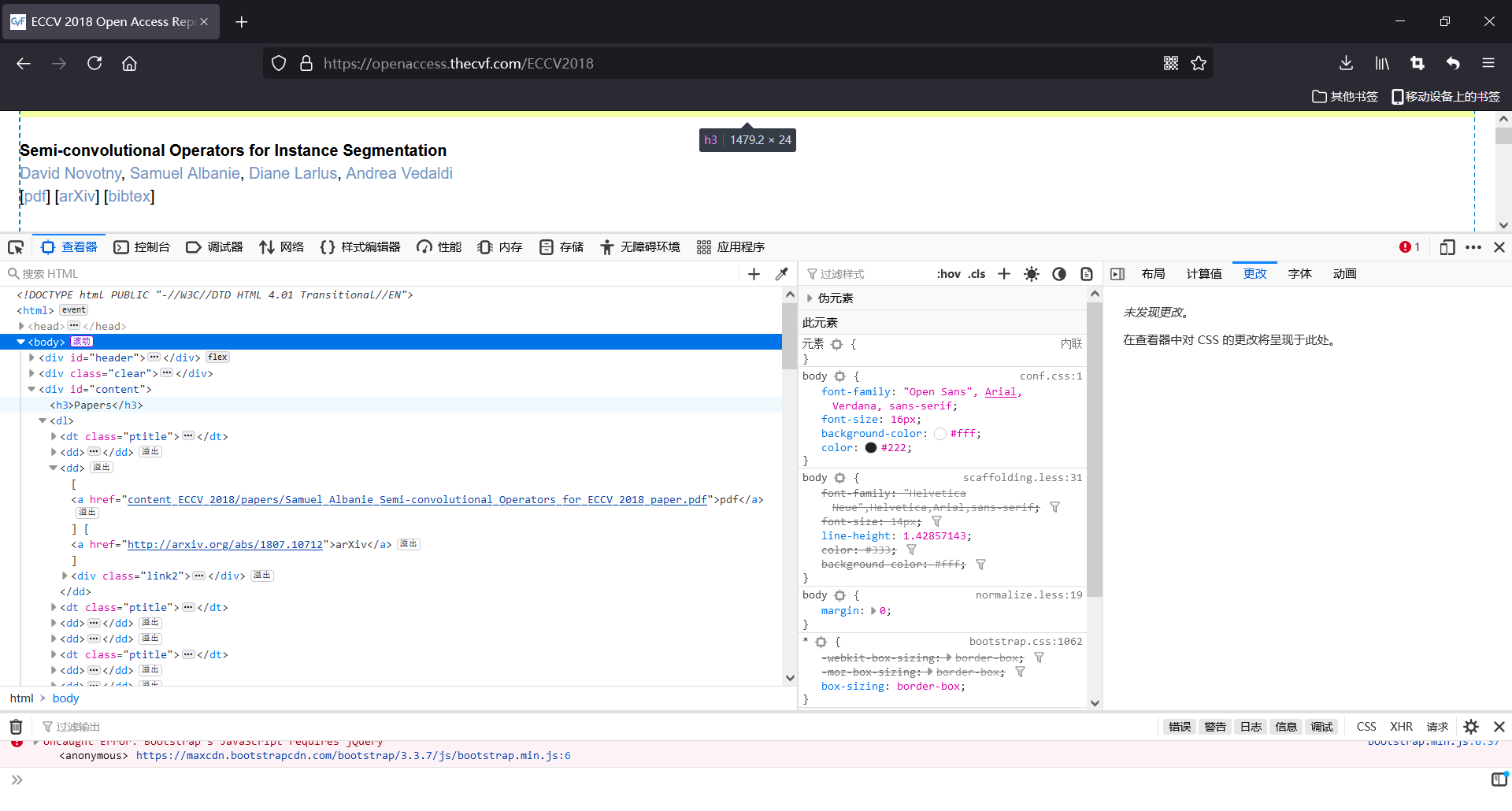
查看后他的一个论文的所有链接都是包含在一个dl中的
然后dl中有好多的dd标签和dt标签
其中dt标签中是有html表示的但是是没有论文内容的
所以需要下载pdf文件
所以寻找pdf文件链接
其中pdf链接是在第二个dd下的
其中第一个dd标签和第二个dd标签是有区别的
其中第一个有一个form标签然后第二个是没有的直接一个a标签
所以直接用Xpath爬取
语句为//dl/dd/a[1]/@href
选取第一个a标签

然后直接爬取
这是链接的爬取
然后标题是在dt标签
也是直接爬取他的text内容即可
html = etree.HTML(html)
indexs = html.xpath('//dl/dd/a[1]/@href')
base_url = 'https://openaccess.thecvf.com/'
titles = html.xpath('//dl/dt/a/text()')


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
· AI 智能体引爆开源社区「GitHub 热点速览」