结对作业二
结对作业二
结对作业二
1.作业信息
| 这个作业属于哪个课程 | 2021春软件工程实践|W班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 结对作业二 |
| 结对学号 | 221801307 & 221801327 |
| 这个作业的目标 | 1.fork仓库,和伙伴商讨如何通过github协作/代码规范等 2.使用Web知识实现原型设计的部分功能 3.将项目部署到云服务器上,并发布release版本 4.根据作业要求撰写第一个博客 5.在deadline之前提交博客 |
| 其他参考文献 | CSDN、简书博客、github |
2.github仓库地址和代码规范
3.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 15 |
| ·Estimate | 估计这个任务需要多少时间 | 15 | 15 |
| Development | 开发 | 1480 | 1922 |
| ·Analysis | ·需求分析(包括学习新技术) | 90 | 120 |
| ·Design Spec | ·生成设计文档 | 30 | 40 |
| ·Design Review | ·设计复审 | 10 | 20 |
| ·Coding Standard | ·代码规范(为目前的开发指定合适的规范) | 30 | 40 |
| ·Design | ·具体设计 | 30 | 40 |
| ·Coding | ·具体编码 | 1200 | 1564 |
| ·Code Review | ·代码复审 | 30 | 24 |
| ·Test | ·测试(自我测试,修改代码,提交修改) | 60 | 74 |
| Reporting | 报告 | 115 | 100 |
| ·Test Repor | ·测试报告 | 40 | 30 |
| ·Size Measurement | ·计算工作量 | 45 | 40 |
| ·Postmortem & Process Improvement Plan | ·事后总结,并提出过程改进计划 | 30 | 30 |
| 合计 | 1610 | 2037 |
4.云服务器链接
5.作品展示
登录界面->请输入正确的用户名和密码哦
- 入口采用轮播图播放,不要被迷住了!!!(user:cs1 pwd:123456)

论文页面
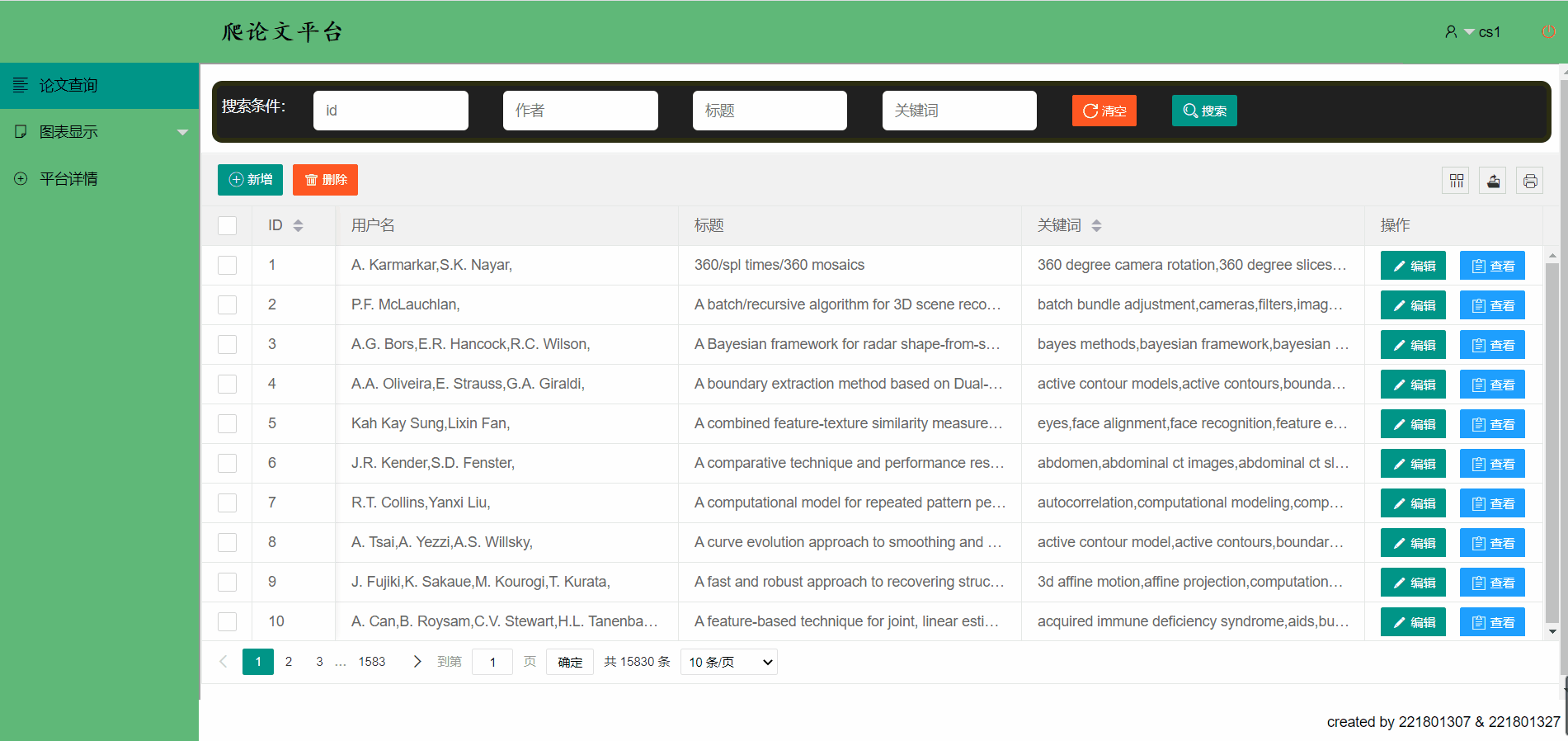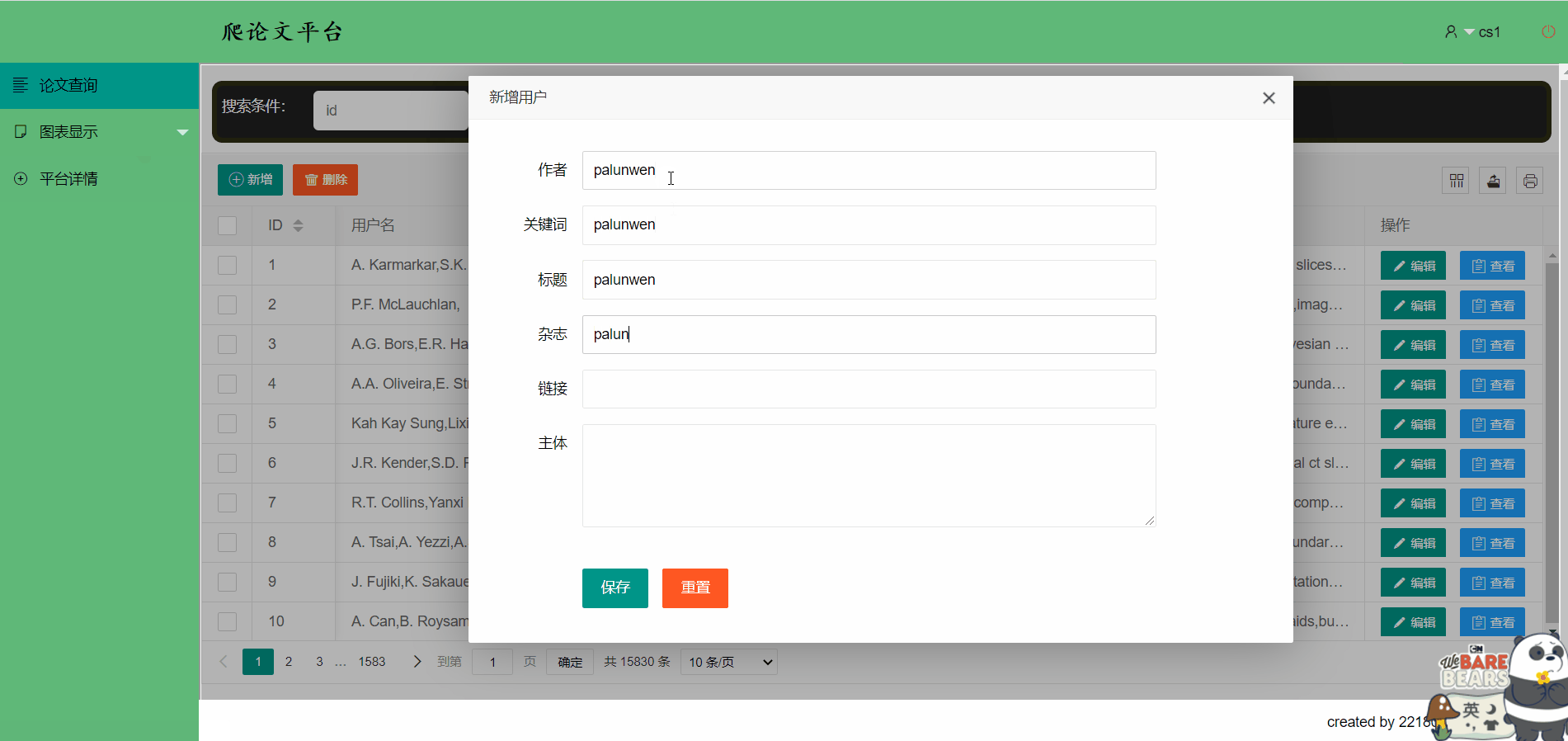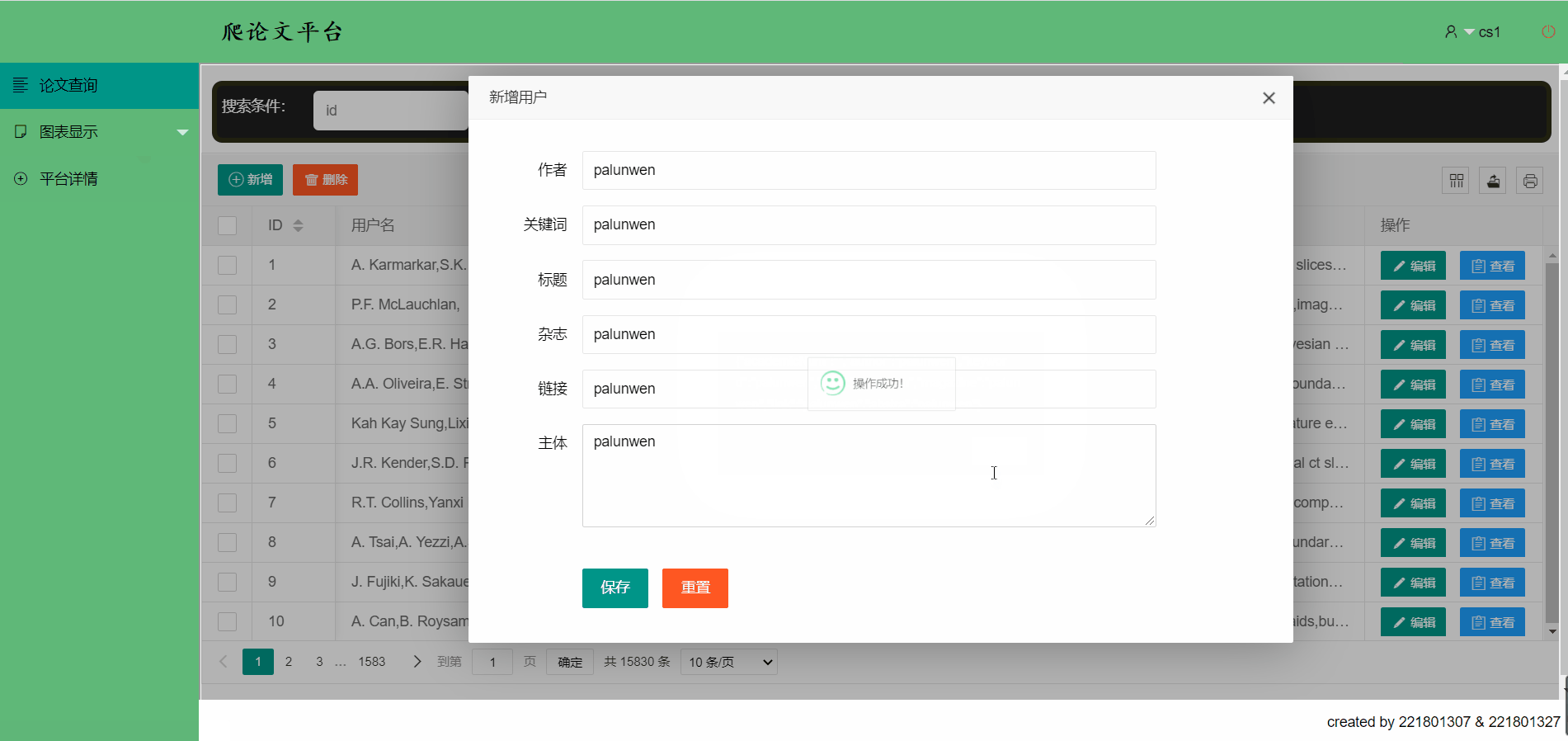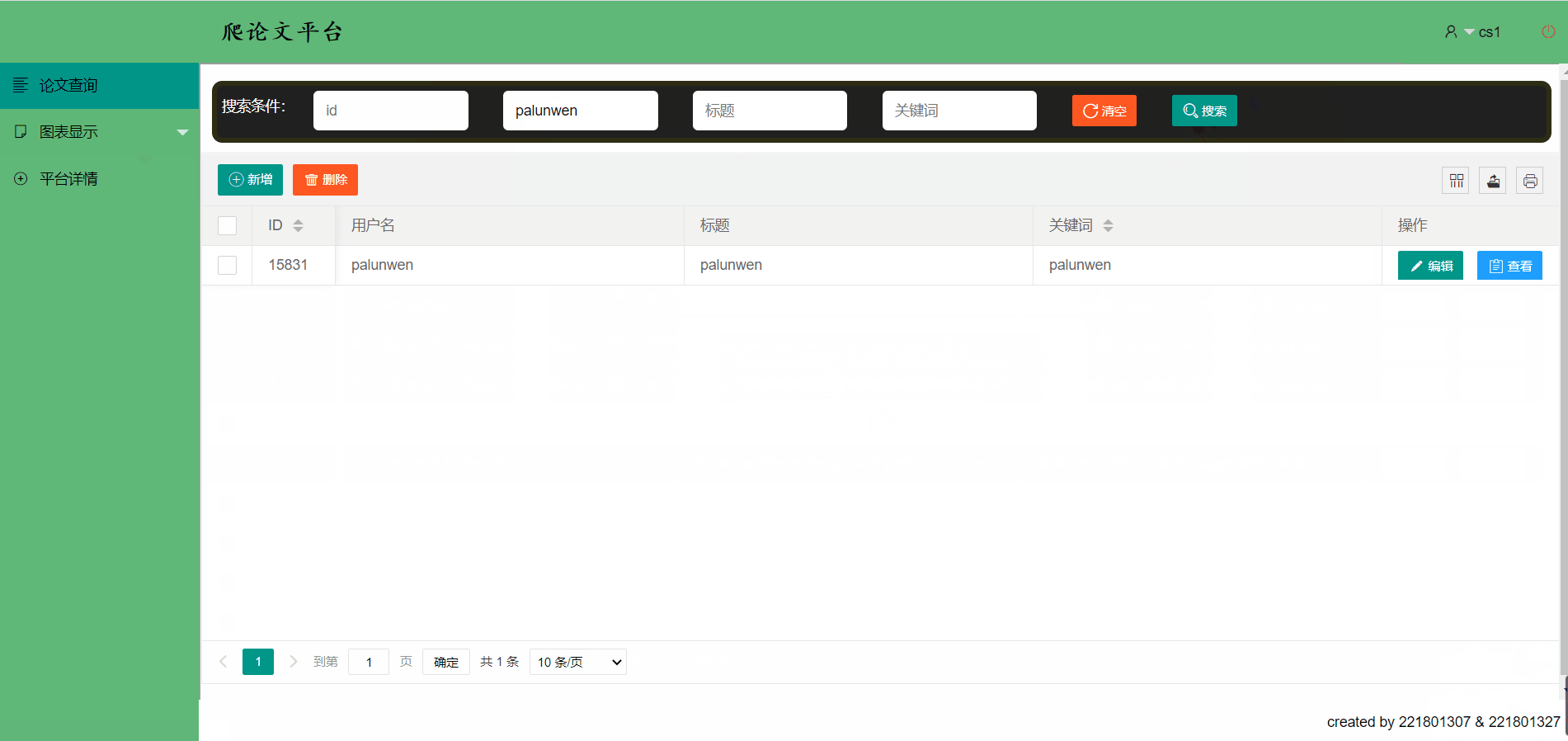
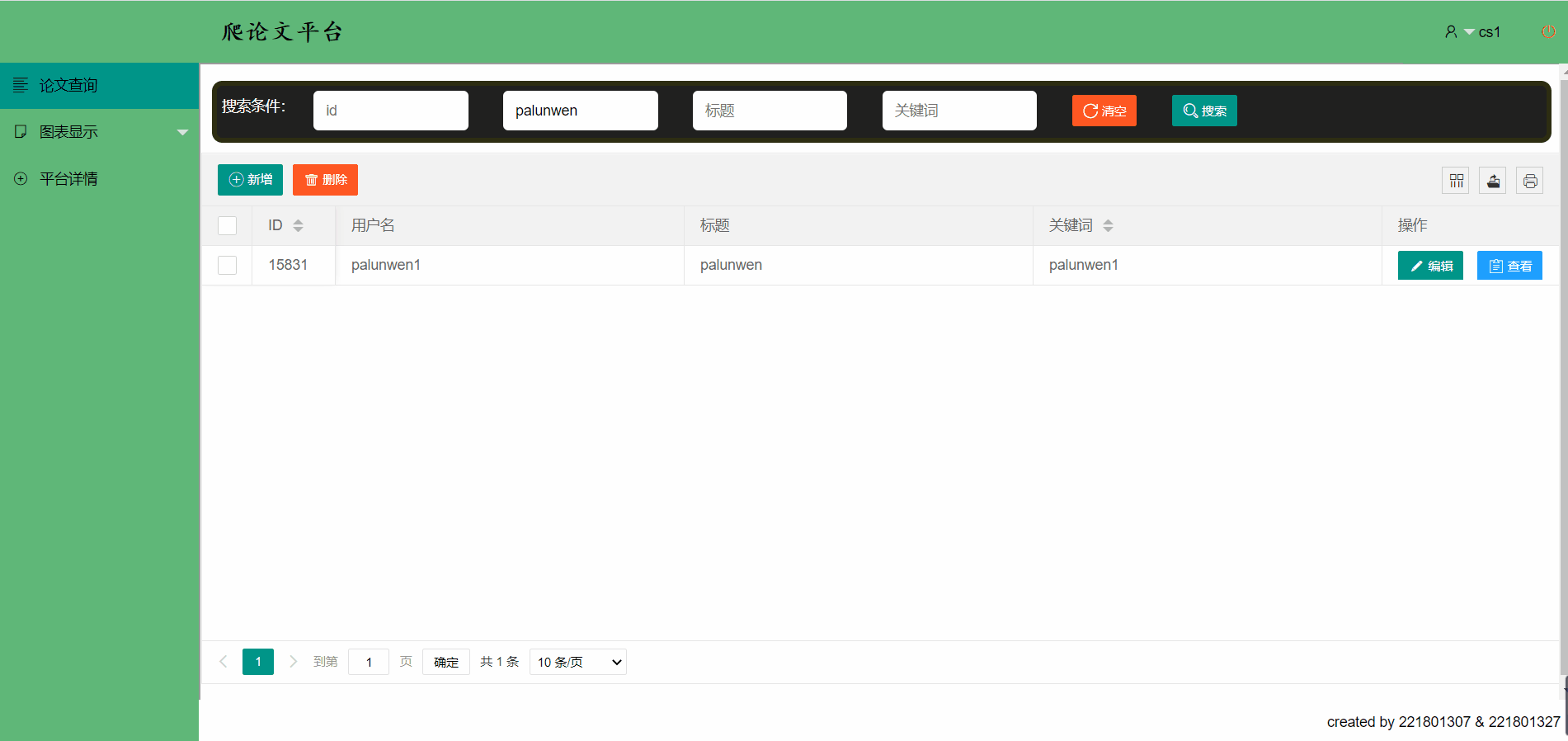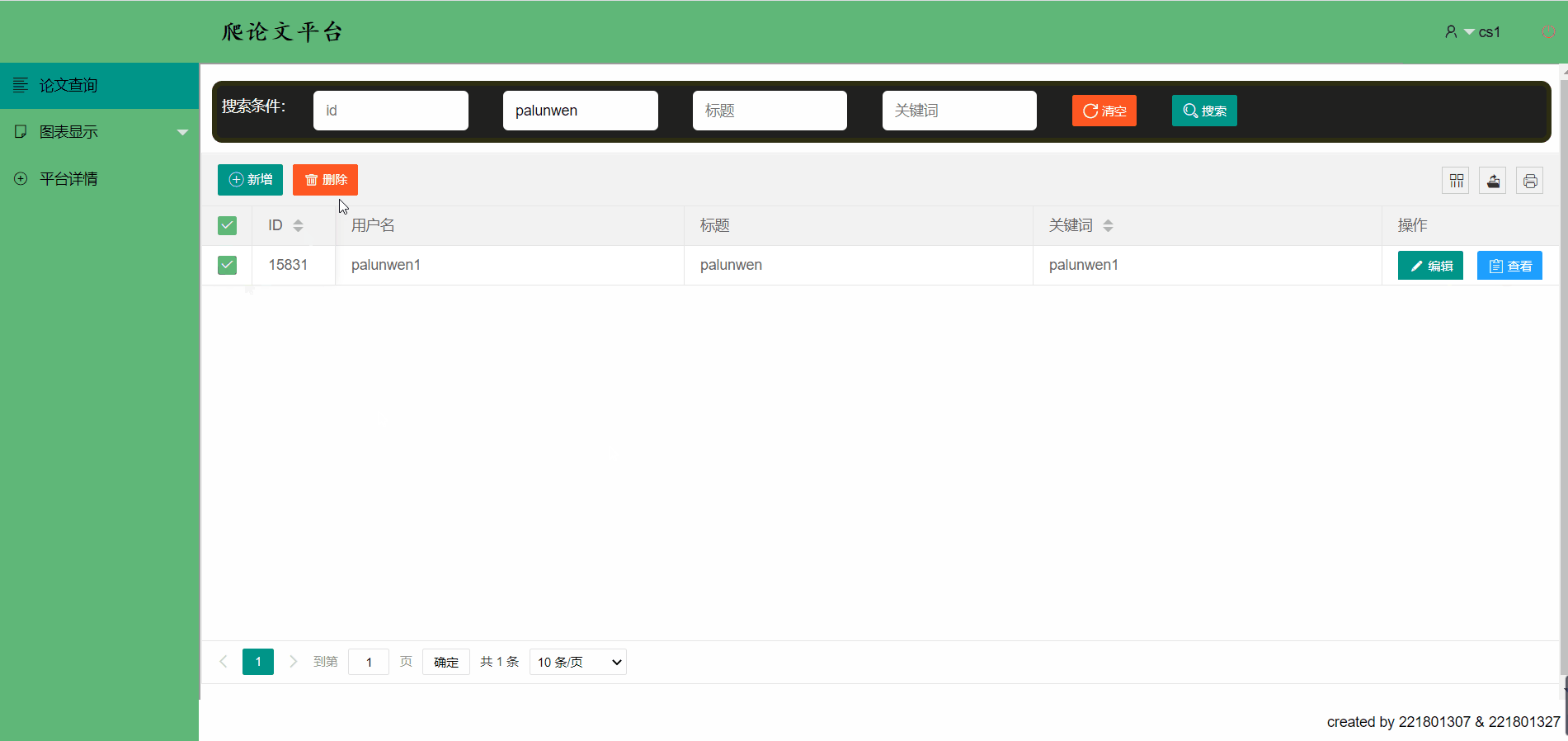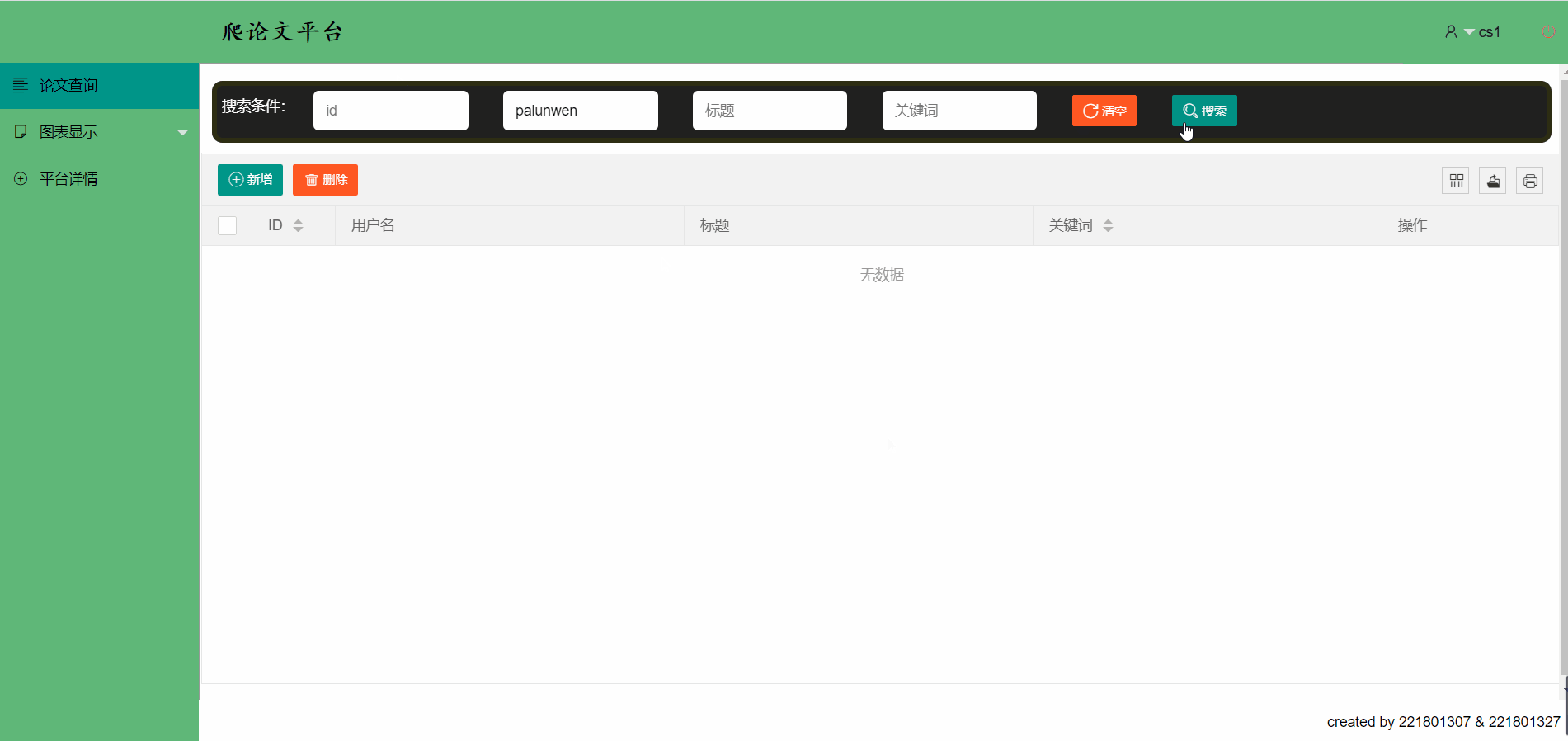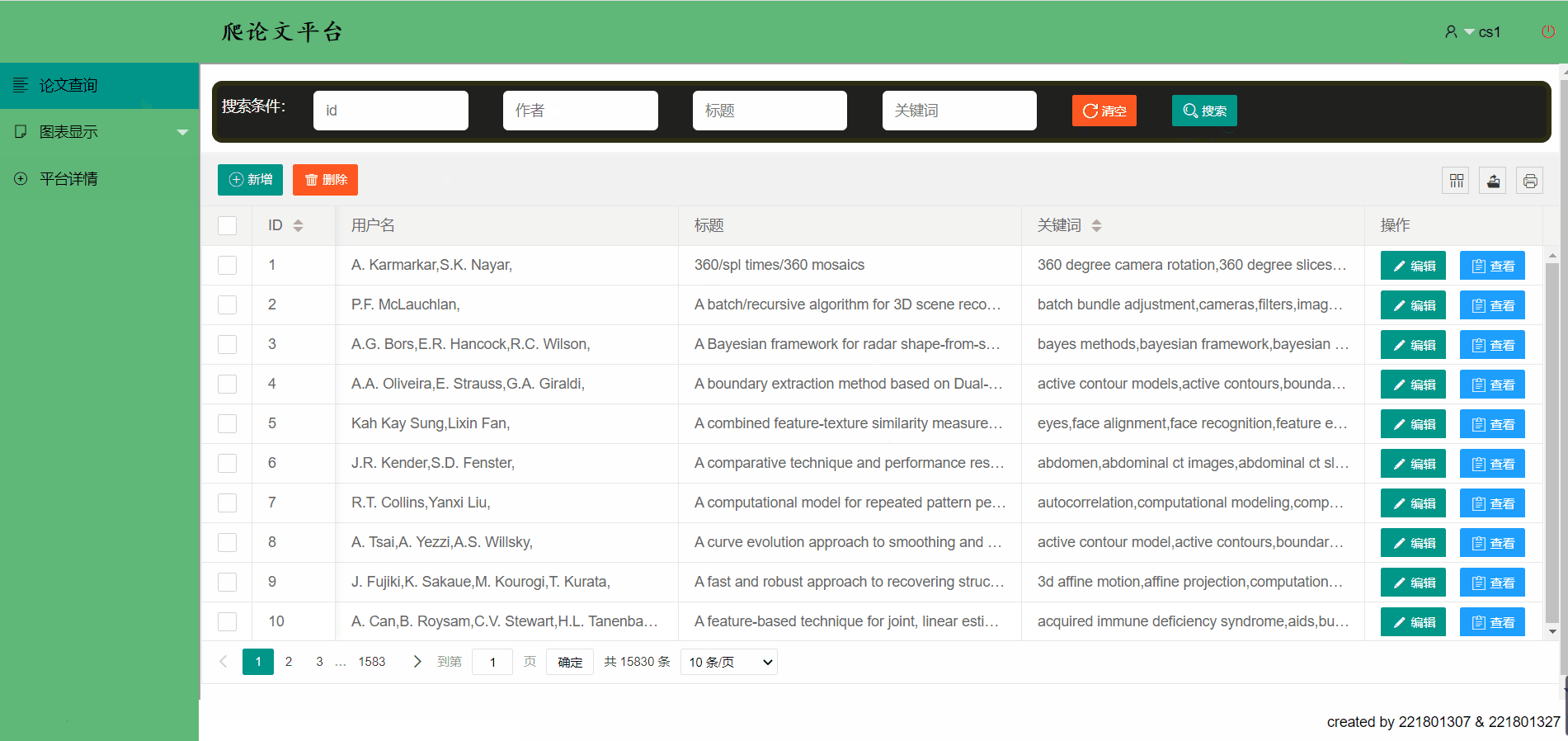
- 论文展示->使用表格的形式向用户展示数据,简洁明了

论文平台支持模糊查找
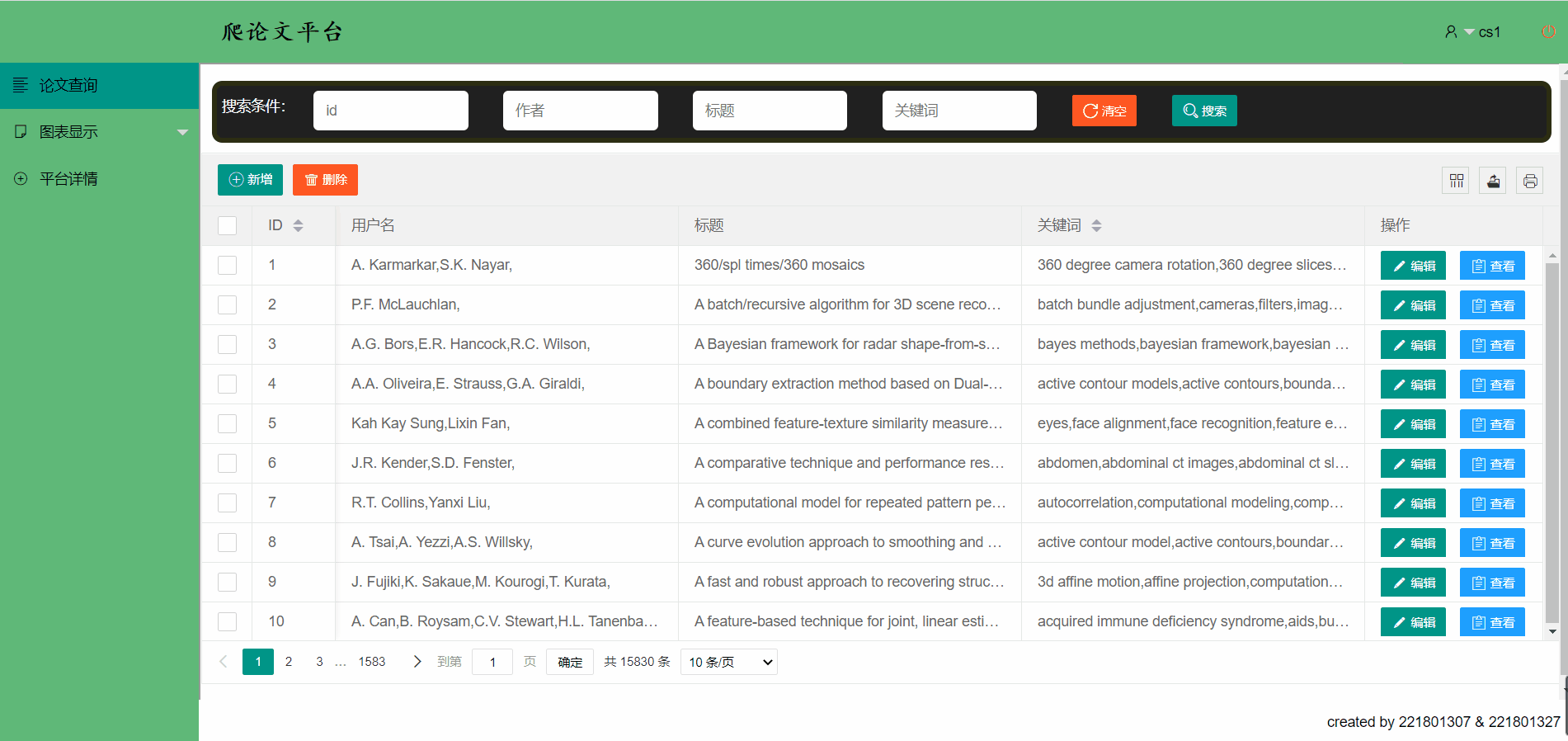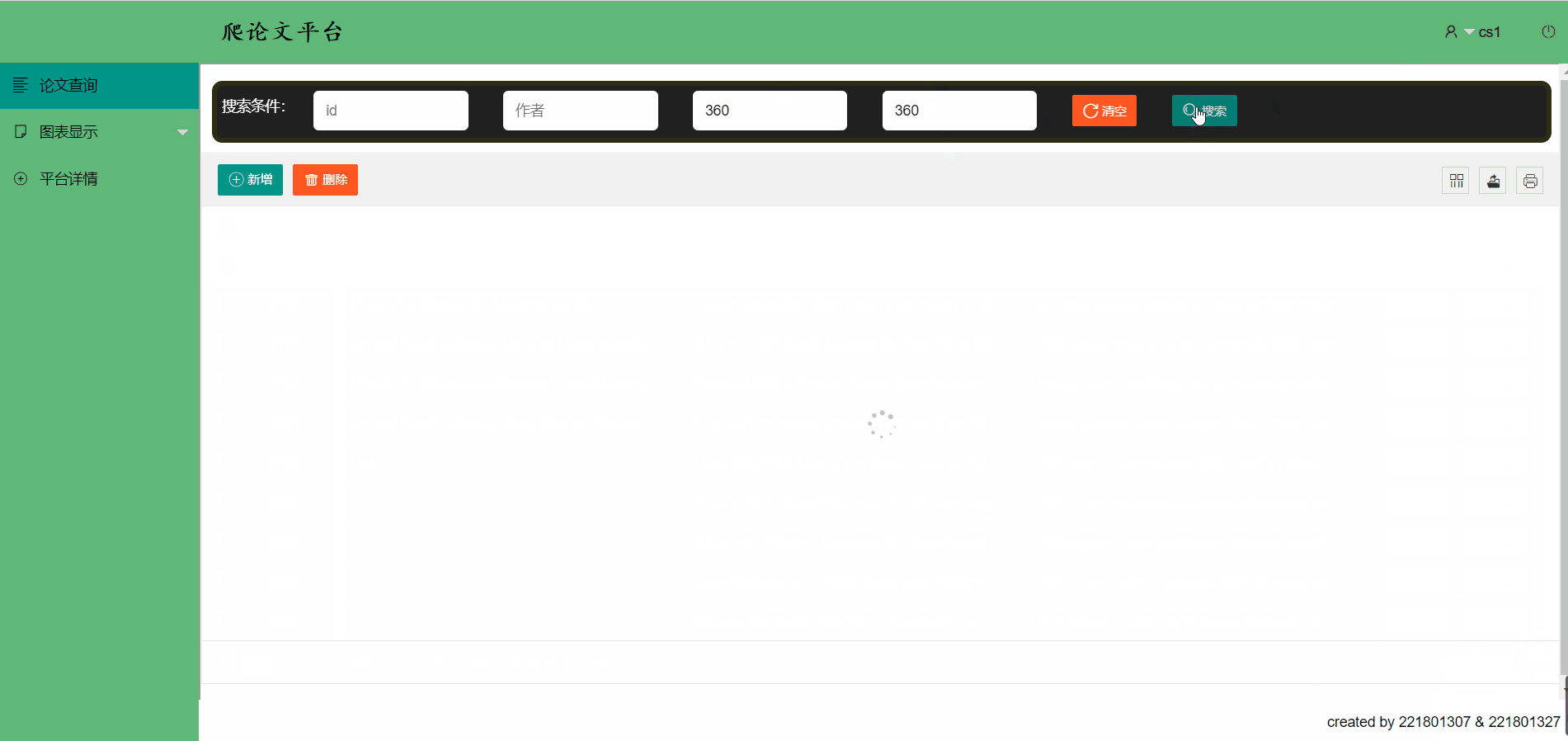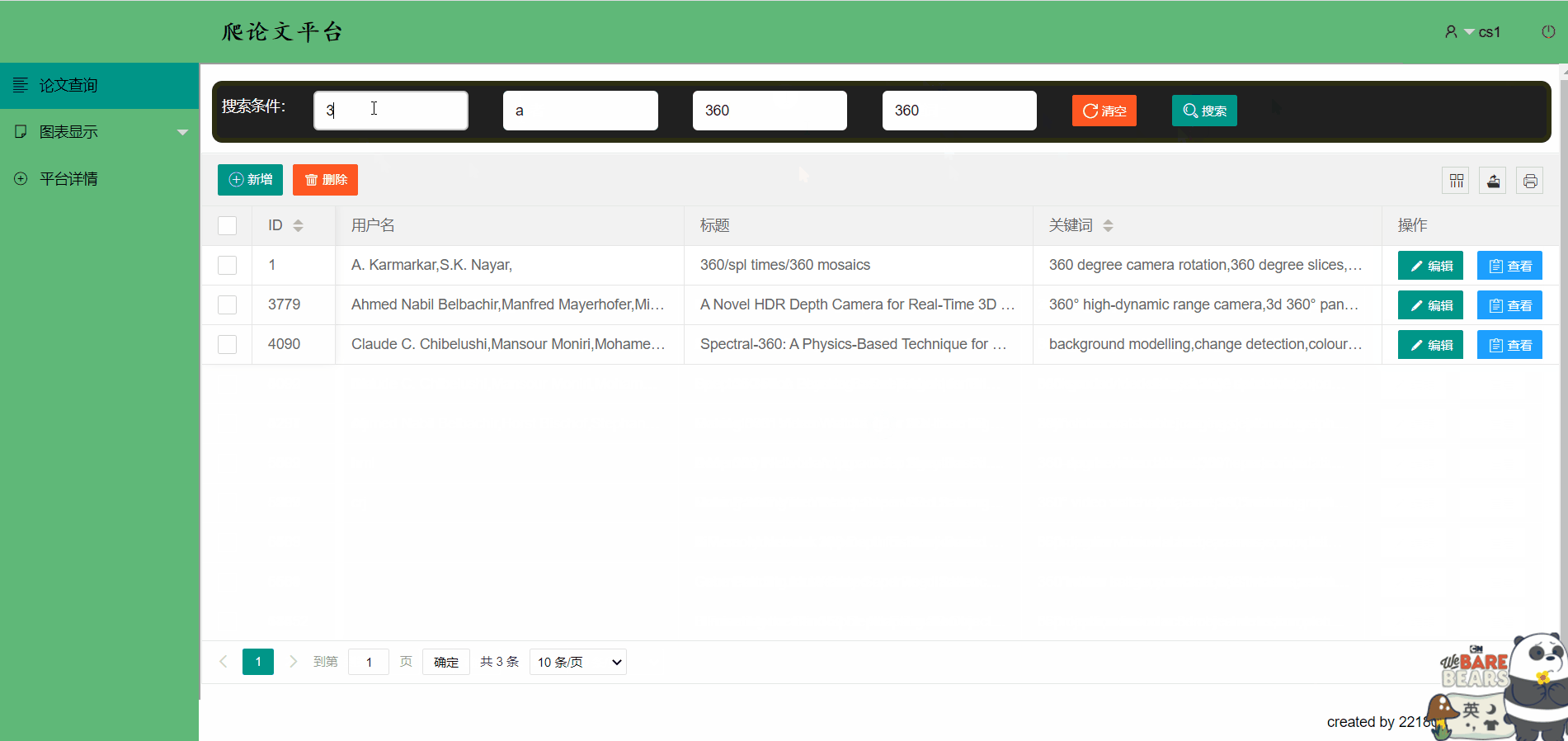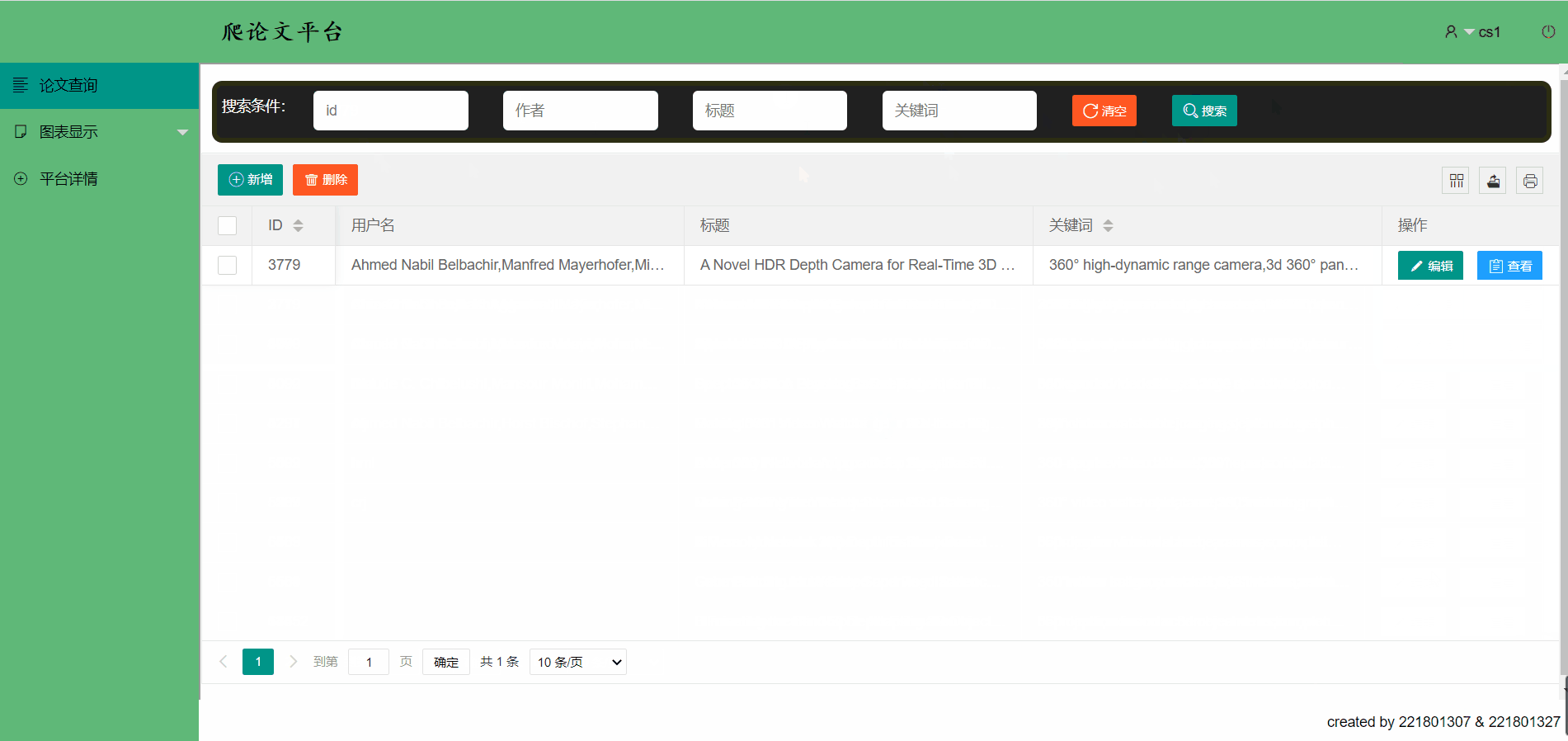
新增一篇论文信息
编辑一篇论文信息,并进行查看

删除一篇论文信息
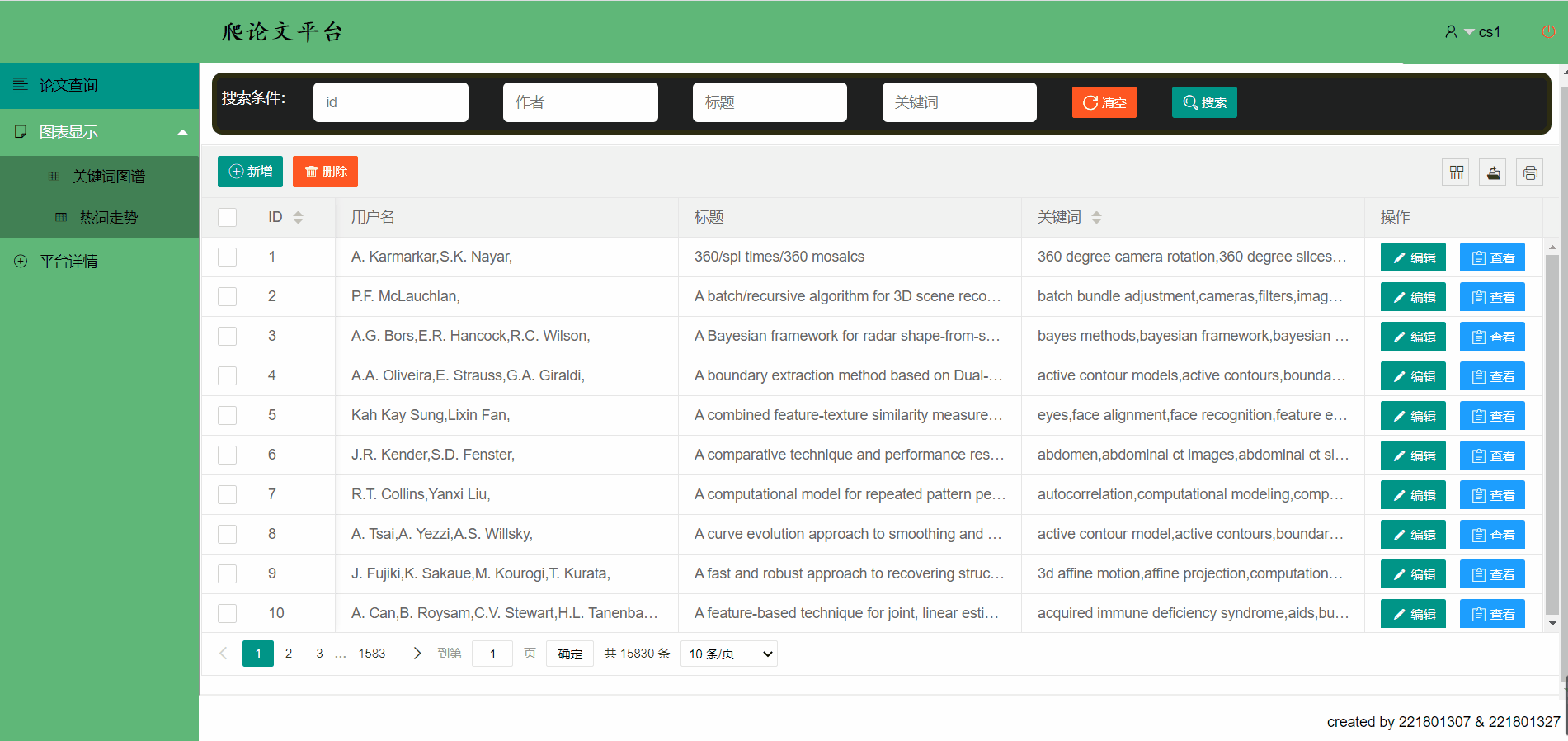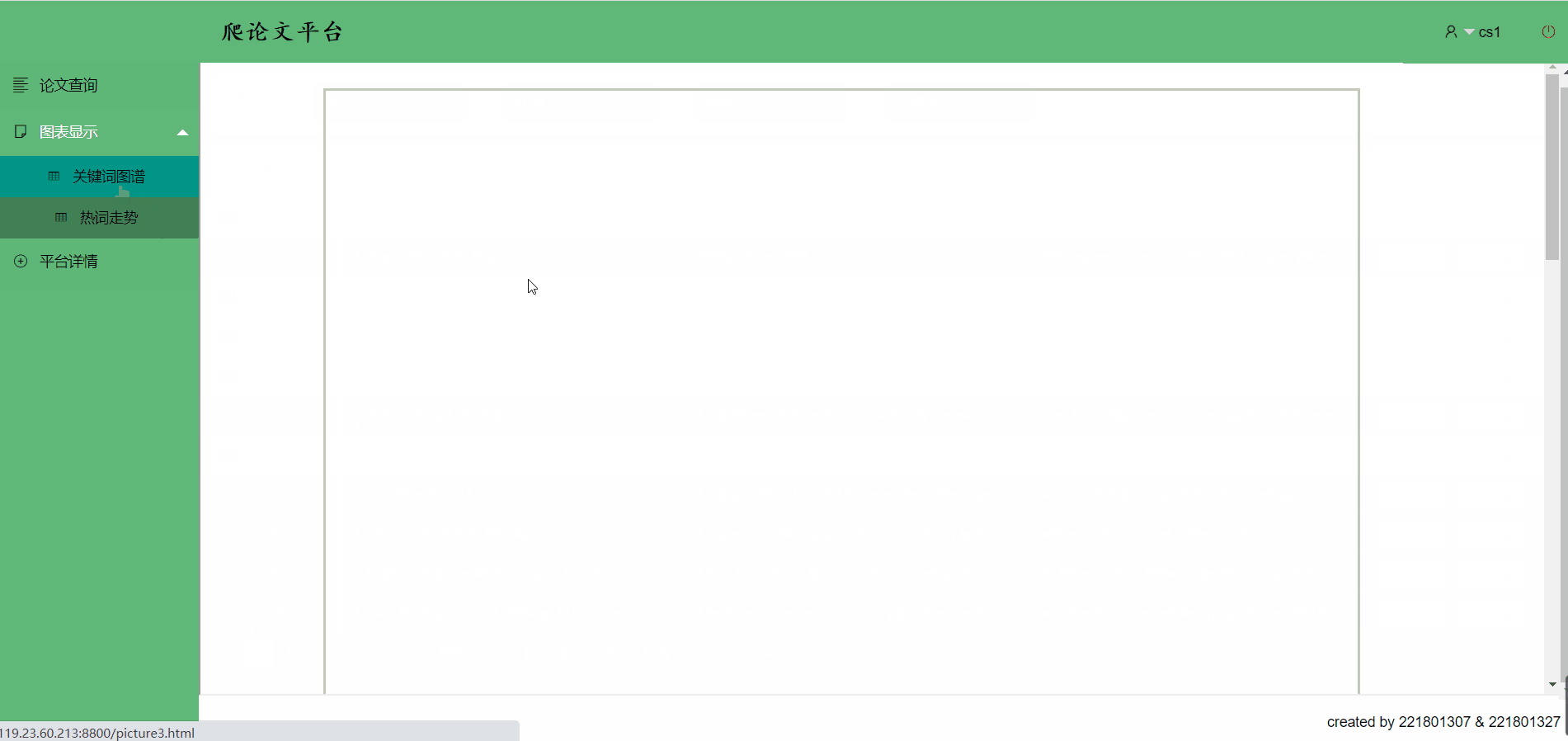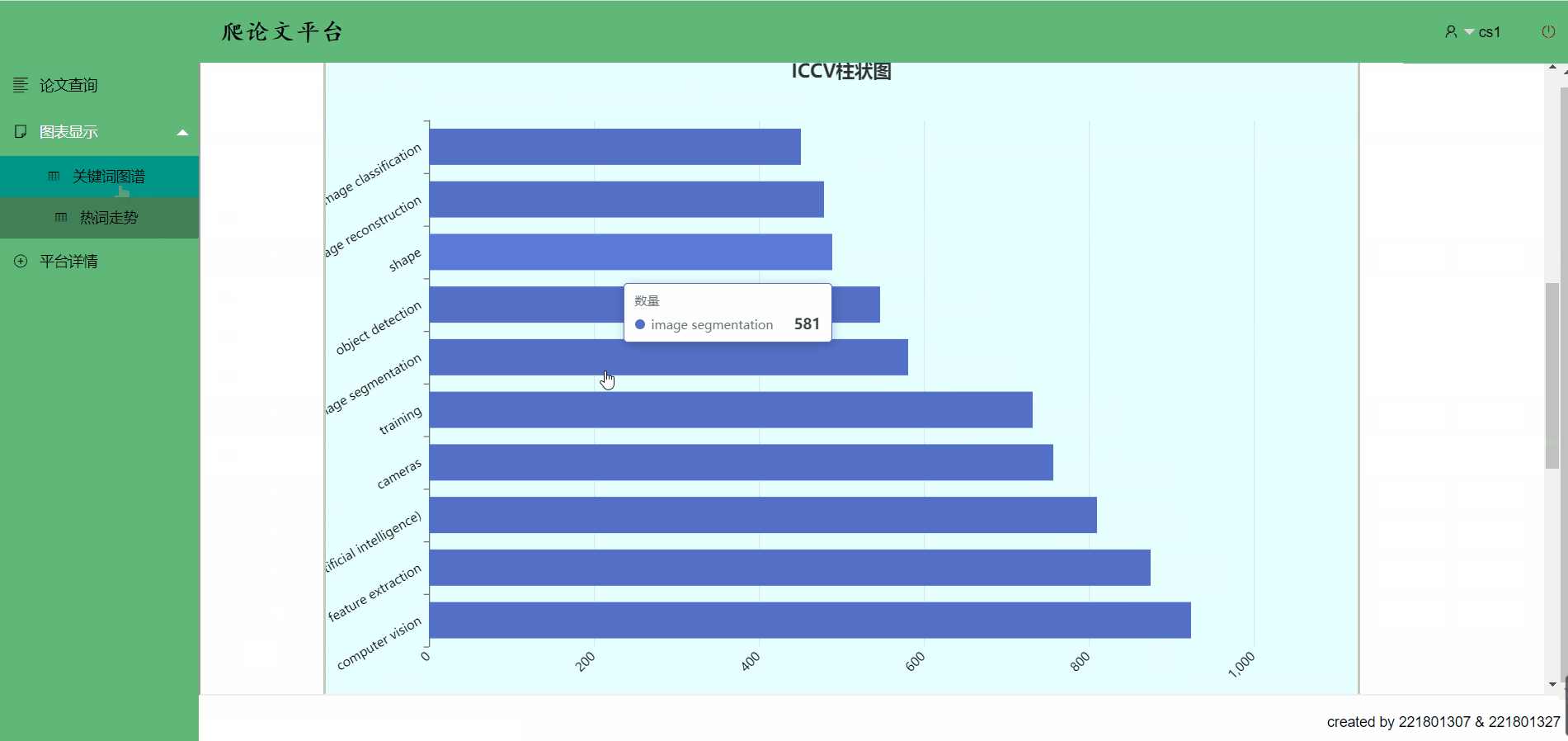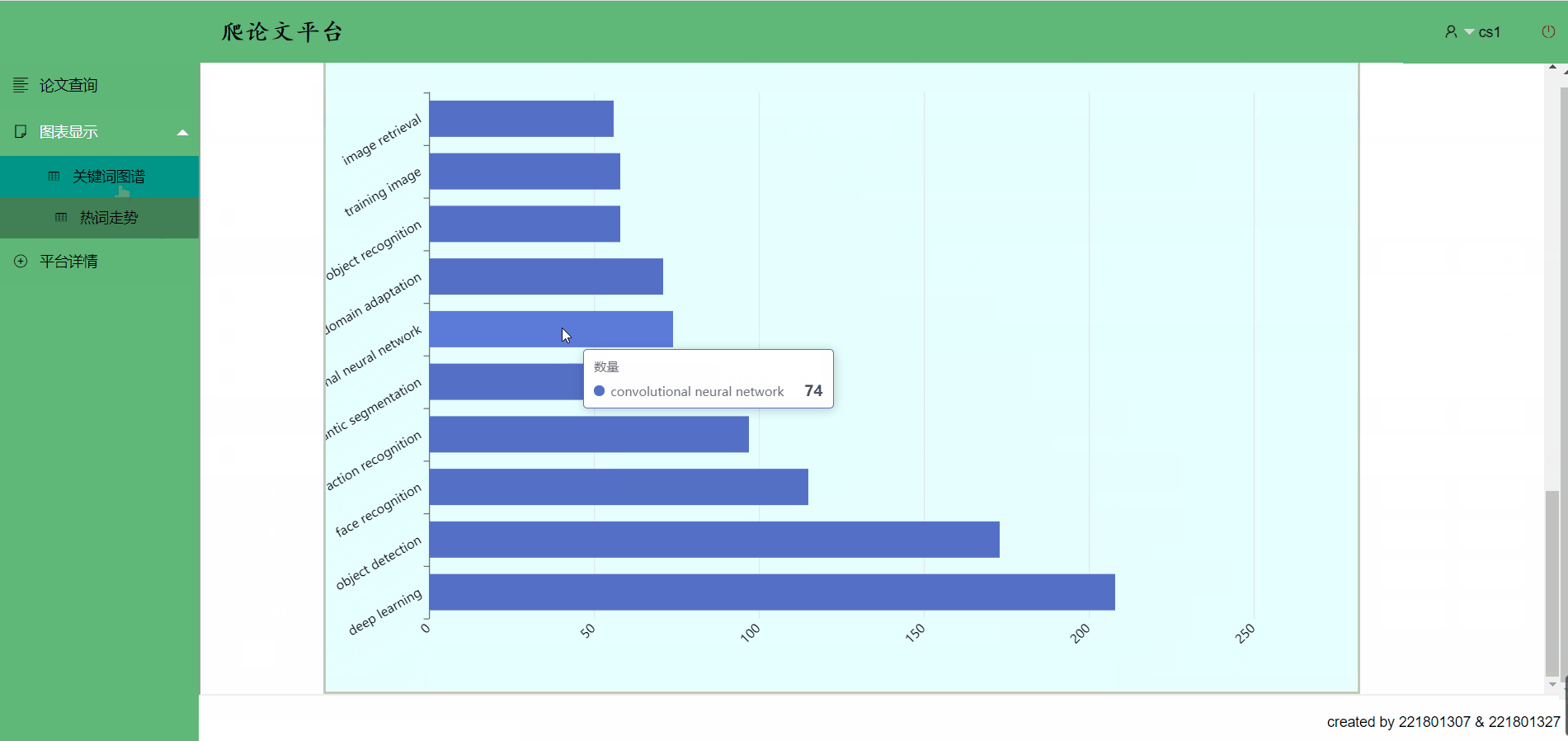
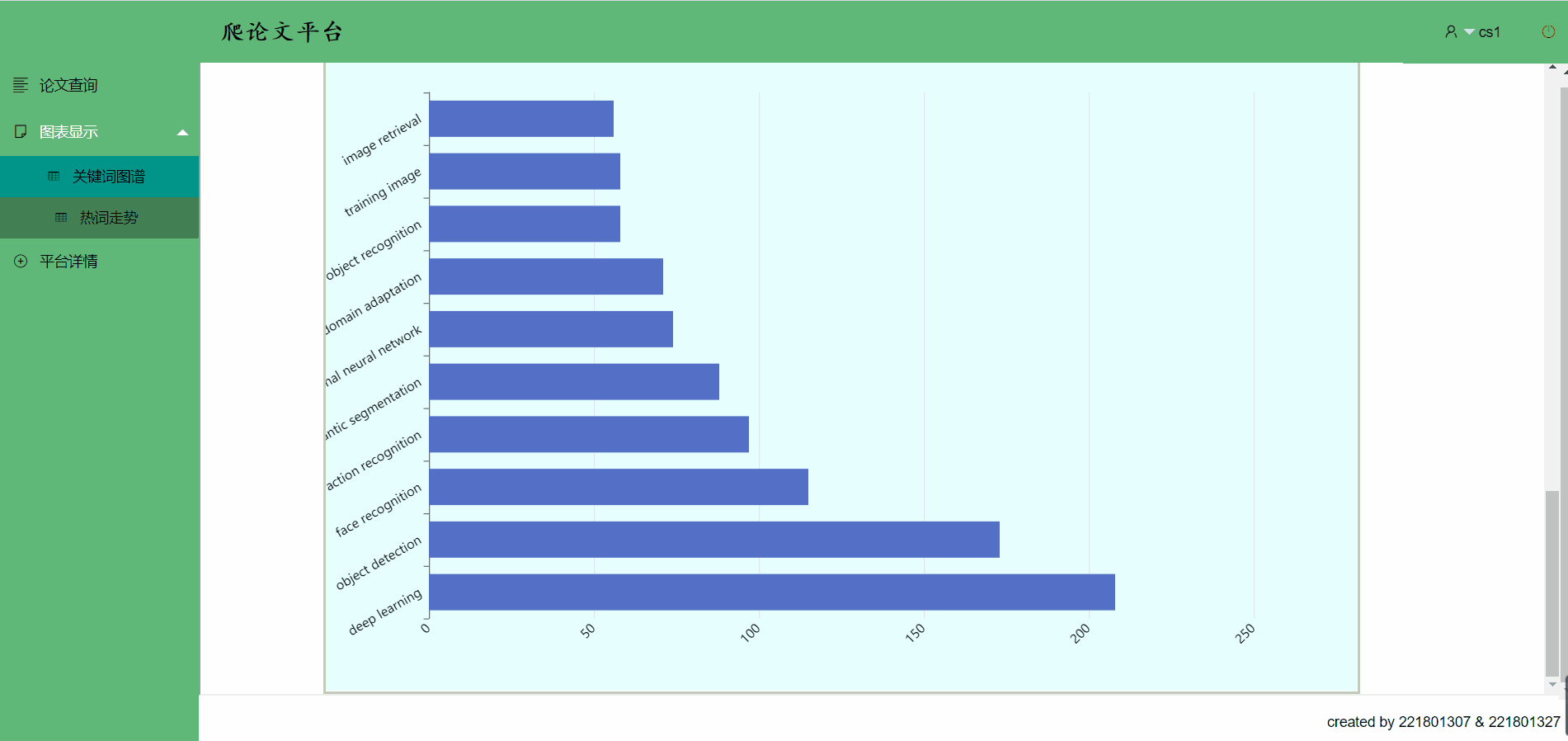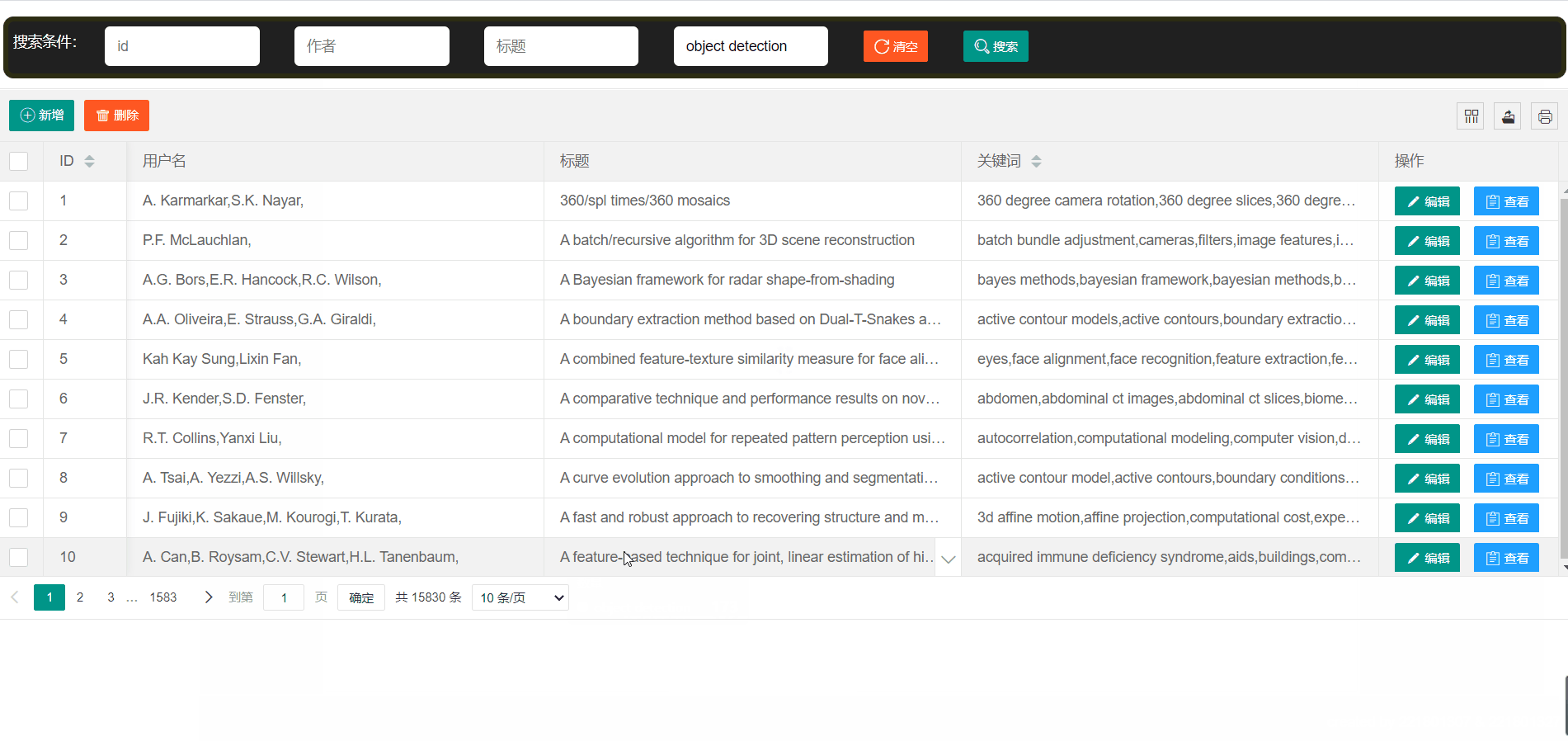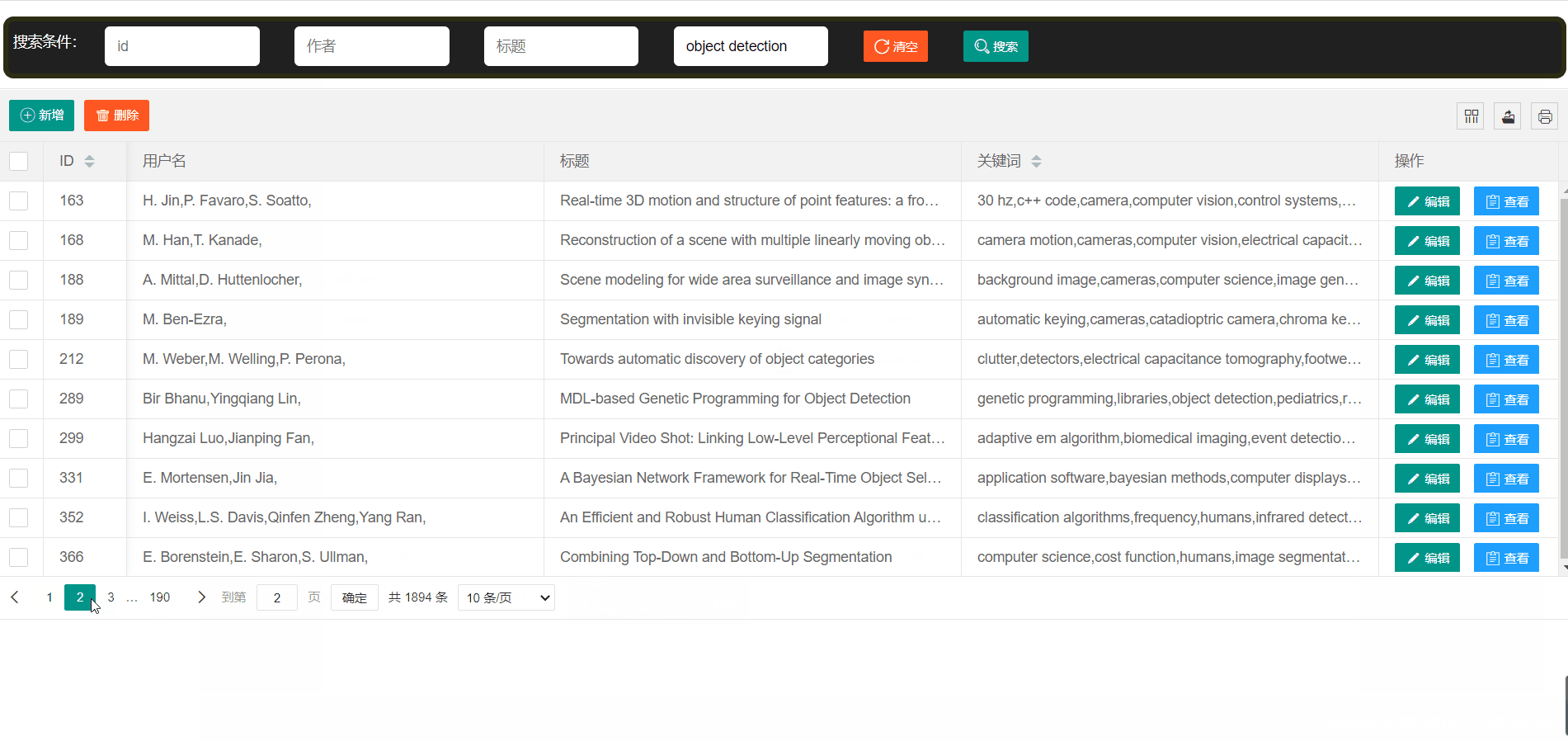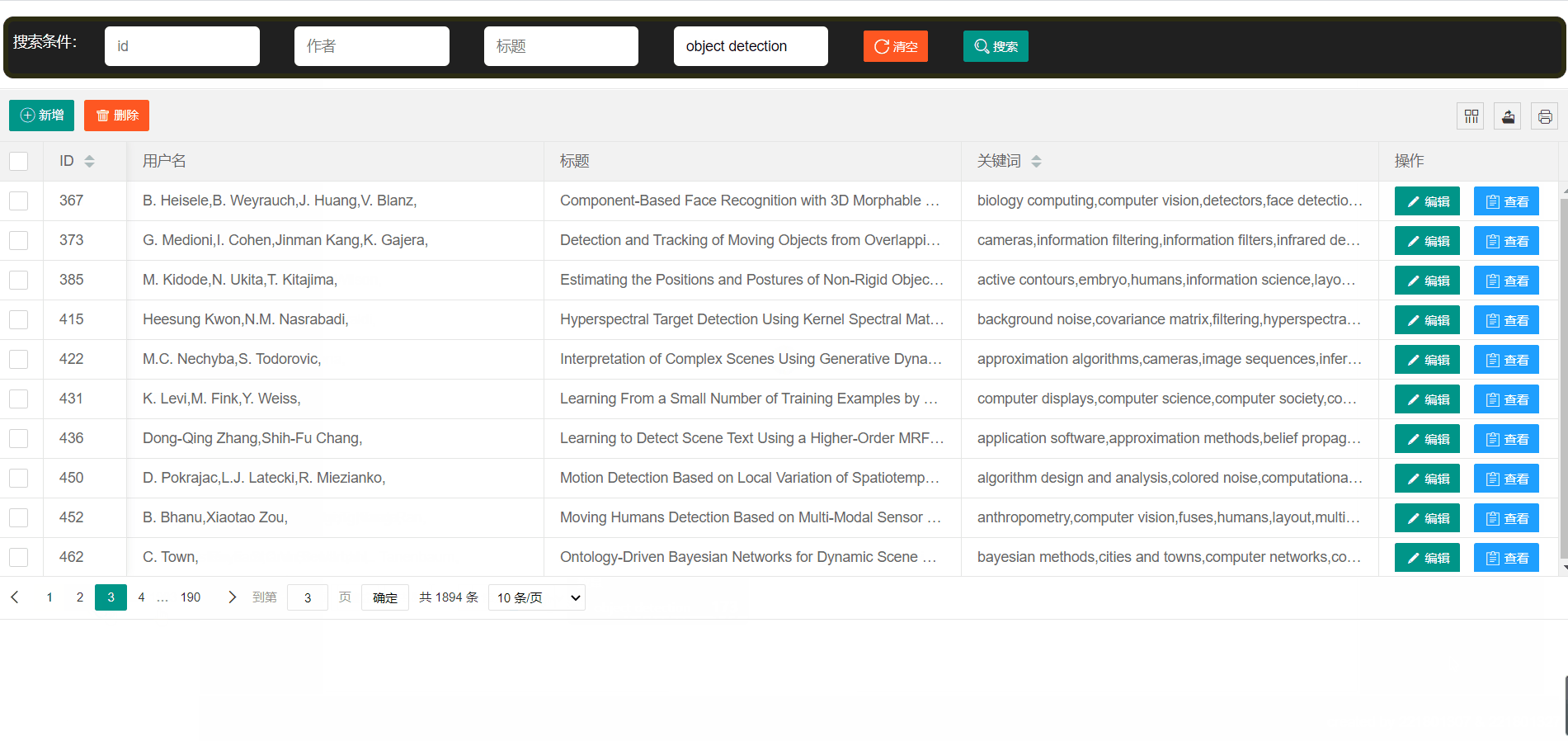
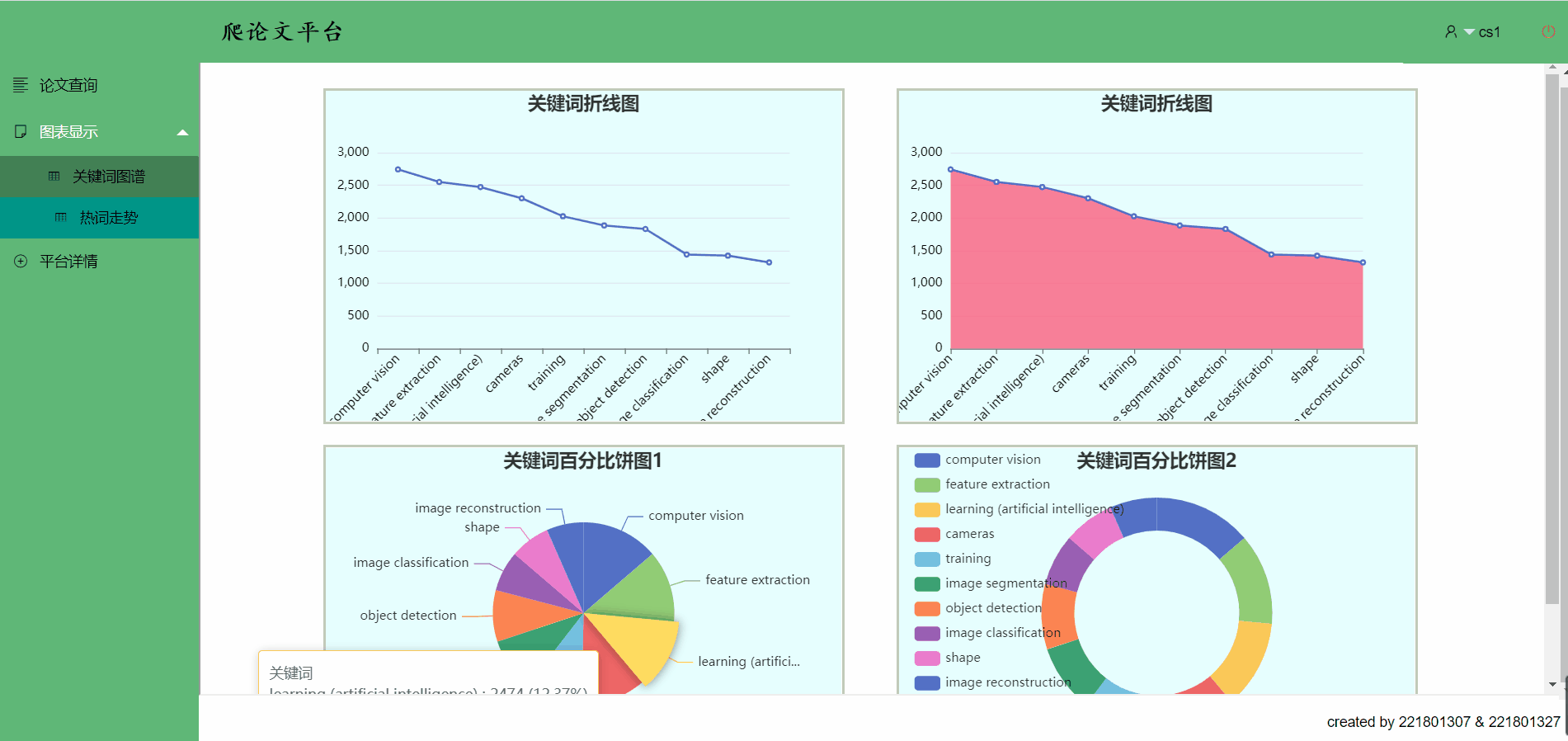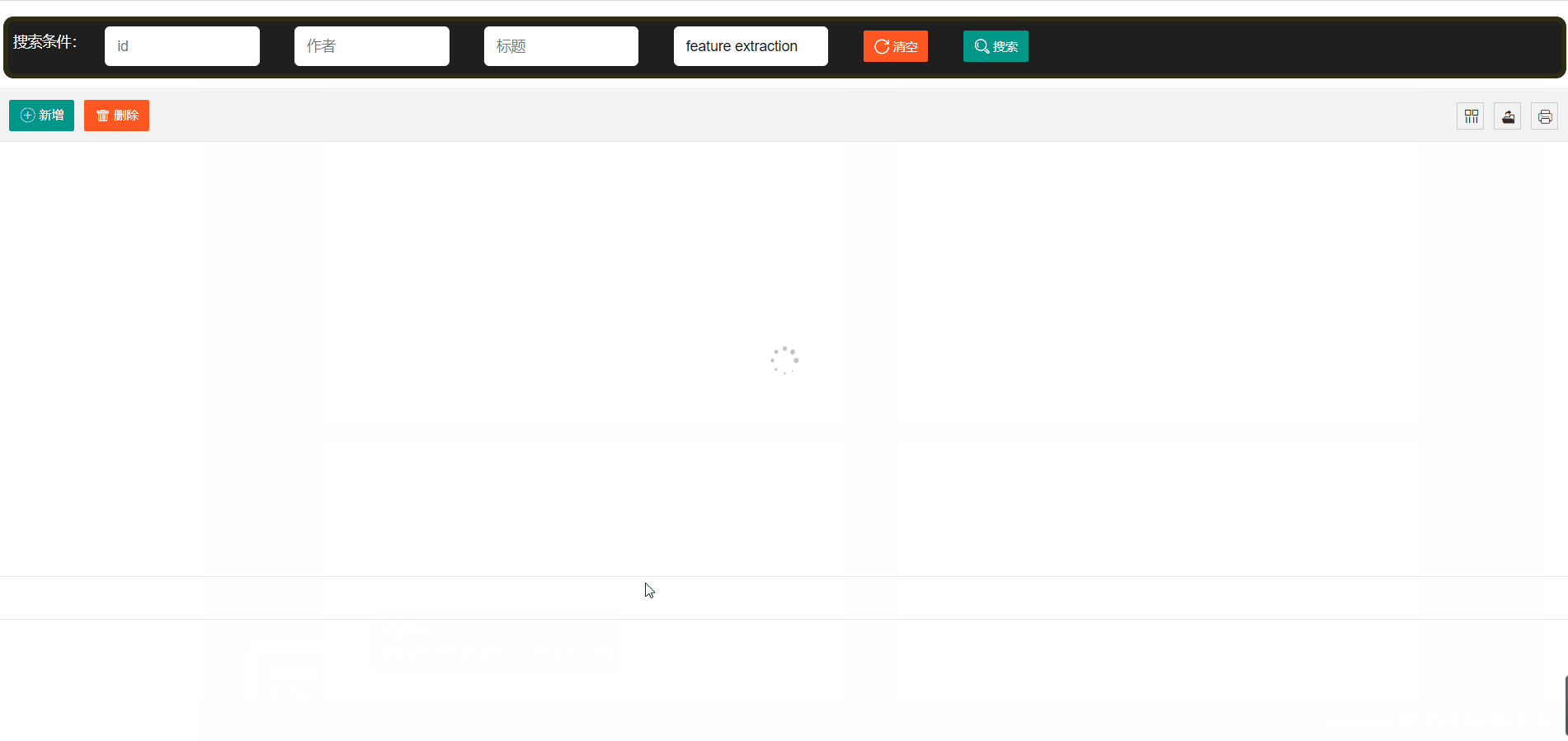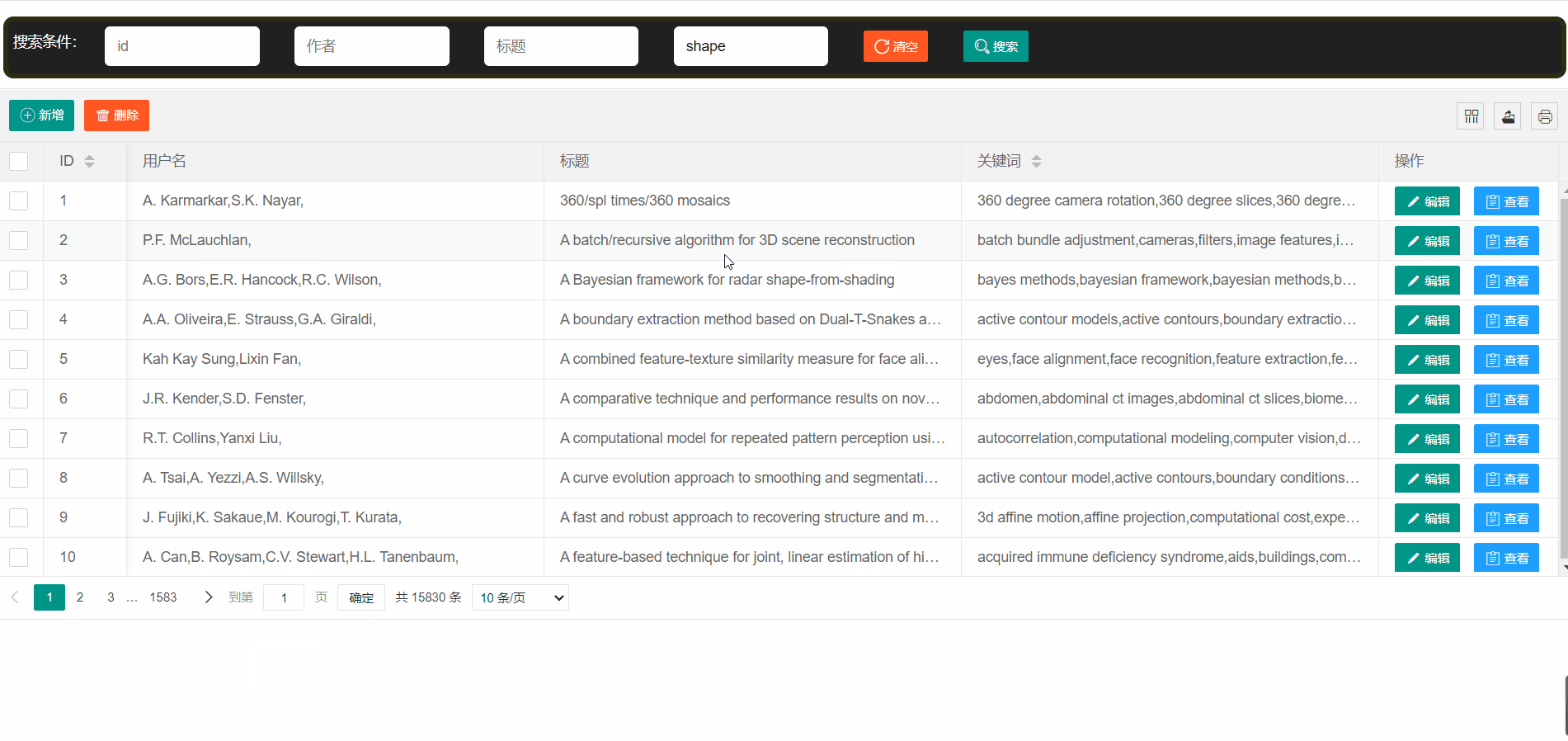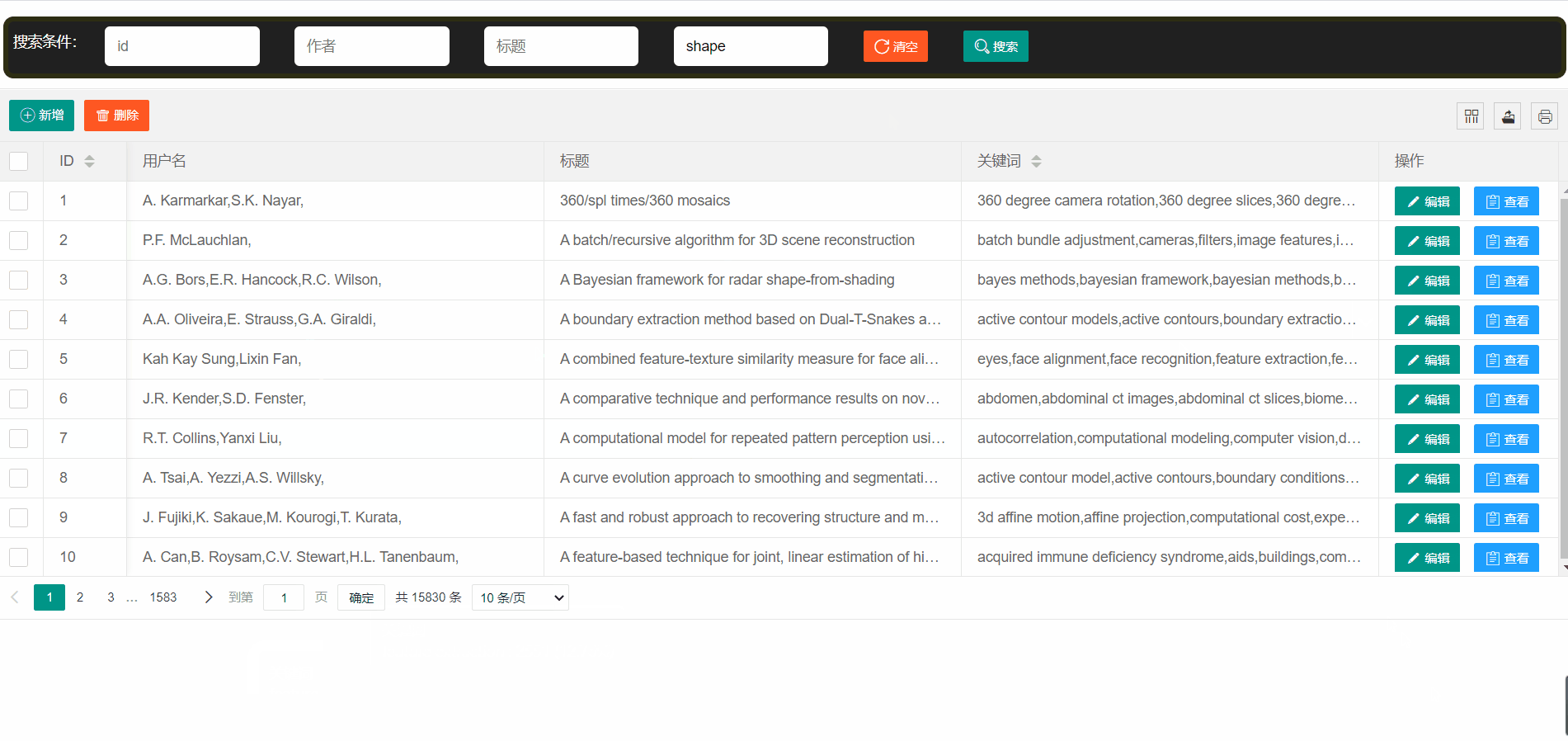
关键词图谱->移到关键词条上可以看到部分数据,点击也有跳转哟
热词走势
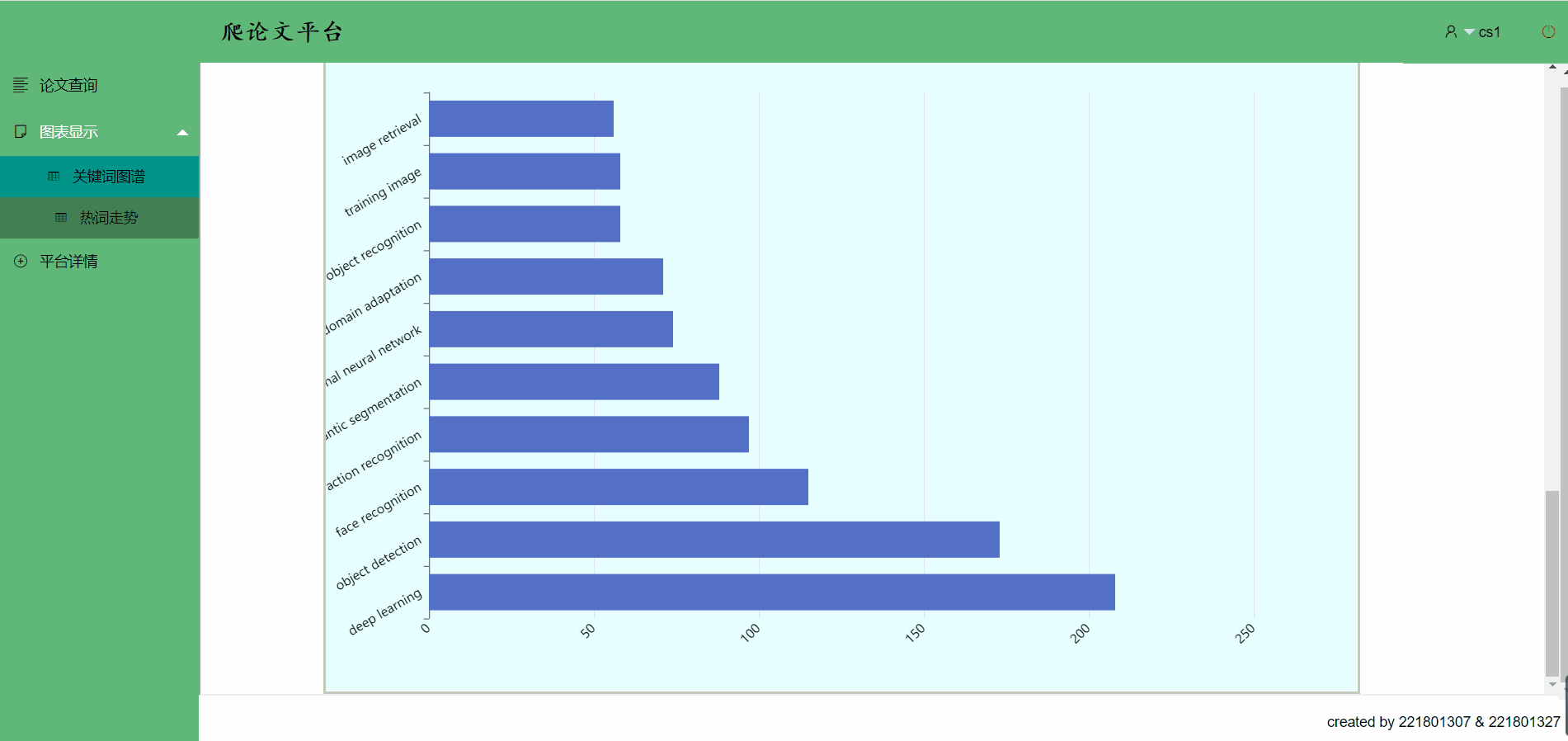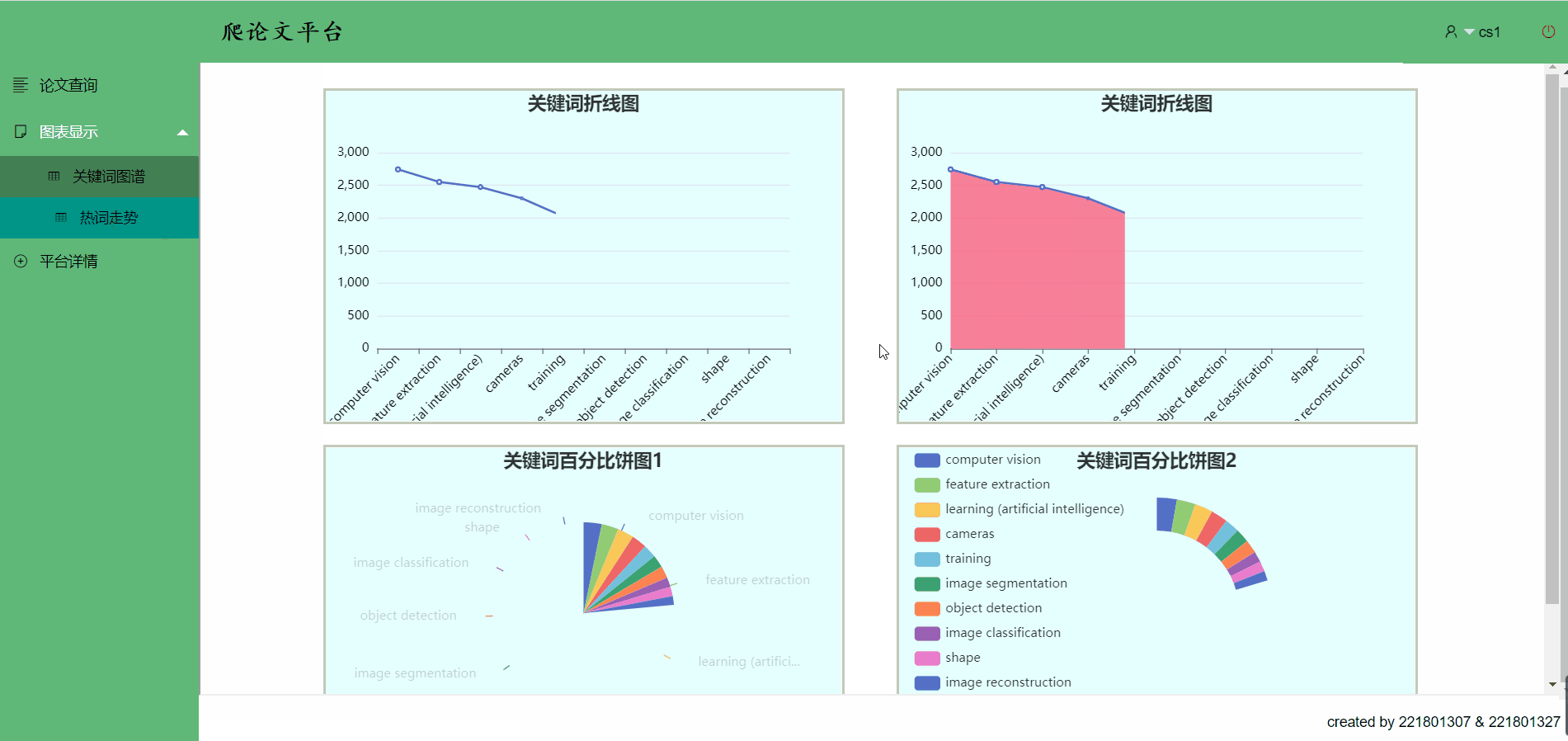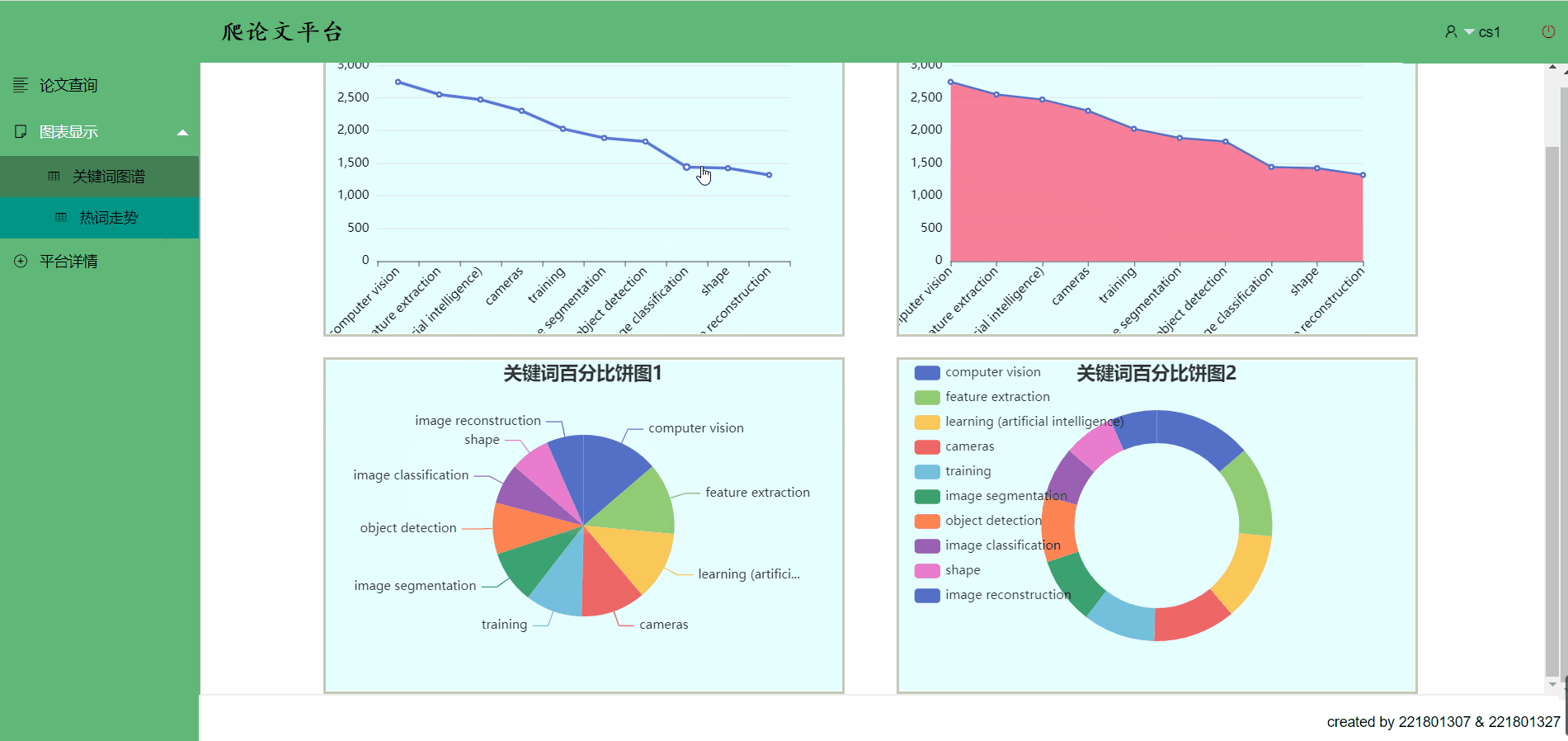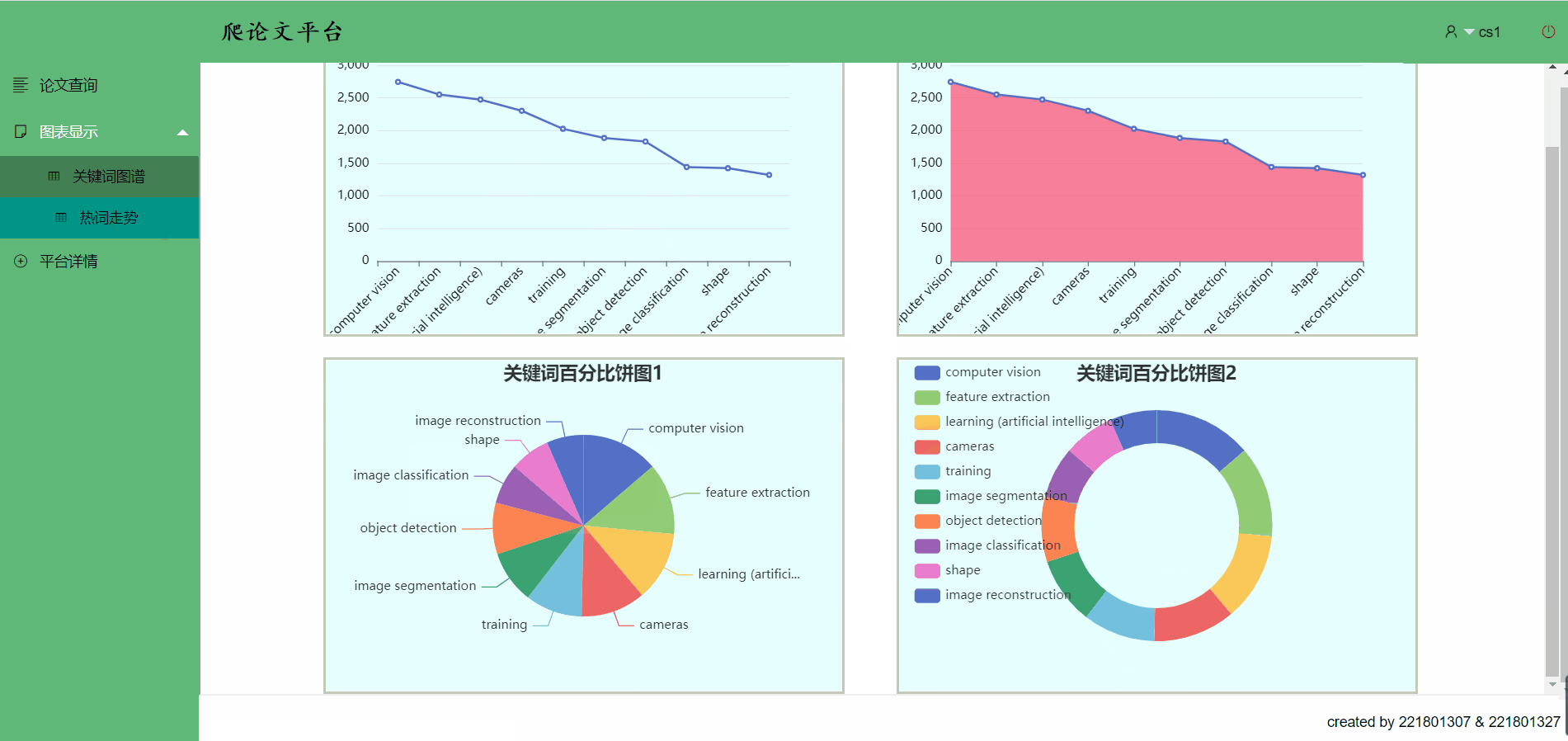
点击关键词,热词跳转->你想跳的,这里都有
表格分页->10条太多看不过来,那就换成5条吧
平台信息->我编的,你别信

6.结对过程讨论
折线图和柱状图的制作讨论
学习使用springboot过程中的讨论
刚开始拿到题目的时候,我们还是很庆幸助教们降低了难度,暂时不需要我们通过学习爬虫技术进行资料收集。但是,处理数据,将数据整理成我们可以使用的数据库表也是一个锻炼我们分析的过程
随后,我们大致分配了一下两个人学习的方向,互相学习,查找资料,通过运行一些小项目和观看视频,逐渐帮助我们熟悉springboot框架,layui,mybatis,druid,maven这些新朋友
以下是我们讨论过程中的一些具体截图,希望我们以后能和"新技术"hxd们相处的其乐融融
第一次使用这样的"新"框架,不得不说依赖的配置也是一门"艺术"活,在这个过程中我们查阅了很多框架上的资料,然后才将项目过程中的依赖一点点的导入进去,然后成功的运行了小小的项目。另外我们也学习了通过配置maven来帮助我们协调冲突
一些数据在调用的过程中出现问题,不显现。最终还是在"反复调试"后出来了成品
实现编辑文章的功能
这是在一次测试过程中,发现有部分数据没有显示,尽管"艰难"的debug,经过和队友的讨论,我们发现问题出在我们增加了一个新的类型,却忘记了对部分方法进行修改
ui界面设计的讨论
我们讨论设计了一个轮播图界面跳转登录界面,最后再进入论文平台的界面,虽然可能比较复杂。因为想学习用一下轮播图框,然后把界面弄得好看一点
7.设计实现过程
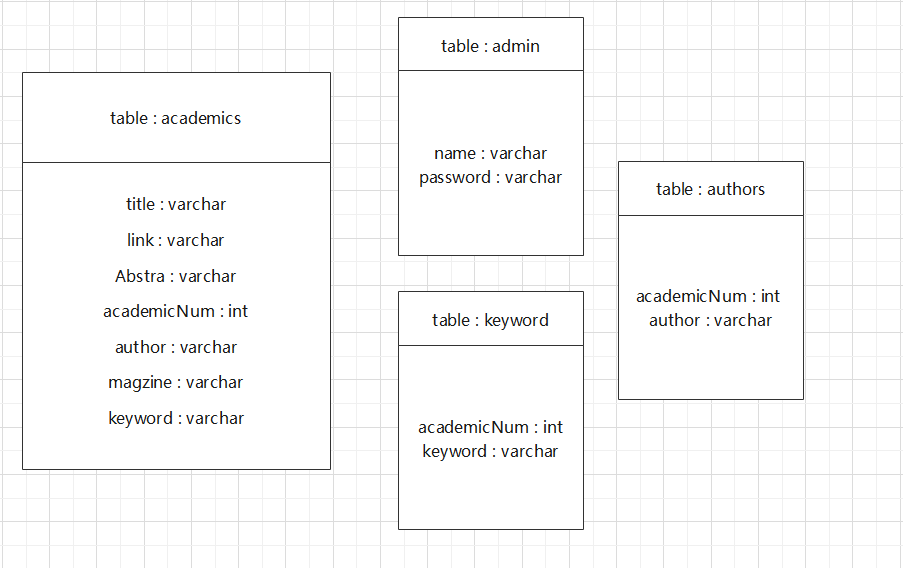
数据库表
数据库中有四张表,分别是authors, admin, academics, keyword。 我们将论文数据整理成四张表,主要依赖academics这张包含论文信息的表,在这张主表上面进行增删改查功能的实现。
项目框架
本次项目开发过程采用了springboot框架 + mybatis + druid + layui的技术,项目的框架结构如下

前端
- 采用layui框架,使用layui组件进行布局,js动态生成数据,和连接页面的跳转
- 登录界面采用轮播图播放一些图片
- 在用户输入用户名,密码,验证码时,会对输入是否为空,验证码是否正确进行判断
- 主界面采用layui框架的侧边栏 + 分页面形式
- 论文的数据通过表格进行展示,实现增删改查的按钮与事件响应绑定,并弹出对应的对话框与用户进行响应交互
- 关键词图谱和热词趋势采用echarts插件对数据库中检索到的数据进行展示,并在点击时实现响应和部分数据显示
- 平台详情显示一些关于平台的具体信息,供用户和平台进行联系
后端
- 采用springboot框架,数据库使用mybatis进行连接和关闭
- pojo : 封装了Academics, Admin, Keywords, author, ResultBean类,前四个对应数据库建立的四张表,最后一个类封装前后端交互的数据
- dao : 定义了AdminDao, KeywordDao, MyDao实现了数据库各种类型增删该查的Mapper数据接口
- security : 定义了网站的权限访问,禁止用户在未登录的情况下进入该系统
- service : 实现了每种接口的具体类Service和ServiceImpI
- config : 协同security管理权限
- controller : 通过调用service层来负责具体业务,供前端进行调用,并将结果返回给前端
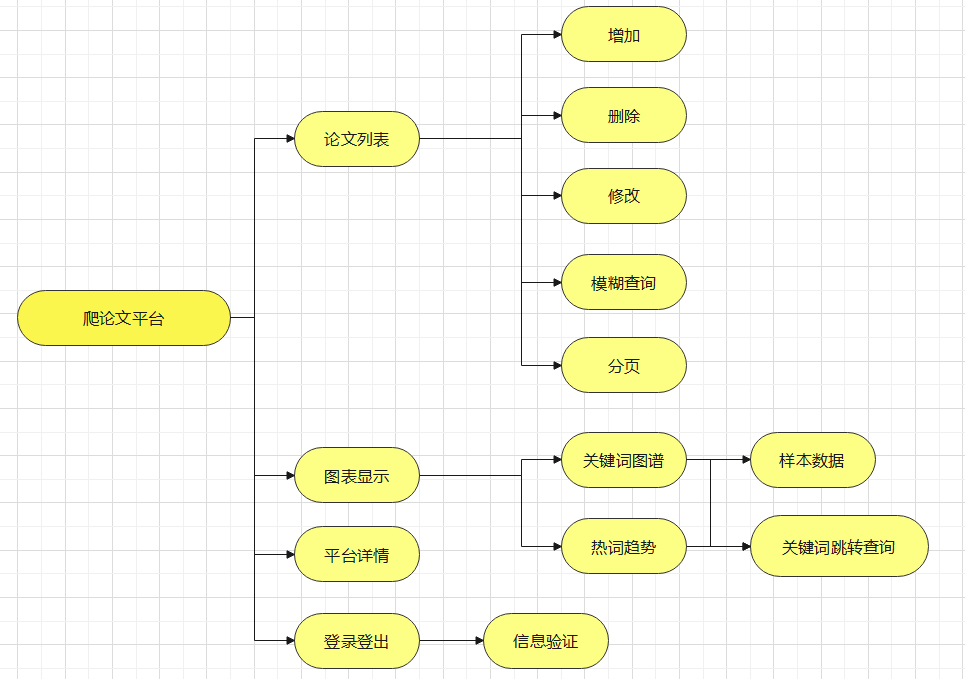
功能模块
8.关键代码描述
1.热词统计
该代码实现在热词趋势过程中,统计ICCV论文中前10关键词的功能,并将关键词的数据以Map的形式进行返回
从数据库中提取数据,获取每篇文章出现的关键词并进行统计
List<Keywords> list = keywordsService.findAllKeywordsICCV();
Map<String, List> map = new HashMap<>();
Map<String, Integer> ma = new HashMap<>();
int num = 10;//输出前十的关键词
for (int i = 0; i < list.size(); i++) {
Keywords keywords = list.get(i);
if (ma.get(keywords.getKeyword()) != null) {
int value = ma.get(keywords.getKeyword());
value++; //该关键词如果出现过就+1存入ma
ma.put(keywords.getKeyword(), value);
} else {
ma.put(keywords.getKeyword(), 1);
}
}
将HashMap中的包含映射关系的视图entrySet转换为List,然后重写比较器
List<Map.Entry<String, Integer>> list3 = new ArrayList<>(ma.entrySet());
List<Integer> list4 = new ArrayList<>();
List<String> list5 = new ArrayList<>();
//idea自动转化成lambda表达式
list3.sort((o1, o2) -> o2.getValue().compareTo(o1.getValue()));
//输出
//同词频单词表
List<String> sameFrequency = new ArrayList<>();
//输出统计
int outputCount = 0;
if (list3.size() < num) {
num = list3.size();
}
if (list3.size() == 1) {//如果只有一个关键词,直接存入map,返回给前端
list4.add(list3.get(0).getValue());
list5.add(list3.get(0).getKey());
map.put("x", list5);
map.put("y", list4);
return map;
}
如果当前字符词频与下一个不一样,则对当前所有同词频单词排序
for (int i = 0; i < list.size() && outputCount < num; i++) {
if ((i == list.size() - 1) || !list3.get(i).getValue().equals(list3.get(i + 1).getValue())) {
//将当前单词加入同词频单词表
sameFrequency.add(list3.get(i).getKey());
//对同词频单词表排序
sameFrequency.sort(String::compareTo);
//按字典顺序记录同词频单词
for (String s : sameFrequency) {
list4.add(list3.get(i).getValue());
list5.add(s);
outputCount++;
}
sameFrequency.clear();
} else sameFrequency.add(list3.get(i).getKey());
}
下面贴出完整代码
public Map<String, List> dataToPic32() {
List<Keywords> list = keywordsService.findAllKeywordsICCV();
Map<String, List> map = new HashMap<>();
Map<String, Integer> ma = new HashMap<>();
int num = 10;//输出前十的关键词
for (int i = 0; i < list.size(); i++) {
Keywords keywords = list.get(i);
if (ma.get(keywords.getKeyword()) != null) {
int value = ma.get(keywords.getKeyword());
value++; //该关键词如果出现过就+1存入ma
ma.put(keywords.getKeyword(), value);
} else {
ma.put(keywords.getKeyword(), 1);
}
}
List<Map.Entry<String, Integer>> list3 = new ArrayList<>(ma.entrySet());
List<Integer> list4 = new ArrayList<>();
List<String> list5 = new ArrayList<>();
//idea自动转化成lambda表达式
list3.sort((o1, o2) -> o2.getValue().compareTo(o1.getValue()));
//输出
//同词频单词表
List<String> sameFrequency = new ArrayList<>();
//输出统计
int outputCount = 0;
if (list3.size() < num) {
num = list3.size();
}
if (list3.size() == 1) {//如果只有一个关键词,直接存入map,返回给前端
list4.add(list3.get(0).getValue());
list5.add(list3.get(0).getKey());
map.put("x", list5);
map.put("y", list4);
return map;
}
for (int i = 0; i < list.size() && outputCount < num; i++) {
if ((i == list.size() - 1) || !list3.get(i).getValue().equals(list3.get(i + 1).getValue())) {
//将当前单词加入同词频单词表
sameFrequency.add(list3.get(i).getKey());
//对同词频单词表排序
sameFrequency.sort(String::compareTo);
//按字典顺序记录同词频单词
for (String s : sameFrequency) {
list4.add(list3.get(i).getValue());
list5.add(s);
outputCount++;
}
sameFrequency.clear();
} else sameFrequency.add(list3.get(i).getKey());
}
map.put("x", list5);
map.put("y", list4);
return map;
}
2.mybatis的sql语句
使用mybatis定义执行的sql语句,并在dao内进行引用
分页查询,根据前端传入每页条数进行sql语句的访问
<select id="getPage" resultType="Academics">
select * from academics order by academicNum asc
limit ${(start-1)*size}, ${size};
</select>
按条件查询并分页,使用标识符绑定传递的参数,在通过sql语句进行查找,这段代码也是实现模糊查询功能的sql部分代码
<select id="queryByParamPage" resultType="Academics">
select * from academics
<where>
<if test="author!=null and author!=''">
author like concat('%',#{author},'%')
</if>
<if test="academicNum!=0">
and academicNum = #{academicNum}
</if>
<if test="title!=null and title!=''">
and title like concat('%',#{title},'%')
</if>
<if test="keyword!=null and keyword!=''">
and keyword like concat('%',#{keyword},'%')
</if>
</where>
order by academicNum asc
limit ${(page-1)*limit},${limit};
</select>
其余的查询语句也一同展示在下面
<select id="findAllArticleList" resultType="Academics">
select * from academics
</select>
<select id="findAllArticles" resultType="int">
select count(*) from academics
</select>
<select id="getPage" resultType="Academics">
select * from academics order by academicNum asc
limit ${(start-1)*size}, ${size};
</select>
<insert id="addAcademic" parameterType="Academics">
insert into academics(title, link, abstra, magazine, author, keyword, academicNum)
values (#{title}, #{link}, #{abstra}, #{magazine}, #{author}, #{keyword}, #{academicNum})
</insert>
<!--更新文章-->
<update id="updateAcademic" parameterType="Academics">
update academics
set title = #{title},
link = #{link},
abstra = #{abstra},
magazine = #{magazine},
author = #{author},
keyword = #{keyword}
where title = #{title}
</update>
<select id="findOneAcademic" parameterType="Academics" resultType="Academics">
select *
from academics
where title = #{title}
</select>
<delete id="delAcademic" parameterType="int">
delete
from academics
where academicNum = #{academicNum}
</delete>
<!--批量删除文章-->
<delete id="delAcademics" parameterType="int">
delete
from academics
where academicNum = #{academicNum}
</delete>
<!--按条件查询并分页-->
<select id="queryByParamPage" resultType="Academics">
select * from academics
<where>
<if test="author!=null and author!=''">
author like concat('%',#{author},'%')
</if>
<if test="academicNum!=0">
and academicNum = #{academicNum}
</if>
<if test="title!=null and title!=''">
and title like concat('%',#{title},'%')
</if>
<if test="keyword!=null and keyword!=''">
and keyword like concat('%',#{keyword},'%')
</if>
</where>
order by academicNum asc
limit ${(page-1)*limit},${limit};
</select>
<!--按条件查询-->
<select id="queryByParam" resultType="Academics">
select * from academics
<where>
<if test="author!=null and author!=''">
author like concat('%',#{author},'%')
</if>
<if test="academicNum!=0">
and academicNum = #{academicNum}
</if>
<if test="title!=null and title!=''">
and title like concat('%',#{title},'%')
</if>
<if test="keyword!=null and keyword!=''">
and keyword like concat('%',#{keyword},'%')
</if>
</where>
</select>
3.饼图的动态设置
通过绑定后端的dataTobin方法,获得前10关键词的排行数据,并进行动态初始化
设置backgroundColor, title, tooltip, serious属性
这些属性的设置分别体现在饼图的背景颜色,饼图的标题,饼图的每个部分的弹窗,以及动态的饼图占比,饼图类型为data_pie
异步加载的过程中还有其他的属性值得 大家学习
// 异步加载数据
$.get('/keywords/dataTobin', function (data) {
myChart3.setOption({
backgroundColor: '#e6ffff',
title: {
textStyle: {
color: 'rgba(0,0,0,0.8)'
},
text: '关键词百分比饼图1',
left: 'center'
},
tooltip: {
trigger: 'item',
formatter: '{a} <br/>{b} : {c} ({d}%)'
},
series: [
{
name: '数据',
type: 'pie', // 设置图表类型为饼图
radius: '55%', // 饼图的半径
data: data.data_pie,
emphasis: {
itemStyle: {
shadowBlur: 10,
shadowOffsetX: 0,
shadowColor: 'rgba(0,0,0,0.5)'
}
}
}
]
});
饼图的点击跳转事件
如果你想实现点击饼图的部分区域进行跳转,不妨试试这个代码
myChart3.on('click', function (param) {
window.open("demo1.html?keyname="+param.name+"")//该处为定义你想要打开的网页的url
//喜欢在本页面跳转的朋友可以试试, window.location.href = "admin.html?" + $("#username").val() + "";
})
9.心路历程与收获
221801327黄明亮:
本次的结对作业二让我受益匪浅。加强了自己在github上的使用,也在遇到bug的时候意识到了版本复原的重要性,(这次真是在上面栽了个大跟头),以后一定按时commit;这次结对作业自己主要是负责前端的部分,学习了使用layui的组件搭建了这样一个平台,不得不说,有一个组件库,确实方便自己的开发,不需要自己写太多的样式表,但我觉得如果自己写也能达到那样的组件样式,那也是很强的。合作过程中自己也曾参加过后端代码的开发,不过bug频出,好在队友力挽狂澜,在队友的帮助下,成功的完成了前后端的交互。通过这一次的结对过程,我认为自己在技术上还要继续学习,编码过程中要更加细心,希望下一次的实践还可以有更多的收获!!!
221801307蔡瑞金
结对作业二的开发过程可谓是一波三折。前期对github的使用,中期学习框架,编写程序,后期搭载服务器,虽然流程在一步一步走着,但在过程中遇到了许多问题。例如github pull request错误,需要回退;编写程序出现bug又不知道改了哪里,导致要回退过于多的版本进行重新编写,体验到了备份的重要性,同时要及时测试程序的稳定性和可靠性。后期搭载服务器算是比较顺风顺水的一次,但是在linux上安装mysql的时候把密码更新错误也重新设置了许久。当然,负责后端也不能只会后端,前端也需要看懂,这在编写文档时具有重大作用。
10.队友评价
To 221801307蔡瑞金
瑞金hxd在这次的结对过程中可谓是技术担当,学习能力一流,很快就能够学习并应用新学习的技术,这个学习能力真是让我非常佩服。在遇到bug的时候,他也不会慌乱,会更愿意投入时间去攻克难题,大胆尝试网上的方法,虽然过程非常煎熬,但可以看出他非常的努力。总之,想对这位hxd说,你是真滴强!
To 221801327黄明亮
明亮在这次结对过程中,能够努力学习新的技能,交代的任务也能努力完成。就是在实现新功能的时候还一直想着其他功能,导致原本能按部就班地完成却要拖到后面才能完成,这个在开发过程中需要改一下。其他时候,他都不失为一个好队友。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号