
golang服务器优化之旅
long time 没写博客了,最近在搞golang服务器优化,颇有心得
场景一:
定时器随着人数增多有延迟,延时蛮大,用法是在 time.AfterFunc之后往通道里面发送消息,
一直打印从开始发到,通道从缓冲区取出消息的时间差,发觉不对。
错误:打印方式不对,不应该在从缓冲区取出消息那一刻打印,因为通道里面当前消息处理如果比较耗时,是无法从缓冲区取出下一个的。
优化:多开几个协程处理,或者优化通道处理的那个函数。
场景二:
战斗结果通道kafka,然后再处理战报等相关操作,处理比较耗时,导致作为消费者的游戏服处理战斗结果
太慢了。
优化:每次有战斗返回,直接开一条新协程go去处理,处理完会自动销毁,不需要for循环保持。
场景三:
游戏里面大地图视野返回太慢了,基本要0.3~0.4s返回结果,人数多的时候要等待很久。
优化:因为之前一直是直接用redis作为大地图的缓存,所以有很多i/o损耗,再加上存储消息时的序列化和反序列化,消耗非常大。
所以后面改为大地图100w地块,分成100个map,直接操作map里面的地块数据,然后再用个独立协程去回写数据到redis持久化。
场景四:
数据库mysql的优化:exec的操作不需要玩家同步等待的都用协程异步操作(启动了10个专门写mysq的协程),所有操作都给个update来标记是否需要定时回写mysql
redis的优化:可以使用通道pipe批量读写。
如何定位问题?
先用pprof,分析运行时的cpu和memory:
import ( "net/http" _ "net/http/pprof" ) func main() { go func() { http.ListenAndServe("localhost:8080", nil) }() }
通过网页查看overview:
http://localhost:8080/debug/pprof/
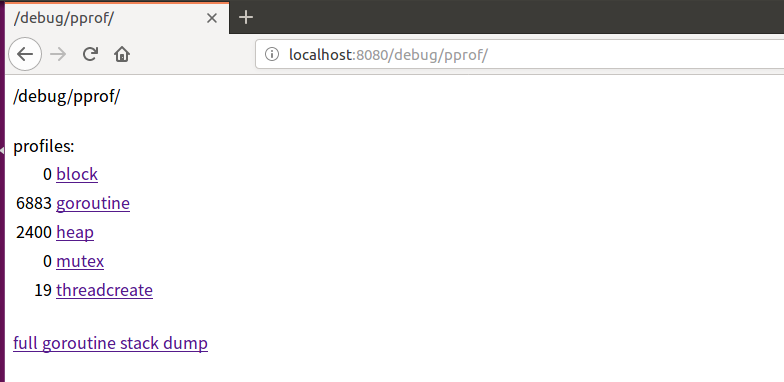
也可以通过命令行查看信息:
查看cpu运行情况:
go tool pprof --seconds 30 http://localhost:8080/debug/pprof/profile
查看总分配内存/正在运行内存:
go tool pprof -alloc_space/-inuse_space http://localhost:8080/debug/pprof/heap
进入后,可以使用命令
help
top
top 50
list 某个函数
分析完pprof后,可以猜想大概哪里消耗比较大,然后可以自己写benchmark进行基准测试:
import ( "sync" "testing" ) var mutex = sync.Mutex{} func BenchmarkTest1(b *testing.B) { b.ResetTimer() for n := 0; n < b.N; n++ { mutex.Lock() mutex.Unlock() } }
//go test world_test.go -bench=.
//go test world_test.go -bench=. -benchmem -run=none
goos: linux goarch: amd64 pkg: benchmark BenchmarkScriptf-2 10000000 106 ns/op 16 B/op 2 allocs/op BenchmarkFormat-2 500000000 3.79 ns/op 0 B/op 0 allocs/op BenchmarkItoa-2 300000000 5.49 ns/op 0 B/op 0 allocs/op BenchmarkUseMutex-2 100000000 17.4 ns/op 0 B/op 0 allocs/op BenchmarkUseChan-2 30000000 57.0 ns/op 0 B/op 0 allocs/op PASS ok benchmark 9.262s 106 ns/op 表示每次调用花费106纳秒 16 B/op 函数每次调用需要分配16字节的内存 2 allocs/op 函数每次调用需要进行1次内存分配
何谓基准测试:就是指至少执行多少次,以后每次执行这个函数时间都是一样的,稳定值!
当运行时间达到稳态时,benchmark才会终止,算出每一次跑的平均时间
最后还可以查看gc的情况:
GODEBUG=gctrace=1 go run main.go
gc 1 @0.038s 1%: 0.55+0.12+0.081 ms clock, 2.2+0/0.42/1.1+0.32 ms cpu, 4->4->0 MB, 5 MB goal, 4 P。 1 表示第一次执行 @0.038s 表示程序执行的总时间 1% 垃圾回收时间占用总的运行时间百分比 0.018+1.3+0.076 ms clock 垃圾回收的时间,分别为STW(stop-the-world)清扫的时间, 并发标记和扫描的时间,STW标记的时间 0.054+0.35/1.0/3.0+0.23 ms cpu 垃圾回收占用cpu时间 4->4->3 MB 堆的大小,gc后堆的大小,存活堆的大小 5 MB goal 整体堆的大小 4 P 使用的处理器数量 尝试把这个比例调大 export GOGC=400,试图降低 gc 触发频率
最后还有一个小技巧,很方便快捷检查静态代码的bug:
go tool vet .
如何查找服务器崩溃宕机:
首先我们服务器在每个有for循环的协程里面都会有recover去恢复现场,并且打印堆栈,所以说一般的错误例如有返回err或者空引用等,都
不会导致服务器崩溃,因为这个相当于try-catch了,是不会crash的,当然有些人是反对这种防御性编程的,just let it crash。但是在线上环境
你就会觉得很痛苦了,如果没有recover,策划一个小小的配置错误就能让你服务器宕机!
言归正传,我们服务器宕机了,但是因为无法recover,所以单纯通过普通的日志是查不出来的。
因为我在启动服务器的时候,都忽略了nohup的输出,因为这个文件实在太大了,所以导致致命的错误无法打印
nohup ./main > /dev/null &
改为:
nohup ./main > /dev/null 2> /tmp/error.log&
将错误日志输出到error.log
发现是map的原因引起的:
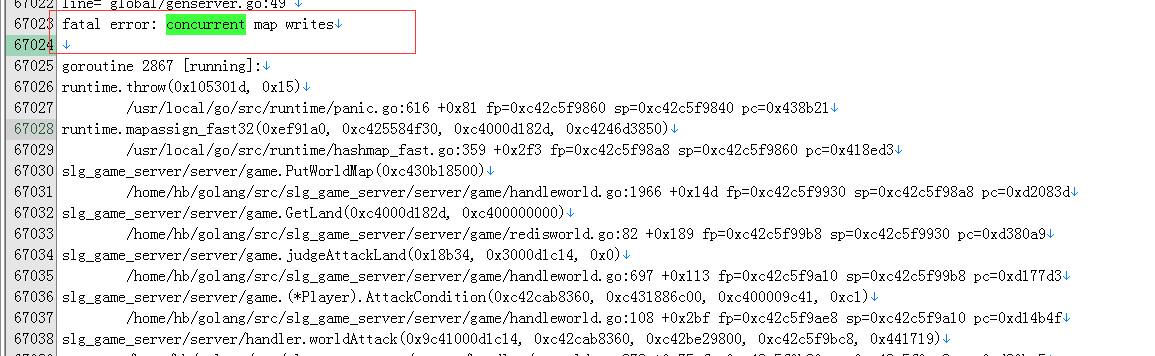
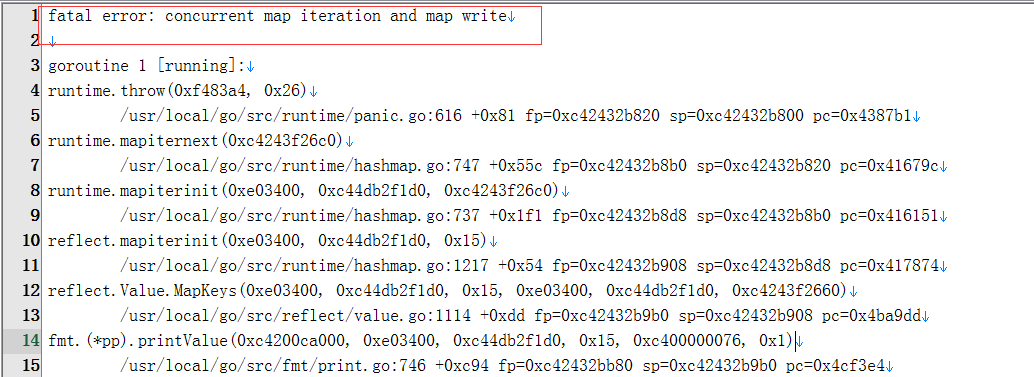
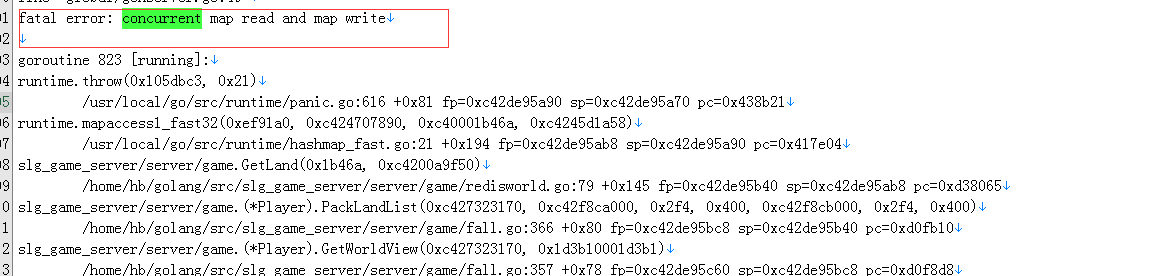
并发读写,并发写,迭代都报错了,而且可以看到最终是调用了panic,这函数是必定崩的!
