
自动机合集(4202.8.15 coming soon)
备注:我不知道 fail 会不会和什么东西重名。(因为感觉这个单词挺完整的)
自动机的概念
不是很清楚自动机的概念。暂且认为:
自动机是一个有向图。点(状态)代表字符串(可能不止一个),边(转移)(可能)带一个字符,表示在字符串的末尾加上这个字符后到达的状态。有一个源点(PAM 有两个),代表初始状态。有若干个结束状态。从初始状态到结束状态的路径形成的字符串被自动机接受。
KMPAM、ACAM、PAM、SAM 都有一棵辅助的树,和自动机的图一起构建。这棵树和自动机的图共用结点,但辅助树的边和自动机的边没有任何关系。
虽然我把它称为“辅助树”,但它可能很有用。有时需要在这棵树上解决问题。
- DFA(确定性有限状态自动机):每条转移边都有字符,如“压缩路径”后的 ACAM。
- NFA(非确定性有限状态自动机):有转移边没有字符,如没有“压缩路径”的 ACAM,fail 边就没有字符。
下面的内容如果没有特殊说明,自动机都是指 DFA。
Trie(DFA)
Trie 居然也算自动机!
P8306 【模板】字典树
#include <bits/stdc++.h> #define eb emplace_back using namespace std; //const int S = 3e6; inline int Num(char c) // inline ? { if(c >= '0' && c <= '9') return c - '0'; else if(c >= 'a' && c <= 'z') return 10 + c - 'a'; else /*if(c >= 'A' && c <= 'Z')*/ return 36 + c - 'A'; } struct Trie{ int tot; vector < vector < int > > ch; vector < int > sum; int Create() { ++ tot; vector < int > tmp(62); // 初始化为 0 了? ch.eb(tmp); sum.eb(0); return tot; } void Init() { tot = - 1; ch.clear(); // ? sum.clear(); // 多测要清空!!! Create(); Create(); } void Insert(string s, int n) { int u = 1; sum[u] ++; for(int i = 1; i <= n; i ++){ int t = Num(s[i]); if(! ch[u][t]){ int v = Create(); ch[u][t] = v; } u = ch[u][t]; sum[u] ++; } } int Query(string s, int n) { int u = 1; for(int i = 1; i <= n; i ++){ int t = Num(s[i]); if(! ch[u][t]) return 0; u = ch[u][t]; } return sum[u]; } }tr; void Solve() { tr.Init(); int n, q; scanf("%d%d", & n, & q); string s; for(int i = 1; i <= n; i ++){ cin >> s; // ??? int l = ((int)s.size()); s = " " + s; tr.Insert(s, l); } for(int i = 1; i <= q; i ++){ cin >> s; // ??? int l = ((int)s.size()); s = " " + s; printf("%d\n", tr.Query(s, l)); } } int main() { int t; scanf("%d", & t); while(t --) Solve(); return 0; }
KMP 自动机(DFA)
解决单模式串匹配的问题。
拿模式串来建,拿文本串来走。
就是把 KMP 中跳 fail 的结果预处理出来。(路径压缩)
ch[i][c](当前站在第
-
s[i + 1] == c,那么 ch[i][c] = i + 1
-
s[i + 1] != c,那么 ch[i][c] = ch[fail[i]][c] (?)(因为当
可能要注意 i == 0 的时候要特殊处理?
AC 自动机(NFA)(没有压缩路径)
我的评价是可以直接写压缩了路径的版本。()
解决多模式串匹配的问题。
拿模式串来建,拿文本串来走。
在 Trie 上把 fail 处理出来。KMP 的 fail 只能跳到自己这个字符串的前缀,而 Trie 上的 fail 可以跳到 Trie 上每个前缀。
可能要注意 根节点及其子结点 要特殊处理?
AC 自动机(DFA)(压缩了路径)
解决多模式串匹配的问题。
拿模式串来建,拿文本串来走。
就是把 KMP 自动机拿到 Trie 上。离线插入模式串后 bfs 构建,因为要用 Trie 上短的前缀更新长的前缀(深度浅的更新深的)。
注意 根节点及其子结点 要特殊处理。因为根结点的 fail 还是根结点,没法满足根的 fail 跳到的前缀长度小于根代表的前缀的长度。
fail 树上的东西常有两种做法:
- 拓扑排序(对 fail 树,这种做法中 fail 树是内向树) + DP。[拓扑序就是 bfs 序反过来。(因为除了根结点,当前的 fail 跳到的前缀的长度小于当前前缀的长度)](?)(这样不用真正建出 fail 树)
- 建 fail 树,树形 DP。
P5357 【模板】AC 自动机
#include <bits/stdc++.h> using namespace std; namespace IO { int read() { int f = 1, x = 0; char c = getchar(); while(c < '0' || c > '9'){ if(c == '-') f = - 1; c = getchar(); } while(c >= '0' && c <= '9'){ x = x * 10 + c - '0'; c = getchar(); } return f * x; } void write(int x) { if(x < 0){ putchar('-'); x = - x; } if(x > 9) write(x / 10); putchar(x % 10 + '0'); } } using namespace IO; // Fast IO sometimes -> Slow IO struct AC{ vector < vector < int > > ch; // 一个结点的 ch 可以是它自己,但是它的 nxt 不能(除了根结点(0)) vector < vector < int > > num; vector < int > nxt; vector < vector < int > > g; vector < int > sum; int ed; void Init(int n) { ch.clear(); // vector 的 resize() 不会把原有且不会被删掉的位置的值改为 0,所以要先 clear() ch.resize(n + 1); // resize() 会把新加入的位置的值赋值为 0 for(int i = 0; i <= n; i ++) ch[i].resize(26); num.clear(); // num.resize(n + 1); nxt.clear(); // nxt.resize(n + 1); g.clear(); // g.resize(n + 1); sum.clear(); // sum.resize(n + 1); ed = 0; } void Insert(string s, int Num) { int u = 0; for(char c : s){ if(! ch[u][c - 'a']) ch[u][c - 'a'] = ++ ed; // u = ch[u][c - 'a']; // } num[u].emplace_back(Num); // } void Build() { queue < pair < int, pair < int, int > > > q; q.push(make_pair(0, make_pair(0, 0))); while(! q.empty()){ int u = q.front().first, fa = q.front().second.first, i = q.front().second.second; q.pop(); for(int j = 0; j < 26; j ++) if(ch[u][j]) q.push(make_pair(ch[u][j], make_pair(u, j))); if(u == 0) continue; if(fa == 0) nxt[u] = 0; else nxt[u] = ch[nxt[fa]][i]; for(int j = 0; j < 26; j ++) if(! ch[u][j]) ch[u][j] = ch[nxt[u]][j]; g[nxt[u]].emplace_back(u); // } } void DFS(int u) { for(int v : g[u]){ DFS(v); sum[u] += sum[v]; } } vector < int > Query(string s, int n) { int u = 0; for(char c : s){ u = ch[u][c - 'a']; ++ sum[u]; } DFS(0); vector < int > res(n + 1); for(int i = 1; i <= ed; i ++) for(int j : num[i]) res[j] = sum[i]; return res; } }ac; void solve() { ac.Init((int)2e5); int n = read(); vector < string > s(n + 1); for(int i = 1; i <= n; i ++){ cin >> s[i]; ac.Insert(s[i], i); } ac.Build(); string t; cin >> t; auto res = ac.Query(t, n); for(int i = 1; i <= n; i ++) { write(res[i]); puts(""); } } signed main() { solve(); return 0; }
KMPAM、ACAM 小结
都可以解决字符串匹配问题。
都是拿模式串来建,拿文本串来跑。
可以简单地作为一种 建图 / 建树 的方式,将字符串问题转换为 相比原问题较为直白的 图论 / 树上 问题。转到树上后可能常用 DS 这类的技巧。
TQX 巨佬说 AC 自动机的一个状态是一条链(fail 树上从当前结点到根的链),[理解了这个可能就能做很多 AC 自动机的题了](?)。我的理解是 当前结点到根的链上每个点表示的前缀都是当前匹配上的。
回文自动机(DFA)
[解决一个串的回文子串相关的问题。](?)
回文自动机 比较特殊,它不能非常方便地定义为自动机。
如果需要定义的话,它接受且仅接受某个字符串的所有回文子串的 中心及右半部分。
「中心及右边部分」在奇回文串中就是字面意思,在偶回文串中定义为一个特殊字符加上右边部分。这个定义看起来很奇怪,但它能让 PAM 真正成为一个自动机,而不仅是两棵树。
——from oi-wiki
回文树又称回文自动机。
PAM 有两棵[树](?)(可以类比前面的自动机的图),每一圈年轮都是江南的太阳(不是我为什么突然想起这句)。一棵有奇根,处理奇回文;一棵有偶根,处理偶回文。每个点表示一个回文子串,每条边表示在出发点的串前后各加上一个边上的字符。
另有一棵 fail 树。fail 边连向当前回文子串的最长回文真后缀。容易发现根据回文串的对称性,最长回文真后缀是(属于)border,于是就可以类比 KMP 等,通过跳若干次 fail 来得到当前回文子串的所有回文真后缀。
现在证明一个结论,每次在字符串末尾增加一个字符最多只会增加一个本质不同的回文子串:
[把新字符串的回文后缀全部拎出来。找到最长的那个,那么其他的都可以通过最长的那个对称到原字符串里去。](?)
所以最多新增加一个最长的那个回文后缀。
有了这个结论,我们就知道了在字符串末尾加字符最多只会给 PAM 增加一个结点。
于是类比 KMP 构建即可。第一轮跳 fail 是为了找到新的回文子串(即新字符串的最长回文后缀)。第二轮跳 fail 是为了找新点的 fail([即新字符串的次长回文后缀](?))。
注意初始值。奇根 len = - 1(这样就可以转移到只有一个字符的奇回文串),偶根 len = 0。奇根和偶根的 fail 都连向奇根(因为奇根的串更基础)。
注意加结点的时候如果能转移到新点的只有奇根,要把新点的 fail 连向偶根,[这样能给以后的结点更多可能性(发挥空间)(让后面的可以从偶根扩展)](?)。
(注意)建议用函数封装新开一个点的过程,防止最后更新 lst 的时候 p(之前的 lst 跳若干次 fail(可以为
时间复杂度分析[类比 KMP](?),似乎是 [
翁文涛论文《回文树及其应用》中的示例图(据 tqx)(from tqx 的博客):
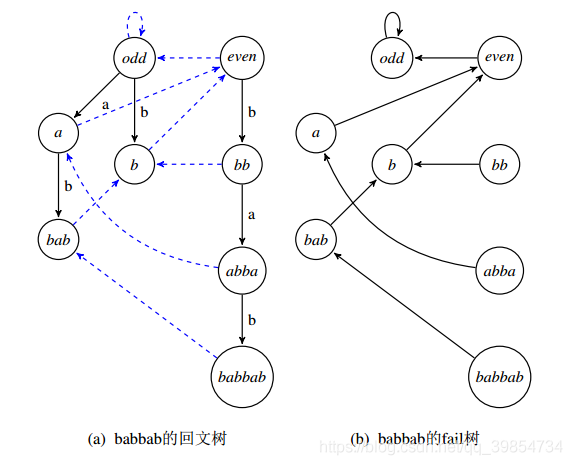
有的题需要增加 PAM 内部的东西。如:P4287 [SHOI2011] 双倍回文。
[由于回文的优秀性质(对称性)](?),可以让 PAM 支持前后都可以添加字符。见:loj#141 回文子串。
对我学 PAM 有巨大帮助的 tqx 的博客。
P5496 【模板】回文自动机(PAM)
#include <bits/stdc++.h> using namespace std; const int N = 5e5; int n; string s; struct PAM{ // even: 0 odd: 1 int tot, lst; int ch[N + 2][26], fal[N + 2], len[N + 2], dep[N + 2]; // 注意空间开多少 void Init() { for(int i = 0; i <= n + 1; i ++){ // 注意范围 for(int j = 0; j < 26; j ++) ch[i][j] = 0; fal[i] = 0; len[i] = 0; dep[i] = 0; } fal[0] = 1; fal[1] = 1; // fal[1] 是 1 而不是 0 len[0] = 0; len[1] = - 1; tot = 1; // 勿忘 lst = 0; // 勿忘 } void Create(int nw, int p, int c) { ch[p][c] = ++ tot; len[tot] = len[p] + 2; if(p == 1) fal[tot] = 0; // 注意不要忘了这种情况! else{ p = fal[p]; while(s[nw - 1 - len[p]] != s[nw]) p = fal[p]; fal[tot] = ch[p][c]; // 是 ch[p][c] 而不是 p } dep[tot] = dep[fal[tot]] + 1; // 是 fal[tot] 而不是 p } void Insert(int nw) { int c = s[nw] - 'a'; int p = lst; while(s[nw - 1 - len[p]] != s[nw]) p = fal[p]; if(! ch[p][c]) Create(nw, p, c); // 必须要用函数封装,不然下一行中可能 p 会变(可能不是原来的 p 了)!!! lst = ch[p][c]; } inline int Query() { return dep[lst]; } }pam; int main() { cin >> s; n = ((int)s.size()); s = " " + s; pam.Init(); // 勿忘 // 这句要放在 n = ... 之后 int lstans = 0; for(int i = 1; i <= n; i ++){ if(i >= 2) s[i] = ((char)((((int)s[i]) - 97 + lstans) % 26 + 97)); pam.Insert(i); lstans = pam.Query(); printf("%d ", lstans); } return 0; }
子序列自动机(DFA?)
oi-wiki 上称之为“序列自动机”。
发扬条条优良传统 咕咕咕。
后缀自动机
咕咕咕。
P3804 【模板】后缀自动机(SAM)
#include <bits/stdc++.h> #define ll long long using namespace std; const int N = 1e6; int n; string s; struct SAM{ // 源点是 1,在这种写法里不能是 0,不然不会在跳 nxt 时考虑 0 的 ch int tot, lst; int nxt[2 * N], ch[2 * N][26], len[2 * N], sum[2 * N], ind[2 * N]; // 开 2 * N 够吗? void Init() // 里面的对吗? { tot = lst = 1; nxt[1] = 0; // len[1] = 0; // ? for(int i = 0; i < 2 * n; i ++) // 范围对吗? for(int j = 0; j < 26; j ++) ch[i][j] = 0; } void Insert(int c) { int p = lst, np = ++ tot; lst = np; // ? len[np] = len[p] + 1; sum[np] = 1; // while(p && ! ch[p][c]){ ch[p][c] = np; p = nxt[p]; } if(! p) nxt[np] = 1; else{ int q = ch[p][c]; if(len[q] == len[p] + 1) nxt[np] = q; else{ // 不用判断? int nq = ++ tot; nxt[nq] = nxt[q]; len[nq] = len[p] + 1; for(int i = 0; i < 26; i ++) ch[nq][i] = ch[q][i]; // ? // 这句会不会增大时间复杂度啊? nxt[q] = nq; nxt[np] = nq; // while(q && ch[q][c] == q) while(p && ch[p][c] == q){ ch[p][c] = nq; p = nxt[p]; } } } } ll TPDP() { ll ans = 0; queue < int > q; for(int i = 1; i <= tot; i ++) ind[i] = 0; for(int i = 2; i <= tot; i ++) ind[nxt[i]] ++; for(int i = 1; i <= tot; i ++) if(! ind[i]) q.push(i); while(! q.empty()){ int u = q.front(); q.pop(); if(nxt[u] > 1) sum[nxt[u]] += sum[u]; if(sum[u] > 1) ans = max(ans, 1ll * sum[u] * len[u]); ind[nxt[u]] --; if(! ind[nxt[u]]) q.push(nxt[u]); } return ans; } }sam; int main() { cin >> s; n = ((int)s.size()); sam.Init(); for(char c : s) sam.Insert(c - 'a'); printf("%lld", sam.TPDP()); return 0; } // 要开 long long
广义后缀自动机
咕咕咕。
SAM 系列和 KMP、AC 系列的对比
咕咕咕。
2024.8.15

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步