
Java并发编程笔记之LongAdder和LongAccumulator源码探究
一.LongAdder原理
LongAdder类是JDK1.8新增的一个原子性操作类。AtomicLong通过CAS算法提供了非阻塞的原子性操作,相比受用阻塞算法的同步器来说性能已经很好了,但是JDK开发组并不满足于此,因为非常搞并发的请求下AtomicLong的性能是不能让人接受的。
如下AtomicLong 的incrementAndGet的代码,虽然AtomicLong使用CAS算法,但是CAS失败后还是通过无限循环的自旋锁不多的尝试,这就是高并发下CAS性能低下的原因所在。源码如下:
public final long incrementAndGet() { for (;;) { long current = get(); long next = current + 1; if (compareAndSet(current, next)) return next; } }
在高并发下N多线程同时去操作一个变量会造成大量线程CAS失败,然后处于自旋状态,这样导致大大浪费CPU资源,降低了并发性。
既然AtomicLong性能问题是由于过多线程同时去竞争同一个变量的更新而降低的,那么如果把一个变量分解为多个变量,让同样多的线程去竞争多个资源,那么性能问题不久迎刃而解了吗?
没错,因此,JDK8 提供的LongAdder就是这个思路。下面通过图形来标示两者的不同,如下图:
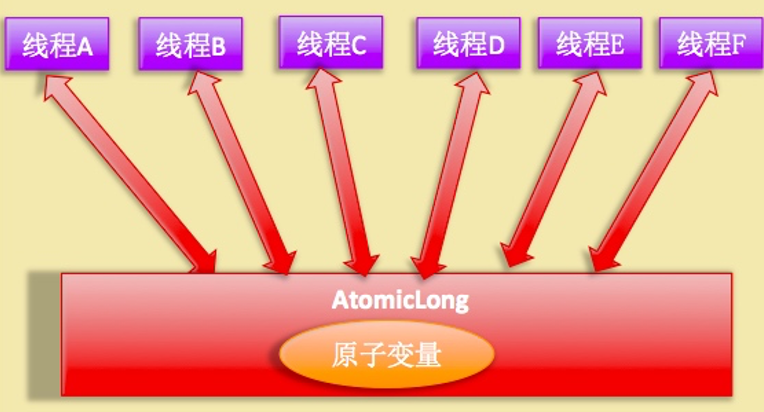
如上图 AtomicLong 是多个线程同时竞争同一个变量情景。
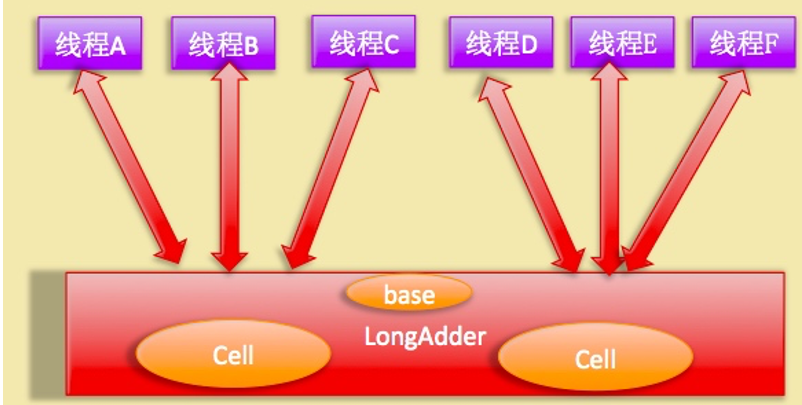
如上图所示,LongAdder则是内部维护多个Cell变量,每个Cell里面有一个初始值为0的long型变量,在同等并发量的情况下,争夺单个变量的线程会减少,这是变相的减少了争夺共享资源的并发量,另外多个线程在争夺同一个原子变量时候,
如果失败并不是自旋CAS重试,而是尝试获取其他原子变量的锁,最后当获取当前值时候是把所有变量的值累加后再加上base的值返回的。
LongAdder维护了要给延迟初始化的原子性更新数组和一个基值变量base数组的大小保持是2的N次方大小,数组表的下标使用每个线程的hashcode值的掩码表示,数组里面的变量实体是Cell类型。
Cell 类型是Atomic的一个改进,用来减少缓存的争用,对于大多数原子操作字节填充是浪费的,因为原子操作都是无规律的分散在内存中进行的,多个原子性操作彼此之间是没有接触的,但是原子性数组元素彼此相邻存放将能经常共享缓存行,也就是伪共享。所以这在性能上是一个提升。
另外由于Cells占用内存是相对比较大的,所以一开始并不创建,而是在需要时候再创建,也就是惰性加载,当一开始没有空间时候,所有的更新都是操作base变量。
接下来进行LongAdder代码简单分析
这里我只是简单的介绍一下代码的实现,详细实现,大家可以翻看代码去研究。为了降低高并发下多线程对一个变量CAS争夺失败后大量线程会自旋而造成降低并发性能问题,LongAdder内部通过根据并发请求量来维护多个Cell元素(一个动态的Cell数组)来分担对单个变量进行争夺资源。
首先我们先看LongAdder的构造类图,如下图:
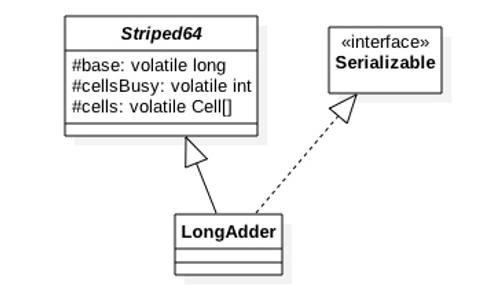
可以看到LongAdder继承自Striped64类,Striped64内部维护着三个变量,LongAdder的真实值其实就是base的值与Cell数组里面所有Cell元素值的累加,base是个基础值,默认是0,cellBusy用来实现自旋锁,当创建Cell元素或者扩容Cell数组时候用来进行线程间的同步。
接下来进去源码如看Cell的构造,源码如下:

@sun.misc.Contended static final class Cell { volatile long value; Cell(long x) { value = x; } final boolean cas(long cmp, long val) { return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val); } // Unsafe 技术 private static final sun.misc.Unsafe UNSAFE; private static final long valueOffset; static { try { UNSAFE = sun.misc.Unsafe.getUnsafe(); Class<?> ak = Cell.class; valueOffset = UNSAFE.objectFieldOffset (ak.getDeclaredField("value")); } catch (Exception e) { throw new Error(e); } } }
正如上面的代码可以知道Cell的构造很简单,内部维护一个声明volatile的变量,这里声明为volatile是因为线程操作value变量时候没有使用锁,为了保证变量的内存可见性这里只有声明为volatile。另外这里就是先前文件所说的使用Unsafe类的方法来设置value的值
接下来进入LongAdder的源码里面去看几个重要的方法,如下:
1.long sum() 方法:返回当前的值,内部操作是累加所有 Cell 内部的 value 的值后累加 base,如下代码,由于计算总和时候没有对 Cell 数组进行加锁,所以在累加过程中可能有其它线程对 Cell 中的值进行了修改,也有可能数组进行了扩容,所以 sum 返回的值并不是非常精确的,
返回值并不是一个调用 sum 方法时候的一个原子快照值。
源码如下:
public long sum() { Cell[] as = cells; Cell a; long sum = base; if (as != null) { for (int i = 0; i < as.length; ++i) { if ((a = as[i]) != null) sum += a.value; } } return sum; }
2.void reset() 方法:重置操作,如下代码把 base 置为 0,如果 Cell 数组有元素,则元素值重置为 0。源码如下:
public void reset() { Cell[] as = cells; Cell a; base = 0L; if (as != null) { for (int i = 0; i < as.length; ++i) { if ((a = as[i]) != null) a.value = 0L; } } }
3.long sumThenReset() 方法:是sum 的改造版本,如下代码,在计算 sum 累加对应的 cell 值后,把当前 cell 的值重置为 0,base 重置为 0。 当多线程调用该方法时候会有问题,比如考虑第一个调用线程会清空 Cell 的值,后一个线程调用时候累加时候累加的都是 0 值。
源码如下:
public long sumThenReset() { Cell[] as = cells; Cell a; long sum = base; base = 0L; if (as != null) { for (int i = 0; i < as.length; ++i) { if ((a = as[i]) != null) { sum += a.value; a.value = 0L; } } } return sum; }
4.long longValue() 等价于 sum(),源码如下:
public long longValue() { return this.sum(); }
5.void add(long x) 累加增量 x 到原子变量,这个过程是原子性的。源码如下:
public void add(long x) { Cell[] as; long b, v; int m; Cell a; if ((as = cells) != null || !casBase(b = base, b + x)) {//(1) boolean uncontended = true; if (as == null || (m = as.length - 1) < 0 ||//(2) (a = as[getProbe() & m]) == null ||//(3) !(uncontended = a.cas(v = a.value, v + x)))//(4) longAccumulate(x, null, uncontended);//(5) } } final boolean casBase(long cmp, long val) { return UNSAFE.compareAndSwapLong(this, BASE, cmp, val); }
可以看到上面代码,当第一个线程A执行add时候,代码(1)会执行casBase方法,通过CAS设置base为 X, 如果成功则直接返回,这时候base的值为1。
假如多个线程同时执行add时候,同时执行到casBase则只有一个线程A成功返回,其他线程由于CAS失败执行代码(2),代码(2)是获取cells数组的长度,如果数组长度为0,则执行代码(5),否则cells长度不为0,说明cells数组有元素则执行代码(3),
代码(3)首先计算当前线程在数组中下标,然后获取当前线程对应的cell值,如果获取到则执行(4)进行CAS操作,CAS失败则执行代码(5)。
代码(5)里面是具体进行数组扩充和初始化,这个代码比较复杂,这里就不讲解了,有兴趣的可以进去看看。
二.LongAccumulator类源码分析
LongAdder类是LongAccumulator的一个特例,LongAccumulator提供了比LongAdder更强大的功能,如下构造函数,其中accumulatorFunction是一个双目运算器接口,根据输入的两个参数返回一个计算值,identity则是LongAccumulator累加器的初始值。
public LongAccumulator(LongBinaryOperator accumulatorFunction,long identity) { this.function = accumulatorFunction; base = this.identity = identity; } public interface LongBinaryOperator { //根据两个参数计算返回一个值 long applyAsLong(long left, long right); }
上面提到LongAdder 其实就是LongAccumulator 的一个特例,调用LongAdder 相当使用下面的方式调用 LongAccumulator。
LongAdder adder = new LongAdder(); LongAccumulator accumulator = new LongAccumulator(new LongBinaryOperator() { @Override public long applyAsLong(long left, long right) { return left + right; } }, 0);
LongAccumulator相比LongAdder 可以提供累加器初始非0值,后者只能默认为0,另外前者还可以指定累加规则,比如不是累加而相乘,只需要构造LongAccumulator 时候传入自定义双目运算器即可,后者则内置累加规则。
从下面代码知道LongAccumulator相比于LongAdde的不同在于casBase的时候,后者传递的是b+x,而前者则是调用了r=function.applyAsLong(b=base.x)来计算。
LongAdder类的add源码如下:
public void add(long x) { Cell[] as; long b, v; int m; Cell a; if ((as = cells) != null || !casBase(b = base, b + x)) { boolean uncontended = true; if (as == null || (m = as.length - 1) < 0 || (a = as[getProbe() & m]) == null || !(uncontended = a.cas(v = a.value, v + x))) longAccumulate(x, null, uncontended); } }
LongAccumulator的accumulate方法的源码如下:
public void accumulate(long x) { Cell[] as; long b, v, r; int m; Cell a; if ((as = cells) != null || (r = function.applyAsLong(b = base, x)) != b && !casBase(b, r)) { boolean uncontended = true; if (as == null || (m = as.length - 1) < 0 || (a = as[getProbe() & m]) == null || !(uncontended = (r = function.applyAsLong(v = a.value, x)) == v || a.cas(v, r))) longAccumulate(x, function, uncontended); } }
另外LongAccumulator调用longAccumulate时候传递的是function,而LongAdder是null,从下面代码可以知道当fn为null,时候就是使用v+x 加法运算,这时候就等价于LongAdder,fn不为null的时候则使用传递的fn函数计算,如果fn为加法则等价于LongAdder;
else if (casBase(v = base, ((fn == null) ? v + x :fn.applyAsLong(v, x)))) // Fall back on using base
break;

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步