爬虫综合大作业
2019-04-24 19:56 科ke 阅读(541) 评论(0) 编辑 收藏 举报import requests import time import json headers = { 'charset': "utf-8", 'Accept-Encoding': "gzip", 'referer': "https://servicewechat.com/wx90ae92bbd13ec629/11/page-frame.html", 'content-type': "application/x-www-form-urlencoded", 'User-Agent': "Mozilla/5.0 (Linux; Android 9; Redmi Note 7 Build/PKQ1.180904.001; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/68.0.3440.91 Mobile Safari/537.36 MicroMessenger/7.0.3.1400(0x2700033B) Process/appbrand0 NetType/WIFI Language/zh_CN", 'Host': "www.enlightent.cn", 'Connection': "keep-alive", 'cache-control': "no-cache", } #获取每一天的日期!!!!!! def get_date(): date_list = [] year_list = [2019,2018,2017] month_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12] fun = lambda year, month: list(range(1, 1+time.localtime(time.mktime((year,month+1,1,0,0,0,0,0,0)) - 86400).tm_mday)) for year in year_list: for month in month_list: day_list = fun(year, month) for day in day_list: save_res = str(year)+'%2f'+str(month)+'%2f'+str(day) date_list.append(save_res) return date_list def start(): with open('微博热搜.csv', 'w', encoding='gbk') as f: f.write('日期,排名,时间名称,搜索量,当时最高排名\n') date_list = get_date() url = "https://www.enlightent.cn/research/top/getWeiboHotSearchDayAggs.do" for date in date_list: payload = "date={date}&type=realTimeHotSearchList" data = payload.format(date=date) response = requests.request("POST", url, data=data, headers=headers,verify=False) print(response.text) json_obj = json.loads(response.text) num = 1 for item in json_obj: save_date = date.replace('%2f','-') save_num = str(num) num+=1 name = item['keyword'].replace(',',',') searchCount = str(item['searchCount']) rank = str(item['rank']) save_res = save_date+','+save_num+','+name+','+searchCount+','+rank+'\n' print(save_res) with open('微博热搜.csv','a',encoding='gbk',errors='ignore') as f: f.write(save_res) if __name__ == '__main__': start()
共抓取了16万数据
对这16万数据进行数据分析如下
爬取了2017-2019微博热搜16万数据进行分析
一、搜索量最高的是?
选取“搜索量”列进行降序排序,并选取排名前十的数据建立数据透视表
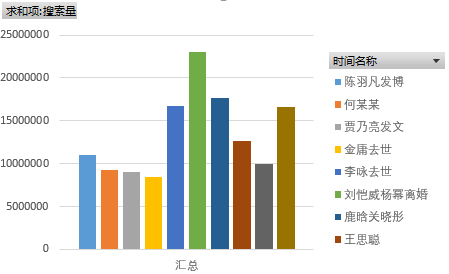
从表中可以看出搜索量最高的是“刘恺威杨幂离婚”唯一一个搜索量突破2000万,其次是“鹿晗关晓彤”“李咏去世” “赵丽颖冯绍峰结婚”,有趣的是:微博热搜量排名前十的竟然有九个是明星事件,而且排名前五的事件竟有三条是明星恋情。据此,我们可以发现,微博用户最为关注的事件是“明星恋情”。
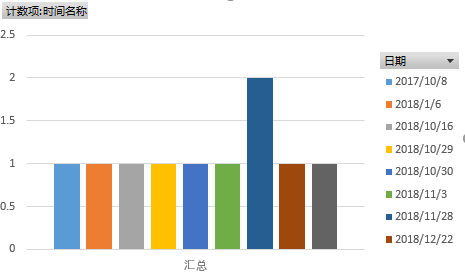
意外的是,排名前十的事件竟有九条是2018年的,仅有一条是2017年的。
二、微博热搜搜索量和排名有怎样的关系?是否仅根据微博搜索量来决定排名?
从排名来看,十条记录中一条是排名第二,据此可以说明搜索量和排名呈正相关关系,但排名并非是完全由搜索量决定,或许还有其他因素。