复合数据类型,英文词频统计
2019-03-11 22:54 科ke 阅读(244) 评论(1) 编辑 收藏 举报复合数据类型
1.列表,元组,字典,集合分别如何增删改查及遍历。
一、列表操作
list.insert(index, obj) 增加元素到指定位置 list.pop(index) 删除指定位置的元素,index是索引
list[index]=obj 修改指定位置的元素 list[index] 通过下标索引,从0开始
二、元组操作
tup=tup1+tup2 元组不支持修改,但可以通过连接组合的方式进行增加
del tup 元组不支持单个元素删除,但可以删除整个元组
tup=tup[index1:index2] 元组是不可变类型,不能修改元组的元素。可通过现有的字符串拼接构造一个新元组
tup[index] 通过下标索引,从0开始
三、字典操作
dict[key]=value 通过赋值的方法增加元素
dict.update(dict_i) 把新的字典dict_i的键/值对更新到dict里(适用dict_i中包含与dict不同的key)
del dict[key] 删除单一元素,通过key来指定删除
dict[key]=value 通过对已有的key重新赋值的方法修改
2.总结列表,元组,字典,集合的联系与区别。参考以下几个方面:
括号
有序无序
可变不可变
重复不可重复
存储与查找方式
一、列表
list是处理一组有序项目的数据结构,即你可以在一个列表中存储一个序列的项目。列表中的项目。列表中的项目应该包括在方括号中,这样python就知道你是在指明一个列表。一旦你创建了一个列表,你就可以添加,删除,或者是搜索列表中的项目。由于你可以增加或删除项目,我们说列表是可变的数据类型,即这种类型是可以被改变的,并且列表是可以嵌套的。
二、元组
元组和列表十分相似,不过元组是不可变的。即你不能修改元组。元组通过圆括号中用逗号分隔的项目定义。元组通常用在使语句或用户定义的函数能够安全的采用一组值的时候,即被使用的元组的值不会改变。元组可以嵌套。
三、字典
可读可写可重复,无序,键值对不能重复
四、集合
与字典类似,但只包含键,而没有对应的值,包含的数据不重复。
3.词频统计
- 1.下载一长篇小说,存成utf-8编码的文本文件 file
2.通过文件读取字符串 str
3.对文本进行预处理
4.分解提取单词 list
5.单词计数字典 set , dict
6.按词频排序 list.sort(key=lambda),turple
7.排除语法型词汇,代词、冠词、连词等无语义词
- 自定义停用词表
- 或用stops.txt
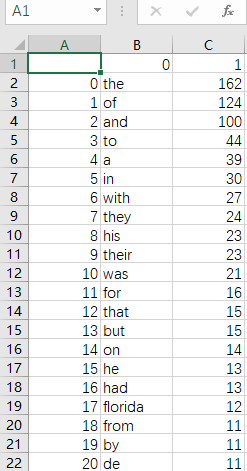
8.输出TOP(20)
- 9.可视化:词云
排序好的单词列表word保存成csv文件



# 1.准备gbk编码的文本文件 2.通过文件读取字符串 str
file = open('fiction.txt', 'r', encoding='utf-8')
str = file.read().lower()
file.close()
print(str)
# 对文本进行预处理(清除标点符号)
punctuation = ',、.";!'
for ch in punctuation:
str = str.replace(ch, '')
print(str)
# 分解提取单词 list
print('\n')
List = str.split(' ')
print(len(List), List)
# 单词计数字典 set , dict
print('\n')
strSet = set(List)
print(len(strSet), strSet)
strDict = {}
for world in strSet:
strDict[world] = List.count(world)
print(len(strDict), strDict)
# 按词频排序并输出(降序)
print('\n')
list = list(strDict.items())
print(list)
list.sort(key=lambda x: x[1], reverse=True)
print(list)
# 排除语法型词汇,代词、冠词、连词等无语义词
e = {'a', 'the', 'an', 'and', 'i', 'or', 'of'}
strSet = strSet - e
print(len(strSet), strSet)
# TOP20输出
print('\n')
for i in range(20):
print(list[i])
import pandas as pd
pd.DataFrame(data=list).to_csv('big.csv',encoding='utf-8')
