

JAVA爬虫实践(实践二:博客园)
分析博客园网站的请求可以发现,博客园的分页请求为POST方式,和知乎的滚动加载类似。
不同的是请求响应返回的是HTML而不是JSON。
这样可以套用上一篇爬知乎的代码,需要修改的部分就是POST方法传的参数,直接用map,还有解析HTML的部分。
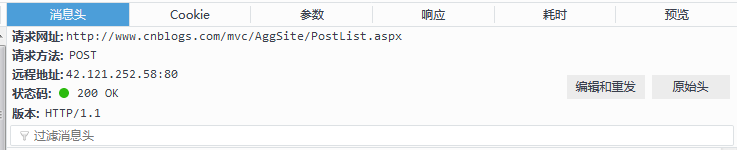

模拟POST请求
public String doPost(Map<String, String> args) throws Exception { HttpClient httpClient = new DefaultHttpClient(); RequestBuilder builder = RequestBuilder.post() .setUri("http://www.cnblogs.com/mvc/AggSite/PostList.aspx"); Set<String> keys = args.keySet(); for (String key : keys) { builder.addParameter(key,args.get(key)); } HttpUriRequest httpUriRequest = builder.build(); // 添加必要的头信息 httpUriRequest.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0"); httpUriRequest.setHeader("Cookie", "这里的还是要用自己的Cookie"); httpUriRequest.setHeader("DNT", "1"); httpUriRequest.setHeader("Connection", "keep-alive"); httpUriRequest.setHeader("Upgrade-Insecure-Requests", "1"); httpUriRequest.setHeader("If-Modified-Since", "Wed, 12 Apr 2017 03:10:29 GMT"); HttpResponse response = httpClient.execute(httpUriRequest); String str = ""; HttpEntity entity = response.getEntity(); if (entity != null) { InputStream instreams = entity.getContent(); str = convertStreamToString(instreams); } return str; }
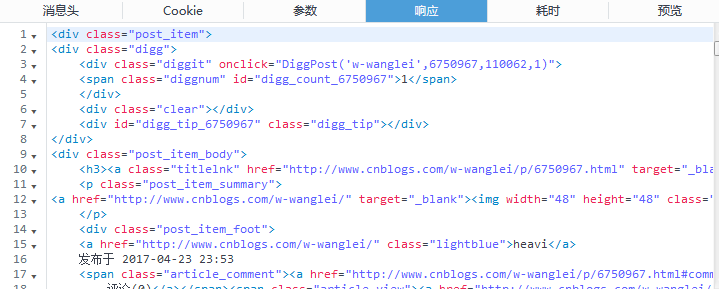
HTML内容的提取部分
因为HTML的所有标签元素id唯一可以找到一个距离较近的带id的元素,向下取到内容。
这里还是较多的用get(0)来取元素。
public String unparsedData(String html) { Document doc = Jsoup.parse(html); Elements elements = doc.getElementsByAttributeValue("class", "post_item"); String writeStr = ""; for (Element element : elements) { //推荐数量 Elements diggs = element.getElementsByAttributeValue("class", "digg"); String digg = diggs.get(0).getElementsByTag("span").text().trim(); Elements postItemBodys = element.getElementsByAttributeValue("class", "post_item_body"); //标题 String titleHref = postItemBodys.get(0).getElementsByTag("h3").get(0).getElementsByAttributeValue("class", "titlelnk").get(0).attr("href"); String titleText = postItemBodys.get(0).getElementsByTag("h3").get(0).getElementsByAttributeValue("class", "titlelnk").get(0).text().trim(); //摘要 String contentText = postItemBodys.get(0).getElementsByAttributeValue("class", "post_item_summary").get(0).text().trim(); System.out.println("--------------------"); System.out.println("-----标题-----"); System.out.println("推荐:" + digg); System.out.println("链接:" + titleHref); System.out.println("内容:" + titleText); System.out.println("-----内容-----"); System.out.println("内容:" + contentText); System.out.println("--------------------"); writeStr += "--------------------\n-----标题-----推荐:"+digg+"\n" + titleHref + "\n" + titleText + "\n-----内容-----\n" + contentText + "\n--------------------\n\n\n"; } return writeStr; }
完整代码


package spider; import java.io.BufferedReader; import java.io.File; import java.io.FileWriter; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.io.PrintWriter; import java.util.HashMap; import java.util.Map; import java.util.Set; import org.apache.http.HttpEntity; import org.apache.http.HttpResponse; import org.apache.http.client.ClientProtocolException; import org.apache.http.client.HttpClient; import org.apache.http.client.methods.HttpGet; import org.apache.http.client.methods.HttpUriRequest; import org.apache.http.client.methods.RequestBuilder; import org.apache.http.impl.client.DefaultHttpClient; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import org.junit.Test; @SuppressWarnings("deprecation") public class CnblogsSpider { // 下载 URL 指向的网页 @SuppressWarnings("static-access") @Test public void downloadFile() throws Exception { // 模拟HTTP GET请求 String responseBody = doGet(); // 解析数据 String writeStr = unparsedData(responseBody); // 创建新文件 String path = "D:\\testFile\\cnblogs.txt"; PrintWriter printWriter = null; printWriter = new PrintWriter(new FileWriter(new File(path))); printWriter.write(writeStr); printWriter.close(); Map<String, String> args = new HashMap<String, String>(); args.put("CategoryId", "808"); args.put("CategoryType", "\"SiteHome\""); args.put("ItemListActionName", "\"PostList\""); args.put("ParentCategoryId", "0"); args.put("TotalPostCount", "4000"); for (int time = 2; time <= 200; time++) { // 延时,调整参数 Thread.currentThread().sleep(200);// 毫秒 args.put("PageIndex", time + ""); // 模拟JS发送POST请求 String json = doPost(args); // 解析数据 String addWriteStr = ""; addWriteStr += unparsedData(json); // 追加文本 printWriter = new PrintWriter(new FileWriter(path, true)); printWriter.write(addWriteStr); printWriter.close(); } } /** * 模拟HTTP GET请求 * * @return 请求返回的JSON数据 */ public String doGet() throws ClientProtocolException, IOException { // 创建HttpClient实例 HttpClient httpClient = new DefaultHttpClient(); // 创建Get方法实例 HttpUriRequest httpUriRequest = new HttpGet("http://www.cnblogs.com"); // 添加必要的头信息 httpUriRequest .setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0"); httpUriRequest .setHeader( "Cookie", "这里的还是要用自己的Cookie"); httpUriRequest.setHeader("DNT", "1"); httpUriRequest.setHeader("Connection", "keep-alive"); httpUriRequest.setHeader("Upgrade-Insecure-Requests", "1"); httpUriRequest.setHeader("If-Modified-Since", "Wed, 12 Apr 2017 03:10:29 GMT"); HttpResponse response = httpClient.execute(httpUriRequest); String json = ""; HttpEntity entity = response.getEntity(); if (entity != null) { InputStream instreams = entity.getContent(); json = convertStreamToString(instreams); } return json; } /** * 模拟HTTP POST请求 * * @param offset * 参数offset * @param start * 参数start * @return 请求返回的JSON数据 */ public String doPost(Map<String, String> args) throws Exception { HttpClient httpClient = new DefaultHttpClient(); RequestBuilder builder = RequestBuilder.post().setUri( "http://www.cnblogs.com/mvc/AggSite/PostList.aspx"); Set<String> keys = args.keySet(); for (String key : keys) { builder.addParameter(key, args.get(key)); } HttpUriRequest httpUriRequest = builder.build(); // 添加必要的头信息 httpUriRequest .setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0"); httpUriRequest .setHeader( "Cookie", "这里的还是要用自己的Cookie"); httpUriRequest.setHeader("DNT", "1"); httpUriRequest.setHeader("Connection", "keep-alive"); httpUriRequest.setHeader("Upgrade-Insecure-Requests", "1"); httpUriRequest.setHeader("If-Modified-Since", "Wed, 12 Apr 2017 03:10:29 GMT"); HttpResponse response = httpClient.execute(httpUriRequest); String str = ""; HttpEntity entity = response.getEntity(); if (entity != null) { InputStream instreams = entity.getContent(); str = convertStreamToString(instreams); } return str; } public static String convertStreamToString(InputStream is) throws IOException { InputStreamReader ir = new InputStreamReader(is, "UTF8"); BufferedReader reader = new BufferedReader(ir); StringBuilder sb = new StringBuilder(); String line = null; try { while ((line = reader.readLine()) != null) { sb.append(line + "\n"); } } catch (IOException e) { e.printStackTrace(); } finally { try { is.close(); } catch (IOException e) { e.printStackTrace(); } } return sb.toString(); } /** * 根据HTML解析数据 * * @param html * 源HTML * @return 解析后的数据 */ public String unparsedData(String html) { Document doc = Jsoup.parse(html); Elements elements = doc.getElementsByAttributeValue("class", "post_item"); String writeStr = ""; for (Element element : elements) { // 推荐数量 Elements diggs = element.getElementsByAttributeValue("class", "digg"); String digg = diggs.get(0).getElementsByTag("span").text().trim(); Elements postItemBodys = element.getElementsByAttributeValue( "class", "post_item_body"); // 标题 String titleHref = postItemBodys.get(0).getElementsByTag("h3") .get(0).getElementsByAttributeValue("class", "titlelnk") .get(0).attr("href"); String titleText = postItemBodys.get(0).getElementsByTag("h3") .get(0).getElementsByAttributeValue("class", "titlelnk") .get(0).text().trim(); // 摘要 String contentText = postItemBodys.get(0) .getElementsByAttributeValue("class", "post_item_summary") .get(0).text().trim(); System.out.println("--------------------"); System.out.println("-----标题-----"); System.out.println("推荐:" + digg); System.out.println("链接:" + titleHref); System.out.println("内容:" + titleText); System.out.println("-----内容-----"); System.out.println("内容:" + contentText); System.out.println("--------------------"); writeStr += "--------------------\n-----标题-----推荐:" + digg + "\n" + titleHref + "\n" + titleText + "\n-----内容-----\n" + contentText + "\n--------------------\n\n\n"; } return writeStr; } }
