
JAVA爬虫实践(实践一:知乎)
爬虫顺序
1.分析网站网络请求
通过浏览器F12开发者工具查看网站的内容获取方式。
2.模拟HTTP请求,获取网页内容。
可以采用HttpClient,利用JAVA HttpClient工具可以模拟HTTP GET、POST请求,可以用来获取爬虫需要的数据。JAVA的一些爬虫框架底层用到的获取网页方式也都是HttpClient。
3.解析网页HTML内容,获取可用数据和下一条请求链接。
可以采用jsoup、正则表达式、xpath等。
实践一:知乎


查看开发者工具可以看到知乎首页的内容获取有两种:
一种是GET请求,请求地址为https://www.zhihu.com/
一种是POST请求,请求地址为https://www.zhihu.com/node/TopStory2FeedList
第一种GET请求即现实中用户直接从浏览器地址栏输入知乎的网址或点击链接进行请求,这时知乎会响应返回一个只有数条内容的首页给用户。
第二种POST请求即现实中用户向下滚动页面,浏览器持续加载新内容。
第一种GET请求没有参数,响应也是HTML,较为简单。
第二种POST请求可以在开发者工具中查看它的参数和响应。
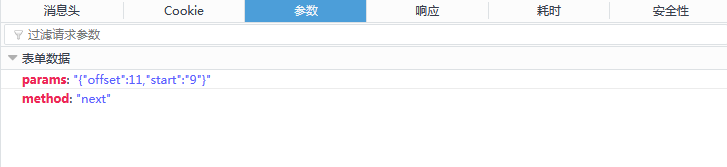
可以看到有两个请求参数
params:"{"offset":21,"start":"19"}"
method:"next"
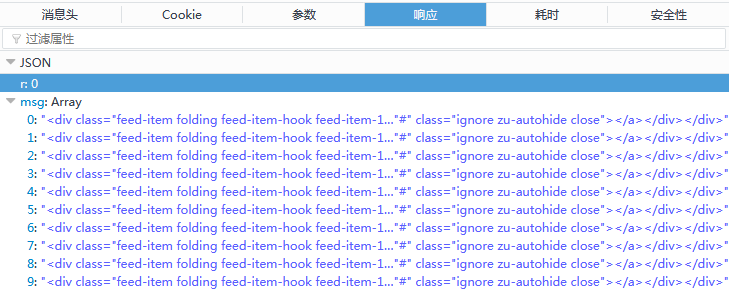
响应为一段JSON,我们要的是下面的msg数组,所以代码中会用到json-lib这个jar包方便我们解析json。
分析完网站的网络请求后就可以进行下一步,模拟HTTP请求
首先模拟GET请求
public String doGet() throws ClientProtocolException, IOException { String str = ""; // 创建HttpClient实例 HttpClient httpClient = new DefaultHttpClient(); // 创建Get方法实例 HttpUriRequest httpUriRequest = new HttpGet("http://www.zhihu.com"); // 添加必要的头信息 httpUriRequest.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0"); httpUriRequest.setHeader("Cookie", "这里的Cookie拷贝复制登录后请求头里的Cookie值"); httpUriRequest.setHeader("DNT", "1"); httpUriRequest.setHeader("Connection", "keep-alive"); httpUriRequest.setHeader("Upgrade-Insecure-Requests", "1"); httpUriRequest.setHeader("Cache-Control", "max-age=0"); HttpResponse response = httpClient.execute(httpUriRequest); HttpEntity entity = response.getEntity(); if (entity != null) { InputStream inputStream = entity.getContent(); str = convertStreamToString(inputStream); } return str; }
convertStreamToString为一个将流转换为字符串的方法


public static String convertStreamToString(InputStream is) throws IOException { InputStreamReader ir = new InputStreamReader(is, "UTF8"); BufferedReader reader = new BufferedReader(ir); StringBuilder sb = new StringBuilder(); String line = null; try { while ((line = reader.readLine()) != null) { sb.append(line + "\n"); } } catch (IOException e) { e.printStackTrace(); } finally { try { is.close(); } catch (IOException e) { e.printStackTrace(); } } return sb.toString(); }
模拟POST请求(两个参数即为请求参数里的两个变量)
public String doPost(int offset, int start) throws Exception { HttpClient httpClient = new DefaultHttpClient(); HttpUriRequest httpUriRequest = RequestBuilder .post() .setUri("https://www.zhihu.com/node/TopStory2FeedList") .addParameter("params", "{\"offset\":" + offset + ",\"start\":\"" + start + "\"}").addParameter("method", "next").build(); // 添加必要的头信息 httpUriRequest.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0"); httpUriRequest.setHeader("X-Xsrftoken", "这里的X-Xsrftoken拷贝复制登录后请求头里的X-Xsrftoken值"); httpUriRequest.setHeader("X-Requested-With", "XMLHttpRequest"); httpUriRequest.setHeader("Referer", "https://www.zhihu.com/"); httpUriRequest.setHeader("Cookie", "这里的Cookie拷贝复制登录后请求头里的Cookie值"); httpUriRequest.setHeader("DNT", "1"); httpUriRequest.setHeader("Connection", "keep-alive"); httpUriRequest.setHeader("Cache-Control", "max-age=0"); HttpResponse response = httpClient.execute(httpUriRequest); String str = ""; HttpEntity entity = response.getEntity(); if (entity != null) { InputStream instreams = entity.getContent(); str = convertStreamToString(instreams); } return str; }
最后走一波main方法将数据保存至TXT文件中,在这之前要提取一下HTML中的数据
根据HTML解析数据
这里用到的Document Elements Element 都是jsoup里的元素
这段代码首先拿到到类名为feed-item-inner的HTML元素
变量所有feed-item-inner拿到类名为feed-title的标题和标签类型为textarea的内容
public String unparsedData(String html) { Document doc = Jsoup.parse(html); Elements feeds = doc.getElementsByAttributeValue("class", "feed-item-inner"); String writeStr = ""; for (Element feed : feeds) { Elements title = new Elements(); Elements feedTitles = feed.getElementsByAttributeValue("class", "feed-title"); for (Element feedTitle : feedTitles) { title = feedTitle.getElementsByTag("a"); } Elements content = feed.getElementsByTag("textarea"); String titleHref = title.attr("href"); String titleText = title.text().trim(); String contentText = content.text().trim(); // if(!titleText.contains("人民的名义")){ // continue; // } System.out.println("--------------------"); System.out.println("-----标题-----"); System.out.println("链接:" + titleHref); System.out.println("内容:" + titleText); System.out.println("-----内容-----"); System.out.println("内容:" + contentText); System.out.println("--------------------"); writeStr += "--------------------\n-----标题-----\n" + titleHref + "\n" + titleText + "\n-----内容-----\n" + contentText + "\n--------------------\n\n\n"; } return writeStr; }
最后Main方法
public void downloadFile() throws Exception { // 模拟HTTP GET请求 String responseBody = doGet(); // 解析数据 String writeStr = unparsedData(responseBody); // 创建新文件 String path = "D:\\testFile\\zhihu.txt"; PrintWriter printWriter = null; printWriter = new PrintWriter(new FileWriter(new File(path))); // 写内容 printWriter.write(writeStr); printWriter.close(); int offset = 10; int start = 9; for (int time = 0; time <= 100; time++) { // 模拟POST请求 JSONObject jsonObject = JSONObject.fromObject(doPost(offset, start)); // 解析数据(只拿JSON数据里的msg数组) String addWriteStr = ""; JSONArray jsonArray = jsonObject.getJSONArray("msg"); Object[] arrays = jsonArray.toArray(); for (Object array : arrays) { addWriteStr += unparsedData(array.toString()); } // 追加文本 printWriter = new PrintWriter(new FileWriter(path, true)); printWriter.write(addWriteStr); printWriter.close(); // 延时,调整参数 Thread.currentThread().sleep(1000);// 毫秒 offset = offset + 10; start = start + 10; } }
完整代码
package spider; import java.io.BufferedReader; import java.io.File; import java.io.FileWriter; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.io.PrintWriter; import net.sf.json.JSONArray; import net.sf.json.JSONObject; import org.apache.http.HttpEntity; import org.apache.http.HttpResponse; import org.apache.http.client.ClientProtocolException; import org.apache.http.client.HttpClient; import org.apache.http.client.methods.HttpGet; import org.apache.http.client.methods.HttpUriRequest; import org.apache.http.client.methods.RequestBuilder; import org.apache.http.impl.client.DefaultHttpClient; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import org.junit.Test; @SuppressWarnings("deprecation") public class ZhihuSpider { /** * 模拟HTTP GET请求 */ public String doGet() throws ClientProtocolException, IOException { String str = ""; // 创建HttpClient实例 HttpClient httpClient = new DefaultHttpClient(); // 创建Get方法实例 HttpUriRequest httpUriRequest = new HttpGet("http://www.zhihu.com"); // 添加必要的头信息 httpUriRequest .setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0"); httpUriRequest .setHeader( "Cookie", "这里的Cookie拷贝复制登录后请求头里的Cookie值"); httpUriRequest.setHeader("DNT", "1"); httpUriRequest.setHeader("Connection", "keep-alive"); httpUriRequest.setHeader("Upgrade-Insecure-Requests", "1"); httpUriRequest.setHeader("Cache-Control", "max-age=0"); HttpResponse response = httpClient.execute(httpUriRequest); HttpEntity entity = response.getEntity(); if (entity != null) { InputStream inputStream = entity.getContent(); str = convertStreamToString(inputStream); } return str; } public static String convertStreamToString(InputStream is) throws IOException { InputStreamReader ir = new InputStreamReader(is, "UTF8"); BufferedReader reader = new BufferedReader(ir); StringBuilder sb = new StringBuilder(); String line = null; try { while ((line = reader.readLine()) != null) { sb.append(line + "\n"); } } catch (IOException e) { e.printStackTrace(); } finally { try { is.close(); } catch (IOException e) { e.printStackTrace(); } } return sb.toString(); } // 下载 URL 指向的网页 @SuppressWarnings("static-access") @Test public void downloadFile() throws Exception { // 模拟HTTP GET请求 String responseBody = doGet(); // 解析数据 String writeStr = unparsedData(responseBody); // 创建新文件 String path = "D:\\testFile\\zhihu.txt"; PrintWriter printWriter = null; printWriter = new PrintWriter(new FileWriter(new File(path))); // 写内容 printWriter.write(writeStr); printWriter.close(); int offset = 10; int start = 9; for (int time = 0; time <= 100; time++) { // 模拟POST请求 JSONObject jsonObject = JSONObject .fromObject(doPost(offset, start)); // 解析数据(只拿JSON数据里的msg数组) String addWriteStr = ""; JSONArray jsonArray = jsonObject.getJSONArray("msg"); Object[] arrays = jsonArray.toArray(); for (Object array : arrays) { addWriteStr += unparsedData(array.toString()); } // 追加文本 printWriter = new PrintWriter(new FileWriter(path, true)); printWriter.write(addWriteStr); printWriter.close(); // 延时,调整参数 Thread.currentThread().sleep(1000);// 毫秒 offset = offset + 10; start = start + 10; } } /** * 根据HTML解析数据 * * @param html * 源HTML * @return 解析后的数据 */ public String unparsedData(String html) { Document doc = Jsoup.parse(html); Elements feeds = doc.getElementsByAttributeValue("class", "feed-item-inner"); String writeStr = ""; for (Element feed : feeds) { Elements title = new Elements(); Elements feedTitles = feed.getElementsByAttributeValue("class", "feed-title"); for (Element feedTitle : feedTitles) { title = feedTitle.getElementsByTag("a"); } Elements content = feed.getElementsByTag("textarea"); String titleHref = title.attr("href"); String titleText = title.text().trim(); String contentText = content.text().trim(); // if(!titleText.contains("人民的名义")){ // continue; // } System.out.println("--------------------"); System.out.println("-----标题-----"); System.out.println("链接:" + titleHref); System.out.println("内容:" + titleText); System.out.println("-----内容-----"); System.out.println("内容:" + contentText); System.out.println("--------------------"); writeStr += "--------------------\n-----标题-----\n" + titleHref + "\n" + titleText + "\n-----内容-----\n" + contentText + "\n--------------------\n\n\n"; } return writeStr; } /** * 模拟HTTP POST请求 * * @param offset * 参数offset * @param start * 参数start * @return 请求返回的JSON数据 */ public String doPost(int offset, int start) throws Exception { HttpClient httpClient = new DefaultHttpClient(); HttpUriRequest httpUriRequest = RequestBuilder .post() .setUri("https://www.zhihu.com/node/TopStory2FeedList") .addParameter( "params", "{\"offset\":" + offset + ",\"start\":\"" + start + "\"}").addParameter("method", "next").build(); // 添加必要的头信息 httpUriRequest .setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0"); httpUriRequest.setHeader("X-Xsrftoken", "这里的X-Xsrftoken拷贝复制登录后请求头里的X-Xsrftoken值"); httpUriRequest.setHeader("X-Requested-With", "XMLHttpRequest"); httpUriRequest.setHeader("Referer", "https://www.zhihu.com/"); httpUriRequest .setHeader( "Cookie", "这里的Cookie拷贝复制登录后请求头里的Cookie值"); httpUriRequest.setHeader("DNT", "1"); httpUriRequest.setHeader("Connection", "keep-alive"); httpUriRequest.setHeader("Cache-Control", "max-age=0"); HttpResponse response = httpClient.execute(httpUriRequest); String str = ""; HttpEntity entity = response.getEntity(); if (entity != null) { InputStream instreams = entity.getContent(); str = convertStreamToString(instreams); } return str; } }
