24-调度引擎:Kubernete 如何高效调度 Pod?
我们已经学会如何部署业务,发布 Pod。但是 Pod 创建好以后,Kubernetes 又如何调度这些 Pod 呢?如果我们希望把一个 Pod 跑在我们期望的节点上,该如何操作呢?如果我们希望把某些关联性强的 Pod 跑在特定的节点上,或者同一个节点上,又该怎么操作呢?
今天我们就来揭晓。
Kubernetes 调度器工作原理简介
kube-scheduler 作为 Kubernetes 的调度器,它的主要任务就是给新创建的 Pod 或者是未被调度的 Pod 挑选一个合适的节点供 Pod 运行,满足 Pod 对资源等的要求。这样对应节点上的 Kubelet 就可以监听到该 Pod,并将其创建、运行。
整个调度过程听起来很简单,但是要考虑到的问题其实有很多,比如优先级、资源高效利用、高性能等。
-
优先级。高优先级的 Pod 肯定要优先被调度,这个我在《21 | 优先级调度:你必须掌握的 Pod 抢占式资源调度》中有详细的案例和说明。
-
资源高效利用。比如我们要避免 Pod 都被调度到一个或某几个节点上,造成节点负载太大;或是避免同一个工作负载(如 Deployment)的几个副本,跑在同一个节点上,以免这个节点宕机对整个业务造成影响。
-
高性能。我们需要支持快速地完成大规模 Pod 的调度工作,这样才能够支撑大规模的集群。
-
可扩展性强。方便用户自己增加调度逻辑,可以参考官方文档中的内容。
-
……
总的来说,调度的过程主要分为两个大步骤。
-
过滤一些不满足条件的节点,这个过程也称为 Predict。
-
调度器会对这些合适的节点进行打分排序,从中选择一个最优的节点,这个过程也称为 Priority。
这里面其实包含了很多的调度策略,在此不一一说明,你可以阅读这份调度策略列表,了解各个策略对应的含义。
在实际使用的过程中,你可以直接使用调度器的默认配置,不需要对其做过多的定制化。当然,如果你有特殊的需求,也可以构建自己的调度器,具体可以参考这份文档来更改默认调度器的调度策略、调度插件以及调度行为。
下面我们主要来认识一下调度器都有哪些高级特性。
调度器的高级特性
调度器的高级特性有 NodeName 和 NodeSelector、亲和性和反亲性、污点和容忍,我们依次来了解一下。
NodeName 和 NodeSelector
首先是 NodeName 和 NodeSelector。
我们可以通过 spec.nodeName 强制约束在某个指定的 Node 上运行 Pod,如下所示:
apiVersion: v1
kind: Pod
metadata:
name: pod-with-nodename
namespace: demo
spec:
nodeName: node1 #指定调度节点 node1 上
containers:
- name: nginx-demo
image: nginx:1.19.4
上面这个 Pod 就被约束在 node1 上。通过这种方式指定节点,会跳过 kube-scheduler 的调度逻辑,即不需要经过调度。
除了这种强制指定节点的方式,我们还可以通过 NodeSelector 的方式来选择节点。调度器的调度策略 MatchNodeSelector 会匹配 Node 的 label,从而达到节点筛选的目的。比如下面这个例子:
# 我们先对节点进行打标
$ kubectl label nodes node1 abc.com/role=dev
# 通过如下命令可以查看该节点目前的所有 label
$ kubectl get node node1 --show-labels
NAME STATUS ROLES AGE VERSION LABELS
node1 Ready master 75d v1.16.6-beta.0 abc.com/role=dev,beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=docker-desktop,kubernetes.io/os=linux,node-role.kubernetes.io/master=
对节点打好标以后,就可以通过 spec.nodeSelector 来将 Pod 调度到带有指定 label 标记的节点上。
apiVersion: v1
kind: Pod
metadata:
name: pod-with-nodename
namespace: demo
spec:
nodeSelector:
abc.com/role: dev #指定调度到带有 abc.com/role=dev 这种 label 标记的节点上
containers:
- name: nginx-demo
image: nginx:1.19.4
nodeSelector 提供了一种非常简单的方法,方便我们将 Pod 约束到带有特定 label 的节点上。
除此之外,kube-scheduler 还提供了更加动态的方式,即亲和性和反亲和性,可以帮助我们完成更高级的 Pod 调度,比如将某些 Pod 都调度到某个节点上。
下面我们就来认识一下亲和性和反亲和性。
亲和性和反亲和性
Kubernetes 提供了如下 3 种类型:
-
nodeAffinity(节点亲和性);
-
podAffinity(Pod 亲和性);
-
podAntiAffinity(Pod 反亲和性)。
这 3 种亲和性和反亲和性策略支持更广泛的操作符,差异如下表所示:
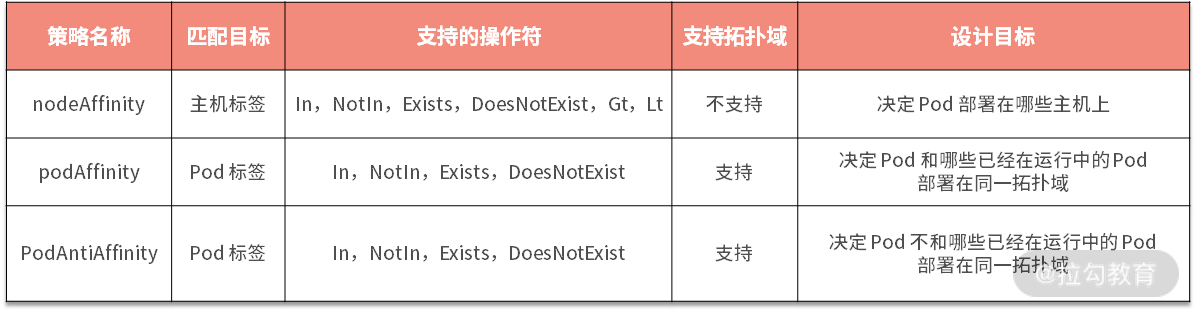
对于上述的亲和性和反亲和性功能,每种都有 3 种规则可以设置。
-
RequiredDuringSchedulingRequiredDuringExecution:在 Pod 调度期间要求满足亲和性或者反亲和性的规则要求。如果不能满足这些指定的规则,那该 Pod 不能被调度到对应的主机上。而且在之后的运行过程中,如果因为某些原因(比如 label 被修改了)导致规则不再满足了,系统就会尝试把该 Pod 从主机上驱逐掉。
-
RequiredDuringSchedulingIgnoredDuringExecution:在 Pod 调度期间要求满足亲和性或者反亲和性规则。如果不能满足的话,那么该 Pod 不能被调度到对应的主机上。在之后的运行过程中,系统也不会再去检查这些规则是否还继续满足。
-
PreferredDuringSchedulingIgnoredDuringExecution:在 Pod 调度期间要尽量地指定的亲和性和反亲和性规则。即使不能满足,Pod 也有可能被调度到对应的主机上。在之后的运行过程中,系统也不会再去检查这些规则是否继续满足。
我们这里来说说具体的使用场景。
对于 nodeAffinity,主要有两个使用场景:
-
帮助我们将一个工作负载的所有 Pod 部署到指定的 label 的主机上,这点和 nodeSelector 是类似的;帮助我们将 Pod 部署到不带有特定 label 的主机上,即 Notin,比如不在 Master 节点上部署该 Pod。
下面是一个官方使用的 nodeAffinity 的例子:
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/e2e-az-name
operator: In
values:
- e2e-az1
- e2e-az2
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: k8s.gcr.io/pause:2.0
这个 Pod 指定必须运行在 label 带有 kubernetes.io/e2e-az-name=e2e-az1 或 kubernetes.io/e2e-az-name=e2e-az2 的节点上。如果没有任何一个节点有这些 label,则该 Pod 不会被调度。同时这些节点上最好还带有 another-node-label-key=another-node-label-vale 的标签。
对于 podAffinity 和 podAntiAffinity,你可以基于已经在节点上运行的 Pod 的标签来约束新 Pod 可以调度到的节点,而不是基于节点上的标签。
如下是一个官方使用的 podAffinity 和 podAntiAffinity 的例子:
a piVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: topology.kubernetes.io/zone
containers:
- name: with-pod-affinity
image: k8s.gcr.io/pause:2.0
上述这个例子中使用了 podAffinity 和 podAntiAffinity。其中亲和性这块的规则表示该 Pod 必须部署在一个节点上,这个节点上至少有一个处于正在运行状态的带有 security=s1 标签的 Pod,并且要求部署的节点同正在运行的 Pod 所在节点都在相同的云服务区域中,也就是 topologyKey:topology.kubernetes.io/zone。
换言之,一旦某个区域出了问题,我们希望这些 Pod 能够再次迁移到同一个区域。当然, topologyKey 可以是任何合法的标签键,比如 kubernetes.io/hostname,你可以参考官方文档,看看这个值在使用上的限制。
对于例子中 Pod 反亲和性规则,表示该 Pod 不希望部署在一个运行着带有 label 为 security=s2 的 Pod 的节点上。
除了在 Pod 层面进行限制外,我们还可以对 Node 进行操作,可以禁止某些 Pod 调度上来。
污点和容忍(Taints and Tolerations)
最后我们来看污点和容忍(Taints and Tolerations)。
我们可以给节点设置污点,通过这个污点就可以避免 Pod 调度上来,除非在 Pod 上设置了污点容忍。
每个污点的组成如下:
key=value:effect
每个污点规则都有一个 key 和 value,其中 value 可以为空,effect 描述污点的作用。当前 taint effect 支持如下 3 个选项:
-
NoSchedule 表示不会将 Pod 调度到带该污点的 Node 上;
-
PreferNoSchedule 表示尽量避免将 Pod 调度到带该污点的 Node 上;
-
NoExecute 表示不会将 Pod 调度到带有该污点的 Node 上,同时会将 Node 上已经运行中的 Pod 驱逐出去。
我们使用 kubectl 命令就可以快速地设置和去除污点,命令如下:
# 设置污点
kubectl taint nodes node1 key1=value1:NoSchedule
# 去除污点
kubectl taint nodes node1 key1:NoSchedule-
我们可以在 Pod 上设置容忍(Toleration),这样就可以将 Pod 调度到存在污点的 Node 上。在 Pod 的 spec 中设置 tolerations 字段可以给 Pod 设置上容忍点 Toleration,如下所示:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
tolerationSeconds: 3600
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
- key: "key2"
operator: "Exists"
effect: "NoSchedule"
其中 key、vaule、effect 要与 Node 上设置的 taint 保持一致;operator 的值为 Exists 将会忽略 value 值;tolerationSeconds 用于描述当 Pod 需要被驱逐时可以在 Pod 上继续保留运行的时间。
写在最后
这一讲我带你了解了 Kubernetes 调度器的工作原理以及调度器的一些高级特性,也介绍了 Kubernetes 是如何高效调度 Pod 的。你可以在实际使用中慢慢体会调度器的这些高级特性。
那么,学完这些,你对于调度 Pod 还有什么疑问吗?欢迎在留言区留言。
下一讲,我将带你剖析容器运行时以及 CRI 原理。
作者:huangjiale
出处:https://www.cnblogs.com/huangjiale/p/17958426
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律