23-最后的防线:怎样对 Kubernete 集群进行灾备和恢复?
Kubernetes 隐藏了所有容器编排的复杂细节,让我们可以专注在应用本身,而无须过多关注如何去做部署和维护。此外,Kubernetes 还支持多副本,可以保证我们业务的高可用性。而对于集群本身而言,我们一样也要保证其高可用性,你可以参考官方文档:利用 Kubeadm 来创建高可用集群。
但是这些并不足以让我们高枕无忧,因为 Kubernetes 在帮助我们编排调度容器的同时,往往还保存了很多关键数据,比如集群自身关键数据、密钥、业务配置信息、业务数据等。我们在使用 Kubernetes 的时候,非常有必要进行灾备,防止出现操作失误(比如大规模无删除)、自然灾害、磁盘损坏无法修复、网络异常、机房断电等情况导致的数据丢失,严重时甚至会导致整个集群不可用。
所以在使用 Kubernetes 的时候,我们最好做个灾备以方便对集群进行恢复,回滚到早期的一个稳定的状态。
Kubernetes 需要备份哪些东西
在对 Kubernetes 集群做备份之前,我们首先得知道要备份哪些东西。
我们从整个 Kubernetes 的架构为出发点,来看看整个集群的组件。我在《02 | 高屋建瓴:Kubernetes 的架构为什么是这样的?》中讲到 Kubernetes 的官方架构图,如下:
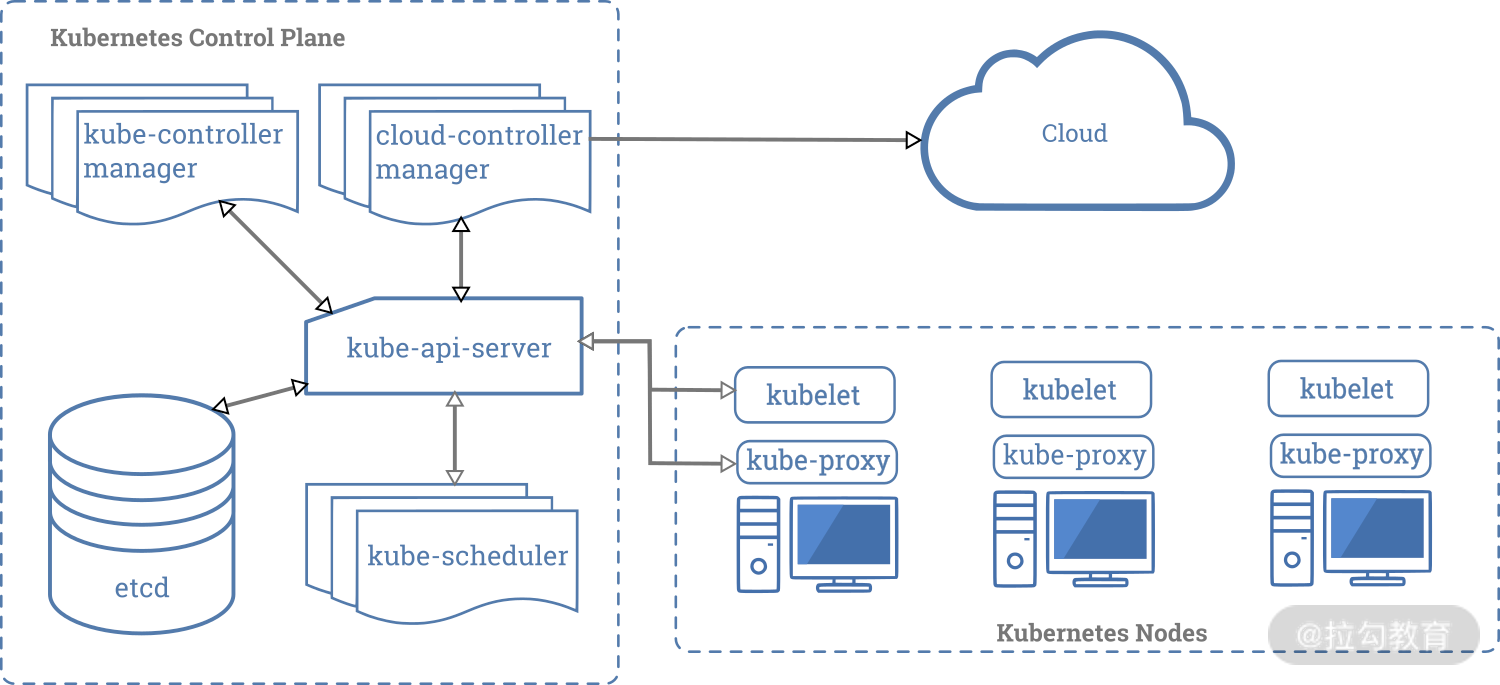
图 1:Kubernetes 官方架构图
从上图可以看出,整个 Kubernetes 集群可分为Master 节点(左侧)和 Node 节点(右侧)。
在 Master 节点上,我们运行着 Etcd 集群以及 Kubernetes 控制面的几大组件,比如 kube-apiserver、kube-controller-manager、kube-scheduler 和 cloud-controller-manager(可选)等。
在这些组件中,除了 Etcd,其他都是无状态的服务。只要保证 Etcd 的数据正常,其他几个组件不管出现什么问题,我们都可以通过重启或者新建实例来解决,并不会受到任何影响。因此我们只需要备份 Etcd 中的数据。
看完了 Master 节点,我们再来看看 Node 节点。
Node 节点上运行着 kubelet、kube-proxy 等服务。Kubelet 负责维护各个容器实例,以及容器使用到的存储。为了保证数据的持久化存储,对于关键业务的关键数据,我都建议通过我在《10 | 存储管理:怎样对业务数据进行持久化存储?》中提到的 PV(Persistent Volume)来保存和使用。鉴于这一点,我们还需要对 PV 进行备份。
如果是节点出现了问题,我们可以向集群中增加新的节点,替换掉有问题的节点。
看完 Kubernetes 的官方架构图之后,下面我们就来看看该如何备份 Etcd 中的数据和 PV。
对 Etcd 数据进行备份及恢复
Etcd 官方也提供了备份的文档,你有兴趣可以阅读一下。我在这里总结了一些实际操作,以便你后续可以借鉴并进行手动的备份和恢复。命令行里面的一些证书路径以及 endpoint 地址需要根据自己的集群参数进行更改。实际操作代码如下:
# 0. 数据备份
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--key=/etc/kubernetes/pki/etcd/peer.key \
--cert=/etc/kubernetes/pki/etcd/peer.crt \
snapshot save ./new.snapshot.db
# 1. 查看 etcd 集群的节点
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/peer.crt \
--key=/etc/kubernetes/pki/etcd/peer.key \
member list
# 2. 停止所有节点上的 etcd!(注意是所有!!)
## 如果是 static pod,可以听过如下的命令进行 stop
## 如果是 systemd 管理的,可以通过 systemctl stop etcd
mv /etc/kubernetes/manifests/etcd.yaml /etc/kubernetes/
# 3. 数据清理
## 依次在每个节点上,移除 etcd 数据
rm -rf /var/lib/etcd
# 4. 数据恢复
## 依次在每个节点上,恢复 etcd 旧数据
## 里面的 name,initial-advertise-peer-urls,initial-cluster=controlplane
## 等参数,可以从 etcd pod 的 yaml 文件中获取到。
ETCDCTL_API=3 etcdctl snapshot restore ./old.snapshot.db \
--data-dir=/var/lib/etcd \
--name=controlplane \
--initial-advertise-peer-urls=https://172.17.0.18:2380 \
--initial-cluster=controlplane=https://172.17.0.18:2380
# 5. 恢复 etcd 服务
## 依次在每个节点上,拉起 etcd 服务
mv /etc/kubernetes/etcd.yaml /etc/kubernetes/manifests/
systemctl restart kubelet
上述这些备份,都需要手动运行命令行进行操作。如果你的 Etcd 集群是运行在 Kubernetes 集群中的,你可以通过以下的定时 Job (CronJob) 来帮你自动化、周期性(如下的 YAML 文件中会每分钟对 Etcd 进行一次备份)地备份 Etcd 的数据。关于 CronJob 部分的内容,我们在后面单独章节会进行介绍。自动备份代码如下:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: backup
namespace: kube-system
spec:
# activeDeadlineSeconds: 100
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: backup
# Same image as in /etc/kubernetes/manifests/etcd.yaml
image: k8s.gcr.io/etcd:3.2.24
env:
- name: ETCDCTL_API
value: "3"
command: ["/bin/sh"]
args: ["-c", "etcdctl --endpoints=https://127.0.0.1:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/healthcheck-client.crt --key=/etc/kubernetes/pki/etcd/healthcheck-client.key snapshot save /backup/etcd-snapshot-$(date +%Y-%m-%d_%H:%M:%S_%Z).db"]
volumeMounts:
- mountPath: /etc/kubernetes/pki/etcd
name: etcd-certs
readOnly: true
- mountPath: /backup
name: backup
restartPolicy: OnFailure
hostNetwork: true
volumes:
- name: etcd-certs
hostPath:
path: /etc/kubernetes/pki/etcd
type: DirectoryOrCreate
- name: backup
hostPath:
path: /data/backup
type: DirectoryOrCreate
对 PV 的数据进行备份
对于 PV 来讲,备份就比较麻烦了。Kubernetes 自身不提供存储能力,它依赖各个存储插件对存储进行管理和使用。因此对于存储的备份操作,尤其是 PV 的备份操作,我们需要依赖各个云提供商的 API 来做 snapshot。
但是上述对于 Etcd 和 PV 的备份操作并不是很方便,我推荐你通过Velero来备份 Kubernetes。Velero 功能强大,但是操作起来很简单,它可以帮你做到以下 3 点:
-
对 Kubernets 集群做备份和恢复。
-
对集群进行迁移。
-
对集群的配置和对象进行复制,比如复制到其他的开发和测试集群中去。
而且 Velero 还提供针对单个 Namespace 进行备份的能力,如果你只想备份某些关键的业务和数据,这是一个十分方便的功能。
说了这么多,下满我们来看看 Velero 是如何备份 Kubernetes 的。
使用 Velero 对 Kubernetes 进行备份
这是 Velero 的架构图:
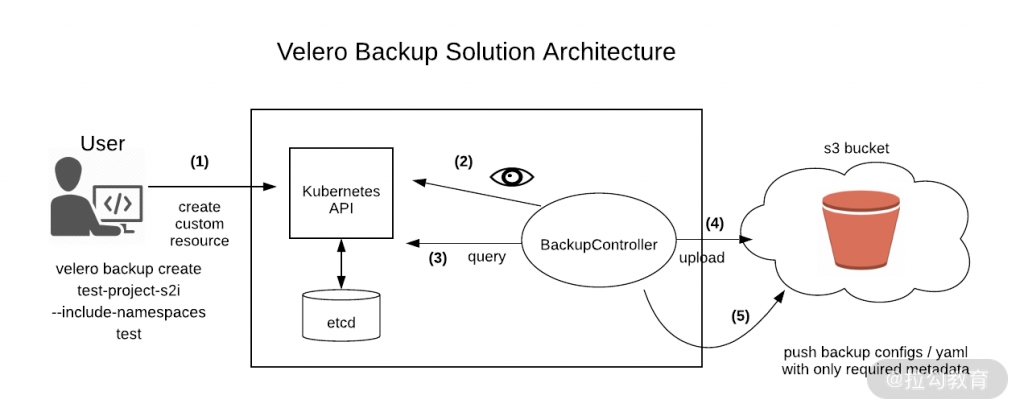
图 2:Velero 架构图
Velero 由两部分组成:
-
一个命令行客户端,你可以运行在本地,通过命令行完成对 Etcd 以及 PV 的备份操作;你也可以像使用 kubectl 操作 Kubernetes 资源一样备份 Kubernetes。
-
一个运行在 kubernetes 集群中的服务(BackupController),负责执行具体的备份和恢复操作。
我们来看看具体使用时的流程:
-
通过本地 Velero 客户端发送备份命令,比如图中的
velero backup create test-project-s2i --include-namespaces test,这条命令会向 APIServer 中创建一个 Backup 对象。 -
BackupController 会去监测并验证这个 Backup 对象的合法性,比如参数的定义。
-
BackupController 通过向 APIServer 查询相关数据开始备份工作。
-
BackupController 将查询到的数据备份到远端的对象存储中。
Velero 在 Kubernetes 集群中创建了很多 CRD (Custome Resource Definition)以及相关的控制器,通过这些进行备份恢复等操作。因此,对集群的备份和恢复,实质上是对这些相关 CRD 的操作。BackupController 会根据 CRD 来确定该进行何种操作。我会在《27 | K8s CRD:如何根据需求自定义你的 API?》中专门介绍 CRD 的使用。
Velero 支持两种关于后端存储的 CRD,分别是 BackupStorageLocation 和 VolumeSnapshotLocation。
-
BackupStorageLocation 主要用来定义 Kubernetes 集群资源的数据存放位置,也就是集群对象数据,而不是 PVC 和 PV 的数据。你可以从这个支持列表里面找到目前官方和第三方支持的后端存储服务,主要是以支持 S3 兼容的存储为主,比如 AWS S3、阿里云 OSS、Minio 等。
-
VolumeSnapshotLocation 主要用来给 PV 做快照,快照功能通常由 Amazon EBS Volumes、Azure Managed Disks、Google Persistent Disks 等云厂商提供,你可以根据需要选择使用各个云厂商的服务。或者你使用专门的备份工具Restic,把 PV 数据备份到Azure Files、阿里云 OSS 中去。阿里云目前已经提供了基于 Velero 的插件。
除此之外,BackupController 在工作过程中,还会创建其他的 CRD,主要用于内部的逻辑处理。你可以参考阿里云的文档进一步学习。
如果你没有阿里云的 OSS,或者集群是线下的内部集群,你也可以自行搭建 Minio,作为对象存储服务来代替阿里云的 OSS。你可以参考官方的文档进行详细的安装配置工作。
写在最后
在分布式的世界里,我们很难保证万无一失。当你在 Kubernetes 集群中部署越来越多的业务的时候,对集群和数据的灾备是非常有必要的。在今年 7 月份,我们常用的代码托管平台 Github 就发生了 Kubernetes 故障 ,导致了持续 4 个半小时的严重故障。所以,我建议对于关键性的业务数据,要记得时常备份。
那么,你对于 Kubernetes 的备份还有哪些想要了解的呢?欢迎在留言区留言。
作者:huangjiale
出处:https://www.cnblogs.com/huangjiale/p/17958424
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· winform 绘制太阳,地球,月球 运作规律
· 上周热点回顾(3.3-3.9)