02-高屋建瓴:Kubernete 的架构为什么是这样的?
通过上一课时的学习,我们已经对 Kubernetes 的前世今生有所了解。接下来,我们开始具体学习如何将 Kubernetes 应用到自己的项目中,首先就需要了解 Kubernetes 的架构。所以,在本节课程中,我们会一起学习 Kubernetes 的架构设计,以及背后的设计哲学。
Google 使用 Linux 容器有超过 15 年的时间,期间共创建了三套容器调度管理系统,分别是 Borg、Omega 和 Kubernetes。虽然是出于某些特殊诉求偏好先后开发出来的,但是在差异中我们仍然可以看到,后代系统中存在着前一代系统的影子,也就是说,它们之间传承了很多优良的设计。这也是为什么 Kubernetes 在登场之初,就可以吸引到诸多大厂的关注,自此一炮而红,名震江湖。
Kubernetes 的架构设计参考了 Borg 的架构设计,现在我们先来看看 Borg 架构长什么样?
Borg 的架构
在这里我们不打算深入讲解 Borg 系统的方方面面,如果你有兴趣,可以阅读 Google 在 2015 年发表的这篇 Borg 论文。
我们先来看看 Borg 定义的两个概念,Cell 和 Cluster。
Borg 用Cell 来定义一组机器资源。Google 内部一个中等规模的 Cell 可以管理 1 万台左右的服务器,这些服务器的配置可以是异构的,比如内存差异、CPU 差异、磁盘空间等。Cell 内的这些机器是通过高速网络进行连通的,以此保证网络的高性能。
Cluster 即集群,一个数据中心可以同时运行一个或者多个集群,每个集群又可以有多个 Cell,比如一个大 Cell 和多个小 Cell。通常来说尽量不要让一个 Cell 横跨两个机房,这样会带来一些性能损失。这也同样适用于 Kubernetes 集群,我们在规划和搭建 Kuberentes 集群的时候要注意这一点。
有了上面这两个概念,我们再来看看下面这幅 Borg 的架构图。
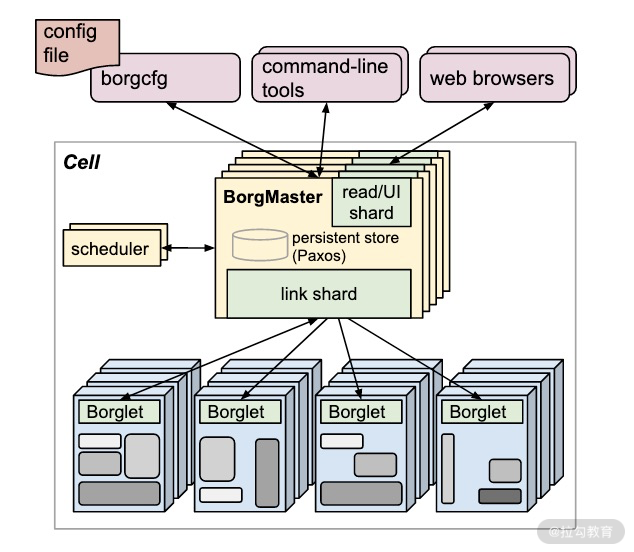
(图片来自[https://research.google/pubs/pub43438/])
Borg 采用了分布式系统中比较常见的 Server/Agent 架构,主要模块包括 BorgMaster、Borglet 和调度器,这些组件都是通过 C++ 来实现的。
Borglet 运行在每个节点或机器上,这个 agent 程序主要负责任务的启停,如果任务失败了,它会对任务进行重启等一系列操作。运行的这些任务一般都是通过容器来做资源隔离,Borglet 会对任务的运行状态进行监控和汇报。
同时,每个集群中会有对应的 BorgMaster。为了避免单点故障,满足高可用的需要,我们往往需要部署多个 BorgMaster 副本,就如我们图里面显示的那样。这五个副本分别维护一份整个集群状态的内存拷贝,并持久化到一个高可用的、基于 Paxos 的存储上。
通过 Paxos,从这 5 个 BorgMaster 副本中选择出一个 Leader,负责处理整个集群的变更请求,而其余四个都处于 Standby 状态。如果该 Leader 宕机了,会重新选举出另外一个 Leader 来提供服务,整个过程一般在几秒内完成。如果集群规模非常大的话,估计需要近 1 分钟的时间。
BorgMaster 进程主要用于处理跟各个 Borglet 进程进行交互。除此之外,BorgMaster 还提供了Web UI,供用户通过浏览器访问。
Borg 在这里面有个特殊的设计,BorgMaster 和 Borglet 之间的交互方式是 BorgMaster 主动请求 Borglet 。即使出现诸如整个 Cell 突然意外断电恢复,也不会存在大量的 Borglet 主动连 BorgMaster,所以就避免了大规模的流量将 BorgMaster 打挂的情况出现。这种方式由 BorgMaster 自己做流控,还可以避免每次 BorgMaster 自己重启后,自己被打挂的情形发生。
我们再来仔细看下架构图,你会发现 BorgMaster 跟 Borglet 之间还加了一层。这是因为 BorgMaster 每次从 Borglet 拿到的数据都是全量的,通过 link shard 模块就可以只把 Borglet 的变化传给 BorgMaster,减少沟通的成本,也降低了 BorgMaster 的处理成本。如果 Borglet 有多次没有对 Borgmaster 的请求进行响应,Borgmaster 就认为运行 Borglet 的这台机器挂掉了,然后对其上的 task 进行重新调度。
下面我们来看看 Kuberenetes 的架构。
Kubernetes 的架构
Kubernetes 借鉴了 Borg 的整体架构思想,主要由 Master 和 Node 共同组成。
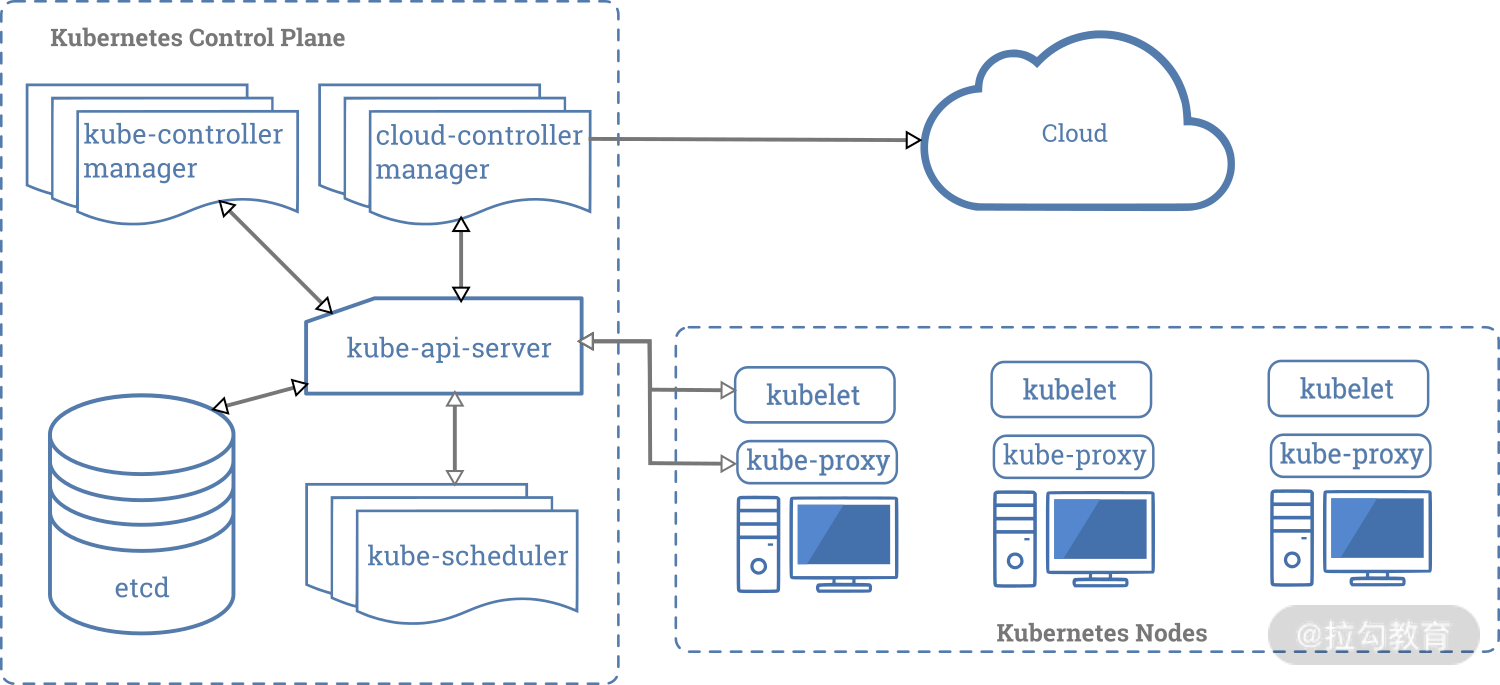
(官方的架构图)
我们需要注意 Master 和 Node 两个概念。其中 Master 是控制节点,部署着 Kubernetes 的控制面,负责整个集群的管理和控制。Node 为计算节点,或者叫作工作负载节点,每个 Node 上都会运行一些负载容器。
跟 Borg 一样,为了保证高可用,我们也需要部署多个 Master 实例。根据我的生产实践经验,最好为这些 Master 节点选择一些性能好且规格大的物理机或者虚拟机,毕竟控制面堪称 Kubernetes 集群的大脑,要尽力避免这些实例宕机导致集群故障。
同样在 Kubernetes 集群中也采用了分布式存储系统 Etcd,用于保存集群中的所有对象以及状态信息。有的时候,我们会将 Etcd 集群也一起部署到 Master 上。但是在集群节点资源足够的情况下,我个人建议可以考虑将 Etcd 集群单独部署,因为Etcd中的数据可是至关重要的,必须要保证 Etcd 数据的安全。Etcd 采用 Raft 协议实现,和 Borg 中基于 Paxos 的存储系统不太一样。关于 Raft 和 Paxos 这两个协议的差异对比,我们在这里就不展开讲了,你可以通过《Paxos 和 Raft 的前世今生》这篇文章了解一二。
Kubernetes 的组件
Kubernetes 的控制面包含着 kube-apiserver、kube-scheduler、kube-controller-manager 这三大组件,我们也称为 Kubernetes 的三大件。下面我们逐一来讲一下它们的功能及作用。
首先来看 kube-apiserver,它 是整个 Kubernetes 集群的“灵魂”,是信息的汇聚中枢,提供了所有内部和外部的 API 请求操作的唯一入口。同时也负责整个集群的认证、授权、访问控制、服务发现等能力。
用户可以通过命令行工具 kubectl 和 APIServer 进行交互,从而实现对集群中进行各种资源的增删改查等操作。APIServer 跟 BorgMaster 非常类似,会将所有的改动持久到 Etcd 中,同时也保存着一份内存拷贝。
这也是为什么我们希望 Master 节点可以性能好、资源规格大,尤其是当集群规模很大的时候,APIServer 的吞吐量以及占用的 CPU 和内存都要很大。APIServer 还提供很多可扩展的能力,方便增强自己的功能。我们会在后面的课程中慢慢介绍。
再来看Kube-Controller-Manager,它负责维护整个 Kubernetes 集群的状态,比如多副本创建、滚动更新等。Kube-controller-manager 并不是一个单一组件,内部包含了一组资源控制器,在启动的时候,会通过 goroutine 拉起多个资源控制器。这些控制器的逻辑仅依赖于当前状态,因为在分布式系统中没办法保证全局状态的同步。
同时在实现的时候避免使用过于复杂的状态机,因此每个控制器仅仅对自己对应的资源对象做操作。而且控制器做了很多容错处理,比如增加 retry 机制等。
最后来看Kube-scheduler,它的工作简单来说就是监听未调度的 Pod,按照预定的调度策略绑定到满足条件的节点上。这个工作虽说看起来是三大件中最简单的,但是做的事情可一点不少。
我们会在后续的课程里,专门讲 Kubernetes 的调度器原理,敬请期待。这个调度器是 Kubernetes 的默认调度器,可插拔,你可以根据需要使用其他的调度器,或者通过目前调度器的扩展功能增加自己的特性进去。
了解完了控制面组件,我们再来看看 Node 节点。一般来说 Node 节点上会运行以下组件。
-
容器运行时主要负责容器的镜像管理以及容器创建及运行。大家都知道的 Docker 就是很常用的容器,此外还有 Kata、Frakti等。只要符合 CRI(Container Runtime Interface,容器运行时接口)规范的运行时,都可以在 Kubernetes 中使用。
-
Kubelet 负责维护 Pod 的生命周期,比如创建和删除 Pod 对应的容器。同时也负责存储和网络的管理。一般会配合 CSI、CNI 插件一起工作。
-
Kube-Proxy 主要负责 Kubernetes 内部的服务通信,在主机上维护网络规则并提供转发及负载均衡能力。
除了上述这些核心组件外,通常我们还会在 Kubernetes 集群中部署一些 Add-on 组件,常见的有:
-
CoreDNS 负责为整个集群提供 DNS 服务;
-
Ingress Controller 为服务提供外网接入能力;
-
Dashboard 提供 GUI 可视化界面;
-
Fluentd + Elasticsearch 为集群提供日志采集、存储与查询等能力。
了解完 Kubernetes 的各大组件,我们再来看看 Master 和 Node 是如何交互的。
Master 和 Node 的交互方式
在这一点上,Kubernetes 和 Borg 完全相反。Kubernetes 中所有的状态都是采用上报的方式实现的。APIServer 不会主动跟 Kubelet 建立请求链接,所有的容器状态汇报都是由 Kubelet 主动向 APIServer 发起的。到这里你也许有疑惑,这种方式会不会对 APIServer 产生很大的流量影响?这个问题,我们同样会在后续课程里,给你一一解答。
当集群资源不足的时候,可以按需增加Node 节点。一旦启动 Kubelet 进程以后,它会主动向 APIServer 注册自己,这是 Kubernetes 推荐的 Node 管理方式。当然你也可以在Kubelet 启动参数中去掉自动注册的功能,不过一般都是默认开启这个模式的。
一旦新增的 Node 被 APIServer 纳管进来后,Kubelet 进程就会定时向 APIServer 汇报“心跳”,即汇报自身的状态,包括自身健康状态、负载数据统计等。当一段时间内心跳包没有更新,那么此时 kube-controller-manager 就会将其标记为NodeLost(失联)。这也是 Kubernetes 跟 Borg 有区别的一个地方。
Kubernetes 中各个组件都是以 APIServer 为中心,通过松耦合的方式进行。借助声明式 API,各部件通过 watch 的机制就可以根据各个对象的变化,很快地做出相应的处理操作。这里,你可以回到上一节课中,回顾一下声明式 API 。
写在最后
虽说 Kubernetes 跟 Borg 系统有不少差异,但是总体架构还是相似的。从Kubernetes的架构以及各组件的工作模式可以看到,Kubernetes 系统在设计的时候很注重容错性和可扩展性。
它假定有发生任何错误的可能,通过 backoff retry、多副本、滚动升级等机制,增强集群的容错性,提高 Kubernetes 系统的稳定性。同时对各个组件增加可扩展能力,保证 Kubernetes 对新功能的接入能力,让人们可以对 Kubernetes 进行个性化定制。
好的,这里这节课就结束了。从后面的课程开始,我们将深入实践并掌握 Kubernetes 的各种对象及使用技巧。
如果你对本节课有什么想法或者疑问,欢迎你在留言区留言,我们一起讨论。
作者:huangjiale
出处:https://www.cnblogs.com/huangjiale/p/17958368
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· winform 绘制太阳,地球,月球 运作规律
· 上周热点回顾(3.3-3.9)