HashMap和ConcurrentHashMap详解
引言
本文主要讲解,Java中hashMap和ConcurrentHashMap的原理内容。
HashMap
在java JDK 1.7之前 hashMap采用的是 数组+链表 的形式;而在 JDK 1.8 之后 hashMap 采用的是 数组+链表[单向/双向]+红黑树 的形式。
内存模型
hashMap内存模型内容,如下图所示:
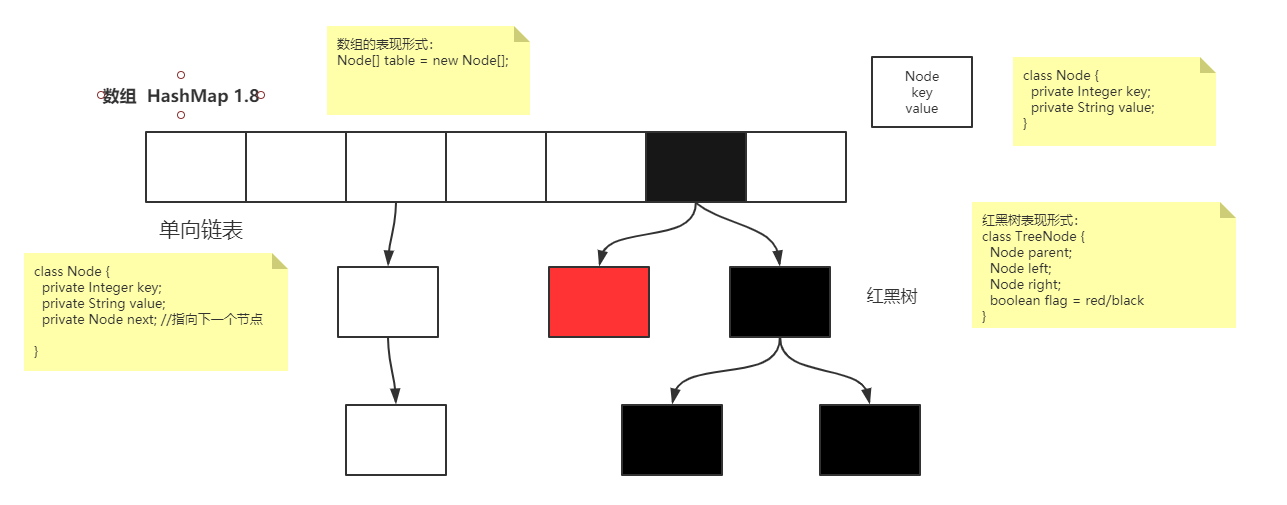
描述map.put(1, "Jamin");
- 得先创建一个数组:Node[] table = new Node(size);
- 根据key、value值,创建一个Node:new Node();
- 需要判断当前Node对象放在数组中的那个位置
- 随机算法: new Random.nextInt(size)----->链表太长,容易导致put和查询的效率变慢
- hash算法:Node节点下标的位置
- 可以拿到key的hash值 key.hashCode()
- 尽量减少hash算法的重复下标的可能性------>采用 %运算 hashCode()%(size-1) 或者 &运算 hashCode()&(size-1) 以及 hashCode高低16位 异或运算 hashCode()^(size-1)
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16) }
- 为保证hash算法的下标尽可能的不重复, 则数组的大小必定是2^n; 如果设定的数组大小非2^n, 则JDK会数组大小进行调整
- 根据index, 将Node对象存储在对应数组的位置
- 数组下标index的位置没有Node: 直接存放
- 数组下标index的位置有Node
- key值相同: 直接替换value值
- key值不相同: 以单向链表的形式进行存储(而当链表对象达到一定长度的时候, JDK则会对该链表进行转为 红黑树)
- 数组扩容----> 根据当前数据结构中Node节点的数量, 如果超过一定的数值标准(0.75倍)的时候, JDK 则会对数组进行扩容
- 数组Node迁移
- 遍历老数组的索引位置,找出索引位置不为空的Node
- 对于不为空的Node索引位置, 进行判断
- 没有Node---> next == null
- 有Node--> 链表的方式 hash&(newCap - 1)--->关注每个Node节点的hash倒数第(n+1)位是否为0 e,hash & n--->0. 新数组原来的位置 1.新数组原来的位置+2^n
ConcurrentHashMap
hashMap线程安全的设计原理
put整个过程中是否是线程安全?
在JDK 1.8中 使用 ConcurrentHashMap
- 初始化数组大小 (保证线程安全)--> CAS 无锁化的机制保障线程的安全性(乐观锁机制) [说明:变量值与内存中最新值比较是否相等,判断其修改权限]
- put-操作 (保证线程安全)
- synchronized --> 导致整个数组的数据都会被锁, 效率极其低下
- 数组下标位置为空的时候, CAS乐观锁机制
- 数组下标不为空的时候, 数组下标位置定制自定义锁(synchronized)
数组扩容会有线程安全的问题, 怎么解决?
当一个数组需要扩容的时候, 当线程T1 正在创建数组/数据迁移的时候; T2/3/4/5 线程 想来put数据, 那么数据允许put么?
no --> 不允许插入数据, 但会利用其它线程(T2/3/4/5)来帮助线程 T1 迁移
帮助迁移流程:
- 第一个线程负责创建新的数组
- 所有的线程领取各自的任务, 并且以(size)大小为单位的领取(从后往前)
真正的谦卑是对真理持续不断的追求。

