题目记录(一直更新
OI记录
P2568 GCD
题意:
给定正整数 \(n\),求 \(1\le x,y\le n\) 且 \(\gcd(x,y)\) 为素数的数对 \((x,y)\) 有多少对(\(n\leq10^7\))
题解:
注意,可以不用莫比乌斯反演,单纯的欧拉函数便可以解决,首先列出式子:
接着转化式子,gcd里的\(i,j\)同除\(p\),再换元一下:
然后我们可以观察到\(gcd(i,j)=1\)代表的是互质,如何转化到可以计算呢,我们假设\(j\)枚举到\(i\),这样就可以用欧拉函数,然后讨论一下改成这个就只是有序变为无序,然后会有2倍的差距,然后考虑\(i=j\)的时候会被统计两次但是因为\(gcd(i,j)=1\) 只有\(i=j=1\)时有贡献,在\(\sum_{p\in prime}\)这层循环下减个1,于是为:
然后发现这个\(\sum_{j=1}^{i}(gcd(i,j)=1)\)就是欧拉函数\(\varphi(x)\):
具体在程序中刚开始用欧拉筛预处理出来要用到的欧拉函数值和所有的质数,接着预处理出来一个前缀和。
最后枚举所有的质数,求\(2sumphi[n/p]-1\)。
因为这题始数学题,AC code较为简单:
#include<bits/stdc++.h>
#define int long long
#define N 10000009
using namespace std;
int n;
int phi[N],sumphi[N];
bool pri[N];
int prime[N],cnt;
int answ=0;
void euler()
{
phi[1]=1;
for(int i=2;i<=10000002;i++)
{
if(!pri[i]) prime[++cnt]=i,phi[i]=i-1;
for(int j=1;j<=cnt;j++)
{
if(i*prime[j]>10000002) break;
if(i%prime[j]==0){
pri[i*prime[j]]=1;
phi[i*prime[j]]=phi[i]*prime[j];break;
}
pri[i*prime[j]]=1;
phi[i*prime[j]]=phi[i]*phi[prime[j]];
}
}
for(int i=1;i<=10000002;i++) sumphi[i]=sumphi[i-1]+phi[i];
}
signed main()
{
scanf("%lld",&n);
euler();
for(int i=1;i<=cnt;i++)
{
if(prime[i]>n) break;
answ+=(2*sumphi[n/prime[i]]-1);
}printf("%lld",answ);
}
P1640 [SCOI2010] 连续攻击游戏
题意:
给定\(n\)个物品,每个物品有两个属性值,每种物品只能选取其中一个属性,并且每个物品只能用一次。现在要从属性\(1\)开始,选取物品,问最多能选取多少个。
题解:
二分图忘了,这道题是二分图板子,是用来锻炼二分图的。
二分图匹配的匈牙利算法有一个很棒的性质:前面已经被匹配过的点不会失配。然后我们进行套路的建图,每个物品连两条边到他的属性值上,然后以属性值作为右部点,依次跑二分图匹配,直到失配便终止循环。
值得一提的是,这道题有些不适合网络流解法,二分答案跑网络流会超时,但是可以玄学先增广序号在前的点,这样也能得到正确答案。
因为用的是匈牙利算法,所以代码简单:
#include<bits/stdc++.h>
#define N 1145141
using namespace std;
int match[N],n;
vector<int>tu[N];
bool vis[N];
stack<int>V;
bool dfs(int now)
{
for(auto too:tu[now])
{
if(!vis[too])
{
vis[too]=1;
V.push(too);
if(!match[too]||dfs(match[too]))
{
match[too]=now;
return true;
}
}
}
return false;
}
int read()
{
int ans=0;
char c=getchar();
while(c<'0'||c>'9') c=getchar();
while(c>='0'&&c<='9')
{
ans=10*ans+c-'0';
c=getchar();
}return ans;
}
int main(){
n=read();
for(int i=1;i<=n;i++)
{
int x=read(),y=read();
tu[10000+i].push_back(x);
tu[10000+i].push_back(y);
tu[y].push_back(10000+i);
tu[x].push_back(10000+i);
}
for(int i=1;i<=10000;i++)
{
while(!V.empty()){
vis[V.top()]=0;
V.pop();
}
if(!dfs(i)){
printf("%d",i-1);
return 0;
}
}
printf("10000");
}
容器 set 和 multiset
set 和 multiset 代表有序集合和可重有序集合,包含在 set 库中。
关于迭代器:
迭代器就是指向一个元素的指针,例如用 int 类型定义的 set 集合里指向开头元素的迭代器一般表示为:
set<int>::iterator it = s.begin();
it + 1 指向下一个元素,it - 1 指向上一个元素(如果这个集合中存在上一个或下一个元素的话)。
s.begin()是指向s开头元素的迭代器。s.end()是指向s末尾元素的下一个内存位置的迭代器,所以如果要查末尾元素,一般是引用s.end() - 1。
注意这里 +1 和 -1 的时间复杂度都是 O(log n)。
有何作用?除了遍历集合元素外,set 和 multiset 都是有序集合(默认从小到大,可以用定义优先队列的方法定义这个东西),所以这就相当于是一个平衡树了,是不是很棒?平衡树可以干很多事呢。
如何把迭代器换为可以直接输出的该元素的值?加个星号,即 *it。
可以用减法查看当前是第几个。
关于操作:
定义如 int 类型用 set<int> s 或 multiset<int> s。
具有以下基础操作:
s.clear()s.empty()s.size()s.insert(x)代表插入元素x,如果是重复的元素,set不会插入,multiset会插入。s.find(x)表示查找集合里等于该元素的迭代器(返回第一个),不存在返回s.end()。- 具有二分函数
s.lower_bound(x)和s.upper_bound(x),代表查询大于等于x和大于x的元素里最小的一个,返回迭代器。 s.erase(x)代表删除所有等于x的元素或者删除x迭代器所指的元素。特别注意的是,如果只删去一个等于x的元素,可以执行:
if((it=s.find(x))!=s.end()) s.erase(it);//代表先找指向x的迭代器,如果x存在,就删去
s.count()返回集合中等于x的元素个数。
上面函数的复杂度除了 s.count() 和 s.erase() 是 O(k + log n),其余都是 O(log n)。
当然,平衡树别写set,时间和正确性都容易炸(时间必炸)。
组合数预处理
先预处理\(C_{i}^{0}=1\)然后根据\(C_{i}^{j}=C_{i-1}^{j-1}+C_{i}^{j-1}\)递推出所有组合数:
for(int i=0;i<=3000;i++) c[i][0]=0;
for(int i=1;i<=3000;i++)
for(int j=1;j<=i;j++) c[i][j]=(c[i-1][j-1]+c[i][j-1])%MOD;
10.23正睿模拟赛T3记录
题意:
给定一张 \(n\)个点,\(m\)条边的有向无环图。
进行 \(q\)次询问,每次询问给定 \(s,t,l,r\)。问若只保留编号在$ [l,r]$ 之间的边,\(s\) 能否到达 \(t\)。
题解:
妙妙题。
先给给询问搞个编号,离线下来做。
首先我们要用\(bitset\)进行辅助记录,首先记录一个\(g[m]\),单个\(g[i]\)记录的是编号为\(i\)的边在所有询问里的存在情况(\(bitset\)存的)。
具体的计算我们搞一个扫描线,对于每一个询问,在边编号的\(tag\)上记东西,在\(l\)位置记上这个询问编号,\(r+1\)位置也记录这个询问编号,然后就定义一个\(bitset\) \(Q\),扫一遍这个\(tag\),每回先给\(Q\)在所有目前位置上所有询问编号在对应的位置取反,然后把这个\(Q\)赋值给对应的\(g[i]\)。
然后就是\(f[n]\)了,对于每一个结点,单个\(f[i]\)记录的是每一个询问的\(s_i\)在只能有当前询问存在的边时到这个点的连通性(同样用\(bitset\)存)。
首先初始化给每个询问的\(s_i\)的\(f[s_i]\)对应的关于本身\(s_i\)的存在性命名为1(因为自己肯定和自己连通嘛)。
然后考虑是DAG,我们可以转移,有边\((u,v)\),编号\(i\),可以使得\(f[u]\)贡献给\(f[v]\)一个$f[u] \(^\) f[v]$(贡献的形式是或),在拓扑排序的过程中转移,因为在所有通向自己的边处理完后,这个点也处理完了。
但是这样就是询问比较多,空间容易炸,但是因为询问和询问间不打扰,所有我们可以\(B\)个询问\(B\)个询问的处理,这样每个\(bitset\)的长度也就只有\(B\),空间也就不会炸,就处理完了。
最后就对于每个询问输出答案即可。
总结:
- 用\(bitset\)优化时间和运算
- 考虑在拓扑排序上进行\(dp\)转移
- 用扫描线思想处理问题
- 空间炸了如果里面各部分互不相干可以分块计算
- 多个数组联合计算
\(over\)
拉格朗日插值
还没记。
小纪录
关于树上面统计答案时,到了以\(u\)为根的子树上,假如这个统计答案的方式需要是从\(u\)出发的两个不同路径的贡献和的最大值,我们不仅可以把最大和次大的贡献给和一块,还可以不断更新单个从u出发的最大贡献过程中更新这个俩路径合并在一起的最大值,不如现在单个路径最大贡献计算到了\(v\)之前的(不包括\(v\)),我们计算经过\(v\)的单个路径和\(u\)目前单个路径最大贡献的和贡献即可,然后继续更新单个路径最大贡献。
线段树分治记录
更明白的应该说是在线段树上离线查询,适用于那种不支持删除但是支持撤销的东西可以用线段树来辅助,具体来说比如一个东西,你要加进去一个东西,过一段时间再删除这个东西,也就是说不是撤销,不妨为这个时间序列开一个线段树,每回区间操作都记录这个东西存在的区间,这样在线段树上就可以保证这个东西创建和删除可以在一块儿进行。
然后有些题目不会给你明示,就需要各种观察和转化,比如求对于每个元素我们就删除它求剩下的元素的答案,就可以把这些元素当成时间序列排一块,对于不删这个元素的两个(或一个)区间进行标记操作,就可以转化为多次撤销和增加然后求答案。
当然一些题目中那些不要局限在题目中的对哪个东西询问来盲目地进行线段树分治,可能不是对这玩意进行线段树分治,要勤进行转化。
比如P2056:
#include<bits/stdc++.h>
#define N 514514
#define int long long
using namespace std;
inline int read()
{
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9')
{
if(ch=='-')
f=-1;
ch=getchar();
}
while(ch>='0' && ch<='9')
x=x*10+ch-'0',ch=getchar();
return x*f;
}
struct node{
vector<int>tag;
}seg[N<<2];
vector<int>tree[N];
int ans[N];
int qua[N];
int n,q;
struct shupou{
int size[N],topp[N],wson[N],dep[N],faa[N];
void pou()
{
dfs1(1,1);
dfs2(1,1,1);
}
void dfs1(int now,int fa)
{
faa[now]=fa;
size[now]=1;dep[now]=dep[fa]+1;
for(auto too:tree[now])
{
if(too!=fa)
{
dfs1(too,now);size[now]+=size[too];
if(size[too]>size[wson[now]]) wson[now]=too;
}
}//cout<<wson[now]<<endl;
}
void dfs2(int now,int fa,int topnode)
{
topp[now]=topnode;
if(wson[now]!=0) dfs2(wson[now],now,topnode);
for(auto too:tree[now])
{
if(too!=fa&&too!=wson[now]){
//cout<<"xixi"<<endl;
dfs2(too,now,too);
}
}
}
int lca(int x,int y)
{
while(topp[x]!=topp[y])
{
if(dep[topp[x]]<dep[topp[y]]){
y=faa[topp[y]];
}else x=faa[topp[x]];
}
if(dep[x]>dep[y]) return y;
else return x;
}
int dis(int x,int y)
{
int lcaa=lca(x,y);
int rea=dep[x]+dep[y]-2*dep[lcaa];
return rea;
}
}callca;
struct dui{
int R=0,P=0;
}nownd;
stack<dui>S;
struct segfen{
void update(int now,int l,int r,int L,int R,int idd)
{
if(l>=L&&r<=R){
seg[now].tag.push_back(idd);
return;
}
int mid=(l+r)>>1;
if(L<=mid)
update(now<<1,l,mid,L,R,idd);
if(R>mid)
update(now<<1|1,mid+1,r,L,R,idd);
}
void calc(int now,int l,int r)
{
//cout<<l<<" "<<r<<endl;
for(auto no:seg[now].tag){
//cout<<endl<<endl;
S.push(nownd);
if(nownd.R==0&&nownd.P==0){
nownd={no,0};continue;
}
else if(nownd.R==0){
nownd.R=no;continue;
}
else if(nownd.P==0){
nownd.P=no;continue;
}
int dis1=callca.dis(nownd.R,nownd.P);
//cout<<nownd.R<<" "<<no;
int dis2=callca.dis(nownd.R,no);
int dis3=callca.dis(no,nownd.P);
int dismin=max(dis1,max(dis2,dis3));
if(dismin==dis2)
nownd={nownd.R,no};
else if(dismin==dis3)
nownd={no,nownd.P};
}
if(l==r){
if(nownd.R==0&&nownd.P==0){
ans[l]=-1;
}else if(nownd.R==0||nownd.P==0) ans[l]=0;
else ans[l]=callca.dis(nownd.R,nownd.P);//cout<<l<<" "<<r<<endl;
for(auto no:seg[now].tag) {
nownd=S.top();
S.pop();
}
return;
}
int mid=(l+r)>>1;
calc(now<<1,l,mid);
calc(now<<1|1,mid+1,r);
for(auto no:seg[now].tag) {
nownd=S.top();
S.pop();
}
}
}fen;
bool fl[N];
int lst[N],qu[N];
int cnt=1;
signed main()
{
n=read();
for(int i=1;i<n;i++)
{
int u,v;
u=read(),v=read();
tree[u].push_back(v);
tree[v].push_back(u);
}//cout<<"xixi";
callca.pou();
//cout<<callca.dis(4,1)<<endl;
q=read();
for(int i=1;i<=q;i++)
{
// cout<<"xixi"<<i<<endl;
char opt;
int opti;
cin>>opt;
if(opt=='C')
{ cnt++;
opti=read();
qu[i]=opti;
}else
qua[i]=cnt;
}
int tot=1;
for(int i=1;i<=q;i++)
{
if(qu[i]!=0)
{ tot++;
int opti=qu[i];
if(!fl[opti])
fen.update(1,1,cnt,lst[opti]+1,tot-1,opti);
if(!fl[opti]) lst[opti]=tot;
else lst[opti]=tot-1;
fl[opti]=!fl[opti];
}
}
for(int i=1;i<=n;i++){
if(!fl[i]){
if(lst[i]<cnt){
//cout<<i<<endl;
fen.update(1,1,cnt,lst[i]+1,cnt,i);
}
}
}
fen.calc(1,1,cnt);//cout<<ans[4]<<endl;
for(int i=1;i<=q;i++)
if(qua[i]) printf("%lld\n",ans[qua[i]]);
}
关于KTT
很牛的数据结构,对于最大子段和的区间查询和区间修改支持,对于线段树上每一个结点记录决策改变的值(注意是不仅是这个结点决策发生改变的值,而是它的线段树子树所有结点发生决策变化的最小值),每次进行区间加时,如果涉及到决策改变,暴力重建这一个树,否则就记下tag,然后给它所有的答案值加上这个值,决策减去这个值,其余就是正常的线段树操作,注意这里的tag下传不会涉及到改变决策,因为我们加的这个值如果没重构了化整颗子树都不会涉及到决策改变。
#include<bits/stdc++.h>
#define int long long
#define N 514514
#define INF 1145141919
using namespace std;
inline int read()
{
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9')
{
if(ch=='-')
f=-1;
ch=getchar();
}
while(ch>='0' && ch<='9')
x=x*10+ch-'0',ch=getchar();
//printf("%lld\n",x*f);
return x*f;
}
void write(int x)
{
if(x<0)
putchar('-'),x=-x;
if(x>9)
write(x/10);
putchar(x%10+'0');
return;
}
struct ele{
int le,val;
void operator +=(int v){
val+=le*v;
}
ele operator +(const ele& p) const{
ele res;
res.le=le+p.le;
res.val=val+p.val;
return res;
}
};
ele maxe(ele a,ele b){
if(a.val>b.val) return a;
else return b;
}
struct node{
ele lemax,rimax,maxv,sum;
int maxx;
int tag;
}tree[N<<2];
node cal(node aa,node bb)
{
node rean;
rean.lemax=maxe(aa.sum+bb.lemax,aa.lemax);
rean.rimax=maxe(aa.rimax+bb.sum,bb.rimax);
rean.maxv=maxe(maxe(aa.maxv,bb.maxv),aa.rimax+bb.lemax);
rean.sum=aa.sum+bb.sum;
return rean;
}
int n,q;
int ina[N];
struct KTT{
int jiao(ele a,ele b)//求决策交界点
{
if(b.le==a.le) return INF;
int pox=(a.val-b.val)/(b.le-a.le);
if(pox>=0){
return pox;
}
else {
return INF;
}
}
void push_up(int now)
{
tree[now].maxx=min(tree[now<<1].maxx,tree[now<<1|1].maxx);//考虑下面的影响
tree[now].maxx=min(tree[now].maxx,jiao(tree[now<<1].maxv,tree[now<<1|1].maxv));
tree[now].maxx=min(tree[now].maxx,jiao(maxe(tree[now<<1].maxv,tree[now<<1|1].maxv),tree[now<<1].rimax+tree[now<<1|1].lemax));//两个连起来均是计算更新maxv的决策
tree[now].maxx=min(tree[now].maxx,jiao(tree[now<<1].sum+tree[now<<1|1].lemax,tree[now<<1].lemax));
tree[now].maxx=min(tree[now].maxx,jiao(tree[now<<1].rimax+tree[now<<1|1].sum,tree[now<<1|1].rimax));
tree[now].lemax=maxe(tree[now<<1].sum+tree[now<<1|1].lemax,tree[now<<1].lemax);
tree[now].rimax=maxe(tree[now<<1].rimax+tree[now<<1|1].sum,tree[now<<1|1].rimax);
tree[now].maxv=maxe(maxe(tree[now<<1].maxv,tree[now<<1|1].maxv),tree[now<<1].rimax+tree[now<<1|1].lemax);
tree[now].sum=tree[now<<1].sum+tree[now<<1|1].sum;
// biz(now);
}
void make_tag(int now,int date){
tree[now].tag+=date;//cout<<"heiehi"<<endl;
tree[now].maxx-=date;//cout<<"heiehi"<<endl;
tree[now].lemax+=date;//cout<<"heiehi"<<endl;
tree[now].rimax+=date;//cout<<"heiehi"<<endl;
tree[now].maxv+=date;//cout<<"heiehi"<<endl;
tree[now].sum+=date;//cout<<"heiehi"<<endl;
}
void rebuild(int now,int l,int r,int v){
if(v>tree[now].maxx){
int mid=(l+r)>>1;
rebuild(now<<1,l,mid,v+tree[now].tag);
rebuild(now<<1|1,mid+1,r,v+tree[now].tag);
push_up(now);
tree[now].tag=0;
}else{
make_tag(now,v);
}
}
void push_down(int now){
if(tree[now].tag!=0){
make_tag(now<<1,tree[now].tag);
make_tag(now<<1|1,tree[now].tag);
tree[now].tag=0;
}
}
void updat(int now,int l,int r,int L ,int R,int date)
{
if(l>=L&&r<=R)
{
rebuild(now,l,r,date);
return;
}
push_down(now);
int mid=(l+r)>>1;
if(L<=mid)
updat(now<<1,l,mid,L,R,date);
if(R>mid) updat(now<<1|1,mid+1,r,L,R,date);
push_up(now);
}
node sear(int now,int l,int r,int L ,int R){
if(l>=L&&r<=R)
{
return tree[now];
}
push_down(now);
int mid=(l+r)>>1;
node rea;
if(L<=mid&&R>mid) {
rea=cal(sear(now<<1,l,mid,L,R),sear(now<<1|1,mid+1,r,L,R));
return rea;
}
if(L<=mid)
{
rea=sear(now<<1,l,mid,L,R);
return rea;
}
if(R>mid){
rea=sear(now<<1|1,mid+1,r,L,R);
return rea;
}
}
void build(int now,int l,int r)
{
if(l==r){
tree[now].maxx=INF;
tree[now].lemax=tree[now].maxv=tree[now].rimax=tree[now].sum={1,ina[l]};
// biz(now);
return;
}
int mid=(l+r)>>1;
build(now<<1,l,mid);
build(now<<1|1,mid+1,r);
push_up(now);
}
}ktt;
signed main()
{//cout<<"xixi111"<<q<<endl;
n=read(),q=read();
for(int i=1;i<=n;i++) ina[i]=read();
ktt.build(1,1,n);
for(int i=1;i<=q;i++)
{
int opt=read();
//cout<<"xio"<<endl;
int lq=read();//cout<<"xil"<<endl;
int rq=read();//cout<<"xir"<<endl;
if(opt==1){
int xx=read();//cout<<"x"<<endl;
ktt.updat(1,1,n,lq,rq,xx);
}else{
write(max(0ll,ktt.sear(1,1,n,lq,rq).maxv.val));
puts("");
}
}
}
P2949
贪心,着重理解一下证明,记录一下,策略是按照开始时间排序,每回加入任一可以加入的栅栏,这样为何是正确的?每个栅栏只有两个状态相关:结束时间和编号,编号是无所谓的,现在首先考虑目前2个牛,要加入一个栅栏有哪些情况:
- 两个牛时间不矛盾,肯定是开始时间早的在前
- 两个牛时间矛盾,必定会再开一个栅栏,而这个新的栅栏结束时间和目前这个栅栏这个的结束时间都会更新,两个栅栏状态必定是两个牛的结束时间,所以两个栅栏除编号以外是没有区别的,所以加入谁是无所谓的,我们为了方便和第一条保持一致,不妨先加入开始时间早的。
然后这个贪心策略就出来了。
反悔贪心
就是先搞出来一种贪心的想法,但是这个贪心有可能不对然后再对这个想法设计一个可撤销的想法。
然后有例题:在n个数中选出至多k个数,且两两不相邻,并使所选数的和最大。
这个题目我们首先想出来的贪心是从大到小依次选择,然后遇到不能选的就不能选,但是这个贪心是错的,所以就需要撤销,考虑为啥是错的,比如3个数3 5 4 1,只选两个数只能选出来5和1,但是答案应该是3和4,那是因为刚开始时就把3和4给否掉了,所以选不了。
可以看出来这是选了一个数后没办法再选周围的数(两种数没法同时取)导致的,如果我们让它可以选周围的数呢?首先我们如果让它选了周围的数,它们周围的数也不可以再选了,同样如果它们周围的数被选了,这个周围的数也不可以再选。
注意这个周围并不是相邻,而是因为取了一个数而导致没法再取的数,就是两种数没法同时选的意思,我们把这个影响考虑到
然后就有了一个非常神器的做法:
首先,我们先搞一个堆对于序列上的数,然后依次从大的取,对于取到的每一个数,我们先把它右边第一个没有被标记的数字和左边第一个没有被标记的数打上标记,然后弹出此数,并且再入队两个周围的数的和-现在的数,同时这个刚入队的数代替原来的数占据在序列上。
注意如果我们选到入队的这个数,结合之前选的,二者相加就是两个周围的数的和,即撤销了之前的操作。
被标记的两个数字其实就是周围的数,是两边周围因为现在的数绝对不可以取的数,为啥?这是因为现在的数和周围的数之间隔开的被标记的数的最左边和最右边是由现在的数或者周围的数产生的或由中间的数产生的,我们以周围的数在左边为例:
如果是由现在的数或者周围的数产生的:那么说明其中有一个数已经被选了几次,可以知道最后一次选的标记一定是因此产生的最左或最右标记(在这个数的另一端),也就是说如果选了这个数相当于去选了这个最左或最右的数,诶!然后就知道这两个数不能同时选,要不然就会产生相邻的选数。
如果石油中间的数产生的,那么这个中间的数(最底层的)是由谁产生的呢?肯定也是由周围的数或现在的数产生的,要不然这个数就会由别的中间的数产生的了,跟上一个一样的到理,其中有一个数肯定就会被选过一次,然后若是选了这个数,就会导致这个中间的数被选,然后因为这个中间的数标记了别的数,又会选别的数,依次类推最终还是会选到最右或最左,所以不可以同时选。
诶,然后这个的正确性就出来了。
带权并查集
不想写了P2024
种类并查集
不想写了P2024
KMP算法的性质运用记录
KMP算法运算最长border。
注意如果border长度大于字符串长度一半,即重叠了,这是有很多有趣的性质的
查找最小循环节:如果是循环的字符串了化,这个就等于字符串长度-border,注意此时border长度大于等于字符串长度一半。
重叠的话的第一个不重叠的后继border可以作为后面继续扩展的:
首先肯定是有下一个有正值的\(border[border[now]]\),因为重叠了的缘故,所以退一下就可以知道一定有一个后继border长度为\(\frac{2border[now]-lens}{2}\),即border重叠的部分,它必然是第一个不重叠的后继border,因为画图推导可以发现如果不是现在border就可以扩展变为更大的border。
考虑两种可能:
- 下一个的border是直接扩展上一个的border,这种情况下推一下就可以知道这样我们必然有的后继border也一定会往后扩展。
- 下一个border扩展时是需要后退,这个就显然可以了,因为后退的第一个就是我们必然有的后继border了。
这个结论可以用于动物园这道题求解。
关于hash:挑了一个专属于自己的质数:1000000931(1e9+931)
关于EXKMP运用:
EXKMP中lcp重合也有类似于KMP的性质,具体来说如果循环节长度为i,循环长度就是:
二分:
当l=mid时,mid取(l+r+1)>>1,否则(l+r)>>1
P4287:
O(n)算法关键在于注意到对于\(ll[i]\)和\(rr[i]\)的处理,注意到不用暴力\(O(n^2)\)扩展,注意一下扩展的关键点就可以,因为别的点都可以从关键点扩展来。
小记录:
char *s在函数里用strlen(s),不能用length()
线段树合并
两颗值域一样的权值线段树,要把它们的信息合并,我们就可以来进行线段树合并。
具体来说,我们支持一个操作,使得一个根为x的与一个根为y的合并,采用递归的方式进行合并,遇到其中一个结点为空的情况,返回另外一个结点,合并到叶子结点,合并y的信息到x,然后返回x,其余情况按线段树递归下去,返回x。
总而言之,合并俩线段树,返回根。实际上总体上看是y合并到x上,只有某个上面x这个没结点,就可以直接接到y,也只有这种情况会返回y。
合并操作代码如下:
int merge(int x,int y,int l,int r)
{
if(!x) return y;
if(!y) return x;
if(l==r){
//此处叶子合并操作
return x;
}
int mid=(l+r)>>1;
segtree[x].lson=merge(segtree[x].lson,segtree[y].lson,l,mid);
segtree[x].rson=merge(segtree[x].rson,segtree[y].rson,mid+1,r);
push_up(x);
return x;
}
一次合并的操作最差是\(O(nlogn)\),所以线段树合并用于那些东西由下而上地递归着合并到一起,一般用于在树结构上做线段树合并,正常来说均摊下去就是\(O(mlogn)\)。
所以必定要用动态开点线段树。
然后注意初始化时对于原本树上的每一个结点都初始化一个root,自然动态开点的cnt也要变化。
最后统计答案在dfs过程中统计即可。
下面是luogu上线段树合并模版的dfs部分:
void dfs(int now,int fa){//在原本的树上进行
for(int to:tree[now])
{
if(to==fa) continue;
dfs(to,now);
merge(root[now],root[to],0,100001);//合并
}
for(dat te:val[now]) update(root[now],0,100001,te.id,te.date);//更新关于这个点的答案
ans[now]=segtree[root[now]].ans;
}
线段树分裂
线段树既然可以合并也可以分裂,当然也是用在权值线段树上。
我们给定一个权值线段树,要分裂为两个线段树,一个是前k个数的权值线段树,一个是剩余的数的权值线段树。
我们可以直接暴力
可以采用类似用FHQ treap的方法进行分裂,仔细推导一下就可以知道,代码关键如下
并且注释十分细心qwq
void split (int x,int &y,ll k) {
//按照k值分裂,小于等于k的在x里,分为x和y,x为原树
if(x==0) return;
//x为空结点时直接返回
ll v=val[ch[x][0]];
//首先要明确的是,分裂的是线段树,所以x与y的结点位置上一定重合(除非x为空),y也一定是新的结点0
y=newnod();
if(k>v) split(ch[x][1],ch[y][1],k-v);
else swap(ch[x][1],ch[y][1]);
//对于k<v或者k=v来说x的左边都被y分裂出去了,相当于x左边变为空,y左边变为x的左边,相当于调换结点(y原本为空)
if(k<v)
//代表还要分裂右边的
split(ch[x][0],ch[y][0],k);
//上面是分裂,下面就是分裂后对这个结点的操作,x这个树就是k,y这个就是val[x]-v
val[y]=val[x]-k;
val[x]=k;
return;
}
关于一些常见却难查的报错
-
define int long long 时出现[Error]expected initializer before 'long',这可能表明后面的代码有个 int 变量 后没有跟分号,其余define同理
- 特别注意函数的返回值写没,比如int形的函数不返回值是不会报错但是会RE
插头DP记录
注:只学了思想,代码及实现NOIP之后再学和写(要是NOIP不寄了话)
插头DP,来自神犇CDQ的论文[《基于连通性状态压缩的动态规划问题》](NOI-papers/国家集训队2008论文集/Day2/3.陈丹琦《基于连通性状态压缩的动态规划问题》 at master · bojieli/NOI-papers · GitHub)。
采用了插头和轮廓线的思维,考虑解决如下问题:
给出 \(n\times m\) 的方格,有些格子不能铺线,其它格子必须铺,形成一个闭合回路。问有多少种铺法?(\(n,m\le 12\))。
先来介绍轮廓线,对于方格上的每一个格子,它都具有一个不一样的轮廓线,包含了这个格子本身左边的线,这个格子左边所有格子的下面的线还有这个格子上面的那一行在这个格子右边的格子的下面的线(包括格子本身正上方的),这如下是某个轮廓线:
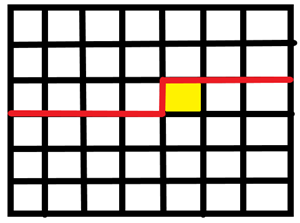
然后我们来说一下插头是啥,注意我们是构成闭合回路,所以考虑闭合回路中每个格子的状态,考虑穿过这个格子的上下左右四个方向,必定穿过其中两个,我们考虑把这两个的方向定为从中间向外(不是闭合回路方向,只是定义方便而已),这就倆东西就叫插头。
然后我们看一下如果只保留碰到轮廓线的插头,会发生啥。
一条轮廓线可以分为\(m+1\)段(除了这个格子本身左边的线,其余m条在下面的线),于是显然每段会存在碰到的插头或者不存在。
但是这样我们还需要更进一部,使得符合题目的要求,我们可以发现如果仅考虑轮廓线之上的,我们连的线里,在这个轮廓线分成的段里设\(a<b<c<d\),不可能出现\(a\)连\(c\),\(b\)连\(d\)的情况,这样闭合回路重合,不满足题目要求,我们也可以知道对于合法的情况,每一个碰到的插头的段都会有一个与它相连的被碰到插头的段,出来结尾结点的轮廓线上面会出现若干个连通但不闭合的线,每个线的两头都碰到轮廓线。
这样像什么?对像括号,左边匹配右边,匹配的连线又不能相交,这样我们针对于轮廓线的每一段,定义三种状态:
- 0 没有碰到插头
- 1 碰到插头,且位于目前连通的线的左边
- 2 碰到插头,且位于目前连通的线的右边
插头DP首先是一种状压DP,定义一个dp为\(dp[i][j][state]\)。你问state是啥?这个就是轮廓线的状态,前面那么多的预备设计出轮廓线的状态就是为了dp,同其它所有状压dp一样,只用按照dp的递推思路按照从上到下,从左到右的顺序分类讨论对于每一个状态对下一个状态的贡献并累加。(讨论对轮廓线现在转折的那个结点)
需要注意的是只有到了最后的点才用分类讨论本结点上面状态是2,左边状态是1的情况,这是把回路闭合的情况,因为只有一条闭合回路,只用在最后闭合。自然,统计答案也只用这个状态统计。
注意设计状态中时间没有问题,空间会爆,除了要滚动外,也要采用哈希链表的思路,每次若加入一个新的状态就加入哈希表里。
还有一道题P5074去掉了只有一个闭合回路的条件,直接不用考虑结尾在哪里,每个结点都可以考虑分类讨论本结点上面状态是2,左边状态是1的情况,然后累加答案把这种状态的答案都累加一遍。
似乎P5074有更简单的插头DP思路。
引用cdq论文结尾的话:
\(在解题的过程中,要抓住问题的主要特征,多思考,多尝试,才能 做的越来越好,优化是无止境的\)
P2042 [NOI2005] 维护数列
注:不想敲代码了,写题解代表我思考了,之后心不静时可以当作FHQ treap综合板子来写
题意:
请写一个程序,要求维护一个数列,支持以下 \(6\) 种操作:
| 编号 | 名称 | 格式 | 说明 |
|---|---|---|---|
| 1 | 插入 | \(\operatorname{INSERT}\ posi \ tot \ c_1 \ c_2 \cdots c_{tot}\) | 在当前数列的第 \(posi\) 个数字后插入 \(tot\) 个数字:\(c_1, c_2 \cdots c_{tot}\);若在数列首插入,则 \(posi\) 为 \(0\) |
| 2 | 删除 | \(\operatorname{DELETE} \ posi \ tot\) | 从当前数列的第 \(posi\) 个数字开始连续删除 \(tot\) 个数字 |
| 3 | 修改 | \(\operatorname{MAKE-SAME} \ posi \ tot \ c\) | 从当前数列的第 \(posi\) 个数字开始的连续 \(tot\) 个数字统一修改为 \(c\) |
| 4 | 翻转 | \(\operatorname{REVERSE} \ posi \ tot\) | 取出从当前数列的第 \(posi\) 个数字开始的 \(tot\) 个数字,翻转后放入原来的位置 |
| 5 | 求和 | \(\operatorname{GET-SUM} \ posi \ tot\) | 计算从当前数列的第 \(posi\) 个数字开始的 \(tot\) 个数字的和并输出 |
| 6 | 求最大子列和 | \(\operatorname{MAX-SUM}\) | 求出当前数列中和最大的一段子列,并输出最大和 |
首先如果只有前五种操作是容易的(吧?),直接fhq treap并支持tag操作和信息上传下传还有信息记录。
那么最后一个操作呢?最后一个操作可以利用套路的求最大子段和的方法进行上传,那么关于3,4的区间修改咋办?对于3的修改来说只需要每个每个信息都加对应数就行。
对于4呢?观察到最大子段和是不变的,但是合并后如何上传呢?只需要把最大前后缀和交换就好,然后我们就可以很棒地维护了。
但是码量是真大(之后再打
壮哉我大FHQ treap。
基础数论复习(noip考纲内的)记录
筛法:
埃式筛:
每次到一个质数,都把这个质数的所有倍数都标记上是合数。注意可以有大幅度的优化,首先可以知道遍历到质数p时,其实\(p^2\)之前的数已经被筛过了,所以每次遇到质数时可以直接从\(p^2\)开始标记合数,进一步的,我们若是想筛出\(n\)以内的,只需要遍历\(i^2\le n\)的\(i\)即可,但是值得注意的是,这个优化仍然是常数优化,因为埃氏筛的时间耗费在质数上面,而质数分布是\(log\)级别的,\(\log n^{\frac{1}{2}}=\frac{1}{2}\log n\)显然是常数优化。
复杂度:\(O(n\log \log n)\)
欧拉筛:
更好的筛法,每一个合数都存在一个最小质因数,根据这个性质,我们考虑每次遇到一个数考虑乘上一个质数变成一个合数,并且要求这个质数作为这个合数的最小质因数,显然我们只需要扫描目前这个数之前的所有质数直到这个数可以被这个质数整除,另外注意范围。
复杂度:\(O(n)\)
exgcd:
扩展欧几里德算法,用于求\(ax+by=m\)的整数解,首先判断有解运用裴蜀定理:\(ax+by=m\)有解当且仅当\(m\)是\((a,b)\)(\(a\)和\(b\)的最大公约数)倍数。
然后设最大公约数\(d=(a,b)\),化为\(\frac{ad}{m} x+\frac{bd}{m} y=d\)(先别考虑这个系数整除问题,后面解释明白了),两边同乘\(\frac{d}{m}\),我们另\(x'=\frac{d}{m}x,y'=\frac{d}{m}y\),可以知道\(ax'+by'=d\)肯定有整数解,假设解出整数解后就可以求出\(x=\frac{m}{d}x',y=\frac{m}{d}y'\),有了前面的条件可知这俩肯定也都是整数,然后\(ax+by=m\)就求出来了。
所以我们只用解决\(ax+by=(a,b)\)的整数解就好。
exgcd是解决这个的算法,考虑我们有\((a,b)=(b,a\mod b)\),还有\(a\mod b=a-\lfloor\frac{a}{b}\rfloor b\)。
于是,考虑我们已经解出了\(bx+(a-\lfloor\frac{a}{b}\rfloor b)y=d\)的解,这个式子由上述考虑可知一定成立,我们展开,可以发现\(ay+b(x-\lfloor\frac{a}{b}\rfloor y)=d\),于是我们就可以用我们解出的解直接套出来\(ax+by=(a,b)\)的解。
然后这样就可以不断递归,考虑递归的边界,首先不管\(a,b\)大小,经过一层递归后都有\(b<a\),所以最后递归的边界不妨设为\(b=0\),这个时候我们取\(x=a,y=0\)即可(即使初始时\(a=0\),一层递归后b也会为0)。
然后这就是exgcd的内容。
最后我们取\(x=\frac{m}{d}x',y=\frac{m}{d}y'\)即可得出\(ax+by=m\)的特解。
需要注意的是,求出特解后,其余所有的解都会满足这个形式:
欧拉函数:
\(\varphi(x)\)代表\(1-x\)中和\(x\)互质的数,然后欧拉函数为积性函数,\(p\)和\(q\)互质时有如下性质:
同时当\(x\)是质数的幂次\(x=p^k\)时:
这是因为一共有\(p^{k-1}\)个数为\(p\)的倍数,一共有\(p^k\)个数,减一下就是。
所以我们\(x=p_1^{a_1}p_2^{a_2}p_3^{a_3}……\),就可以有:
所以可以通过分解质因数求欧拉函数。
值得注意得是,可以通过欧拉筛求最小质因数的唯一性,线性求出一定范围内的所有数的欧拉函数。
然后值得注意的还有,可以观察到,一个数的欧拉函数不用知道分解质因数之后每一个质数分别出现多少次,只需得出有哪几种质数即可,所以对于欧拉函数中遇到\(i\mod prime[j]=0\)时直接\(phi[i\times prime[j]]=prime[j]\times phi[i]\)。
欧拉函数还有一个值得注意的和函数性质:
这个可以用于高级的杜教筛中
欧拉定理:
若\((a,m)=1\),则\(a^{\varphi(m)}\equiv1(mod\enspace m)\)。
费马小定理:
欧拉定理的推论,若\((a,m)=1\),则\(a^{m-1}\equiv1(mod\enspace m)\)。
乘法逆元:
\(x\)的模\(m\)意义下的逆元\(x^{-1}\)指使得\(x^{-1}x\equiv1(mod\enspace m)\)。
解法?通用解法是把同余式展开后可以使用exgcd算法解出。
而在m和x互质的情况下,我们根据费马小定理有逆元可以是\(x^{m-2}\)。
用快速幂求就好。
用于除法取模很棒。
小性质:\(p\)为素数时,\(a\)为自身的逆元是,即\(a^2\equiv 1(mod \enspace p)\)时,\(a\equiv1(mod \enspace p)\)或\(a\equiv1(mod \enspace p)\)
逆元线性求法:
值得注意的是,逆元也有求所有数的线性求法,额,还是直接记线性求法的公式吧:
初始化\(inv[1]=1\),其余递推式为:
威尔逊定理:
当且仅当\(p\)为质数时,\((p-1)!\equiv -1(mod \enspace p)\),表明了\(p\)可以被\((p-1)!+1\)可以被\(p\)整除。
进一步知道:
- \((p-1)!\enspace mod \enspace p=p-1\)
- \((p-1)!=pq-1(q\in \mathbb{Z})\)
EXCRT:
考虑单个同余方程\(ax\equiv b(mod\enspace m)\)的特解解只需要展开同余式然后用exgcd求解就好,即\(ax+my=b\),然后显然有解是\(b\)为\((a,m)\)的倍数。
用逆来考虑,同余式的解为\(x=a^{-1}b(mod \enspace m)\)。
所以所有单个有解的同余方程组都可以化为\(x\equiv a(mod\enspace m)\)。
那么对于多个同余方程的同余方程组如何解?如下:
中国剩余定理:我们对于\(m\)互相互素的情况,有整数解,则解为:
但是如果\(m_1,m_2,m_3……\)之间不互素呢?
用扩展中国剩余定理,即EXCRT,也叫迭代法,考虑合并两个同余方程组如何合并:
先展开为等式:
最后带入\(y_2\)的最小值,得出对应的\(x\)值\(x'\),则解为:
快速乘&龟速乘
适用用求\(ab\mod m\),\(m\)比较大,使得\(ab\)会爆long long的情况
注意如下ll=long long,ld=long double,ull=unsigned long long
龟速乘:
typedef long long ll;
ll mul (ll a, ll b, ll mod) { // 防止爆long long
if(b < 0) a = -a, b = -b;//防止b为负数的情况
ll s = 0;
for (;b; b >>= 1, a = (a + a) % mod)//每回b向右移动以为,a相应的乘2,当遇到末尾有贡献时,就有贡献
if (b & 1) s = (s + a) % mod;
return s;
}
快速乘:
inline ll ksc(ll x,ll y,ll p){
ll z=(ld)x/p*y;
ll res=(ull)x*y-(ull)z*p;
return (res+p)%p;
}
另外可以中途用int128吗(但别用
P1099&P2491
这个首先重要的是你可以推出来这个树网的核只能位于树的直径里,且任意一条直径上都可以出来一个等价的核,所以我们只需要考虑在一条直径上来计算就可以。
考虑这条直径是那一条,直接使用两次dfs即可。
接下来有很多做法。
考虑枚举两个点并且计算价值,\(O(n^3)\),考虑核肯定是最长长度的,所以枚举一个点,计算另一个点在哪里再计算价值,\(O(n^2)\),这俩做法都可以卡过简单的P1099。
那么对于加强版的P2491,我们该咋做。
实际上有两个做法
二分答案:
观察到这个是否有核具有某偏心距小于等于某值具有单调性,于是二分偏心距。
我们check偏心距mid,那么如何check?check是否有核的偏心距小于等于某值。
先说方法:
设直径两端点为\((u,v)\),我们找直径上距离\(u\)最远的小于mid的点\(p\),距离距离\(v\)最远的小于mid的点\(q\)。
然后取\(p-q\)为核,计算偏心距,看是否满足小于等于mid。
再说原理:
首先两边端点贡献的偏心距值一定都是mid,如果不是就代表有更长的路径,就不是直径了。
那么为何是选择这个为核?
我们考虑反证,不选择这个为核:
- 对于距离小于\(p-q\)的核,这样两边偏心距至少有一个大于mid,肯定不满足。
- 对于距离等于\(p-q\)的核,只能在这个位置,因为如果移动,也是两边偏心距至少有一个大于mid
- 对于距离大于\(p-q\)的核,肯定包含\(p-q\),而两边贡献的值虽然小于等于mid,但是中间的贡献曾多,就劣于了\(p-q\)。
\(Q.E.D\)
单调队列:
可以转化为滑动窗口问题,先随意定义一个方向,对于直径上的每一个点都存在一个两个值,一个是核包括这个点时沿着直径方向两边的贡献的偏心距(也就是这个方向上子树所有点距离这个点的距离),一个是这个点其它子树的偏心距(不包括在直经上的儿子子树),然后我们相当于对每个点的其它子树偏心距滑动一个窗口,每回求RMQ,然后每回得到的值再和两头端点的直径方向偏心距求max,最后答案就是所有值的min。
然后这样就可以\(O(n)\)的时间复杂度求出来答案。
总结:
脑残没推出来第一条性质,寄(),所以勤从性质入手。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号