

NLP入门系列四:Tensorflow2.0+Keras实现seq2seq+Attention模型的对话系统
本文主要是利用Tensorflow中keras框架记录简单实现seq2seq+Attention模型的过程,seq2seq的应用主要有问答系统、人机对话、机器翻译等。代码中会用一个中文对话数据简单测试。
seq2seq模型介绍
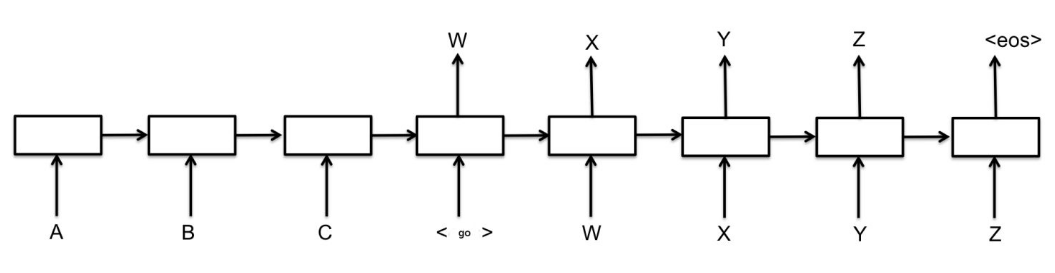
seq2seq模型主要有两个部分Encoder和Decoder,Encoder负责将输入序列编码,Decoder负责解码输出序列。最简单的seq2seq模型图:
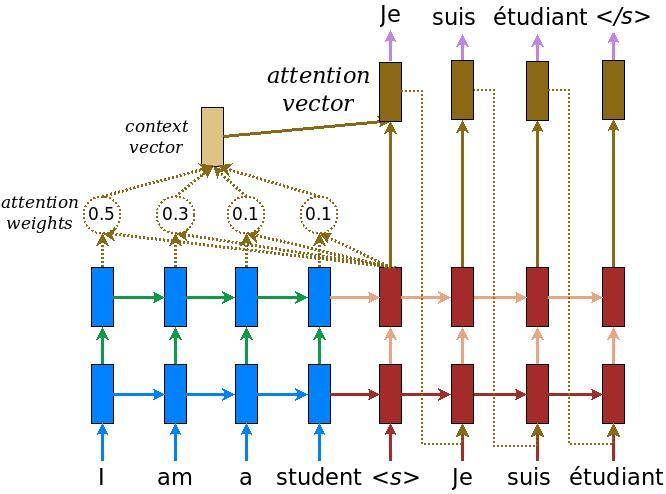
基于注意力机制的seq2seq模型。
Keras实现seq2seq+Atttention模型
本文的实现是基于Tensorflow 2.0中的keras,也可以用原始的keras也可以,如果用原始的keras,需要自己实现Attention层。
详细代码和数据:https://github.com/huanghao128/zh-nlp-demo
Encoder部分
encoder部分就是一个标准的RNN/LSTM模型,取最后时刻的隐藏层作为输出。我们用tensorflow.keras.models定义Encoder为一个sub model。
先导入tensorflow.keras的常用包。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import backend as K
from tensorflow.keras import activations
from tensorflow.keras.layers import Layer, Input, Embedding, LSTM, Dense, Attention
from tensorflow.keras.models import Model
encoder部分结构,主要就是一个Embedding层,加上LSTM层。
class Encoder(keras.Model):
def __init__(self, vocab_size, embedding_dim, hidden_units):
super(Encoder, self).__init__()
# Embedding Layer
self.embedding = Embedding(vocab_size, embedding_dim, mask_zero=True)
# Encode LSTM Layer
self.encoder_lstm = LSTM(hidden_units, return_sequences=True, return_state=True, name="encode_lstm")
def call(self, inputs):
encoder_embed = self.embedding(inputs)
encoder_outputs, state_h, state_c = self.encoder_lstm(encoder_embed)
return encoder_outputs, state_h, state_c
Decoder部分
decoder部分结构,有三部分输入,一是encoder部分的每个时刻输出,二是encoder的隐藏状态输出,三是decoder的目标输入。另外decoder还包含一个Attention层,计算decoder每个输入与encoder的注意力。
class Decoder(keras.Model):
def __init__(self, vocab_size, embedding_dim, hidden_units):
super(Decoder, self).__init__()
# Embedding Layer
self.embedding = Embedding(vocab_size, embedding_dim, mask_zero=True)
# Decode LSTM Layer
self.decoder_lstm = LSTM(hidden_units, return_sequences=True, return_state=True, name="decode_lstm")
# Attention Layer
self.attention = Attention()
def call(self, enc_outputs, dec_inputs, states_inputs):
decoder_embed = self.embedding(dec_inputs)
dec_outputs, dec_state_h, dec_state_c = self.decoder_lstm(decoder_embed, initial_state=states_inputs)
attention_output = self.attention([dec_outputs, enc_outputs])
return attention_output, dec_state_h, dec_state_c
Encoder和Decoder合并
encoder和decoder模块合并,组成一个完整的seq2seq模型。
def Seq2Seq(maxlen, embedding_dim, hidden_units, vocab_size):
"""
seq2seq model
"""
# Input Layer
encoder_inputs = Input(shape=(maxlen,), name="encode_input")
decoder_inputs = Input(shape=(None,), name="decode_input")
# Encoder Layer
encoder = Encoder(vocab_size, embedding_dim, hidden_units)
enc_outputs, enc_state_h, enc_state_c = encoder(encoder_inputs)
dec_states_inputs = [enc_state_h, enc_state_c]
# Decoder Layer
decoder = Decoder(vocab_size, embedding_dim, hidden_units)
attention_output, dec_state_h, dec_state_c = decoder(enc_outputs, decoder_inputs, dec_states_inputs)
# Dense Layer
dense_outputs = Dense(vocab_size, activation='softmax', name="dense")(attention_output)
# seq2seq model
model = Model(inputs=[encoder_inputs, decoder_inputs], outputs=dense_outputs)
return model
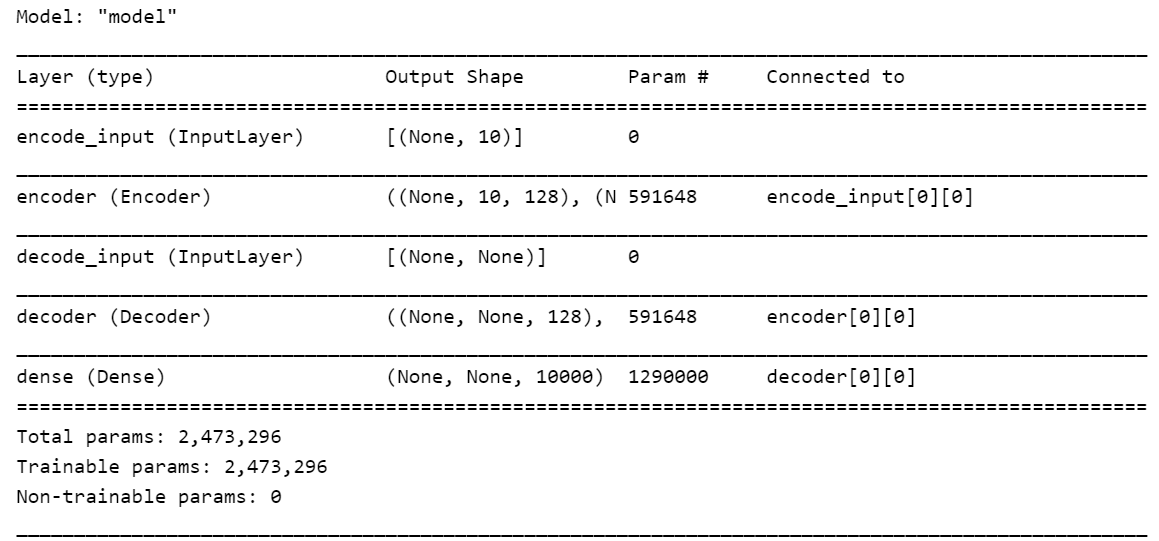
模型详细结构
我们自定义一些参数,看看seq2seq模型的整个结构。
maxlen = 10
embedding_dim = 50
hidden_units = 128
vocab_size = 10000
model = Seq2Seq(maxlen, embedding_dim, hidden_units, vocab_size)
print(model.summary())
seq2seq的层结构和参数,由于上面我们把encoder和decoder都封装在一起,所以这里看起来只有一个层,当然也可以展开的。
从上面seq2seq模型中获取Encoder子模块:
def encoder_infer(model):
encoder_model = Model(inputs=model.get_layer('encoder').input,
outputs=model.get_layer('encoder').output)
return encoder_model
encoder_model = encoder_infer(model)
print(encoder_model.summary())
Encoder内部的层结构和参数:

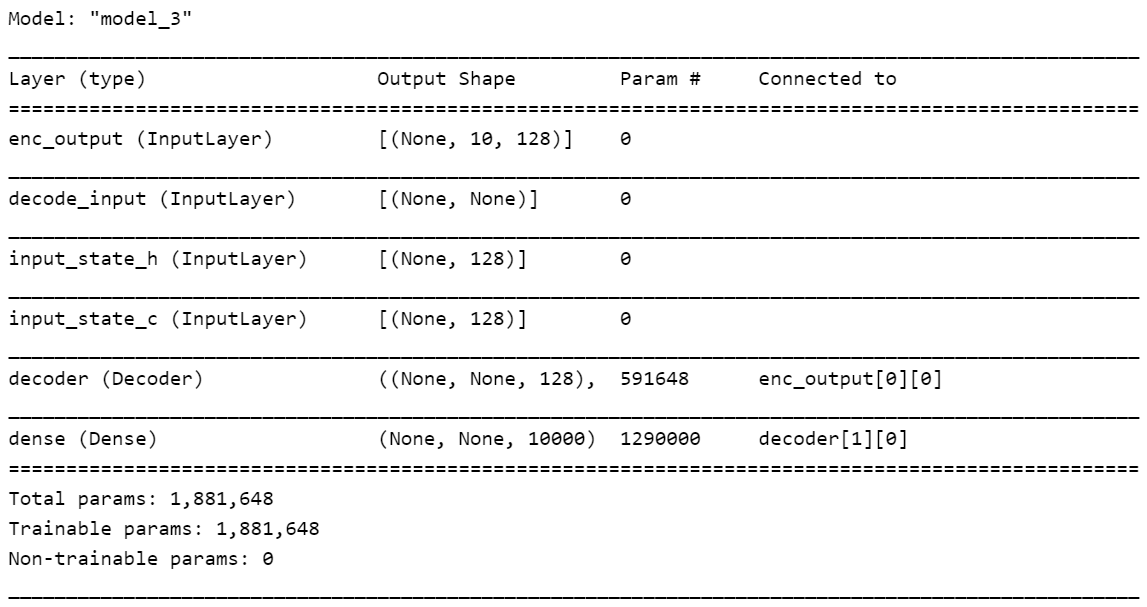
从上面seq2seq模型中获取Decoder子模块,这里没有直接从decoder层取,方便后续decoder的预测推断。
def decoder_infer(model, encoder_model):
encoder_output = encoder_model.get_layer('encoder').output[0]
maxlen, hidden_units = encoder_output.shape[1:]
dec_input = model.get_layer('decode_input').input
enc_output = Input(shape=(maxlen, hidden_units), name='enc_output')
enc_input_state_h = Input(shape=(hidden_units,), name='input_state_h')
enc_input_state_c = Input(shape=(hidden_units,), name='input_state_c')
dec_input_states = [enc_input_state_h, enc_input_state_c]
decoder = model.get_layer('decoder')
dec_outputs, out_state_h, out_state_c = decoder(enc_output, dec_input, dec_input_states)
dec_output_states = [out_state_h, out_state_c]
decoder_dense = model.get_layer('dense')
dense_output = decoder_dense(dec_outputs)
decoder_model = Model(inputs=[enc_output, dec_input, dec_input_states],
outputs=[dense_output]+dec_output_states)
return decoder_model
decoder_model = decoder_infer(model, encoder_model)
print(decoder_model.summary())
Decoder内部的层结构和参数:
seq2seq模型训练
这里我们以一个中文的聊天对话数据作为训练语料,训练一个简单的对话系统demo。语料已经分过词,首先对数据做一下预处理,转成one-hot表示,并添加一些开始结束符。
读取数据以及词典的方法
def read_vocab(vocab_path):
vocab_words = []
with open(vocab_path, "r", encoding="utf8") as f:
for line in f:
vocab_words.append(line.strip())
return vocab_words
def read_data(data_path):
datas = []
with open(data_path, "r", encoding="utf8") as f:
for line in f:
words = line.strip().split()
datas.append(words)
return datas
def process_data_index(datas, vocab2id):
data_indexs = []
for words in datas:
line_index = [vocab2id[w] if w in vocab2id else vocab2id["<UNK>"] for w in words]
data_indexs.append(line_index)
return data_indexs
预处理数据并生成词典
vocab_words = read_vocab("data/ch_word_vocab.txt")
special_words = ["<PAD>", "<UNK>", "<GO>", "<EOS>"]
vocab_words = special_words + vocab_words
vocab2id = {word: i for i, word in enumerate(vocab_words)}
id2vocab = {i: word for i, word in enumerate(vocab_words)}
num_sample = 10000
source_data = read_data("data/ch_source_data_seg.txt")[:num_sample]
source_data_ids = process_data_index(source_data, vocab2id)
target_data = read_data("data/ch_target_data_seg.txt")[:num_sample]
target_data_ids = process_data_index(target_data, vocab2id)
print("vocab test: ", [id2vocab[i] for i in range(10)])
print("source test: ", source_data[10])
print("source index: ", source_data_ids[10])
print("target test: ", target_data[10])
print("target index: ", target_data_ids[10])

Decoder部分输入输出加上开始结束标识
decoder的输入前面加上开始"“表示,输出后面加上结束”"标识。
def process_decoder_input_output(target_indexs, vocab2id):
decoder_inputs, decoder_outputs = [], []
for target in target_indexs:
decoder_inputs.append([vocab2id["<GO>"]] + target)
decoder_outputs.append(target + [vocab2id["<EOS>"]])
return decoder_inputs, decoder_outputs
target_input_ids, target_output_ids = process_decoder_input_output(target_data_ids, vocab2id)
print("decoder inputs: ", target_input_ids[:2])
print("decoder outputs: ", target_output_ids[:2])
数据pad填充
maxlen = 10
source_input_ids = keras.preprocessing.sequence.pad_sequences(source_data_ids, padding='post', maxlen=maxlen)
target_input_ids = keras.preprocessing.sequence.pad_sequences(target_input_ids, padding='post', maxlen=maxlen)
target_output_ids = keras.preprocessing.sequence.pad_sequences(target_output_ids, padding='post', maxlen=maxlen)
print(source_data_ids[:5])
print(target_input_ids[:5])
print(target_output_ids[:5])
构建模型
K.clear_session()
maxlen = 10
embedding_dim = 50
hidden_units = 128
vocab_size = len(vocab2id)
model = Seq2Seq(maxlen, embedding_dim, hidden_units, vocab_size)
print(model.summary())
训练模型
epochs = 10
batch_size = 32
val_rate = 0.2
loss_fn = keras.losses.SparseCategoricalCrossentropy()
model.compile(loss=loss_fn, optimizer='adam')
model.fit([source_input_ids, target_input_ids], target_output_ids,
batch_size=batch_size, epochs=epochs, validation_split=val_rate)
保存和加载模型
由于上面构建模型的写法原因,这里不能直接model.save()同时保存模型图和权重,这里只保存了保存模型的权重,所以新加载时,需要先重新定义模型,然后load_weights加载权重。
# save model weights
model.save_weights("data/seq2seq_attention_weights.h5")
del model
# load model weights
model = Seq2Seq(maxlen, embedding_dim, hidden_units, vocab_size)
model.load_weights("data/seq2seq_attention_weights.h5")
print(model.summary())
模型预测
seq2seq模型预测时,与一般的模型是有区别的,这里Encoder部分直接预测得到输出,Decoder部分需要一次预测一个位置的输出,并把当前位置的输出作为下一时刻的输入。所以decoder部分需要自己写一个循环,预测每个时刻输出,最后拼接到一起。结束的判断要么达到最大长度,要么预测出结束符""。
预测时用到了上面从seq2seq总的model中提取出的encoder_model和decoder_model部分,encoder_model用于对输入编码,decoder_model用于对输出按每个时刻解码。
import numpy as np
maxlen = 10
def infer_predict(input_text, encoder_model, decoder_model):
"""
预测部分
"""
text_words = input_text.split()[:maxlen]
input_id = [vocab2id[w] if w in vocab2id else vocab2id["<UNK>"] for w in text_words]
# input_id = [vocab2id["<START>"]] + input_id + [vocab2id["<END>"]]
if len(input_id) < maxlen:
input_id = input_id + [vocab2id["<PAD>"]] * (maxlen-len(input_id))
input_source = np.array([input_id])
input_target = np.array([vocab2id["<GO>"]])
# 编码器encoder预测输出
enc_outputs, enc_state_h, enc_state_c = encoder_model.predict([input_source])
dec_inputs = input_target
dec_states_inputs = [enc_state_h, enc_state_c]
result_id = []
result_text = []
for i in range(maxlen):
# 解码器decoder预测输出
dense_outputs, dec_state_h, dec_state_c = decoder_model.predict([enc_outputs, dec_inputs]+dec_states_inputs)
pred_id = np.argmax(dense_outputs[0][0])
result_id.append(pred_id)
result_text.append(id2vocab[pred_id])
if id2vocab[pred_id] == "<EOS>":
break
dec_inputs = np.array([[pred_id]])
dec_states_inputs = [dec_state_h, dec_state_c]
return result_id, result_text
测试一下输入一个句子,看看输出结果。
input_sent = "你 在 干 什么 呢"
result_id, result_text = infer_predict(input_text, encoder_model, decoder_model)
print("Input: ", input_text)
print("Output: ", result_text, result_id)
注意:这里作为例子,预测每个时刻的输出都只取了概率最大的那一个,这样的输出序列其实不是最优的,还有一种beam search的方法输出效果会更好,有机会在加上。
参考文档:
[1]. https://machinelearningmastery.com/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
[2]. https://www.tensorflow.org/guide/keras/functional

