

tensorflow2+keras简单实现BERT模型
文章目录
BERT模型简介
BERT主要利用Transformer Encoder部分结合Masked Language Model,训练双向注意力模型应用到语言建模中。

BERT模型拆解
完整项目参考:https://github.com/huanghao128/bert_example
tensorflow模块导入
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import activations
from tensorflow.keras import layers
from tensorflow.keras import models
from tensorflow.keras import backend as K
multi-head attention
class MultiHeadAttention(keras.Model):
def __init__(self, hidden_size, num_heads, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.hidden_size = hidden_size
self.num_heads = num_heads
self.head_size = hidden_size // num_heads
self.WQ = layers.Dense(hidden_size, name="dense_query")
self.WK = layers.Dense(hidden_size, name="dense_key")
self.WV = layers.Dense(hidden_size, name="dense_value")
self.dense = layers.Dense(hidden_size)
def _split_heads(self, x, batch_size):
x = tf.reshape(x, shape=[batch_size, -1, self.num_heads, self.head_size])
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, query, key, value, mask):
# query: (batch, maxlen, hidden_size)
# key : (batch, maxlen, hidden_size)
# value: (batch, maxlen, hidden_size)
batch_size = tf.shape(query)[0]
# shape: (batch, maxlen, hidden_size)
query = self.WQ(query)
key = self.WK(key)
value = self.WV(value)
# shape: (batch, num_heads, maxlen, head_size)
query = self._split_heads(query, batch_size)
key = self._split_heads(key, batch_size)
value = self._split_heads(value, batch_size)
# shape: (batch, num_heads, maxlen, maxlen)
matmul_qk = tf.matmul(query, key, transpose_b=True)
# 缩放 matmul_qk
dk = tf.cast(query.shape[-1], tf.float32)
score = matmul_qk / tf.math.sqrt(dk)
if mask is not None:
mask = tf.cast(mask[:, tf.newaxis, tf.newaxis, :], dtype=tf.float32)
score += (1 - mask) * -1e9
alpha = tf.nn.softmax(score)
context = tf.matmul(alpha, value)
context = tf.transpose(context, perm=[0, 2, 1, 3])
context = tf.reshape(context, (batch_size, -1, self.hidden_size))
output = self.dense(context)
return output
FeedForwardNetwork
class GELU(layers.Layer):
def __init__(self):
super(GELU, self).__init__()
def call(self, x):
cdf = 0.5 * (1.0 + tf.tanh((np.sqrt(2 / np.pi) * (x + 0.044715 * tf.pow(x, 3)))))
return x * cdf
class FeedForwardNetwork(keras.Model):
def __init__(self, dff_size, hidden_size):
super(FeedForwardNetwork, self).__init__()
self.dense1 = layers.Dense(dff_size)
self.activation = GELU()
self.dense2 = layers.Dense(hidden_size)
def call(self, x):
x = self.dense1(x)
x = self.activation(x)
x = self.dense2(x)
return x
Transformer Encoder
# Encoder Layer层
class TransformerBlock(keras.Model):
def __init__(self, hidden_size, num_heads, dff_size, rate=0.1, **kwargs):
super(TransformerBlock, self).__init__(**kwargs)
self.attention = MultiHeadAttention(hidden_size, num_heads)
self.ffn = FeedForwardNetwork(dff_size, hidden_size)
# Layer Normalization
self.layernorm1 = layers.LayerNormalization(epsilon=1e-6, name="layernorm_1")
self.layernorm2 = layers.LayerNormalization(epsilon=1e-6, name="layernorm_2")
self.dropout1 = layers.Dropout(rate)
self.dropout2 = layers.Dropout(rate)
def call(self, x, mask, training=False):
# multi head attention
attn_output = self.attention(x, x, x, mask)
attn_output = self.dropout1(attn_output, training=training)
# residual connection
out1 = self.layernorm1(x + attn_output)
# ffn layer
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
# Residual connection
out2 = self.layernorm2(out1 + ffn_output)
return out2
位置编码PositionEmbedding
固定位置编码
def positional_encoding(maxlen, hidden_size):
PE = np.zeros((maxlen, hidden_size))
for i in range(maxlen):
for j in range(hidden_size):
if j % 2 == 0:
PE[i, j] = np.sin(i / 10000 ** (j / hidden_size))
else:
PE[i, j] = np.cos(i / 10000 ** ((j-1) / hidden_size))
PE = tf.constant(PE, dtype=tf.float32)
return PE
可学习位置编码
class PositionEmbedding(layers.Layer):
def __init__(self, maxlen, hidden_size, name):
super(PositionEmbedding, self).__init__()
self.embedding = layers.Embedding(maxlen, hidden_size)
def call(self, inputs):
position_ids = tf.range(inputs.shape[1], dtype=tf.int32)[tf.newaxis, :]
position_embeddings = self.embedding(position_ids)
return position_embeddings
BERT输入Embedding

class BERTEmbedding(keras.Model):
def __init__(self, vocab_size, hidden_size, maxlen, rate=0.1):
super(BERTEmbedding, self).__init__()
self.token_embedding = layers.Embedding(vocab_size, hidden_size, name="token_embedding")
self.segment_embedding = layers.Embedding(2, hidden_size, name="segment_embedding")
self.position_embedding = PositionEmbedding(maxlen, hidden_size, name="position_embedding")
self.dropout = layers.Dropout(rate)
def call(self, x, segment_ids, training=False):
tokens_embeddings = self.token_embedding(x)
segment_embeddings = self.segment_embedding(segment_ids)
position_embeddings = self.position_embedding(x)
embeddings = tokens_embeddings + segment_embeddings + position_embeddings
embeddings = self.dropout(embeddings, training=training)
return embeddings
Masked Language Model
从一个batch的隐藏层按mask索引抽取部分数据
def gather_indexes(input_tensor, positions):
"""Gathers the vectors at the specific positions over a minibatch."""
sequence_shape = tf.shape(input_tensor)
batch_size = sequence_shape[0]
seq_length = sequence_shape[1]
width = sequence_shape[2]
flat_offsets = tf.reshape(tf.range(0, batch_size, dtype=tf.int32) * seq_length, [-1, 1])
flat_positions = tf.reshape(positions + flat_offsets, [-1])
flat_input_tensor = tf.reshape(input_tensor, [batch_size * seq_length, width])
output_tensor = tf.gather(flat_input_tensor, flat_positions)
output_tensor = tf.reshape(output_tensor, [batch_size, -1, width])
return output_tensor
带mask的语言模型
class MaskedLanguageModel(layers.Layer):
def __init__(self, vocab_size, name):
super(MaskedLanguageModel, self).__init__()
self._name = name
b_init = tf.zeros_initializer()(shape=(vocab_size,), dtype="float32")
self.bias = tf.Variable(initial_value=b_init, trainable=True)
self.activation = layers.Activation(activation="softmax")
def call(self, inputs, positions, weights):
mask_inputs = gather_indexes(inputs, positions)
out = tf.matmul(mask_inputs, weights, transpose_b=True) + self.bias
out = self.activation(out)
return out
Next Sentence Prediction
根据输入时第一个token位置[CLS]表示是否为下一个句子的标示,从最后隐藏层一个位置的输出,接一个2分类的全连接层,过softmax激活做分类任务。
BERT base model
class BERT(keras.Model):
def __init__(self, vocab_size, hidden_size=768, maxlen=512, num_layers=12, nums_heads=12, rate=0.1):
super(BERT, self).__init__()
self.num_layers = num_layers
self.nums_heads = nums_heads
self.dff_size = hidden_size * 4
self.embedding = BERTEmbedding(vocab_size=vocab_size, hidden_size=hidden_size, maxlen=maxlen)
self.transformer_blocks = [TransformerBlock(hidden_size, nums_heads, self.dff_size, rate)
for i in range(num_layers)]
def call(self, inputs):
input_ids, segment_ids, input_mask, training = inputs
# add input embedding
x = self.embedding(input_ids, segment_ids, training)
output_weights = self.embedding.token_embedding.weights
# multi transformer
for i in range(self.num_layers):
x = self.transformer_blocks[i](x, input_mask, training)
return x, output_weights
masked_language_model和next sentence prediction
class BERTMLM(keras.Model):
def __init__(self, vocab_size, hidden_size=768, maxlen=512, num_layers=12, nums_heads=12, rate=0.1):
super(BERTMLM, self).__init__()
self.bert = BERT(vocab_size, hidden_size, maxlen, num_layers, nums_heads, rate)
self.masked_language_model = MaskedLanguageModel(vocab_size=vocab_size, name="mlm")
self.extract_nsp_embedding = layers.Lambda(lambda x: x[:,0], name="nsp_embedding")
self.next_sentence = layers.Dense(2, activation='softmax', name="nsp")
def call(self, inputs):
input_ids, segment_ids, input_mask, masked_lm_positions, training = inputs
seq_outputs, output_weights = self.bert([input_ids, segment_ids, input_mask, training])
# MLM output
mlm_output = self.masked_language_model(seq_outputs, masked_lm_positions, output_weights)
# NSP output
nsp_output = self.next_sentence(self.extract_nsp_embedding(seq_outputs))
return seq_outputs, mlm_output, nsp_output
测试输出模型结构
vocab_size = 10000
hidden_size = 768
maxlen = 128
mask_len = 10
num_layers = 4
nums_heads = 4
input_ids = layers.Input(shape=(maxlen,), name="input_ids", dtype=tf.float32)
segment_ids = layers.Input(shape=(maxlen,), name="segment_ids", dtype=tf.float32)
input_mask = layers.Input(shape=(maxlen,), name="input_mask", dtype=tf.float32)
masked_lm_positions = layers.Input(shape=(mask_len,), name="masked_lm_positions", dtype=tf.int32)
masked_lm_labels = layers.Input(shape=(mask_len,vocab_size), name="masked_lm_labels", dtype=tf.int32)
is_next_labels = layers.Input(shape=(2), name="is_next", dtype=tf.int32)
bert = BERTMLM(vocab_size=vocab_size,
hidden_size=hidden_size,
maxlen=maxlen,
num_layers=num_layers,
nums_heads=nums_heads)
bert_output, mlm_output, nsp_output = bert([input_ids, segment_ids, input_mask, masked_lm_positions, True])
model = models.Model(inputs=[input_ids, segment_ids, input_mask, masked_lm_positions],
outputs=[mlm_output, nsp_output])
print(model.summary())
模型结构summary结果
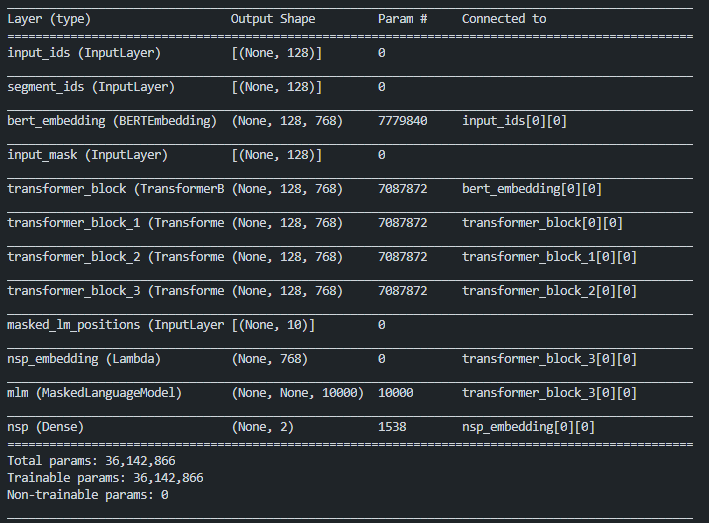
BERT模型训练
下面是一个简单的训练bert语言模型的实例。
生成训练样本
def load_dataset(data_path, tokenizer):
all_documents = []
with open(data_path, "r", encoding="utf8") as f:
for line in f:
line = line.strip()
doc_tokens = tokenizer.tokenize(line)
all_documents.append(doc_tokens)
max_seq_length = 128
max_pred_per_seq = 10
vocab_size = len(tokenizer.vocab)
data_features = []
i = 0
for doc_index in range(len(all_documents)):
doc_pair_tokens = create_pair_document(all_documents, doc_index, max_seq_length, short_seq_prob=0.1)
for tokens_a, tokens_b, is_next in doc_pair_tokens:
example = InputExample(i, tokens_a, tokens_b, is_next, lm_labels=None)
feature = convert_examples_to_features(example, seq_length=max_seq_length,
max_pred_per_seq=max_pred_per_seq, tokenizer=tokenizer)
data_features.append(feature)
i += 1
input_ids, segment_ids, input_mask = [], [], []
masked_lm_positions, masked_lm_labels, is_next_labels = [], [], []
for feature in data_features:
input_ids.append(feature.input_ids)
segment_ids.append(feature.segment_ids)
input_mask.append(feature.input_mask)
masked_lm_positions.append(feature.masked_lm_positions)
masked_lm_labels.append(feature.masked_lm_ids)
is_next_labels.append(feature.is_next)
masked_lm_labels = to_categorical(masked_lm_labels, num_classes=vocab_size)
is_next_labels = to_categorical(is_next_labels, num_classes=2)
input_ids = np.array(input_ids)
segment_ids = np.array(segment_ids)
input_mask = np.array(input_mask)
masked_lm_positions = np.array(masked_lm_positions)
data_features = [input_ids, segment_ids, input_mask, masked_lm_positions]
data_labels = [masked_lm_labels, is_next_labels]
return data_features, data_labels
训练模型
model用上面已经定义好的
data_features, data_labels = load_dataset("data/sample_data.txt", tokenizer)
print("train sample count: ", len(data_features[0]))
print("start training...")
model.fit(x=data_features, y=data_labels, validation_split=0.1,
batch_size=batch_size, epochs=epochs)
bert_model = models.Model(inputs=model.inputs, outputs=bert_output)
print(bert_model.summary())
bert_model.save_weights("output/bert_model_ckpt")

